Downloaded 27 times




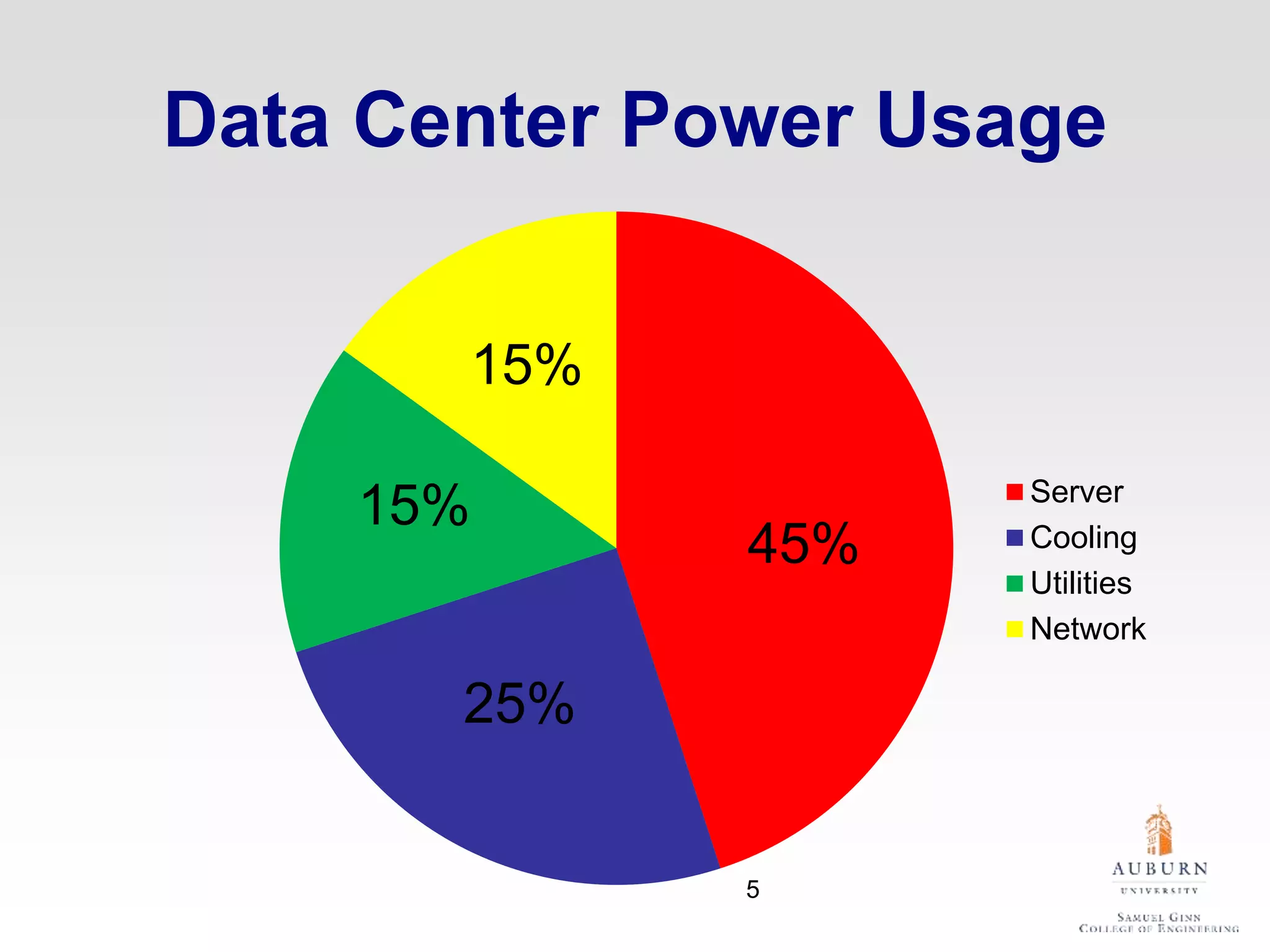
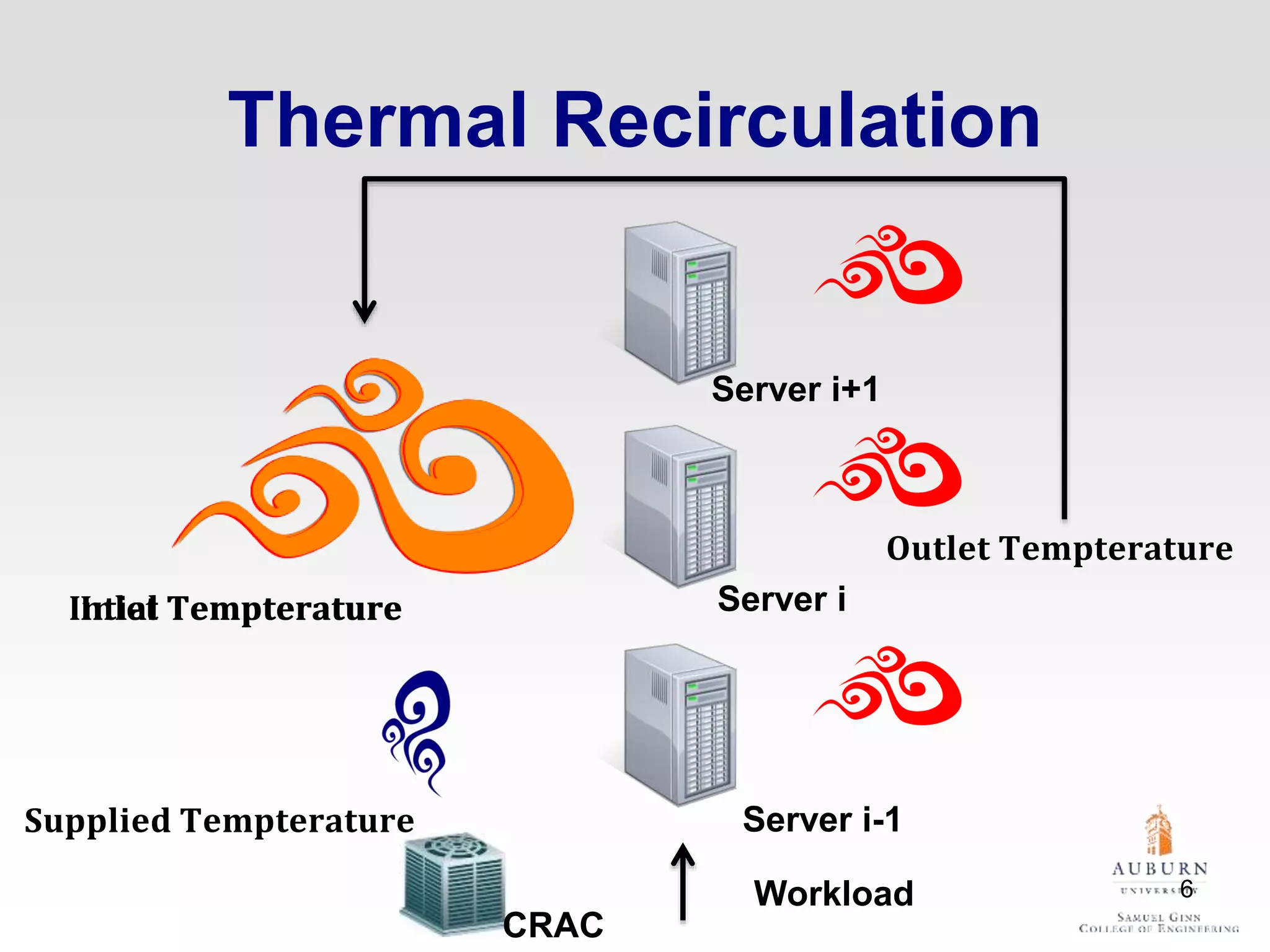



