Download as PDF, PPTX



![The author of this material is Julien Simon https://www.linkedin.com/in/juliensimon unless explicitly mentioned.
This material is shared under the CC BY-NC 4.0 license https://creativecommons.org/licenses/by-nc/4.0/
You are free to share and adapt this material, provided that you give appropriate credit, provide a link to the license, and indicate if changes were made.
You may not use the material for commercial purposes. You may not apply any restriction on what the license permits.
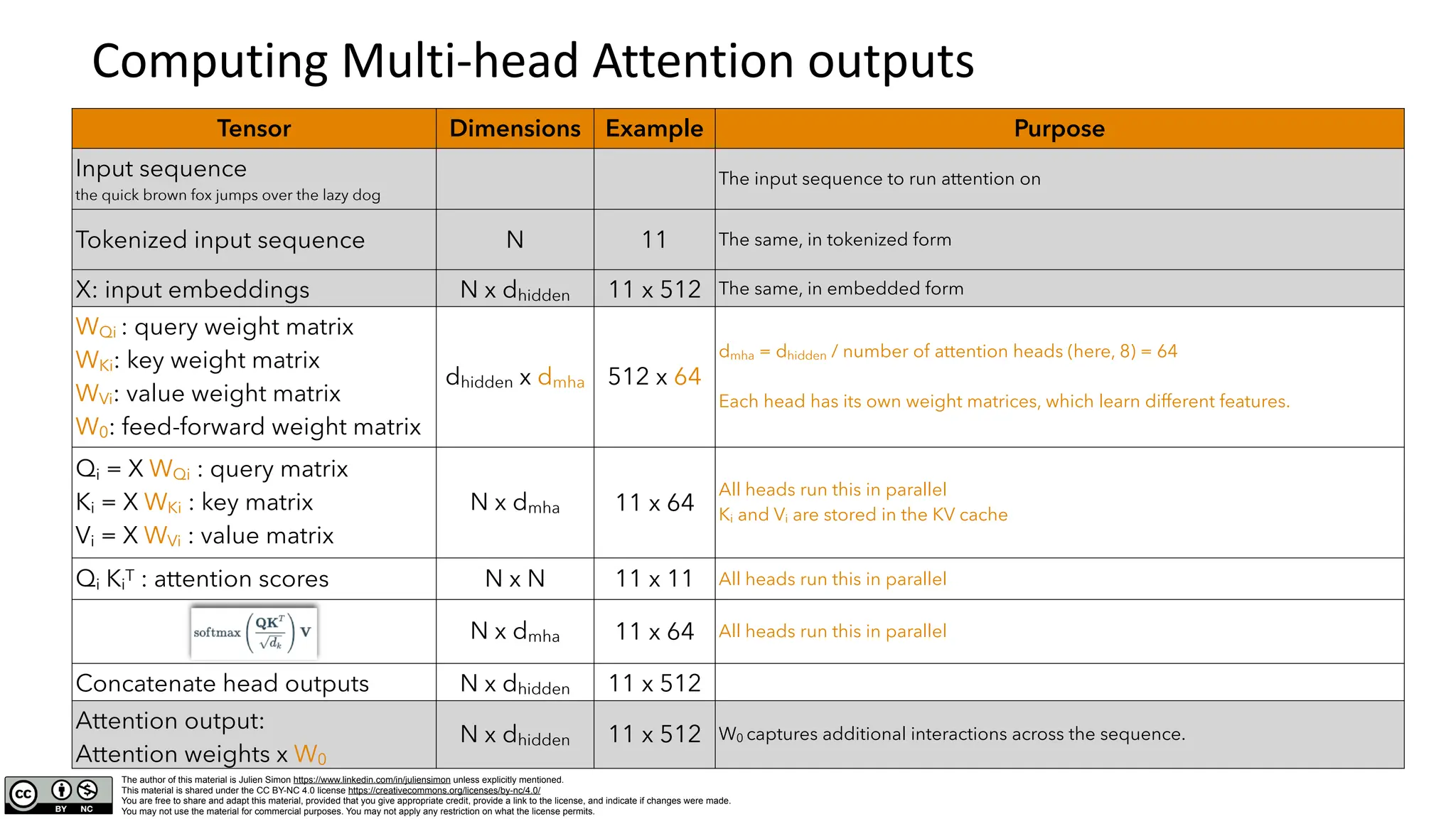
