Download to read offline




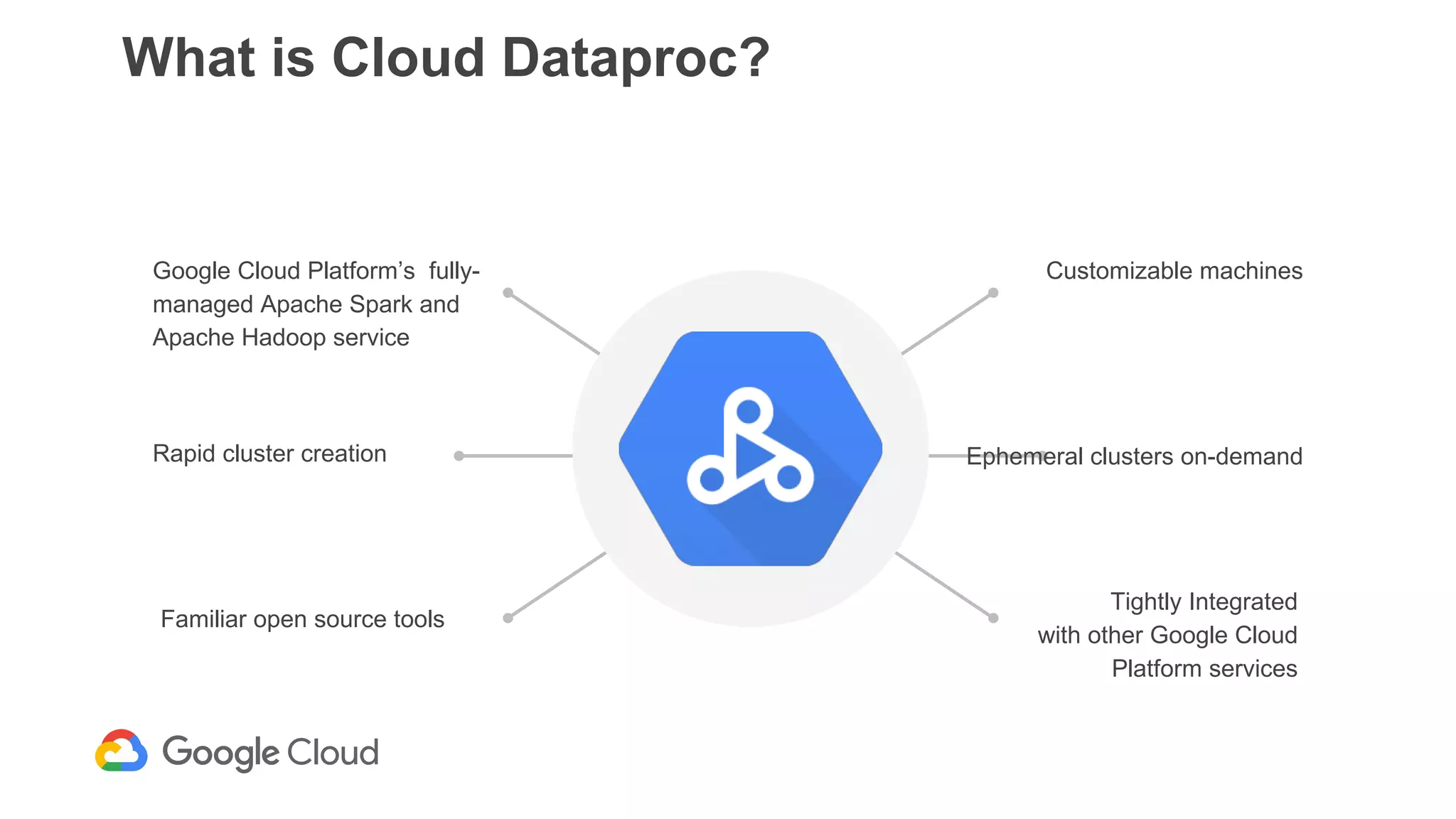

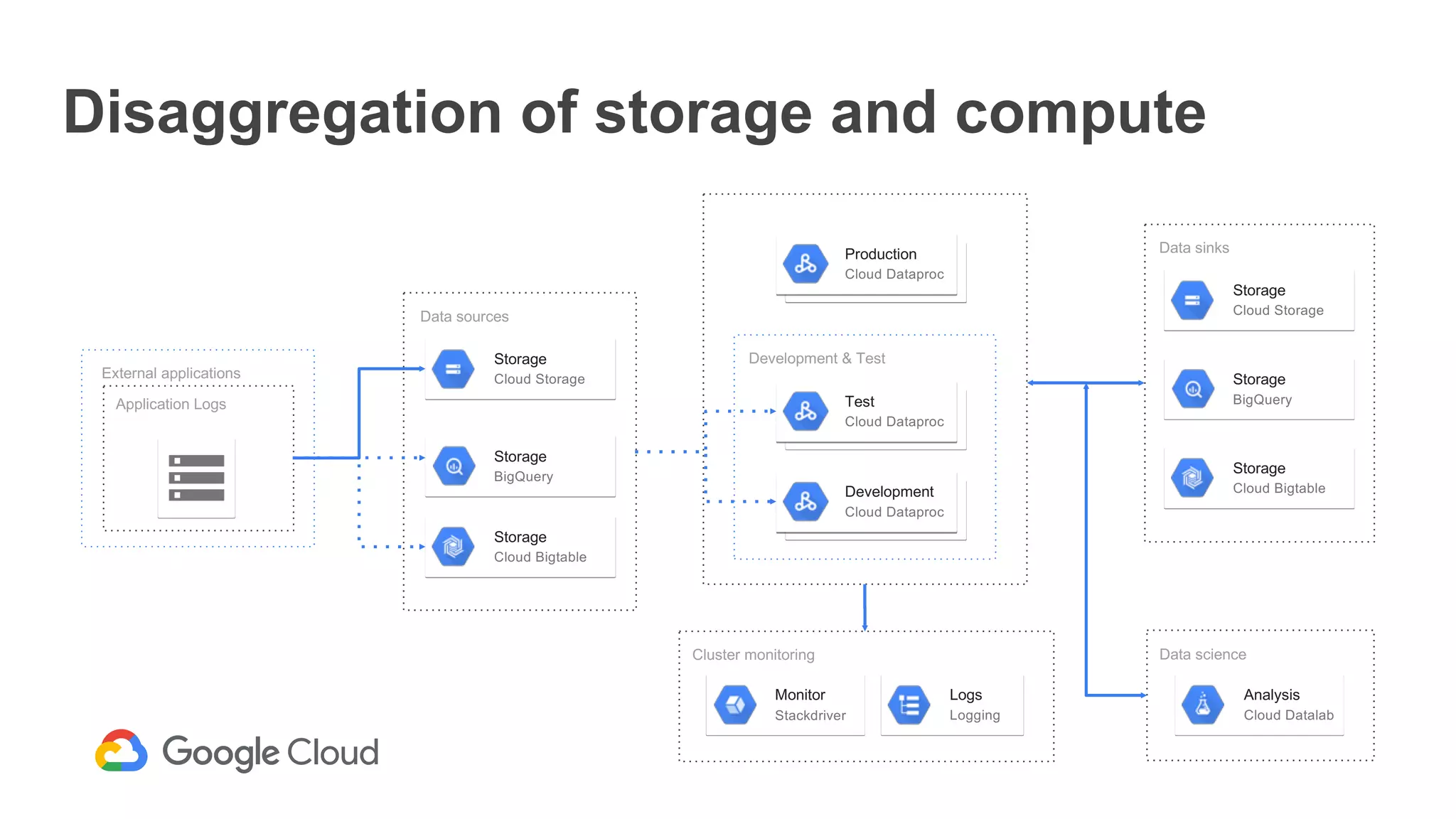
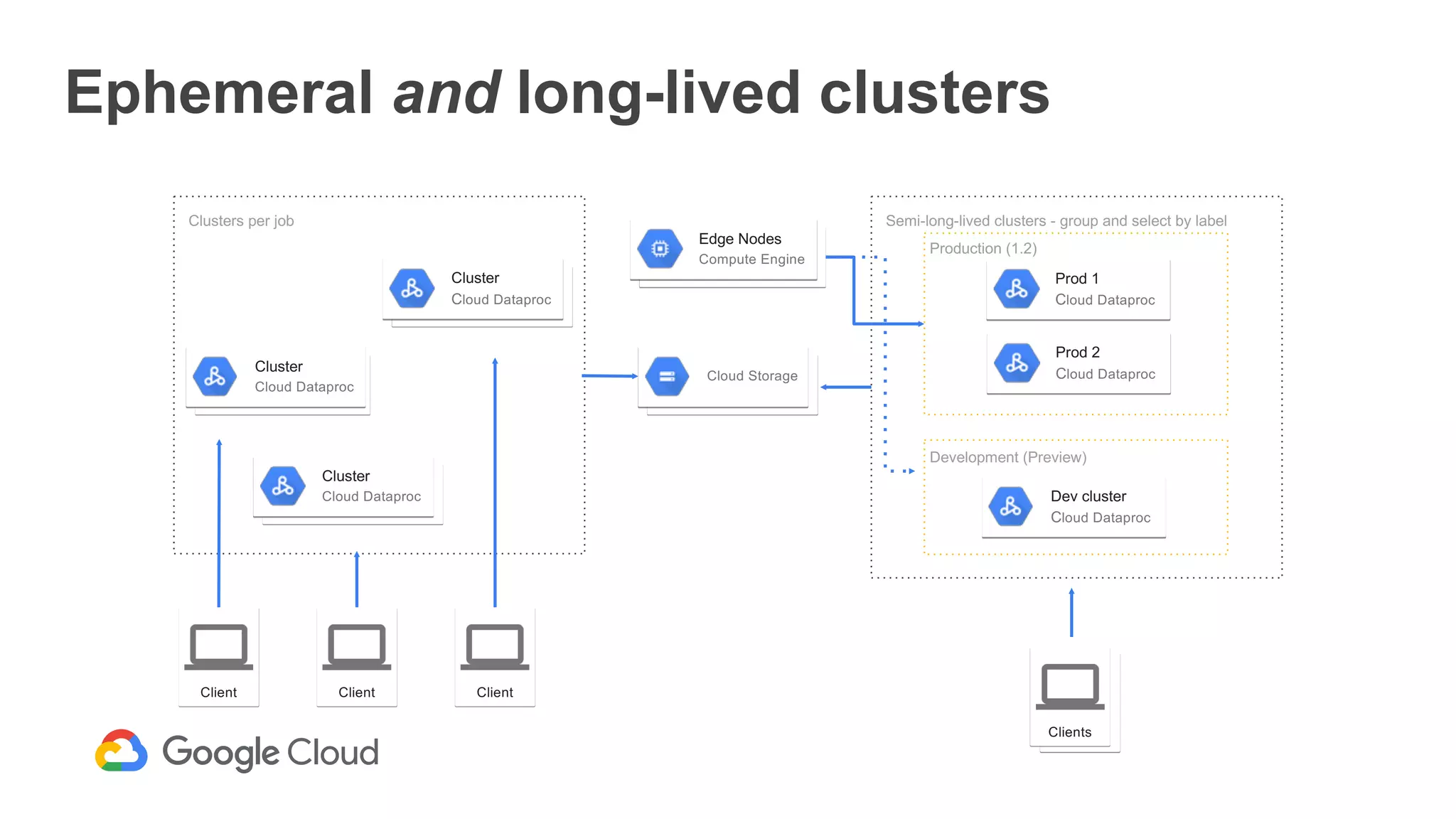

