Downloaded 69 times






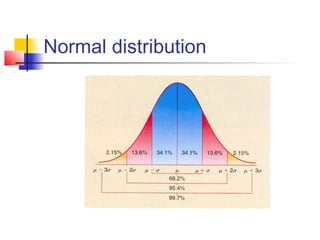


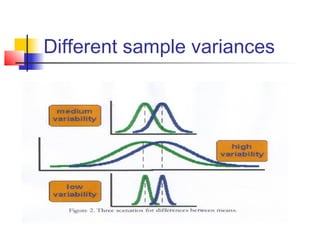
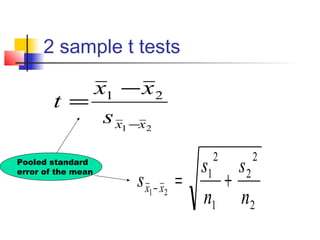

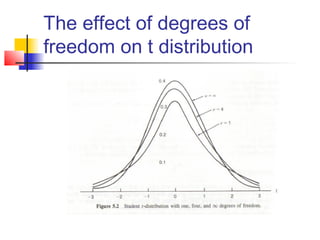

![T tests in SPM: Did the observed signal
change occur by chance or is it stat.
significant?
Recall GLM. Y= X β + ε
β1 is an estimate of signal change over time
attributable to the condition of interest
Set up contrast (cT) 1 0 for β1: 1xβ1+0xβ2+0xβn/s.d
Null hypothesis: cTβ=0 No significant effect at each
voxel for condition β1
Contrast 1 -1 : Is the difference between 2 conditions
significantly non-zero?
t = cTβ/sd[cTβ] – 1 sided](https://image.slidesharecdn.com/t-testsanovasandregression-130322162201-phpapp01/85/T-tests-anovas-and-regression-14-320.jpg)


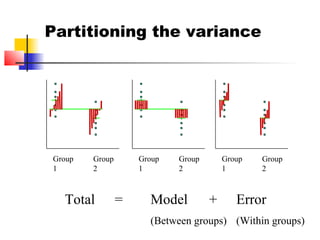







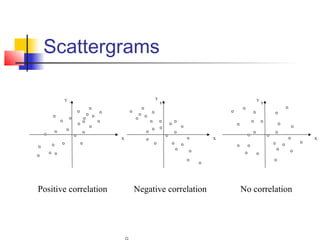


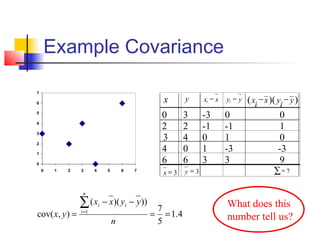
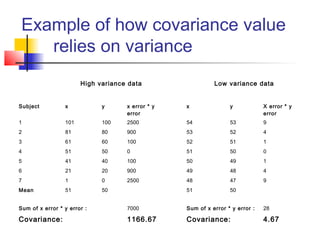



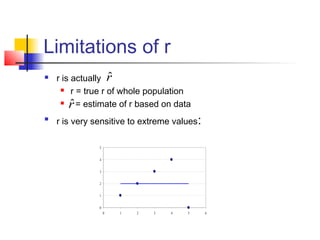


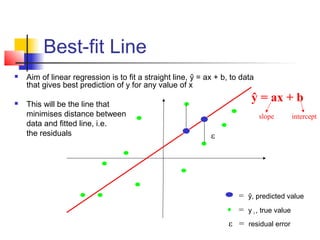

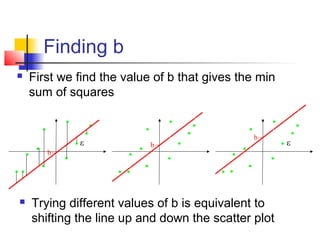
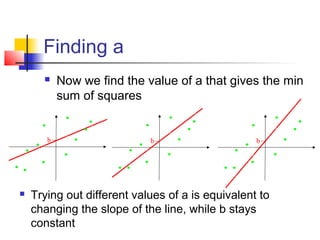
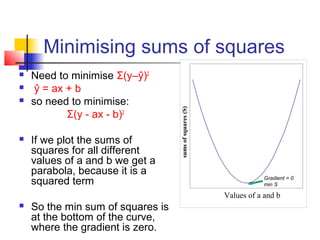












This document provides an overview of statistical tests commonly used in neuroimaging such as t-tests, ANOVAs, and regression. It discusses the purposes of these tests and how they are applied. T-tests are used to compare means, for example to determine if the difference between two conditions is statistically significant. ANOVAs examine variances and can be used when comparing more than two groups. Regression allows describing and predicting the relationship between variables and is useful in the general linear model approach used in SPM. Key assumptions and calculations for each method are outlined.























































































