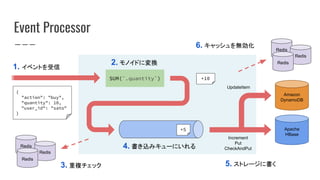
What is Zero?
SELECT
count(*) AS foo,
sum(`...`) AS bar
FROM
flume(`.datetime`) DISTINCT ON `.uuid` FOR 10m
WHERE `
...
`
GROUP BY `{
user_id: ...
}`
PARTITION BY user_id
INTERVAL 1d, NONE
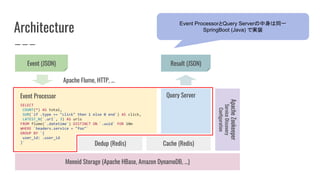
クエリ(ZeroQL)を登録すると ...
… 結果をリアルタイムに取得できます。
GET /v1/report.json?column.user_id=1
HTTP/1.1 200 OK
Content-type: application/json
{
"rows": [
{
"user_id": 1,
"foo": 100,
"bar": 200
}
]
}
ログの発生から結果に反映されるまで数秒程度。
結果のレスポンス時間は平均数ミリ秒 ~ 数十ミリ秒程度。
What is Zero?
LATEST(…)
最新値
LATEST_N(…,n)
最新のn件
LATEST_SET_N(…,n)
最新のn件(重複を除く)
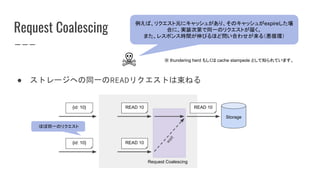
7.
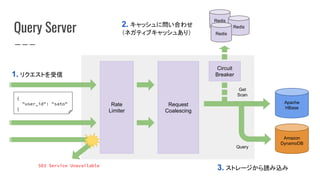
What is Zero?
WHERE `
.name == "jackson-jq"
and .language == "java"
and .url == "https://github.com/eiiches/jackson-jq"
`
● JSON形式のイベント(ログ)処理のためにjqに対応
SELECT
SUM(`if .action == "click" then 100 else 1 end`) AS score
ライブラリ(Java)としてjackson-jqを開発
GROUP BY `{
user_id: .user_id,
ad_id: .ads[].id
}`
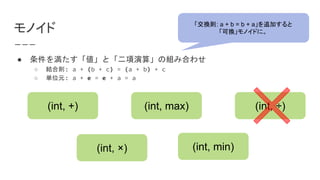
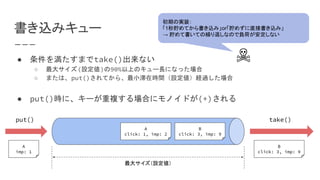
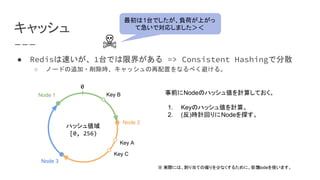
モノイド
● 条件を満たす「値」と「二項演算」の組み合わせ
○ 結合則:a + (b + c) = (a + b) + c
○ 単位元: a + e = e + a = a
「交換則: a + b = b + a」を追加すると
「可換」モノイドに。
(int, +)
(int, ×)
(int, max)
(int, min)
(int, ÷)
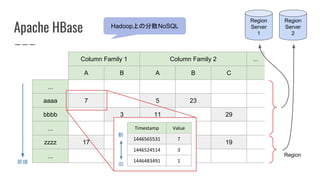
Apache HBase Hadoop上の分散NoSQL
ColumnFamily 1 Column Family 2 ...
A B A B C
...
aaaa 7 5 23
bbbb 3 11 29
...
zzzz 17 13 1 19
...
昇順
新
旧
Region
Region
Server
1
Region
Server
2

![What is Zero ?
SELECT
count(*) AS foo,
sum(`...`) AS bar
FROM
flume(`.datetime`) DISTINCT ON `.uuid` FOR 10m
WHERE `
...
`
GROUP BY `{
user_id: ...
}`
PARTITION BY user_id
INTERVAL 1d, NONE
クエリ(ZeroQL)を登録すると ...
… 結果をリアルタイムに取得できます。
GET /v1/report.json?column.user_id=1
HTTP/1.1 200 OK
Content-type: application/json
{
"rows": [
{
"user_id": 1,
"foo": 100,
"bar": 200
}
]
}
ログの発生から結果に反映されるまで数秒程度。
結果のレスポンス時間は平均数ミリ秒 ~ 数十ミリ秒程度。](https://image.slidesharecdn.com/3zero2017-09-27-170928013312/85/Zero-3-320.jpg)



![What is Zero ?
WHERE `
.name == "jackson-jq"
and .language == "java"
and .url == "https://github.com/eiiches/jackson-jq"
`
● JSON形式のイベント(ログ)処理のためにjqに対応
SELECT
SUM(`if .action == "click" then 100 else 1 end`) AS score
ライブラリ(Java)としてjackson-jqを開発
GROUP BY `{
user_id: .user_id,
ad_id: .ads[].id
}`](https://image.slidesharecdn.com/3zero2017-09-27-170928013312/85/Zero-7-320.jpg)








![Patching Apache HBase
● [HBASE-14460] スレッドの競合でread-modify-writeが遅くなる
○ HBaseチームでパッチ作成 (HBASE-14460のパッチとは別)
○ Fix: 忘れました
● [HBASE-17072] ThreadLocal内のハッシュテーブルで負荷高騰
○ ハッシュテーブルの primary clustering
○ 不要なキャッシュロジックをごっそり削除(乱暴)
○ Fix: 2.0.0, 1.4.0, 0.98.24, cdh5.10.0
● [HBASE-18042,...] Scannerをサーバー側で早期クローズ
○ 何故かScannerが大量に残ってFullGCで死ぬことがあり、そもそも早期クローズで回避。
○ branch-1.3のコミットをバックポート
○ Fix: 1.3.2](https://image.slidesharecdn.com/3zero2017-09-27-170928013312/85/Zero-26-320.jpg)

























