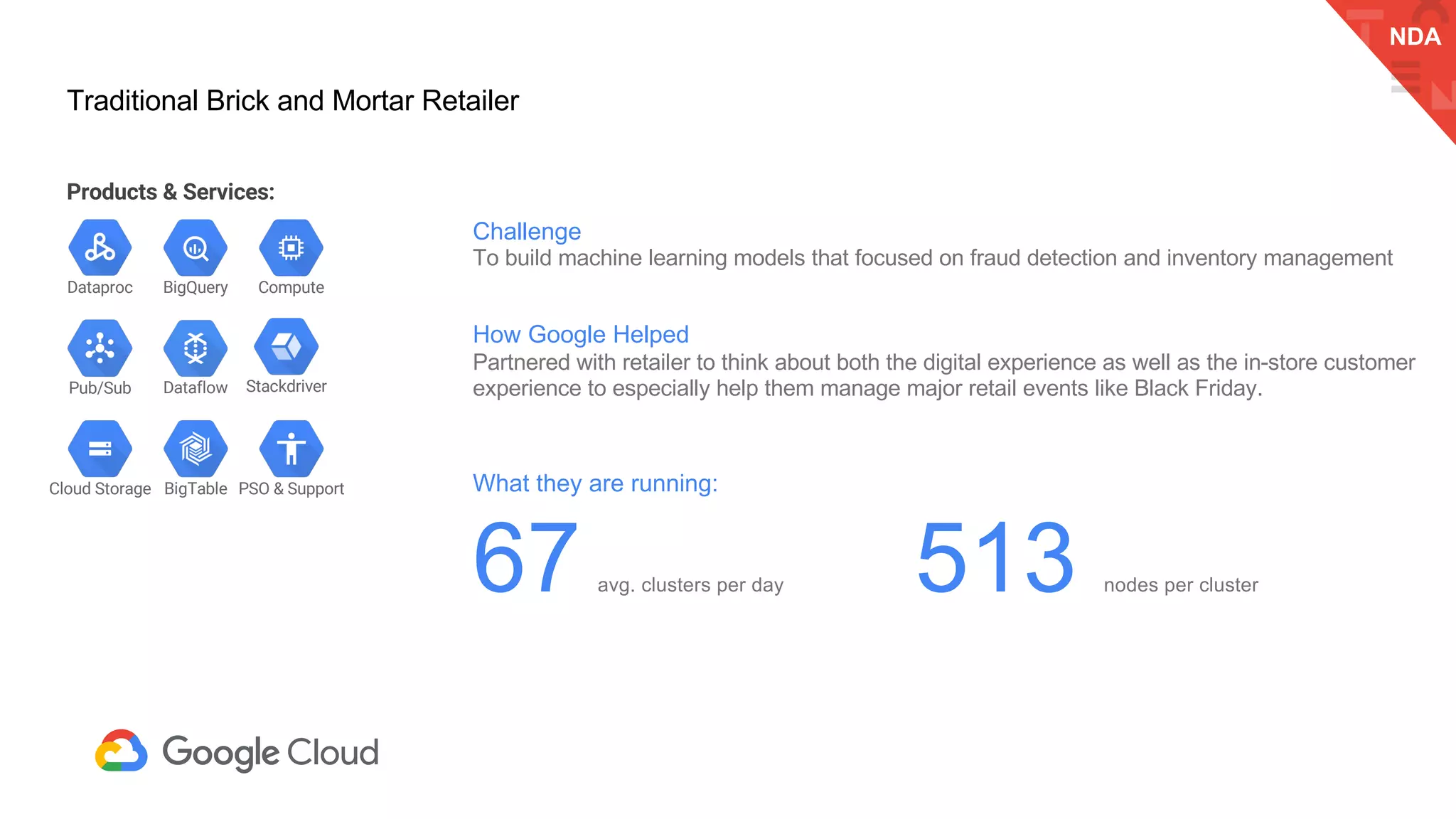





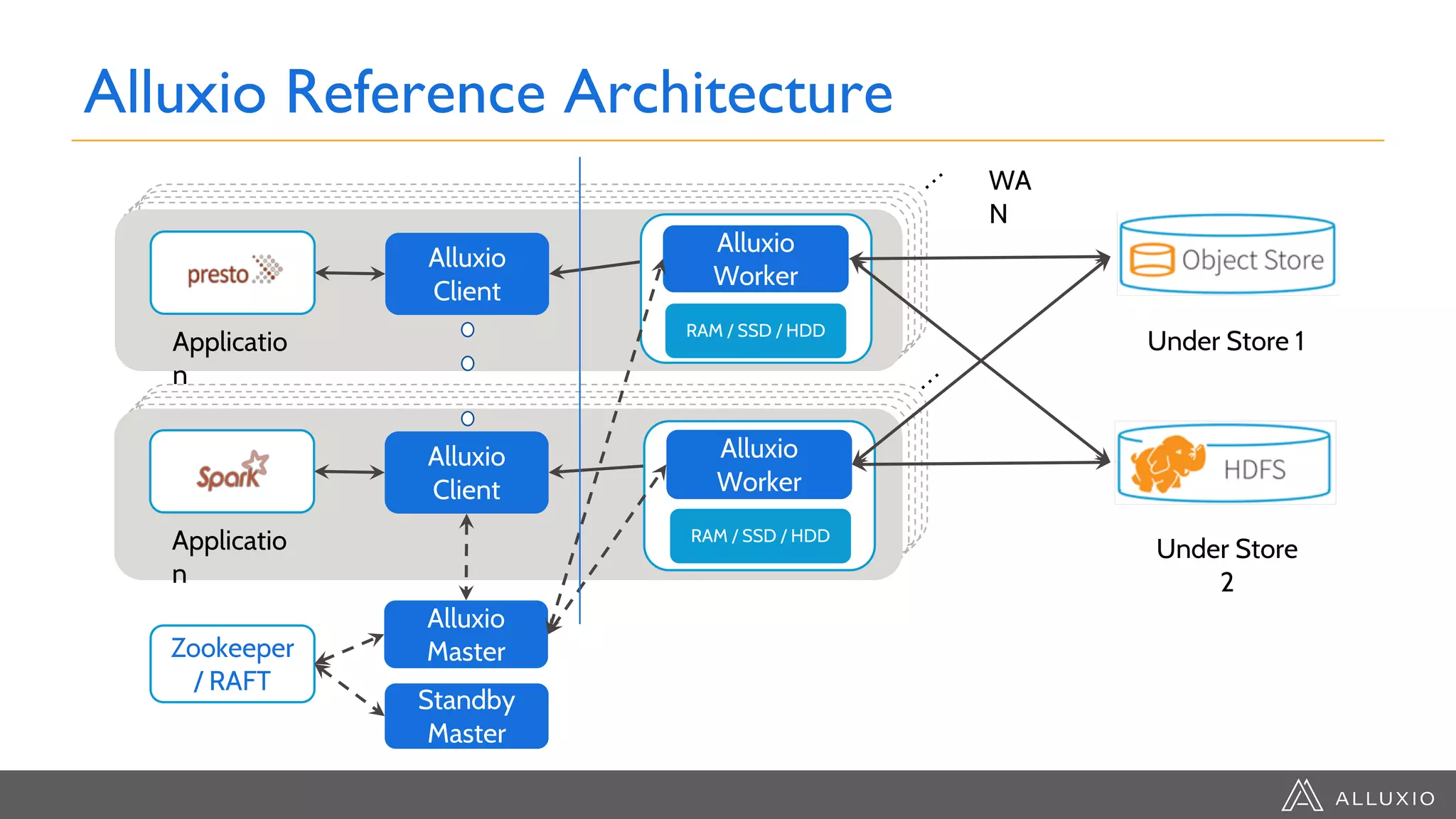
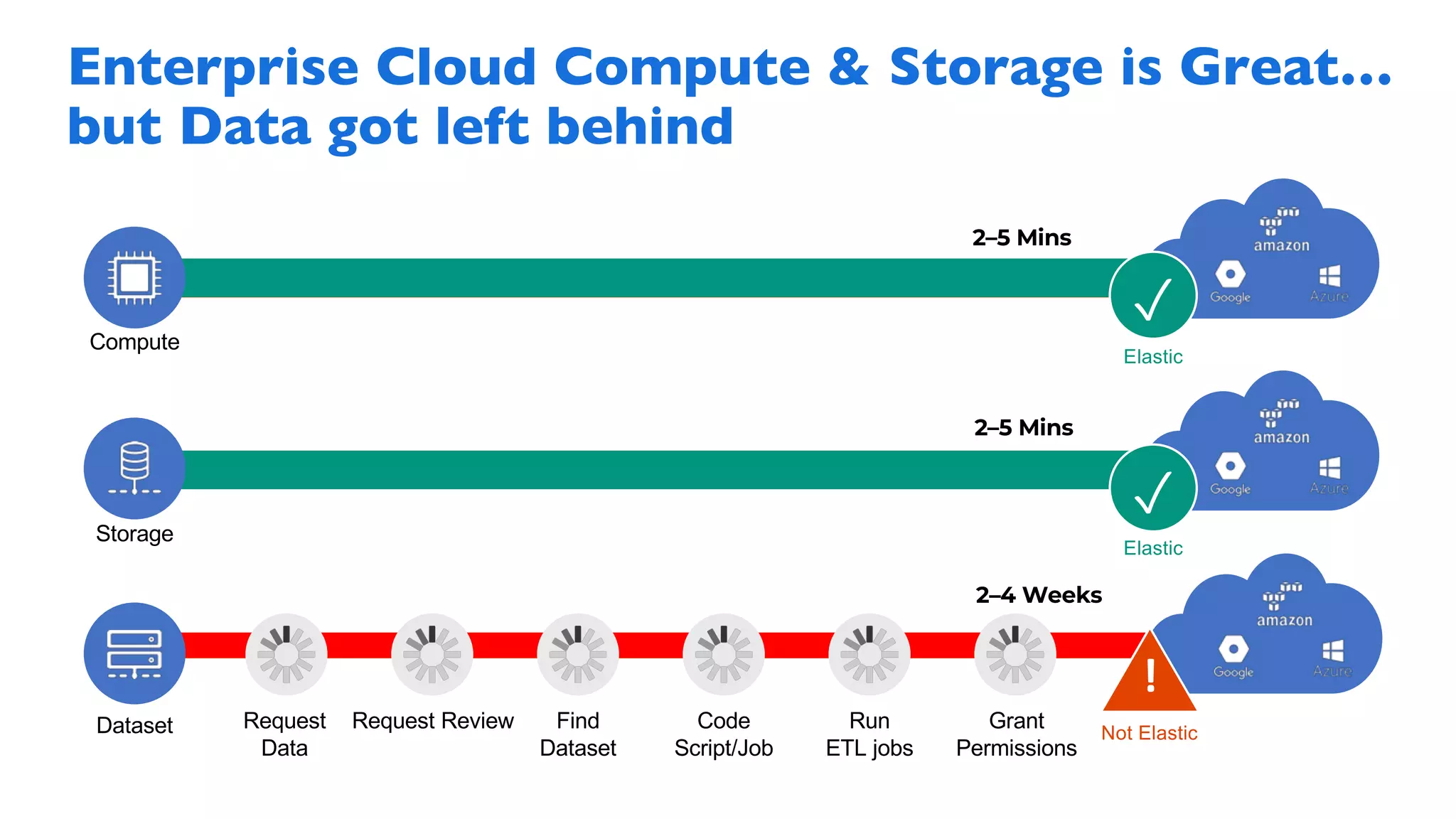
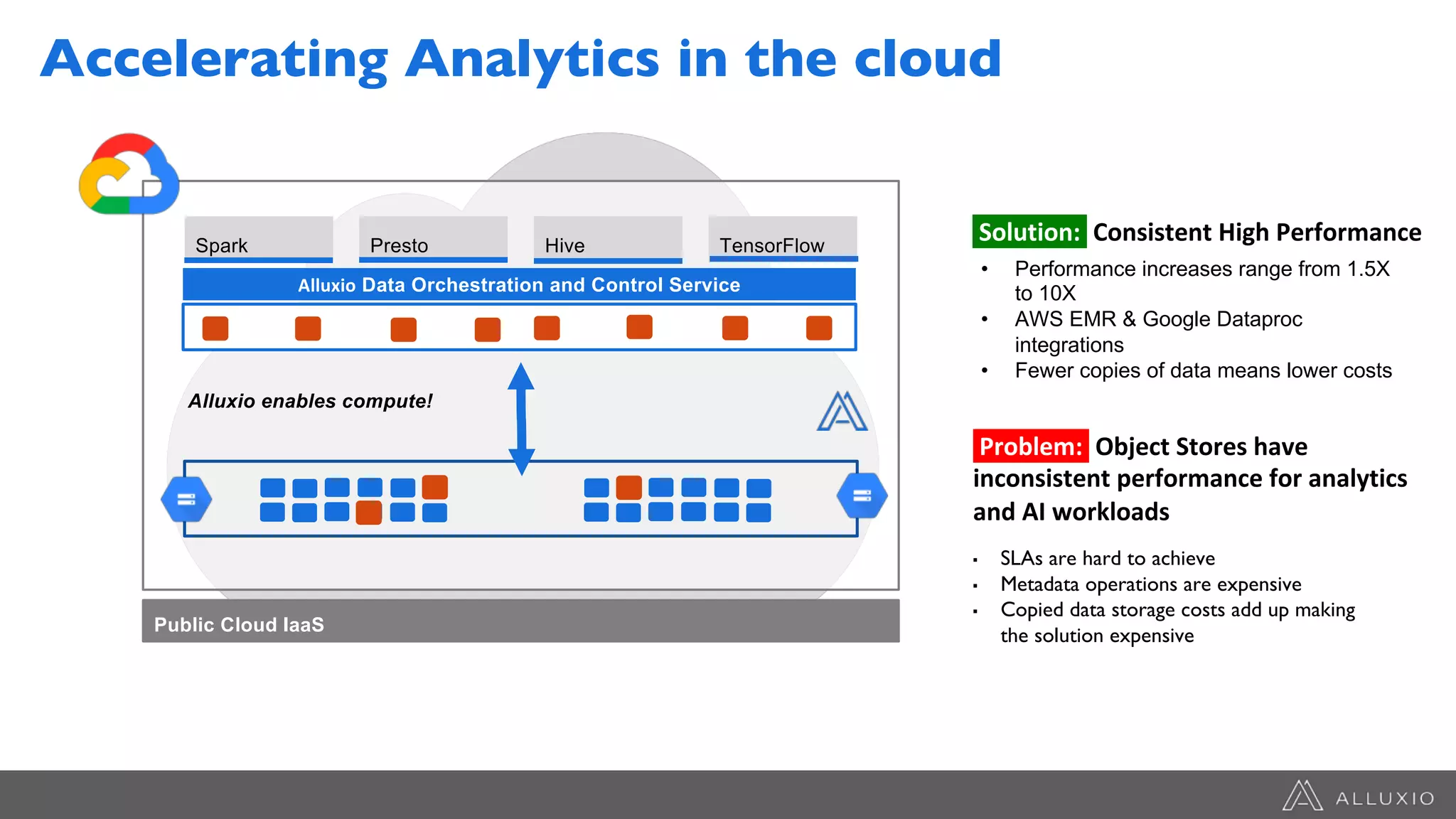