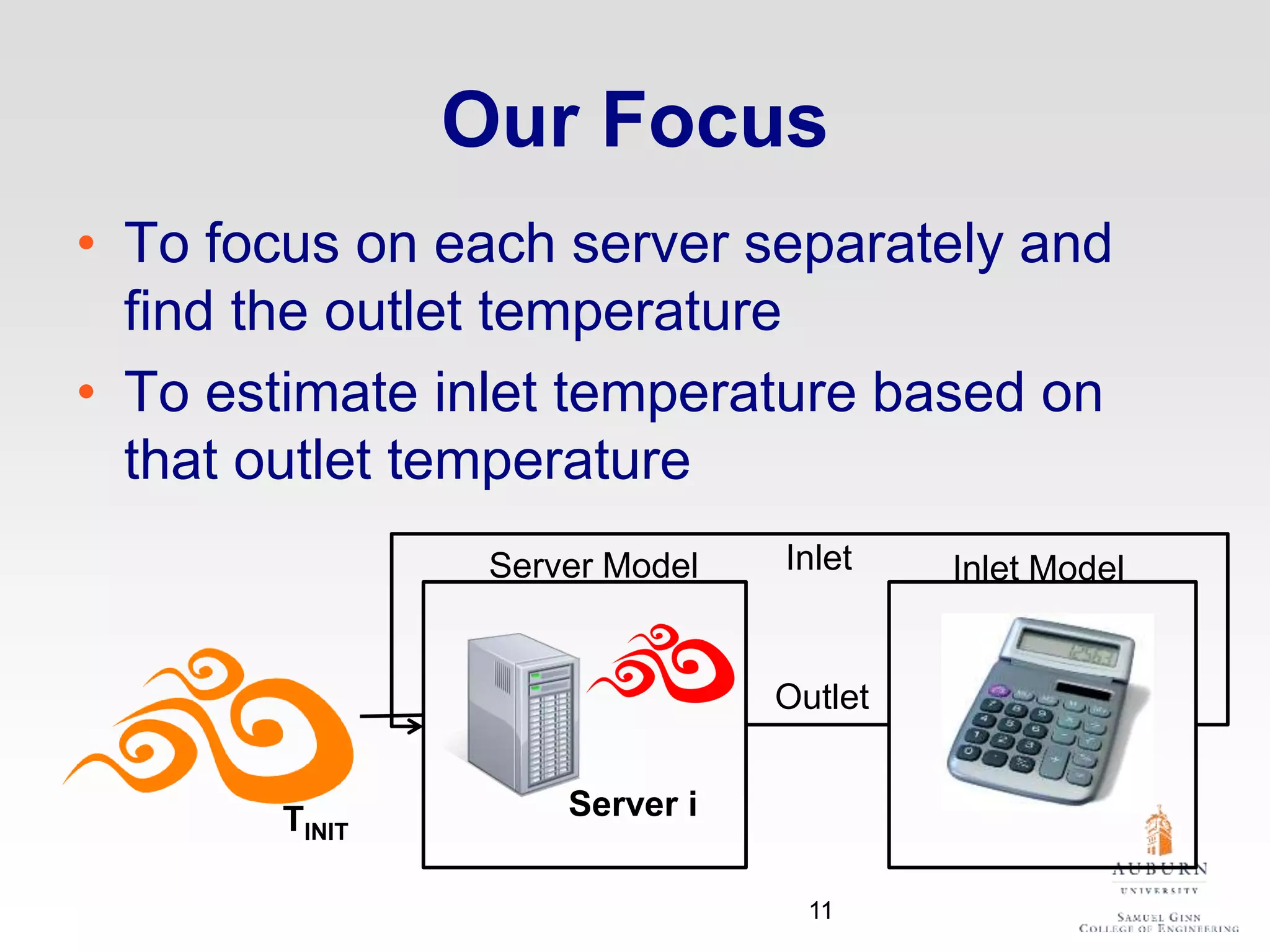
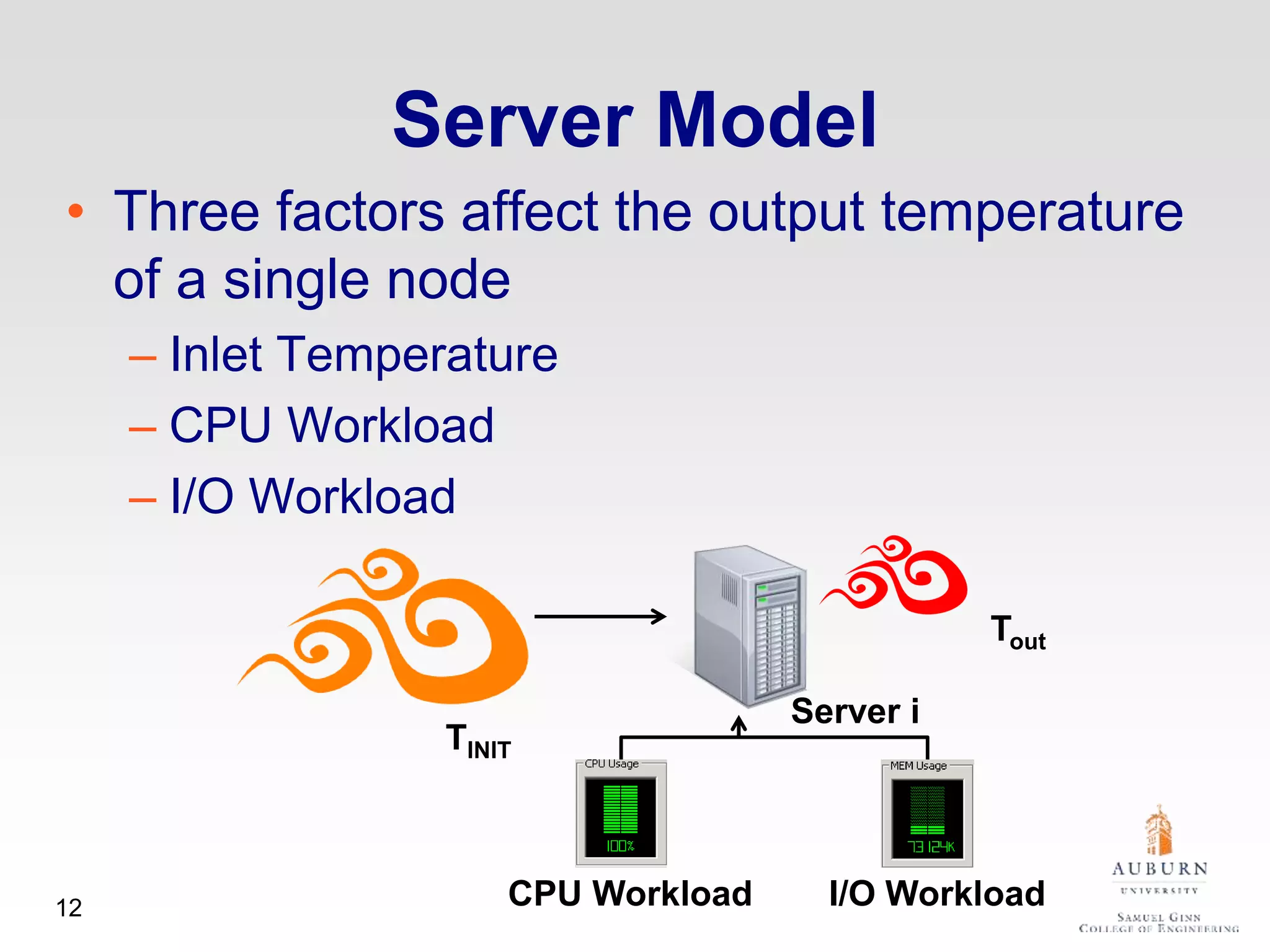
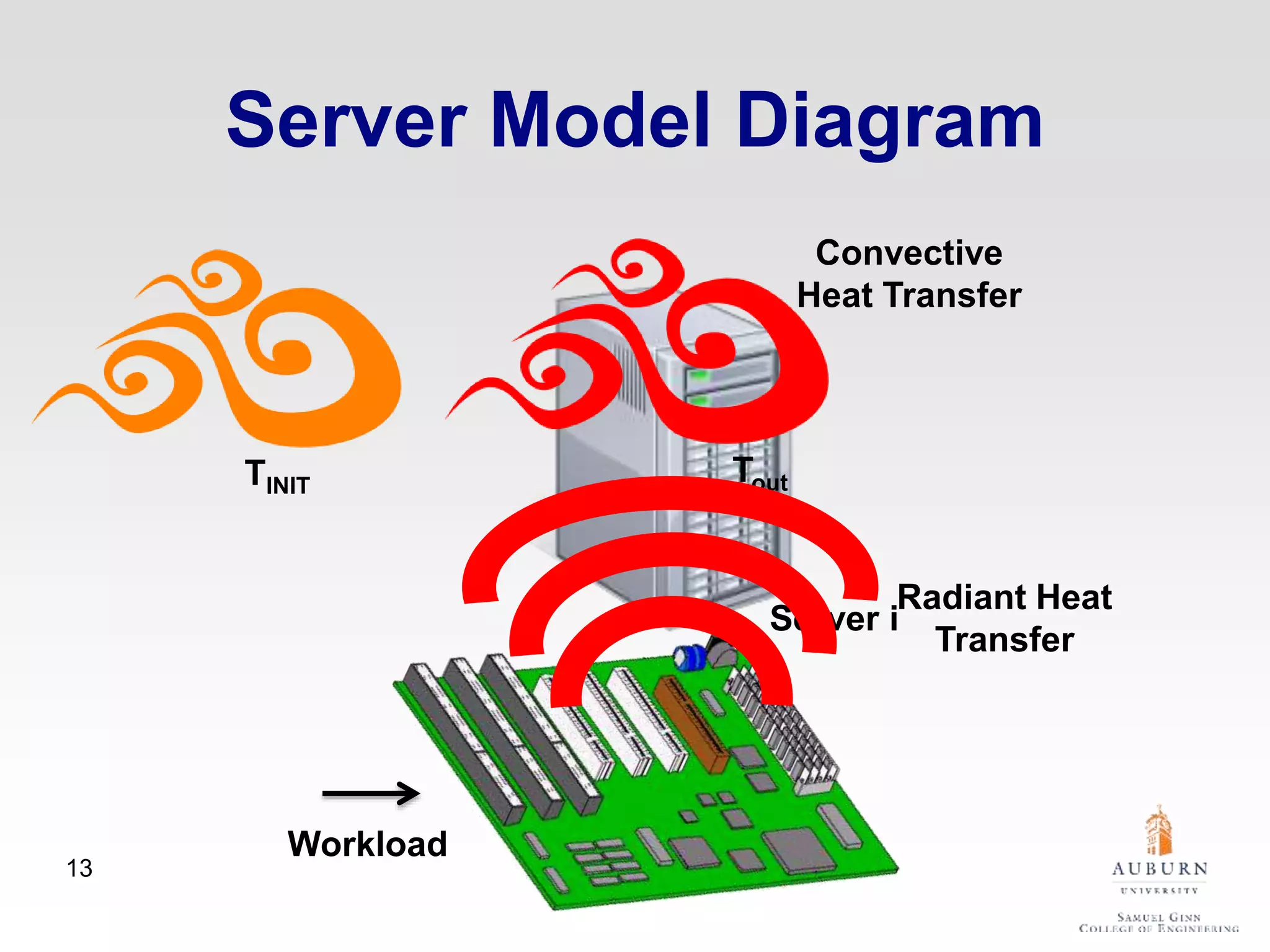