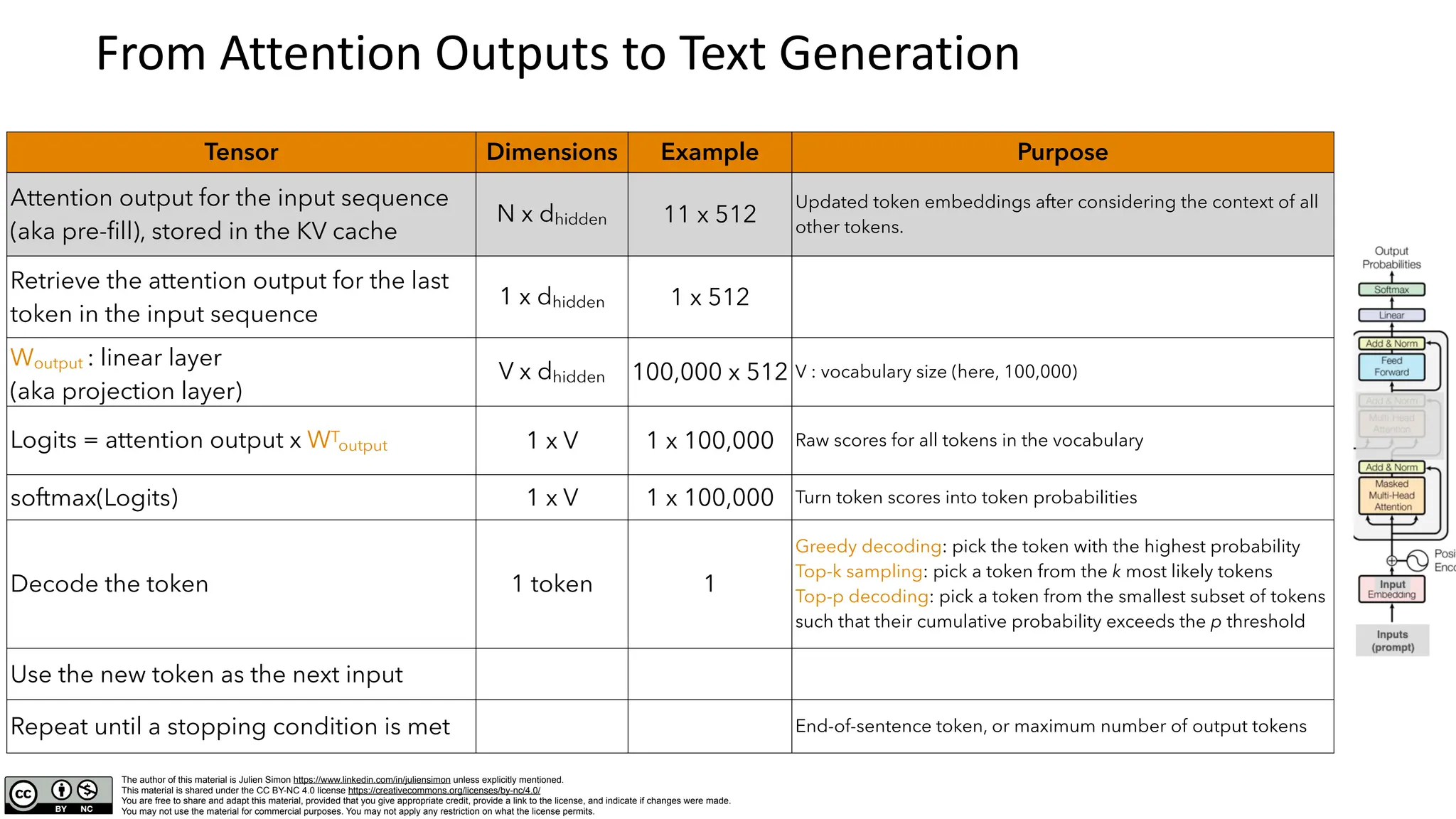
Computing Attention outputs
Tensor Dimensions Example Purpose
Input sequence
the quick brown fox jumps over the lazy dog
The input sequence to run attention on: 9 words
Tokenized input sequence
[101, 1996, 4248, 2829, 4419, 14523, 2058, 1996, 13971, 3899, 102]
N 11 The same, in tokenized form, plus start and end tokens
X: input embeddings N x dhidden 11x512 The same, in embedded form: dhidden is the embedding size
WQ : query weight matrix
WK: key weight matrix
WV: value weight matrix
