Download as PDF, PPTX










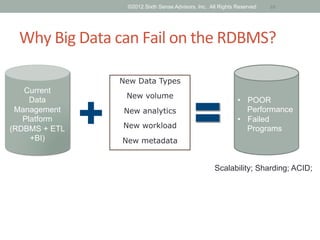

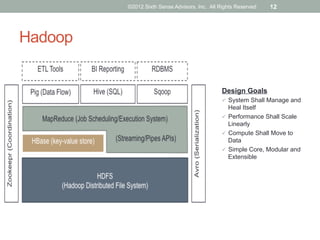





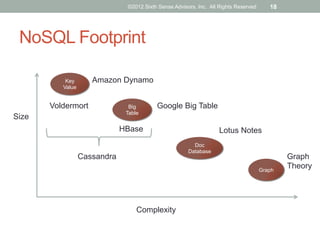



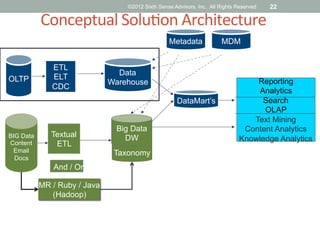

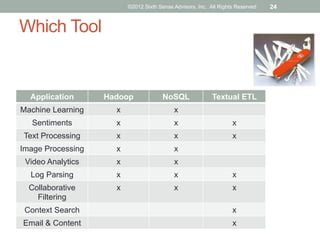

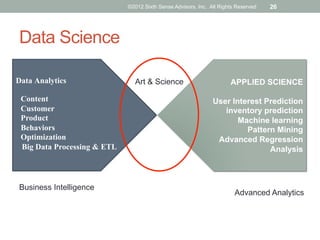


The document discusses emerging trends in big data and analytics, including how expectations for business intelligence are changing with the growth of unstructured data sources. It covers challenges associated with integrating big data, and introduces concepts and tools like Hadoop, NoSQL databases, and textual ETL to address these challenges. The final sections discuss best practices for big data projects and provide examples of successful big data applications.































































