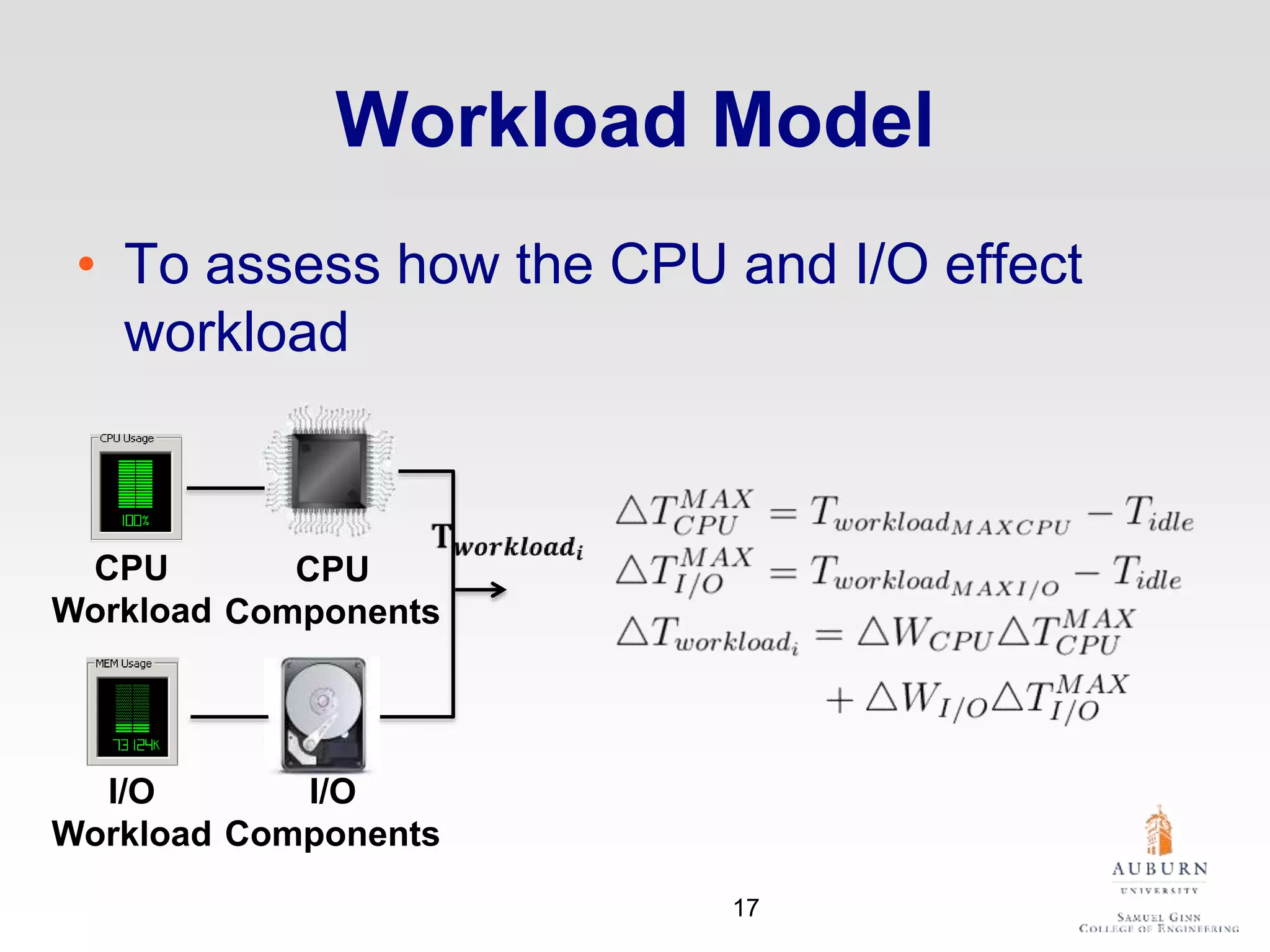




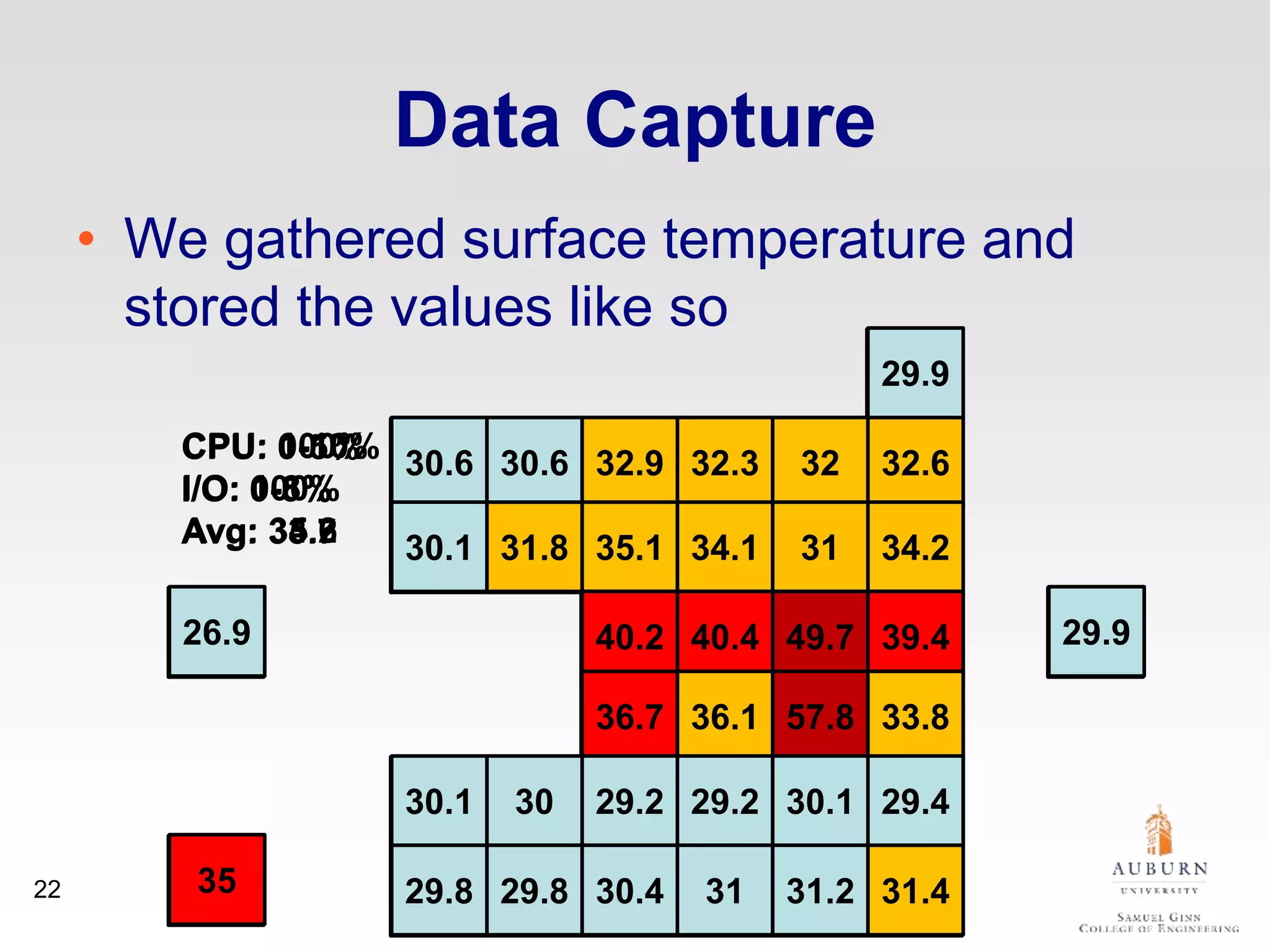
