



















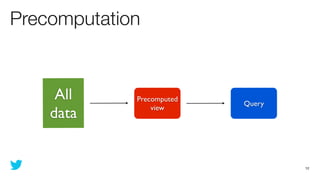
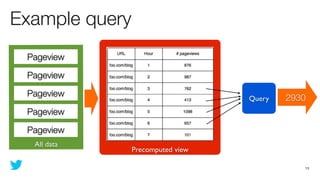
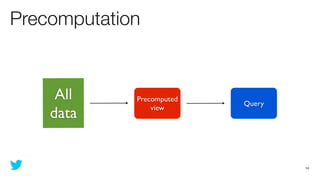
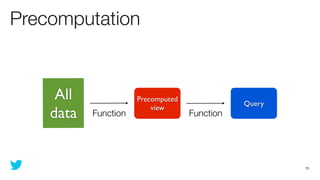

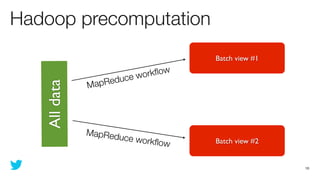




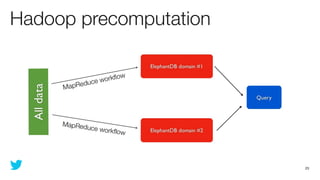

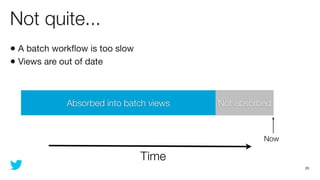
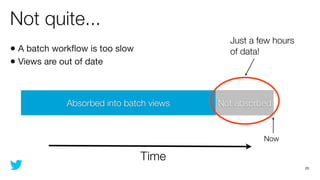
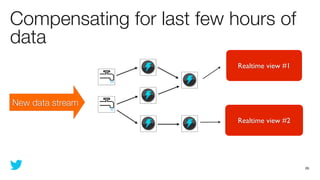
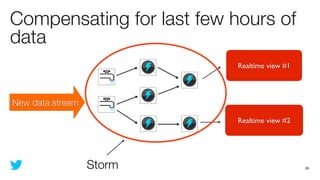

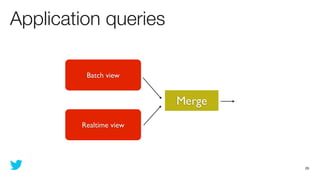
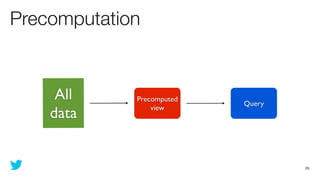
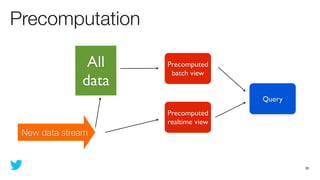
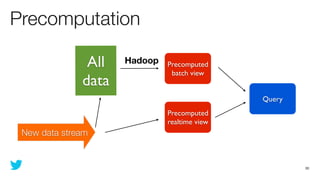
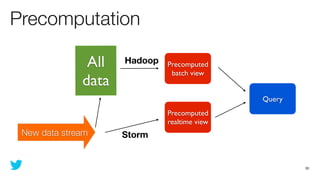
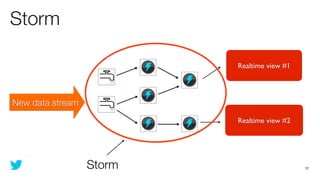

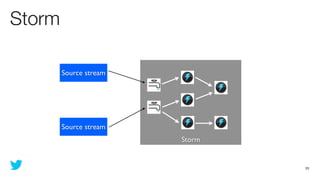
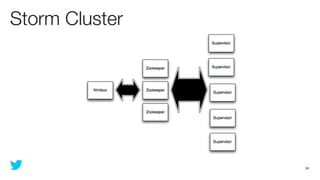
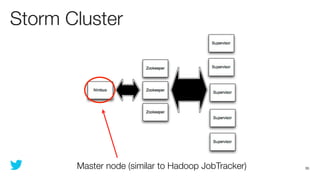
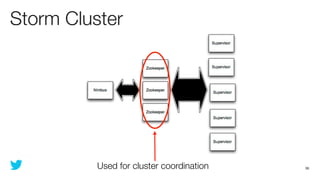
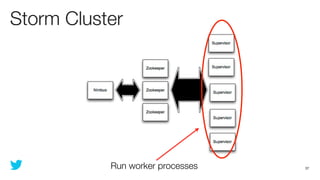



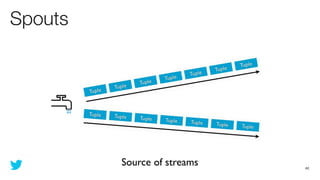

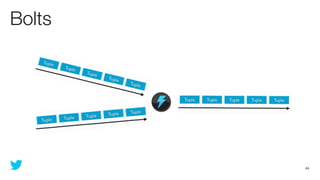

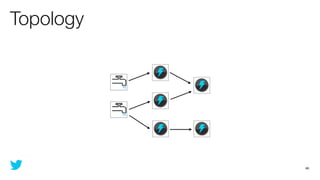
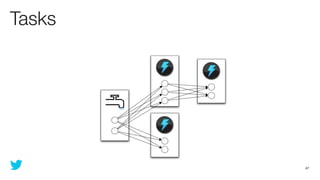
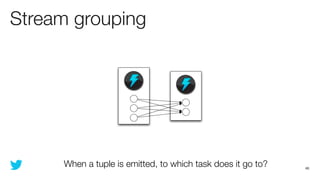







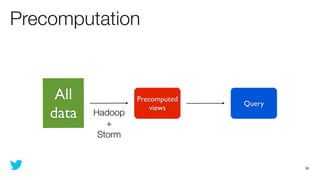
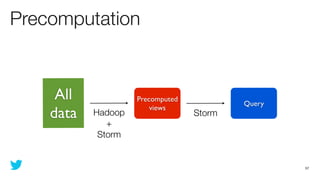



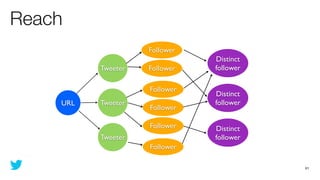
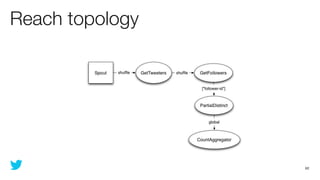
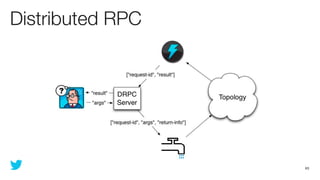
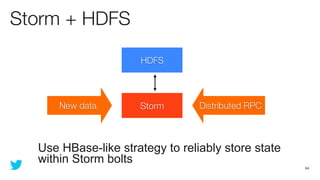







This document discusses how to use Storm and Hadoop together to enable real-time and batch processing of large datasets. It describes using Hadoop to precompute batch views of data, and Storm to incrementally update real-time views as new data streams in. This allows for low-latency queries by combining precomputed batch views with real-time views that compensate for recent data not yet absorbed into the batch views.












































