W0: feed-forward weight matrix
dhidden x dhidden 512 x 512 Model weights learned during training
Q = X WQ : query matrix
K = X WK : key matrix
V = X WV : value matrix
N x dhidden 11 x 512
Q expresses what each token needs to know from others (« search query »)
K encodes the information that each token provides (« keywords »)
V stores the actual content that each token shares when attended to (« values »)
Q KT : attention scores N x N 11 x 11 How well each token matches the keys of the other tokens (« similarity scores »)
N x dhidden 11 x 512
Tokens collect information from each other based on their relevance
(« attention weights »)
Attention output:
Attention weights x W0
N x dhidden 11 x 512 W0 captures additional interactions across the sequence.](https://image.slidesharecdn.com/deepdivemultiheadlatentattention-250110081708-99e74bfd/75/deep_dive_multihead_latent_attention-pdf-4-2048.jpg)
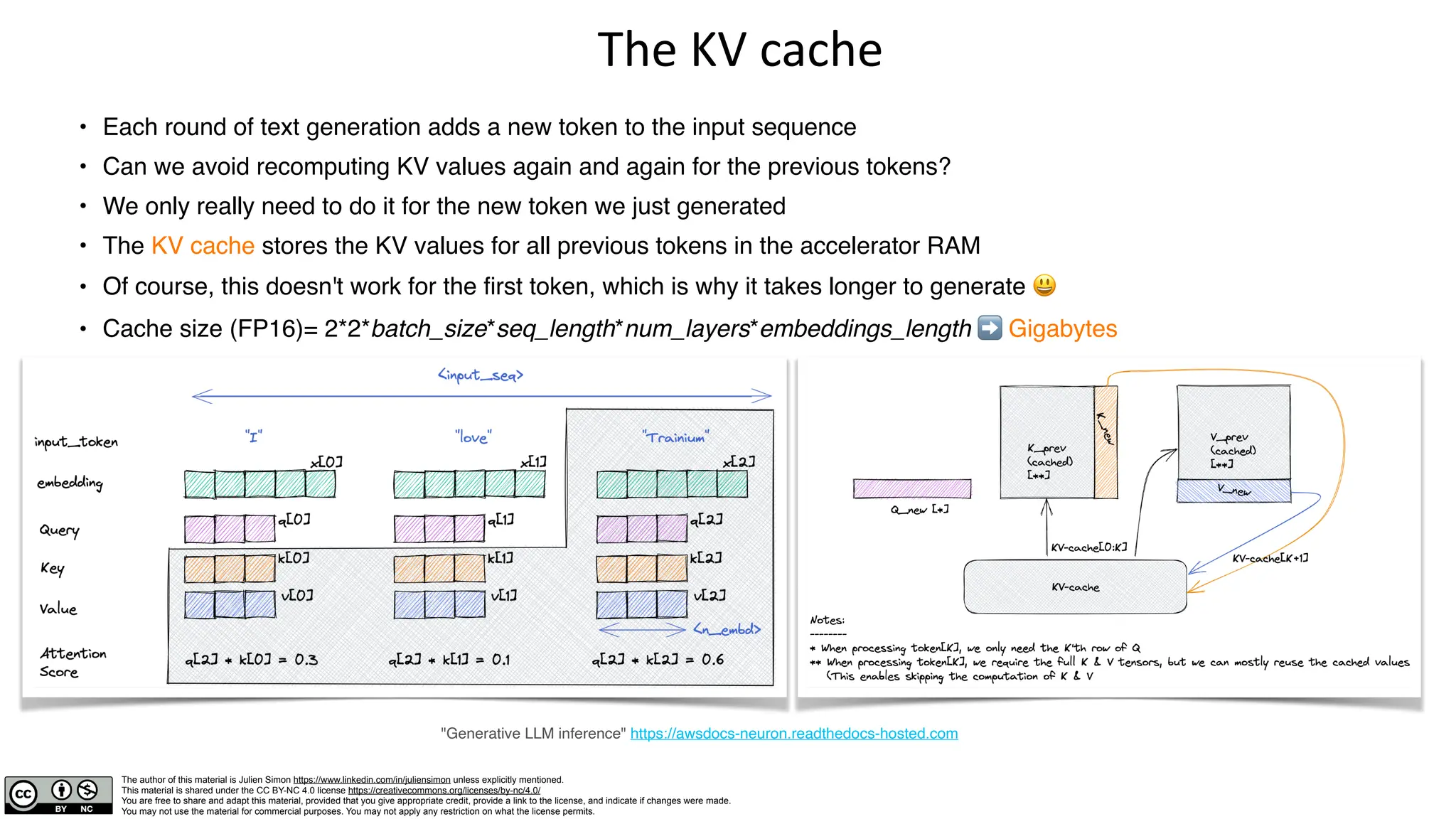

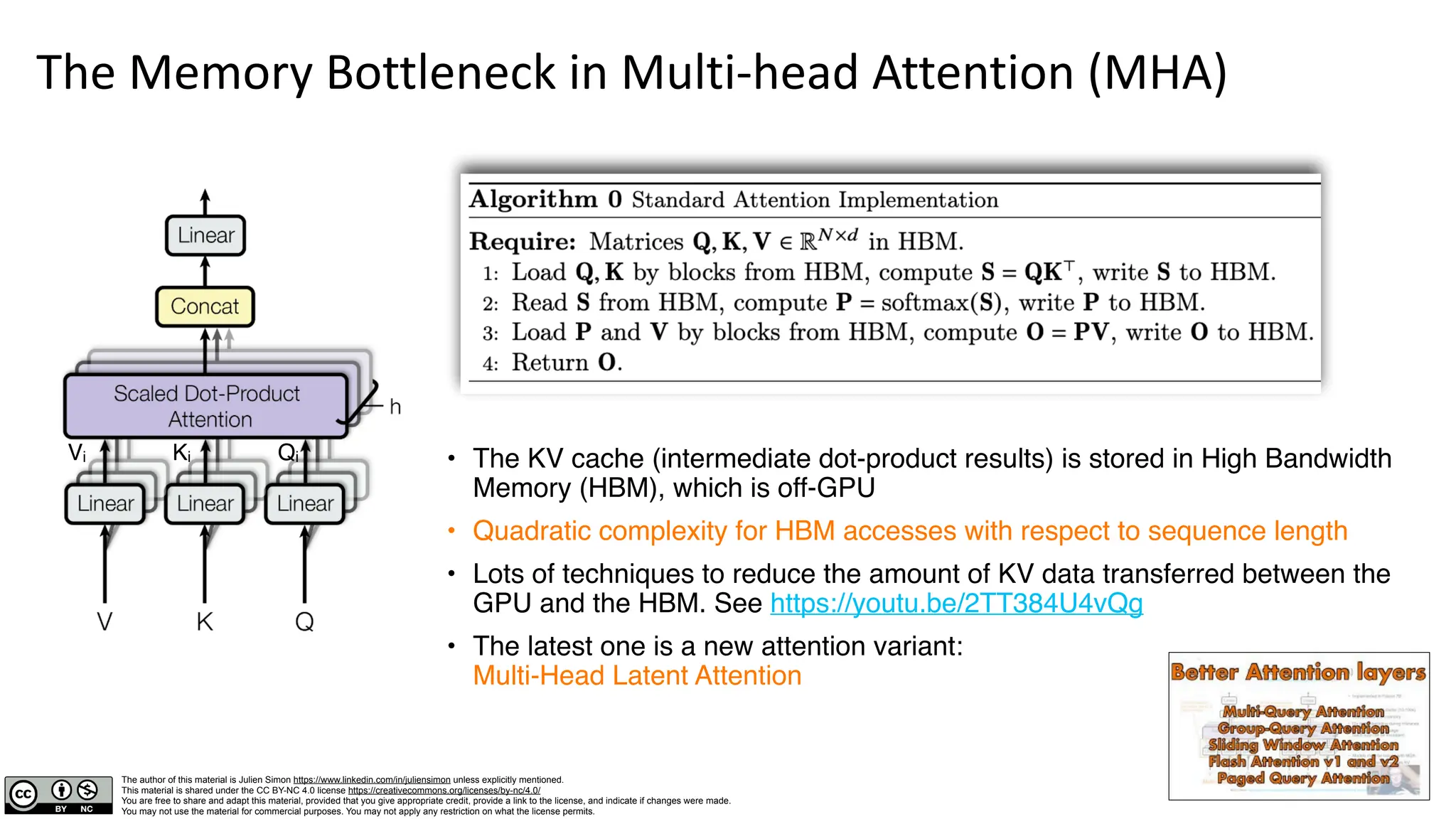

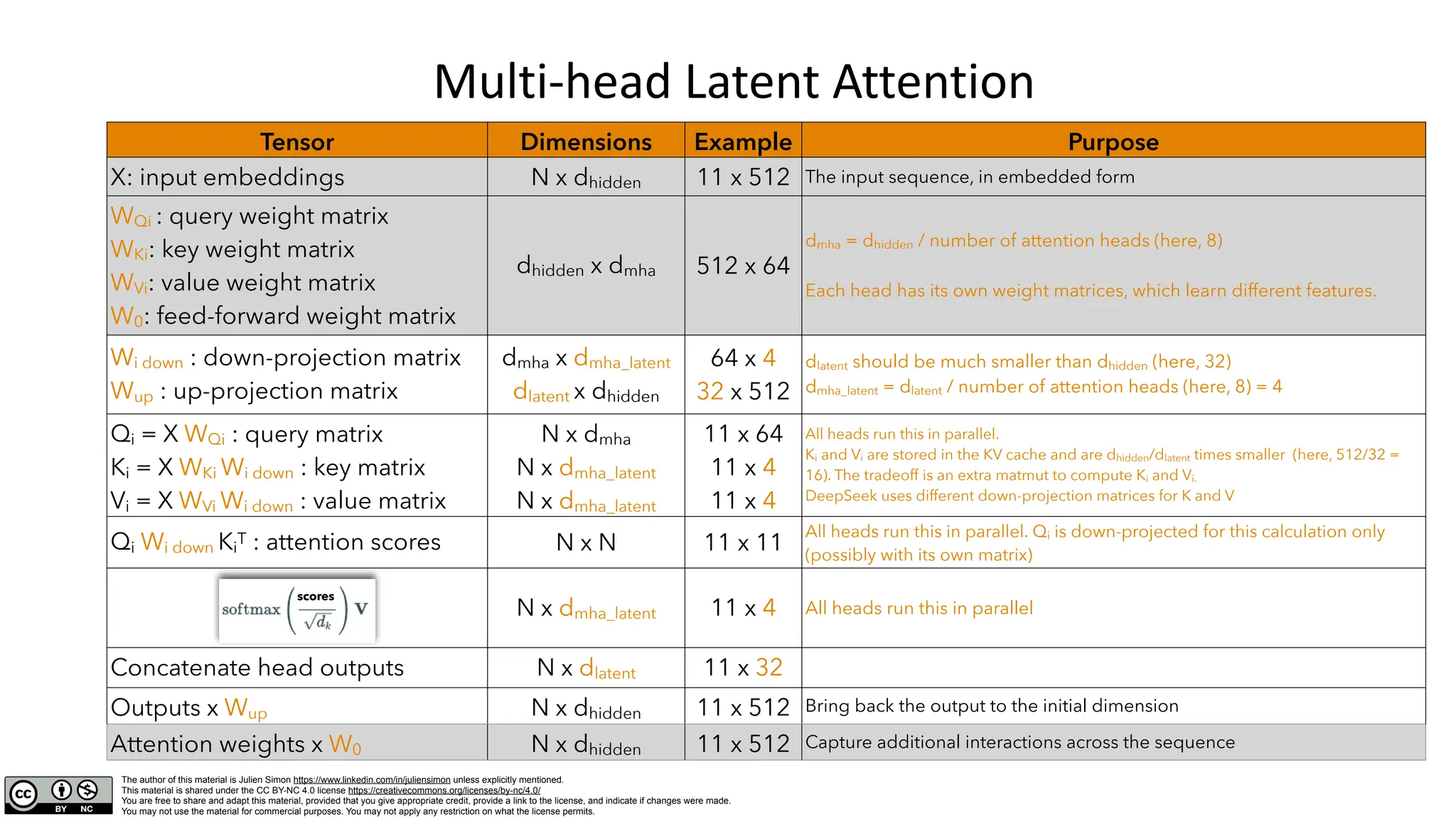

The document provides a detailed overview of the text generation process using decoder-only transformer models, focusing on elements such as input processing, attention mechanisms, and the role of multi-head attention (MHA). It also discusses advancements like multi-head latent attention, which optimizes memory usage and inference speed while maintaining accuracy. Additionally, it includes information on the architecture's implications on hardware requirements and computational efficiency.






























![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)























