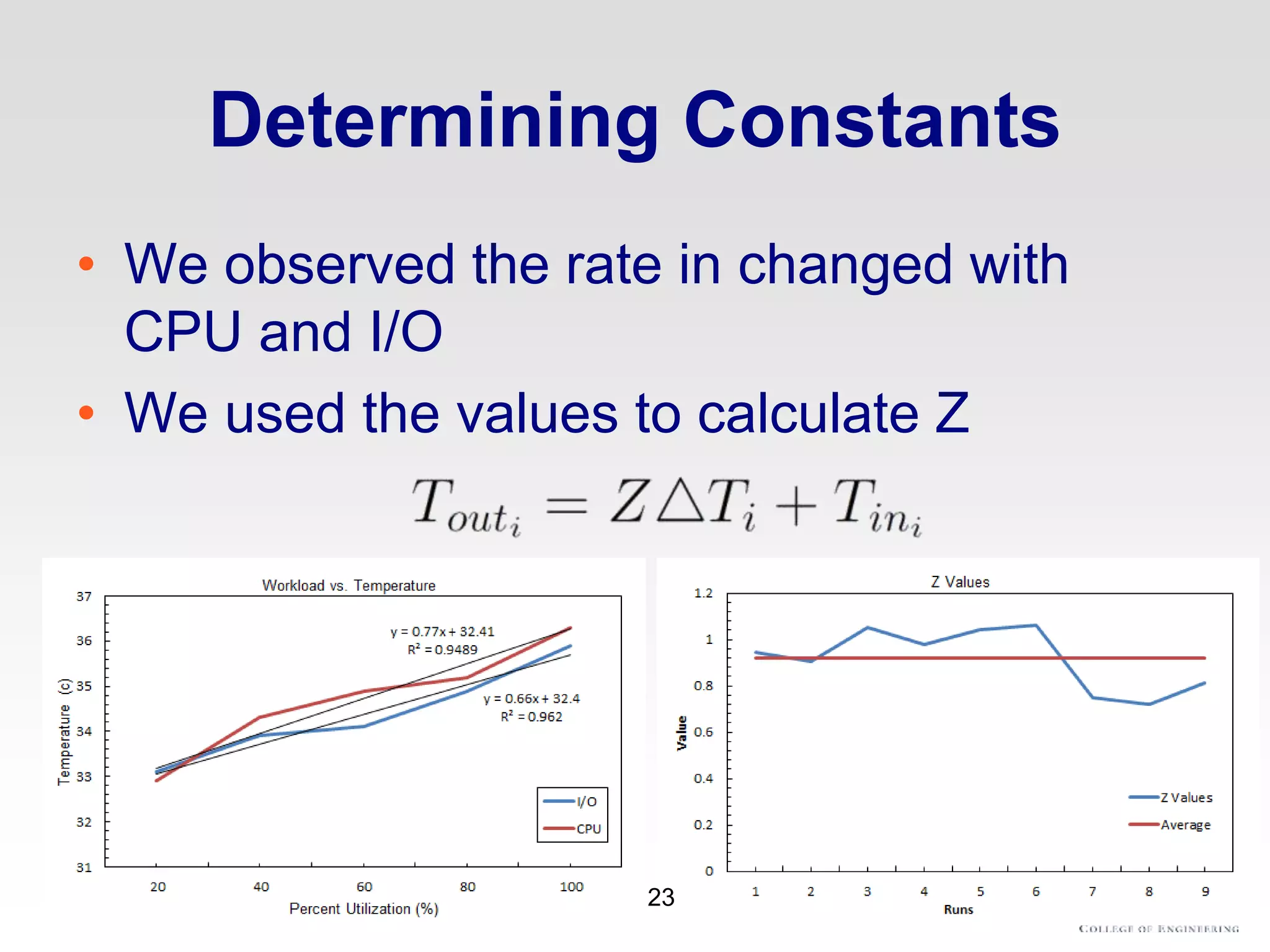
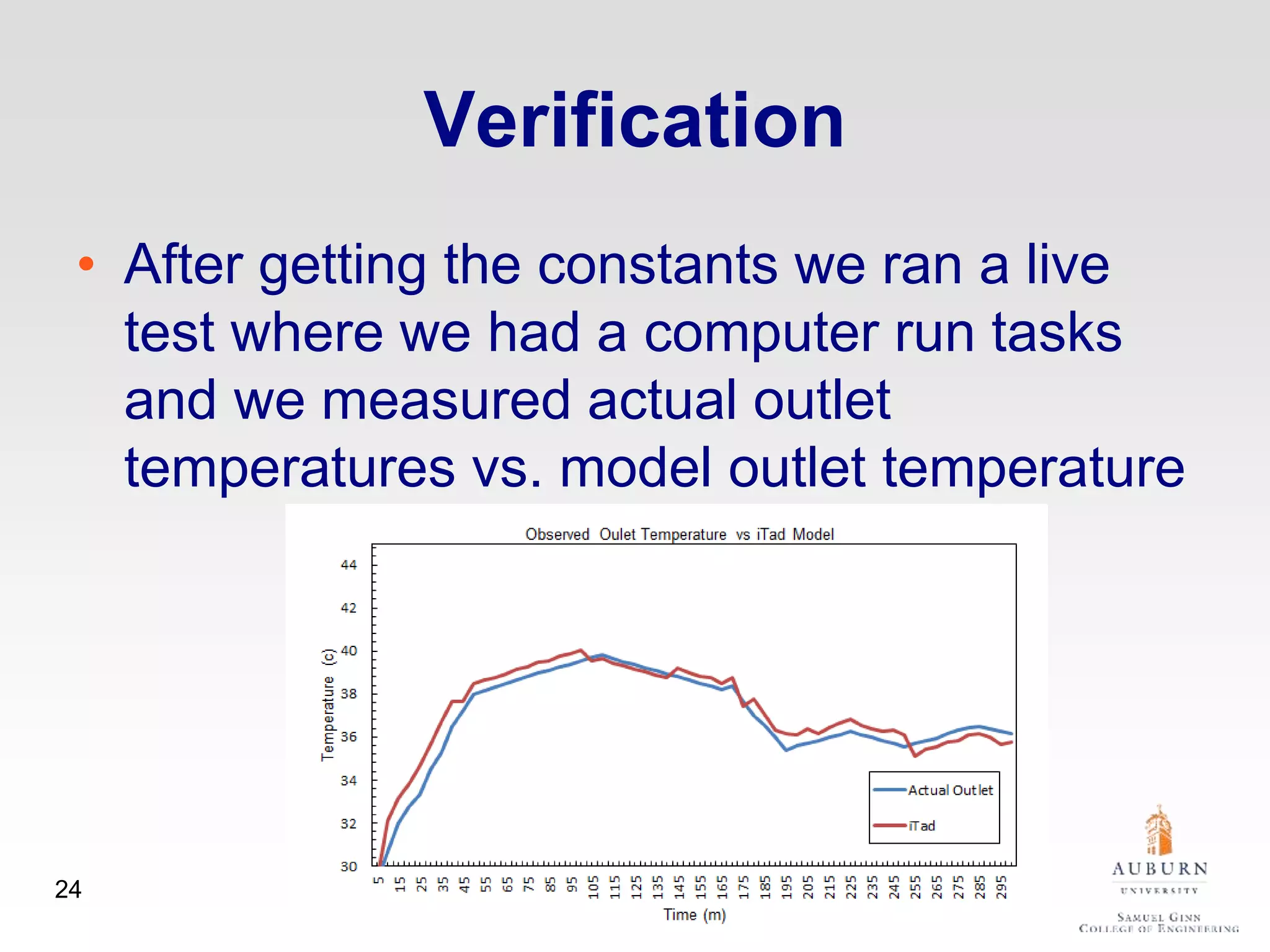

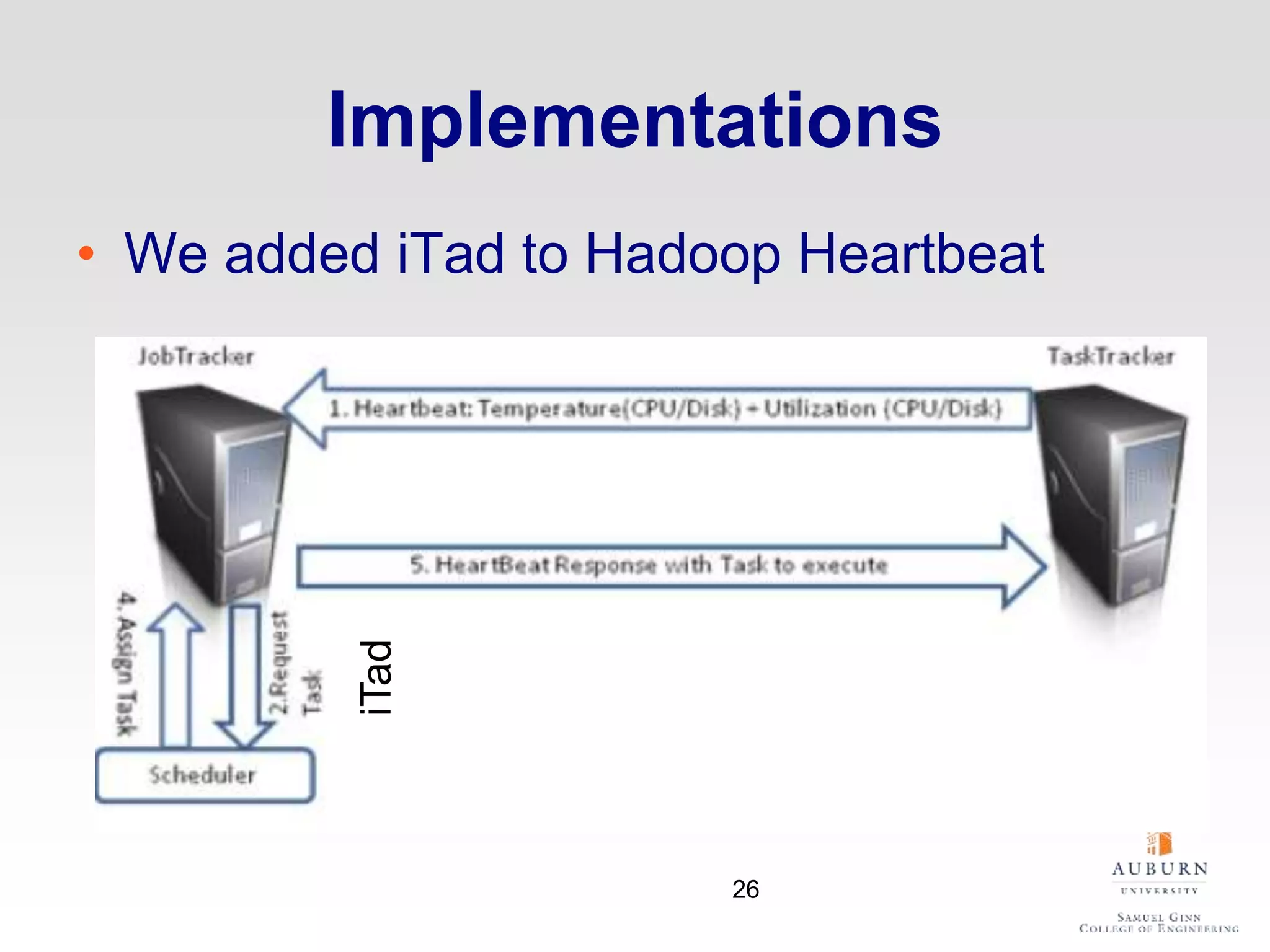