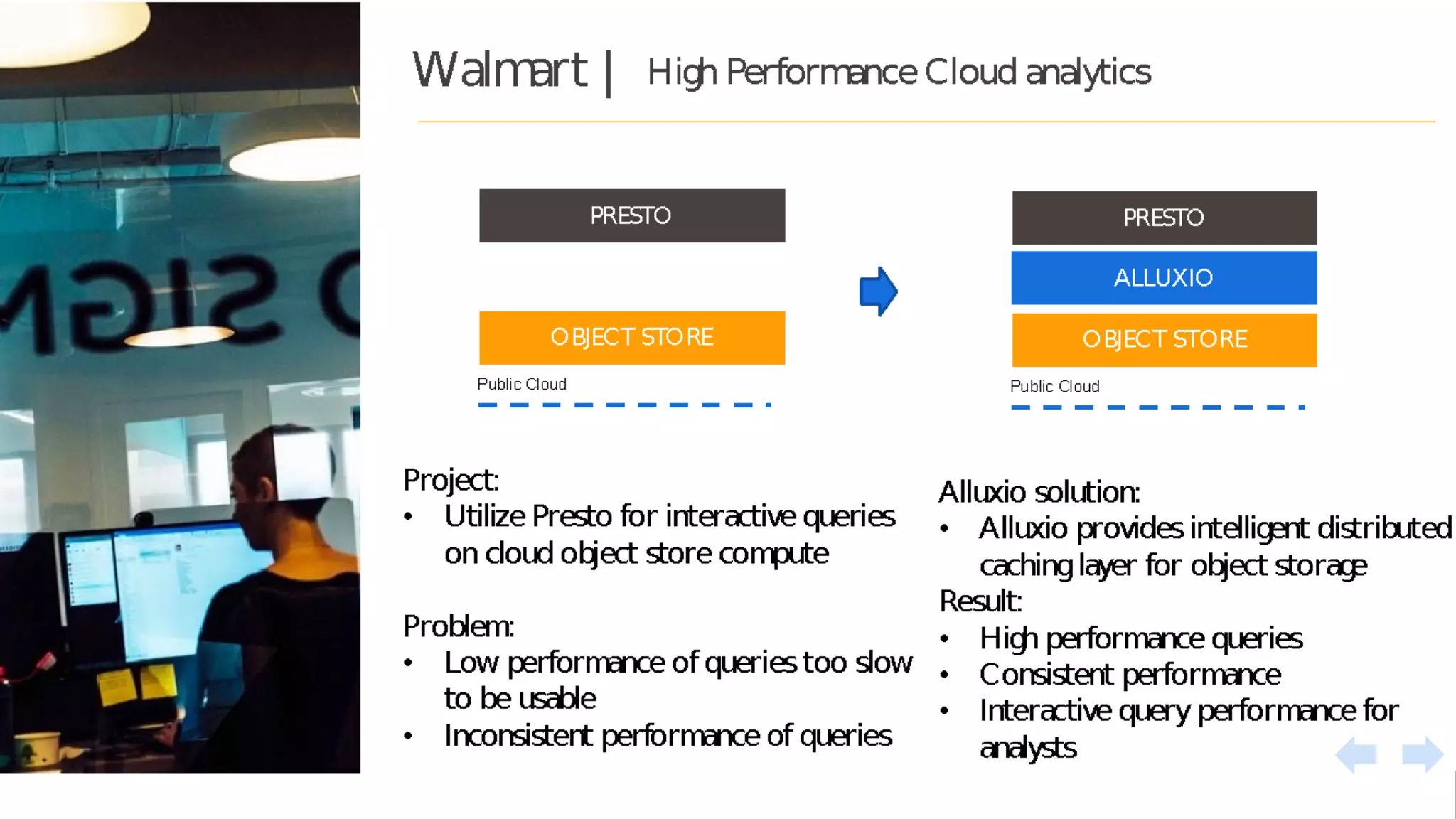
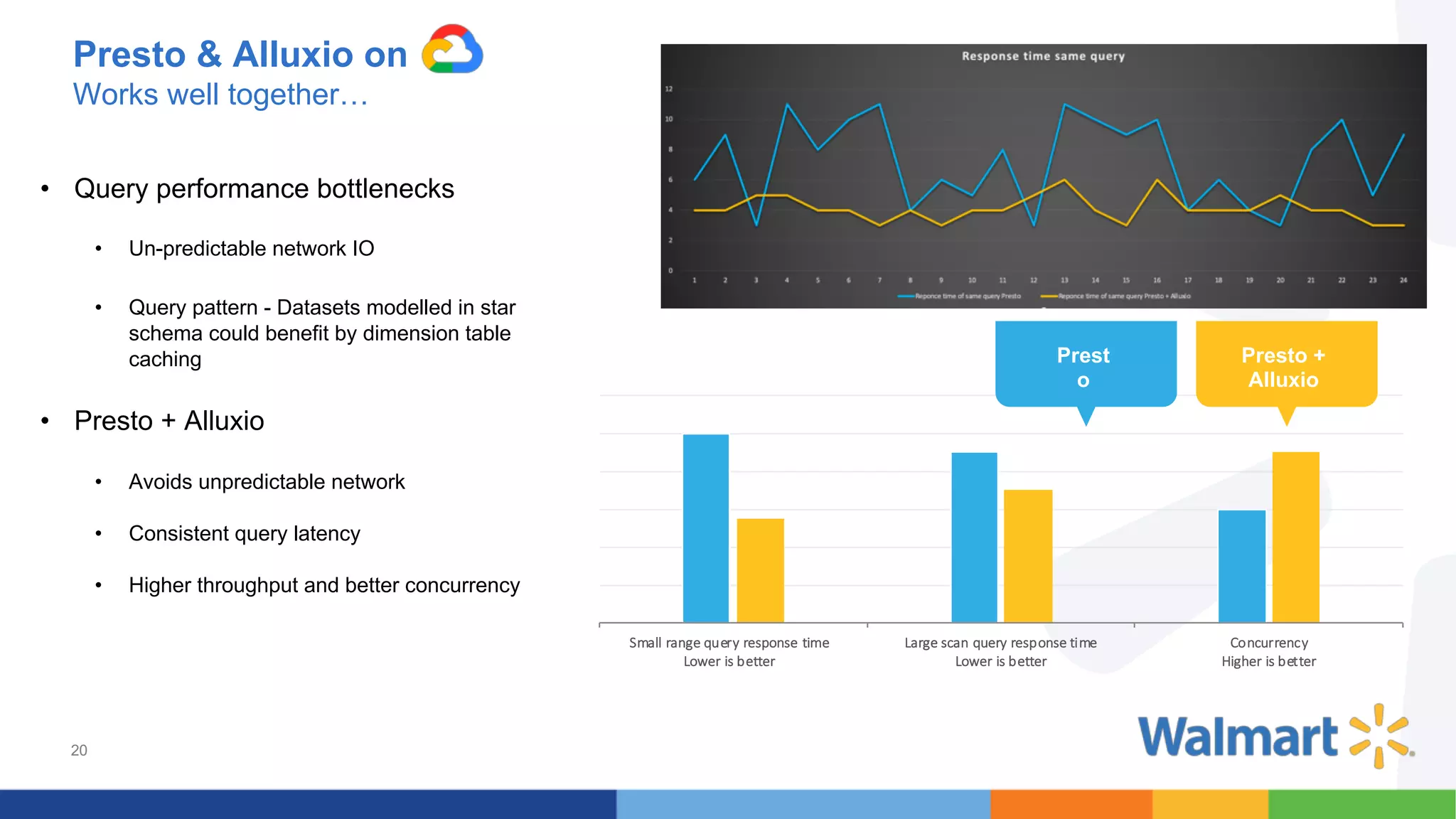

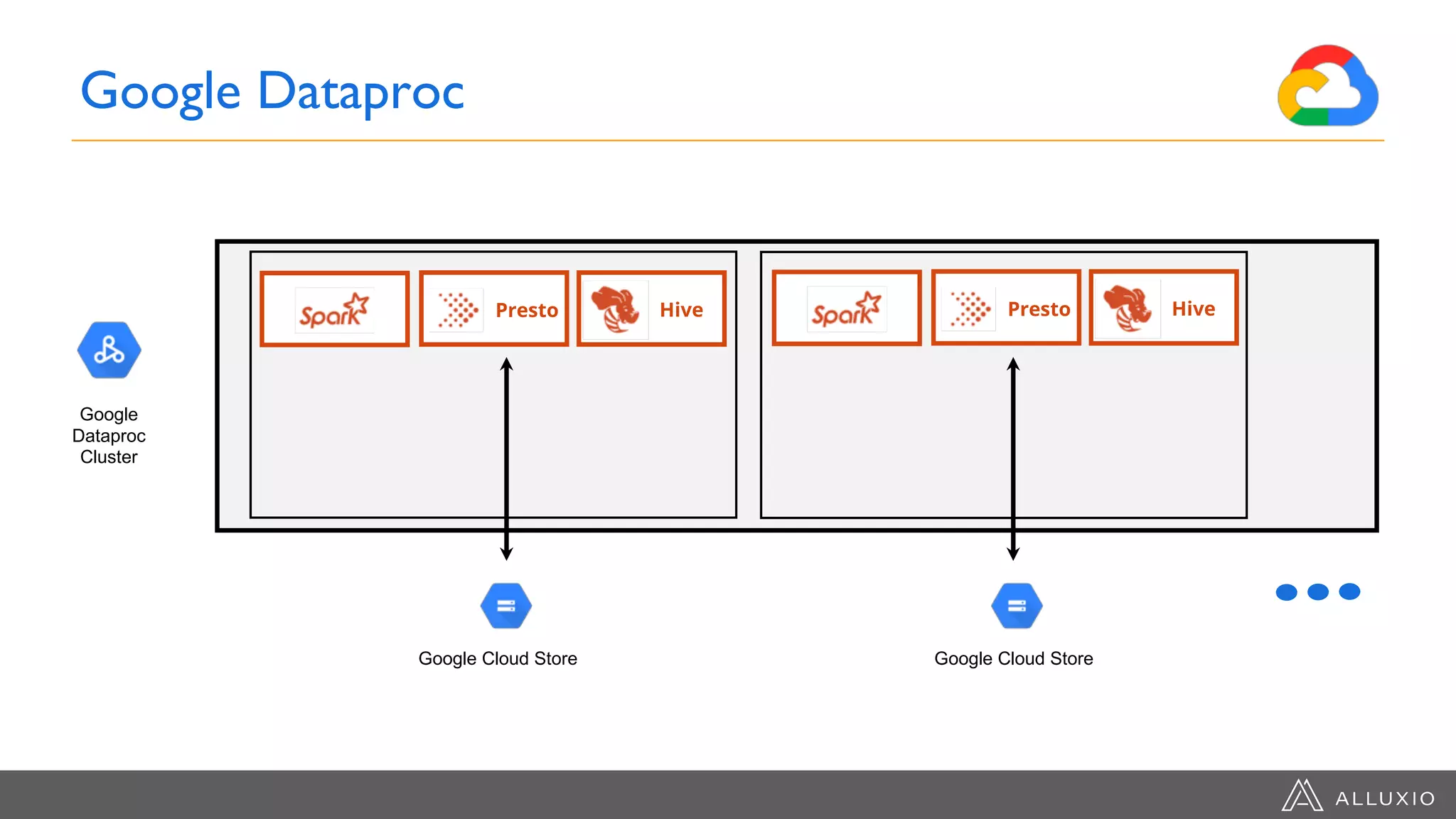
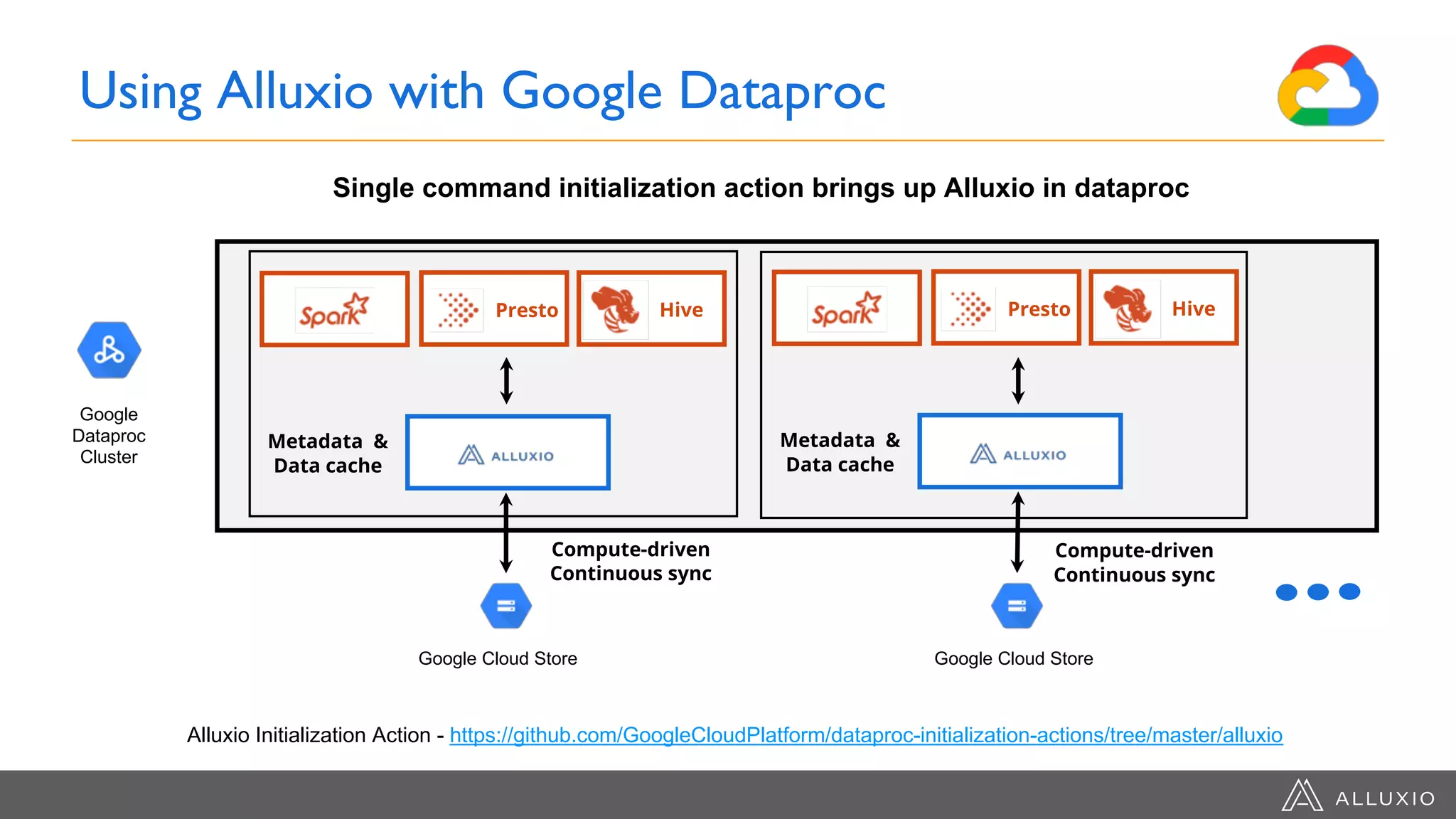


