Download as PDF, PPTX


![The author of this material is Julien Simon https://www.linkedin.com/in/juliensimon unless explicitly mentioned.
This material is shared under the CC BY-NC 4.0 license https://creativecommons.org/licenses/by-nc/4.0/
You are free to share and adapt this material, provided that you give appropriate credit, provide a link to the license, and indicate if changes were made.
You may not use the material for commercial purposes. You may not apply any restriction on what the license permits.
[ ]
minFP32 maxFP32
0
Rescaling weights and activations
Note: only one dimension is shown,
but we need to do the same on all tensor dimensions!
[ ]
minINT8 maxINT8
0](https://image.slidesharecdn.com/deepdivequantizingllms-240811122507-fba3e9f3/85/Julien-Simon-Deep-Dive-Quantizing-LLMs-3-320.jpg)
![The author of this material is Julien Simon https://www.linkedin.com/in/juliensimon unless explicitly mentioned.
This material is shared under the CC BY-NC 4.0 license https://creativecommons.org/licenses/by-nc/4.0/
You are free to share and adapt this material, provided that you give appropriate credit, provide a link to the license, and indicate if changes were made.
You may not use the material for commercial purposes. You may not apply any restriction on what the license permits.
Mapping function
The mapping function maps the high-precision numerical space to a lower-precision space
This usually takes place per layer, but finer-grained quantization is also possible (e.g. per row or per column)
S,Z: quantization parameters
Ratio of the [⍺,β] input range to the [⍺q,βq] output range
For 8-bit quantization: βq-⍺q = 28-1
Bias value to map a zero input to a zero output
How can we best pick the [⍺,β] range to minimize quantization error?
Q (r) = round
(
r
S
+ Z
)
S =
β − α
βq − αq
Z = αq −
α
S](https://image.slidesharecdn.com/deepdivequantizingllms-240811122507-fba3e9f3/85/Julien-Simon-Deep-Dive-Quantizing-LLMs-4-320.jpg)
![The author of this material is Julien Simon https://www.linkedin.com/in/juliensimon unless explicitly mentioned.
This material is shared under the CC BY-NC 4.0 license https://creativecommons.org/licenses/by-nc/4.0/
You are free to share and adapt this material, provided that you give appropriate credit, provide a link to the license, and indicate if changes were made.
You may not use the material for commercial purposes. You may not apply any restriction on what the license permits.
Picking the [⍺,β] range
[ ]
minFP32 maxFP32
⍺ β
0
[ ]
minINT8 maxINT8
⍺q βq
0
A simple technique is to use the minimum and maximum value of the input range
This is sensitive to outliers: part of [⍺q,βq] could be unused, and "squeeze" other values
Alternative: use percentiles or histogram bins
Range Min. positive value
FP32 / BF16 [±1.18e-38, ±3.4e38] 1.4e-45
INT8 [-128, +127] 1](https://image.slidesharecdn.com/deepdivequantizingllms-240811122507-fba3e9f3/85/Julien-Simon-Deep-Dive-Quantizing-LLMs-5-320.jpg)
![The author of this material is Julien Simon https://www.linkedin.com/in/juliensimon unless explicitly mentioned.
This material is shared under the CC BY-NC 4.0 license https://creativecommons.org/licenses/by-nc/4.0/
You are free to share and adapt this material, provided that you give appropriate credit, provide a link to the license, and indicate if changes were made.
You may not use the material for commercial purposes. You may not apply any restriction on what the license permits.
Picking the [⍺,β] range
[ ]
minFP32 maxFP32
⍺ β
0
[ ]
minINT8 maxINT8
⍺q βq
0
To make the best use of [⍺q,βq], we need to get rid of outliers
How many can we eliminate without hurting accuracy too much?
We need to minimize information loss between the two distributions
➡ Use a calibration dataset and minimize the Kullback-Leibler (KL) divergence 😱
Range Min. positive value
FP32 / BF16 [±1.18e-38, ±3.4e38] 1.4e-45
INT8 [-128, +127] 1](https://image.slidesharecdn.com/deepdivequantizingllms-240811122507-fba3e9f3/85/Julien-Simon-Deep-Dive-Quantizing-LLMs-6-320.jpg)







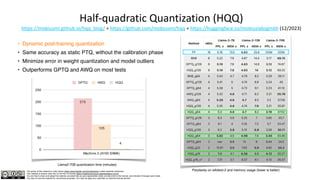



The document discusses quantization techniques for large language models (LLMs), detailing methods to reduce memory and compute requirements while minimizing accuracy loss. It covers various quantization types, including post-training dynamic quantization, quantization-aware training, and specific implementations like ZeroQuant and Activation-Aware Weight Quantization. Additionally, it includes examples and comparisons of model performance improvements through quantization in practical applications.






































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)