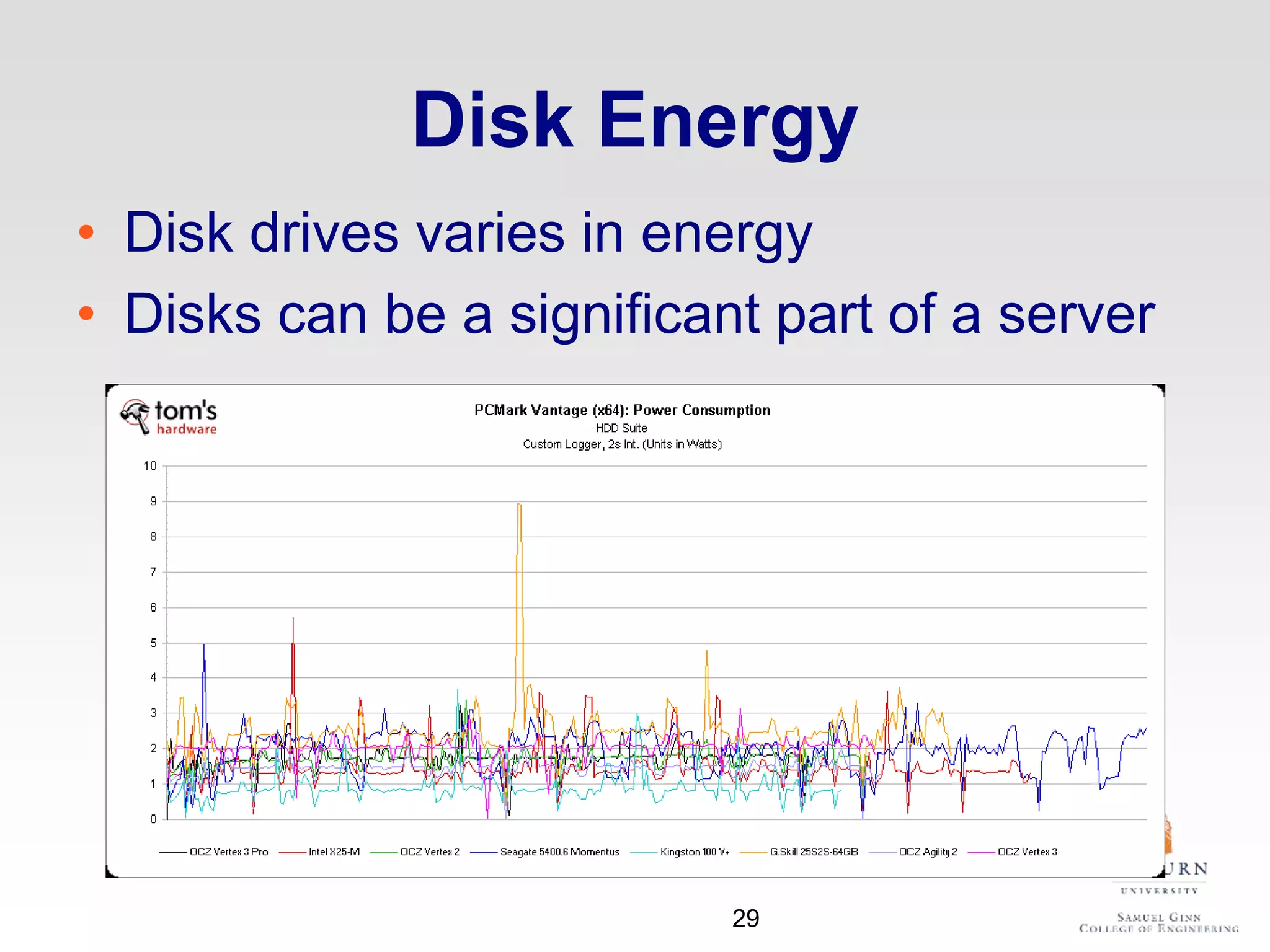

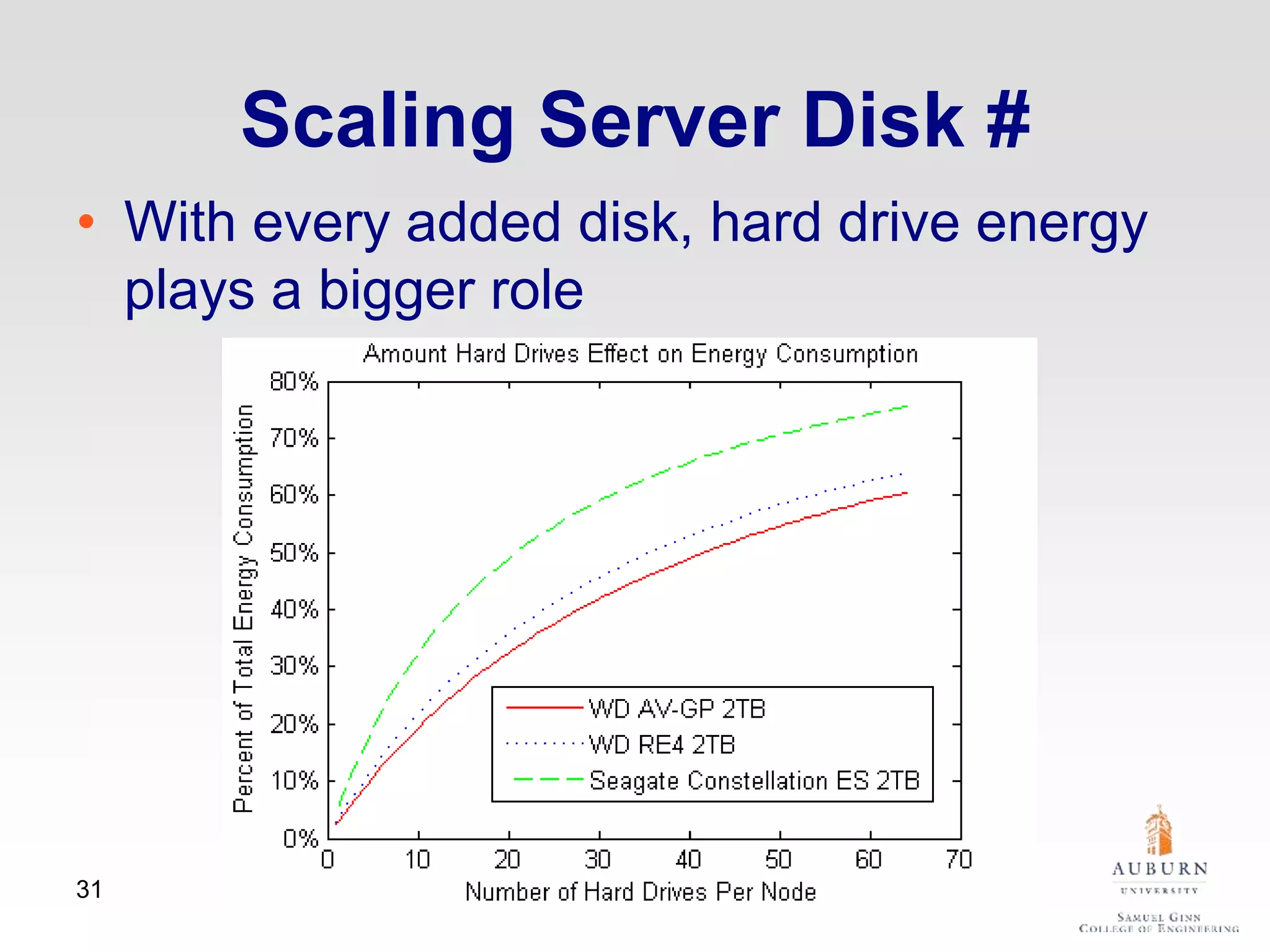

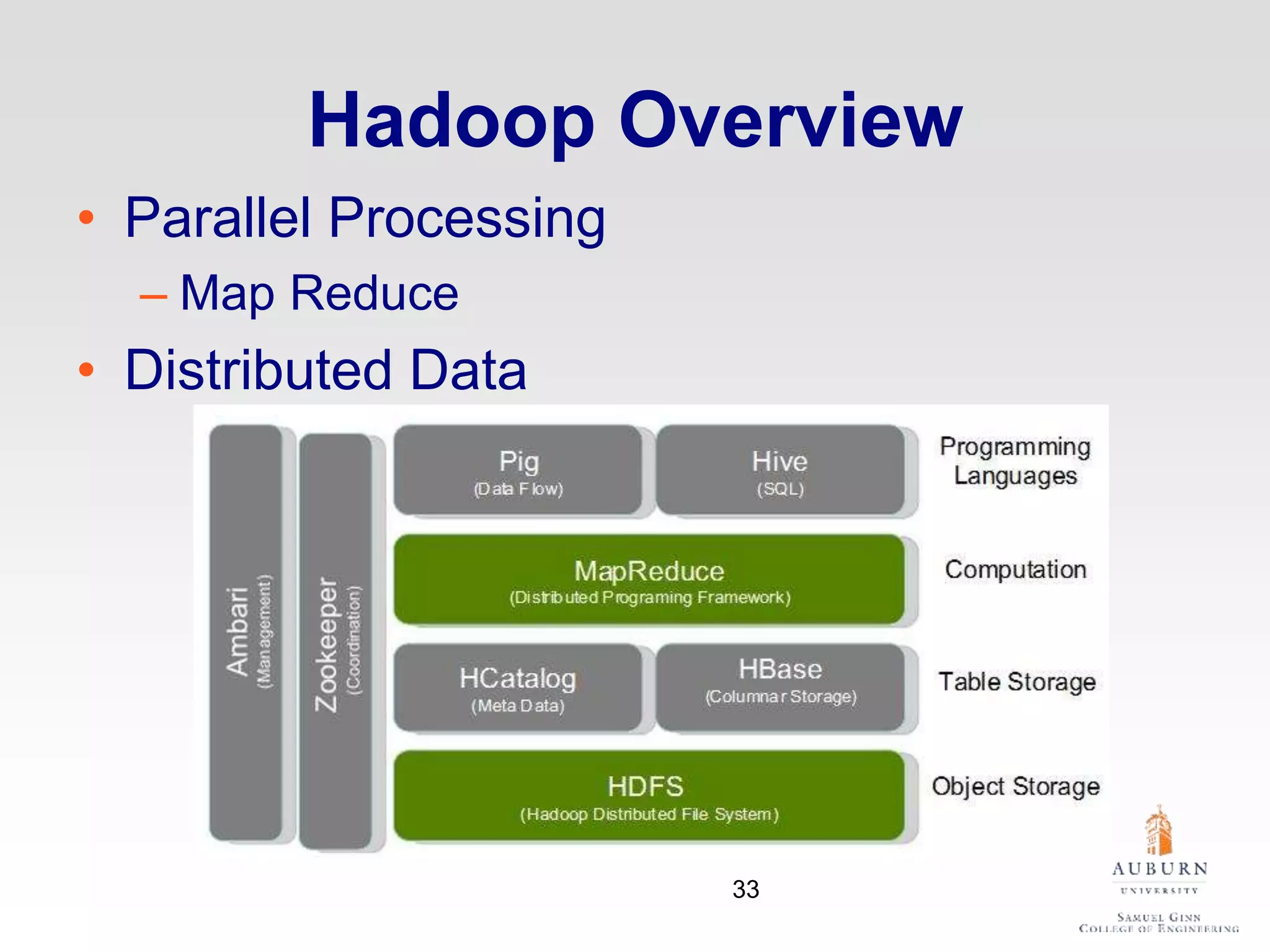