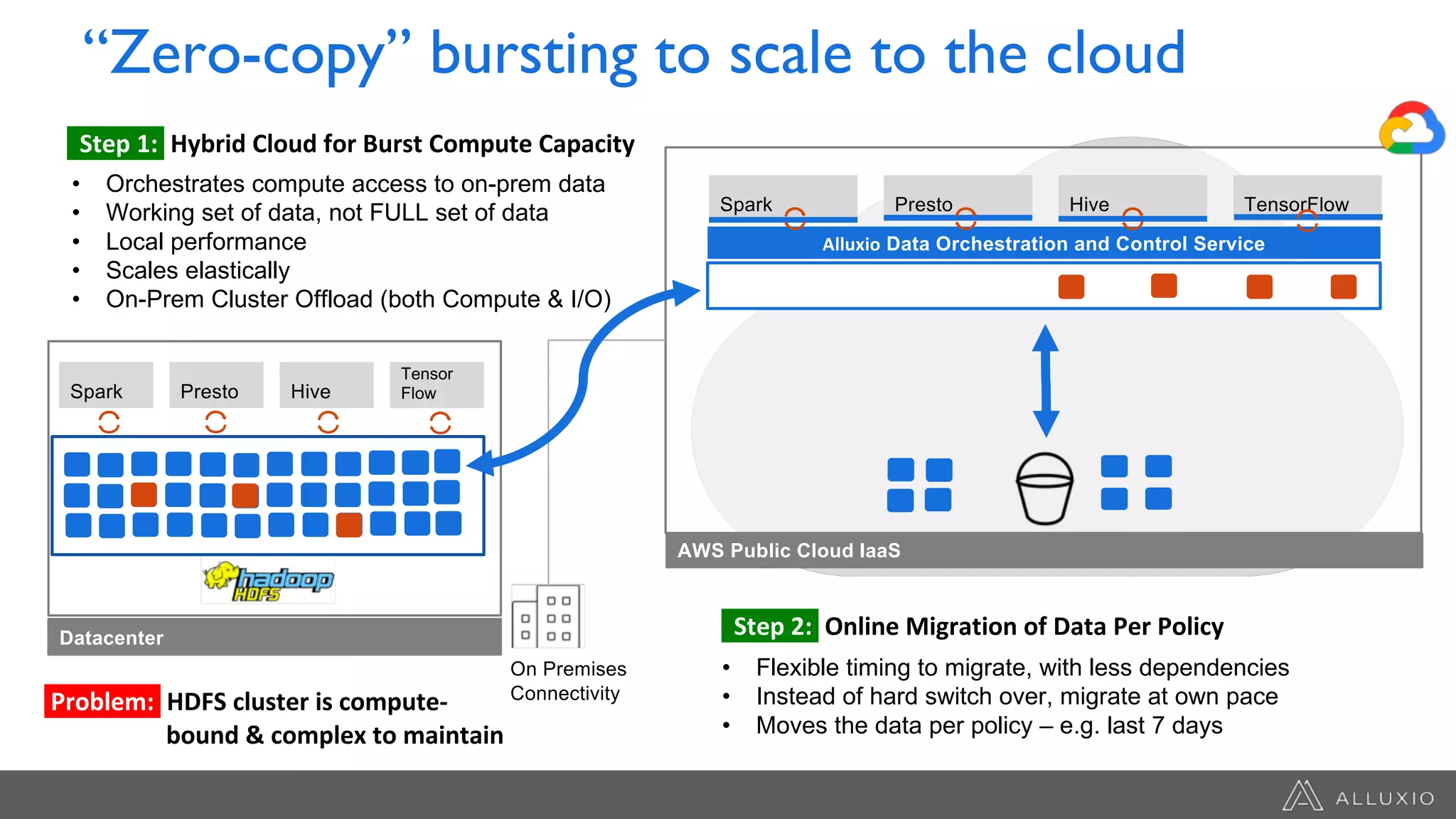
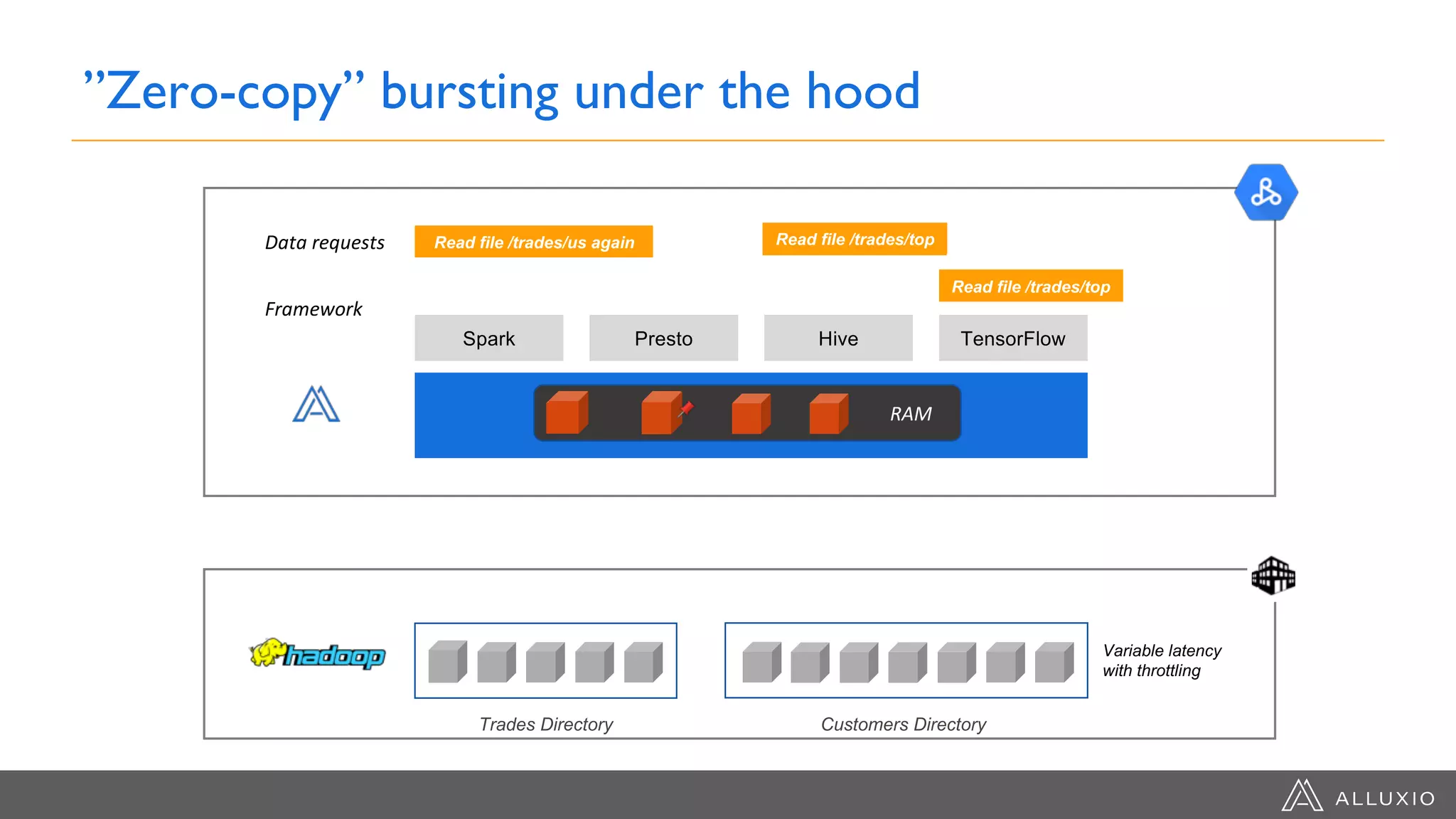


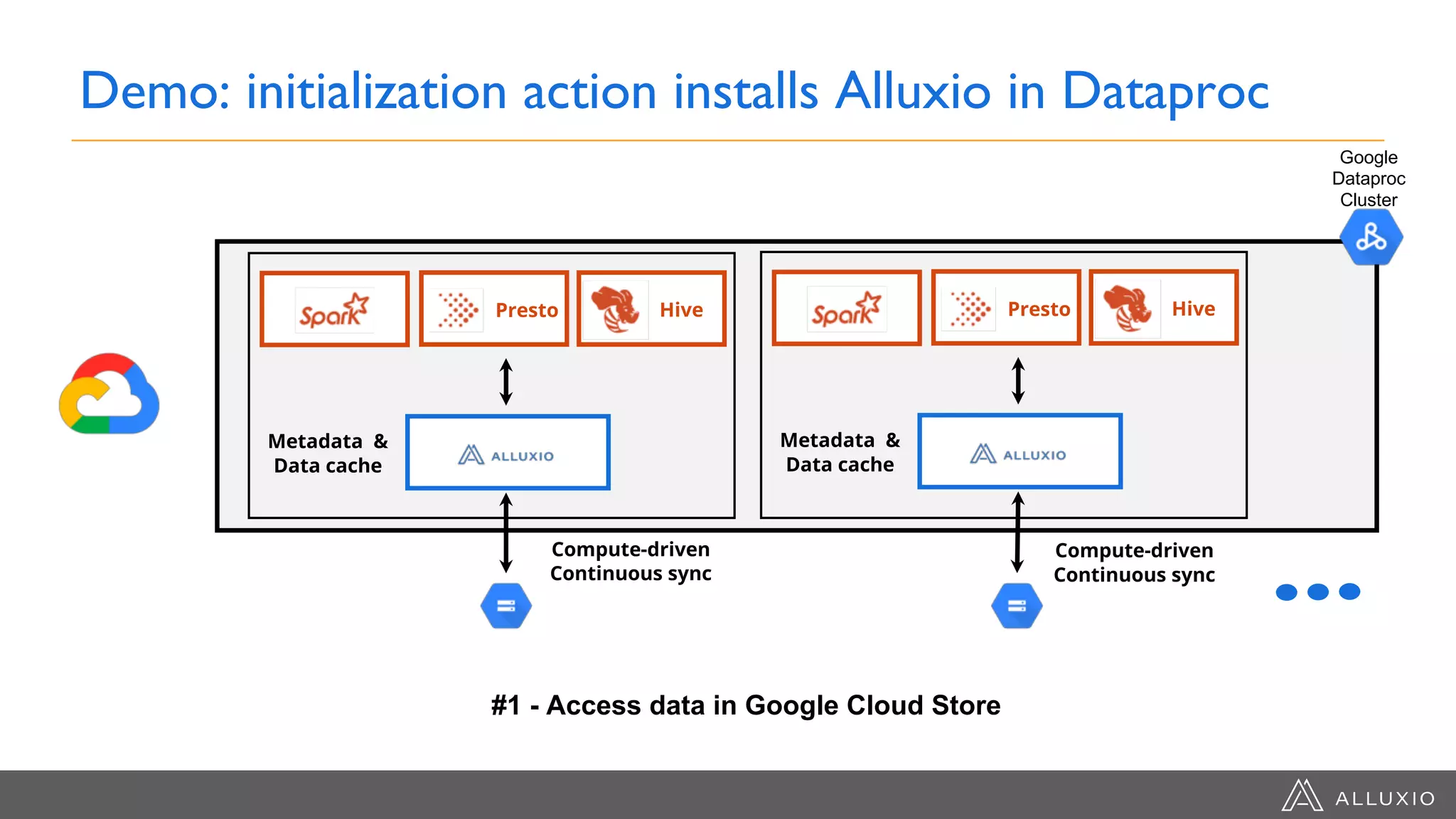
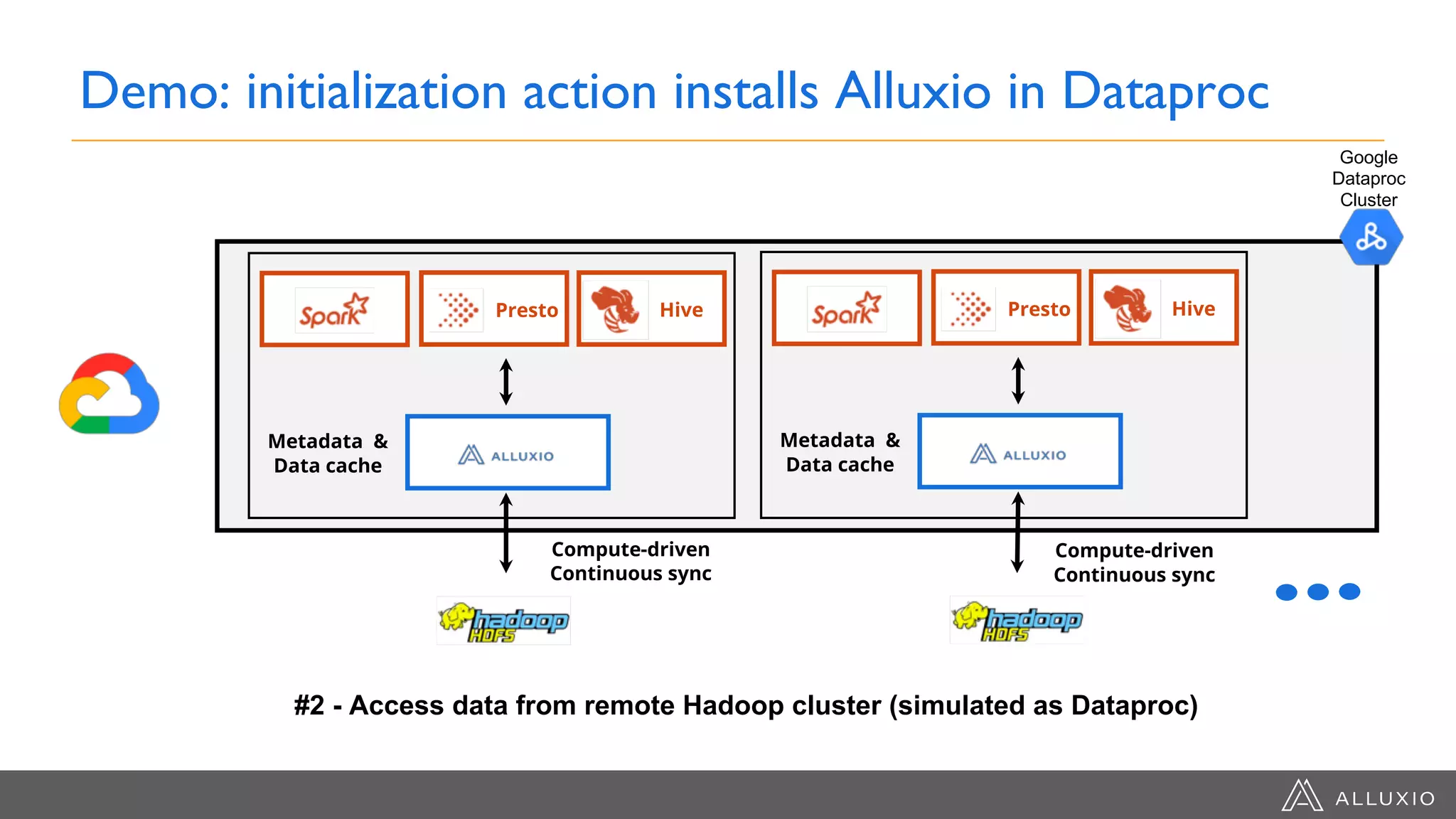