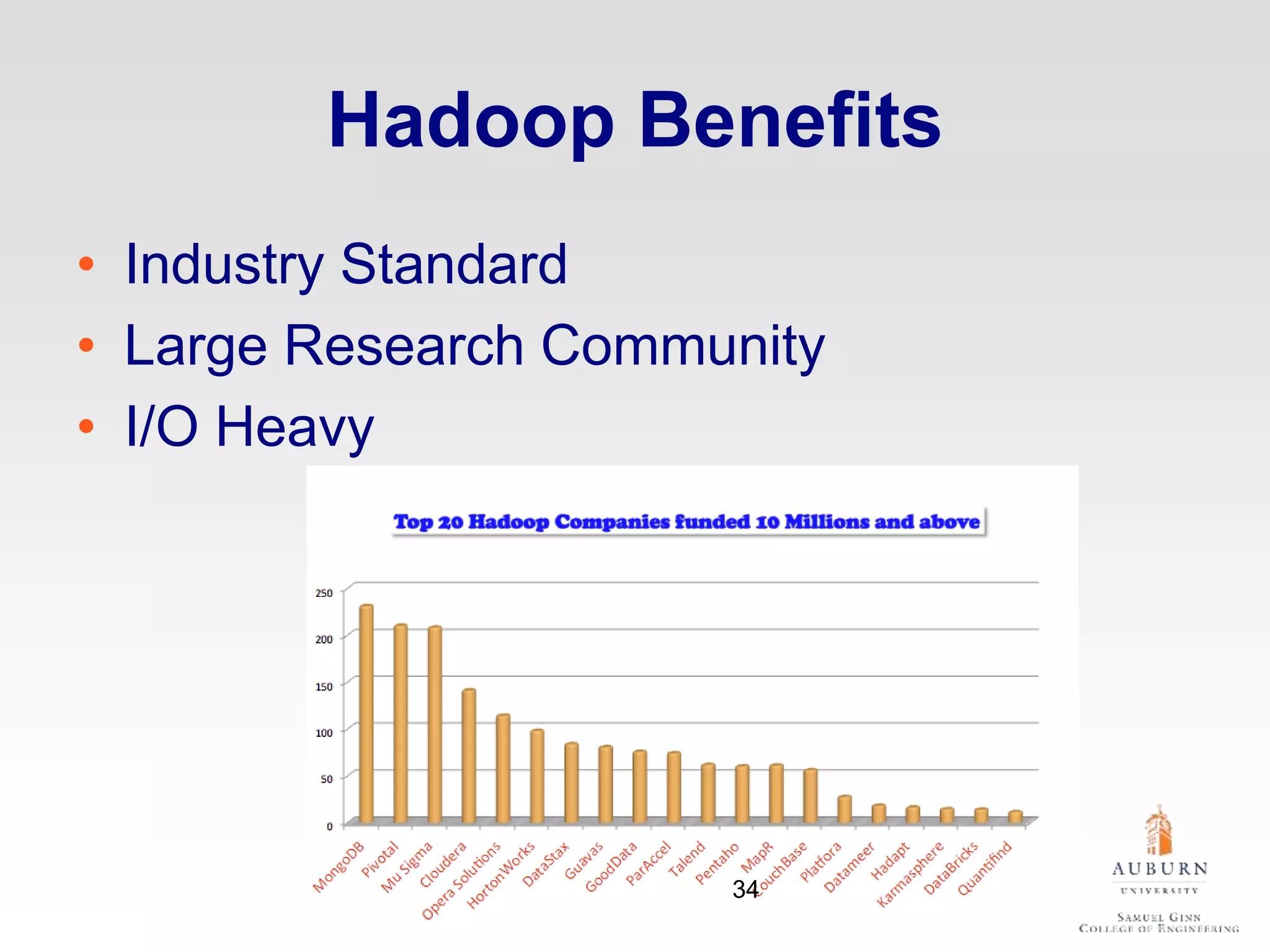
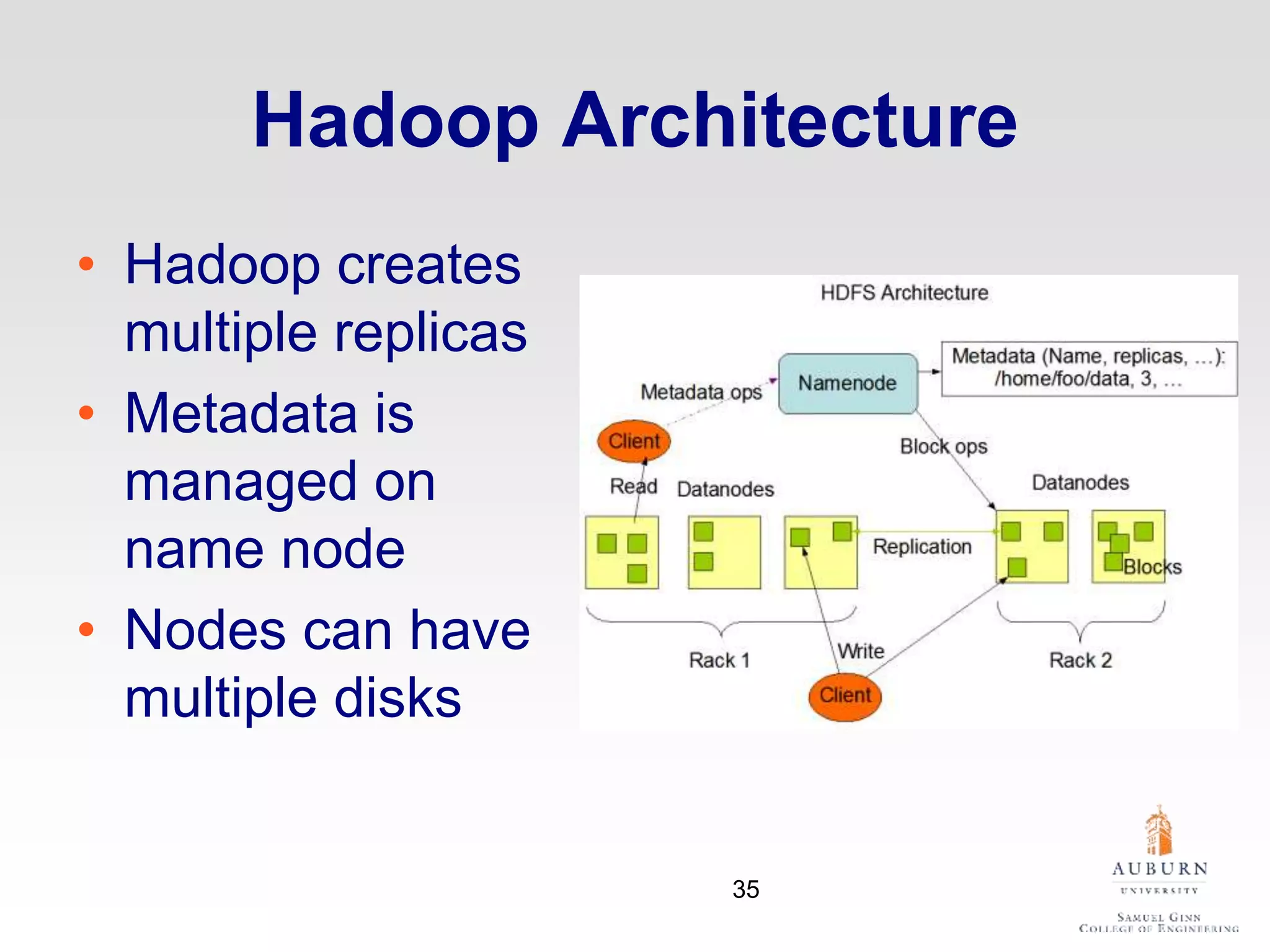



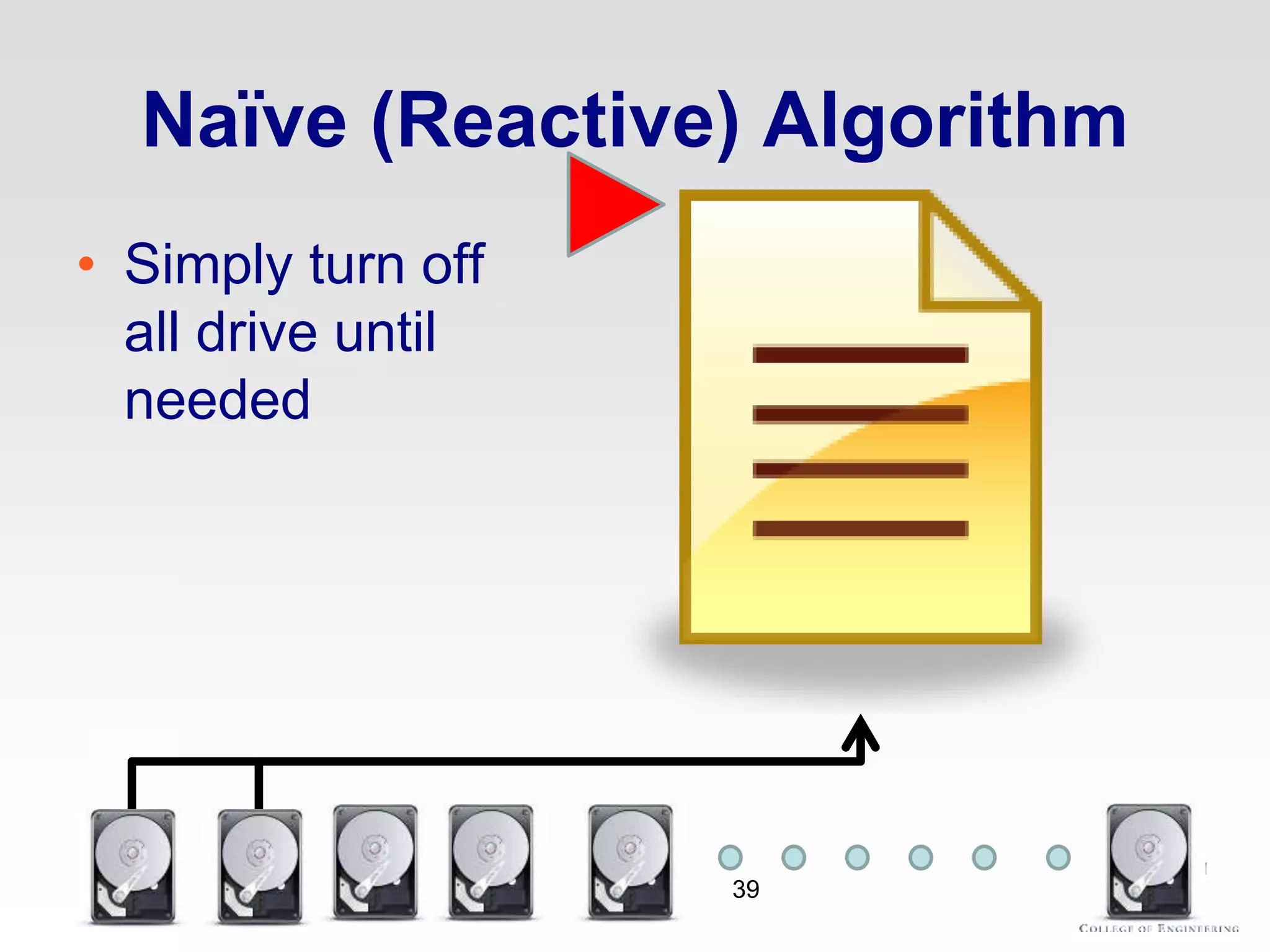

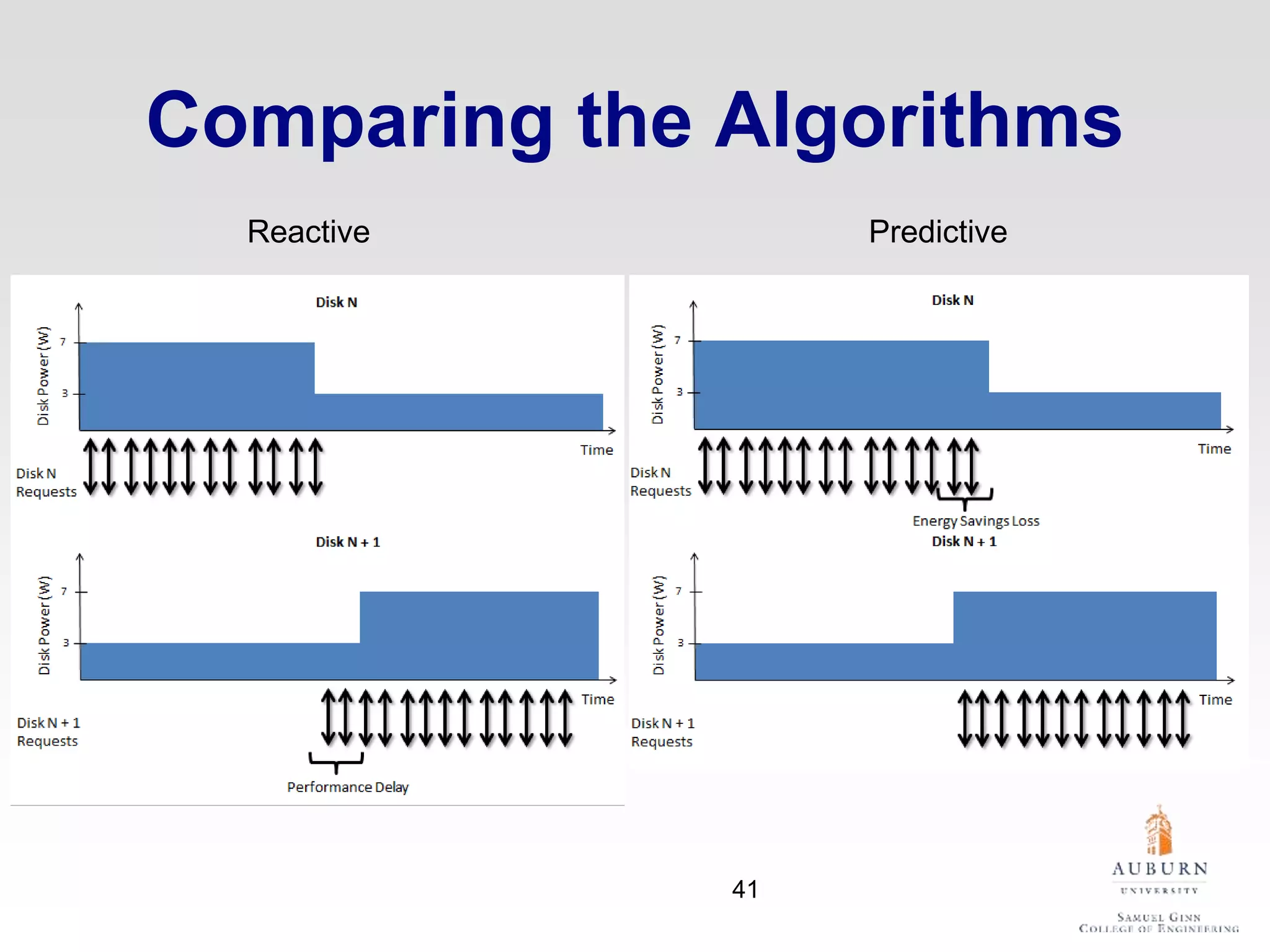
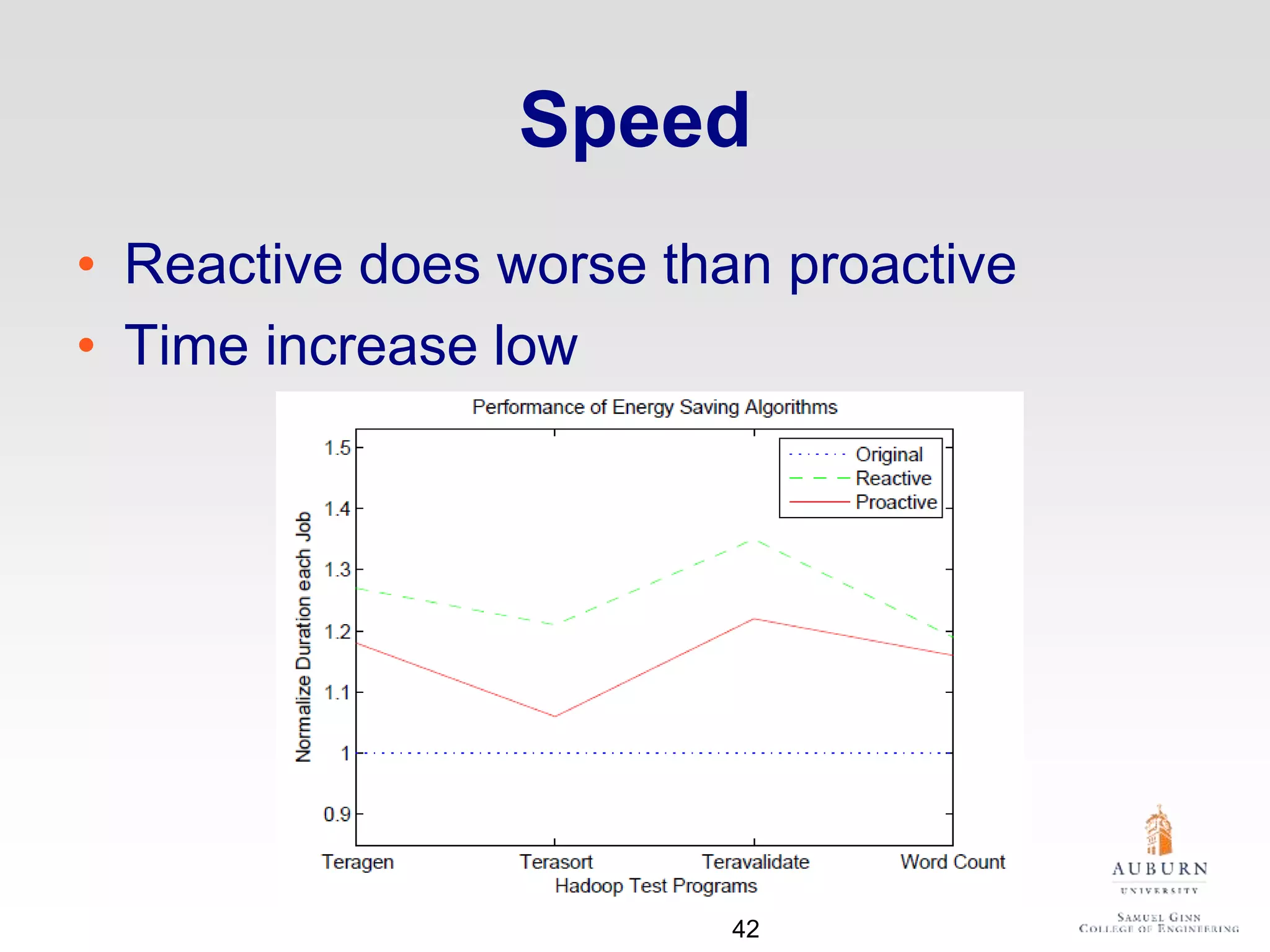