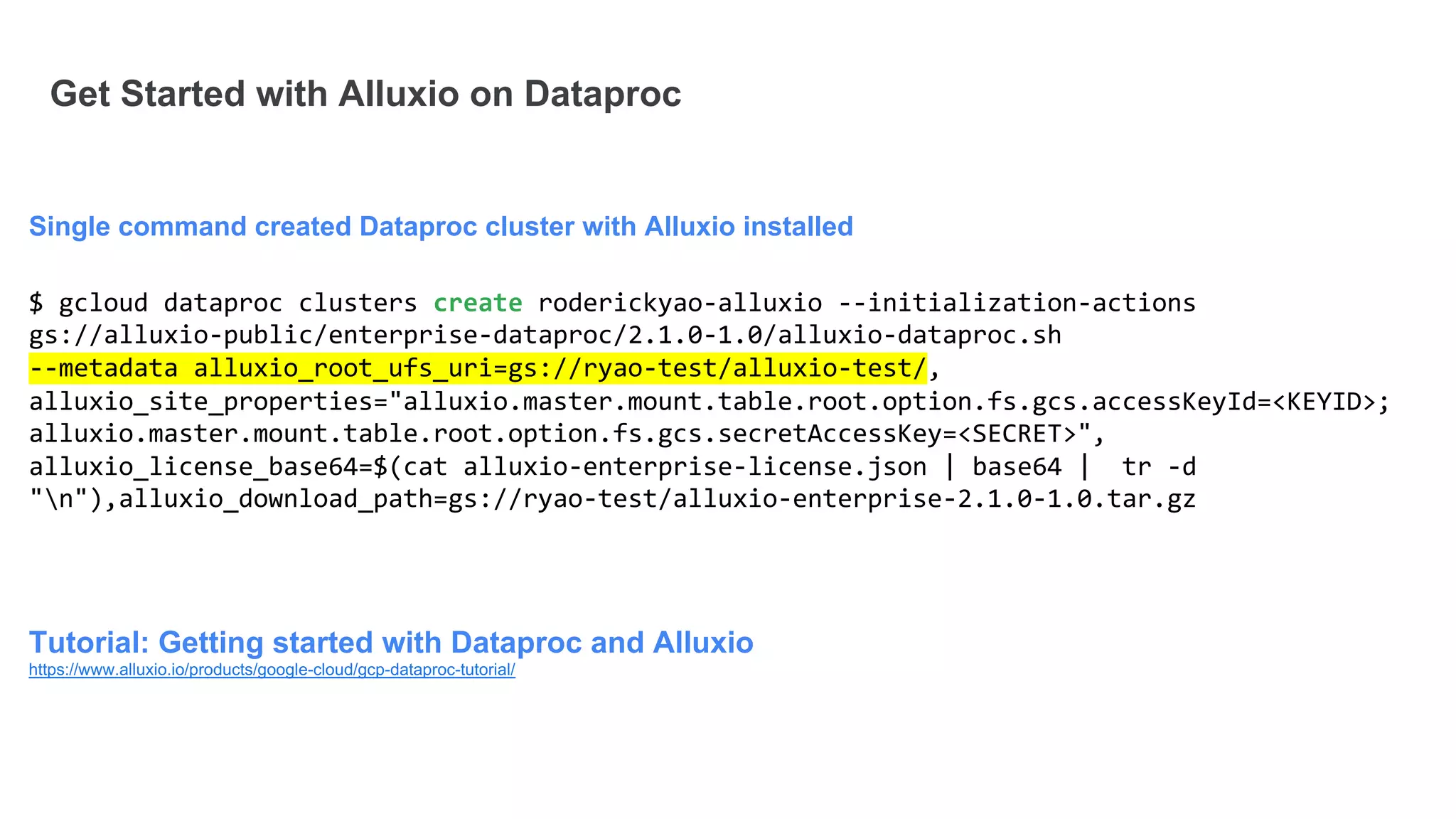



The document discusses the integration of Google Dataproc and Alluxio to accelerate data workloads, enabling enterprises to rapidly create customizable Hadoop clusters for varying business needs. It highlights the benefits of ephemeral clusters, cost efficiency, and the orchestration of data for cloud-based analytics, which can enhance performance and reduce operational burdens. Additionally, it covers the implementation process, hybrid cloud capabilities, and provides resources for getting started with Dataproc and Alluxio.























































