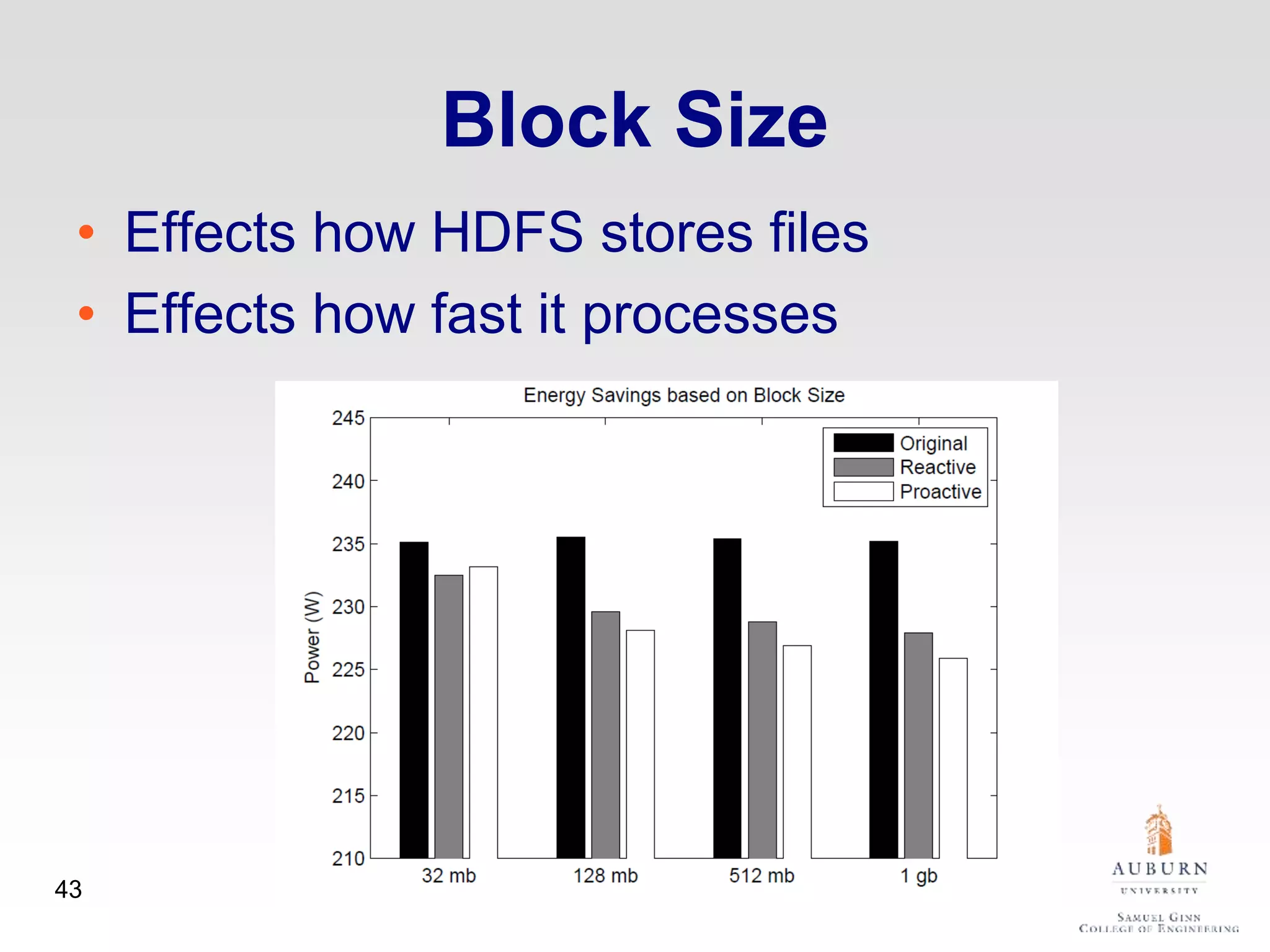
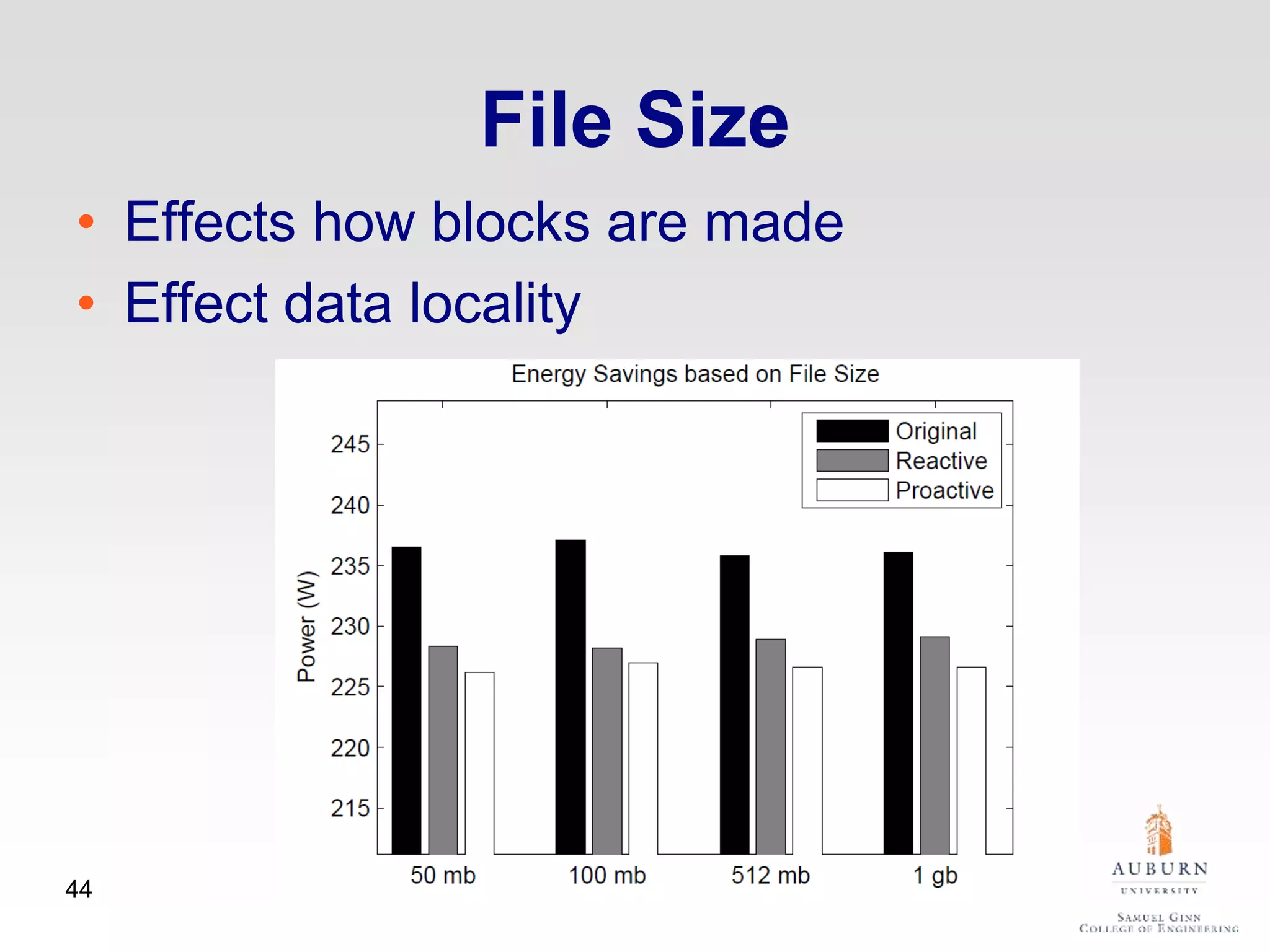
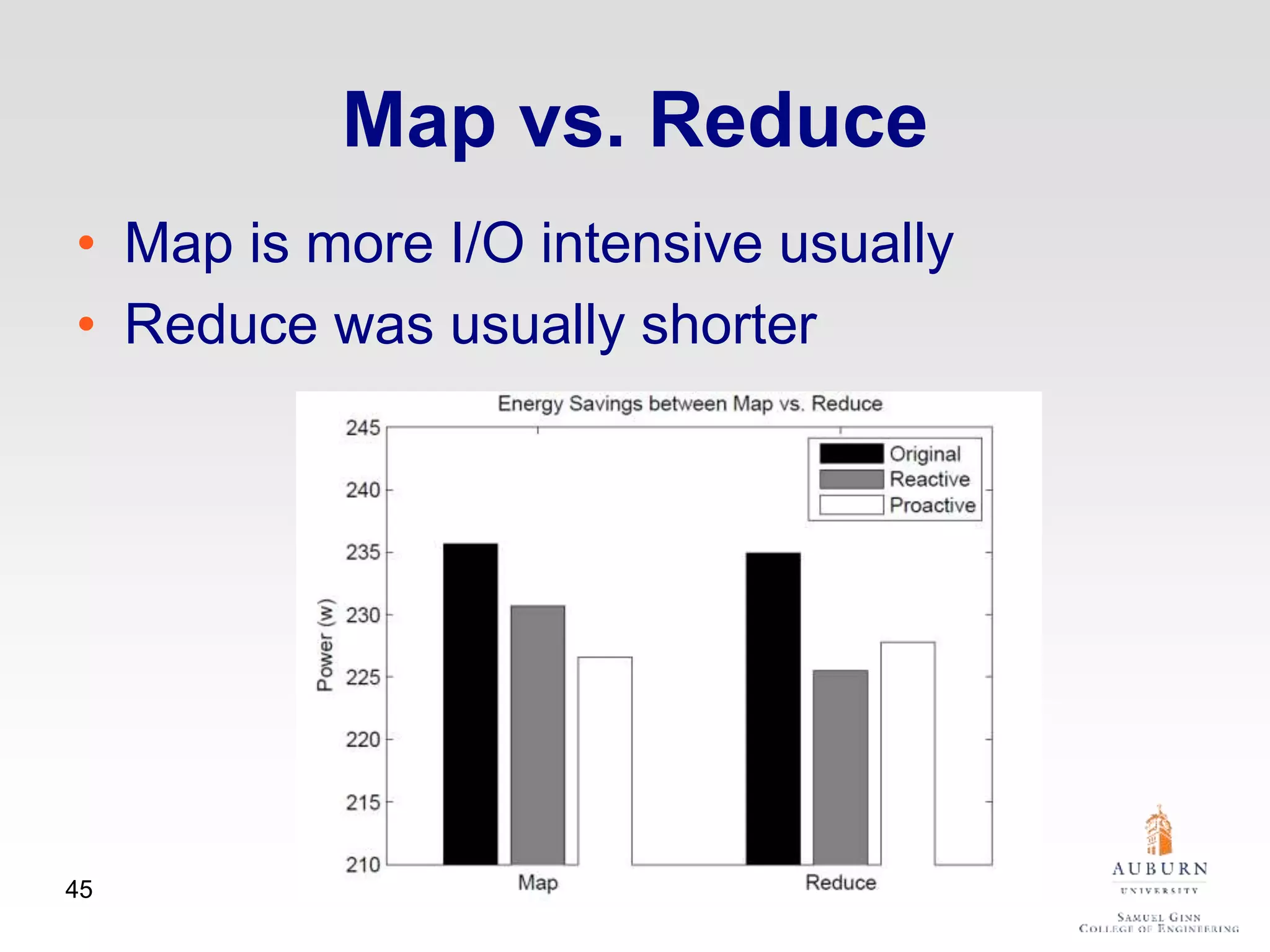
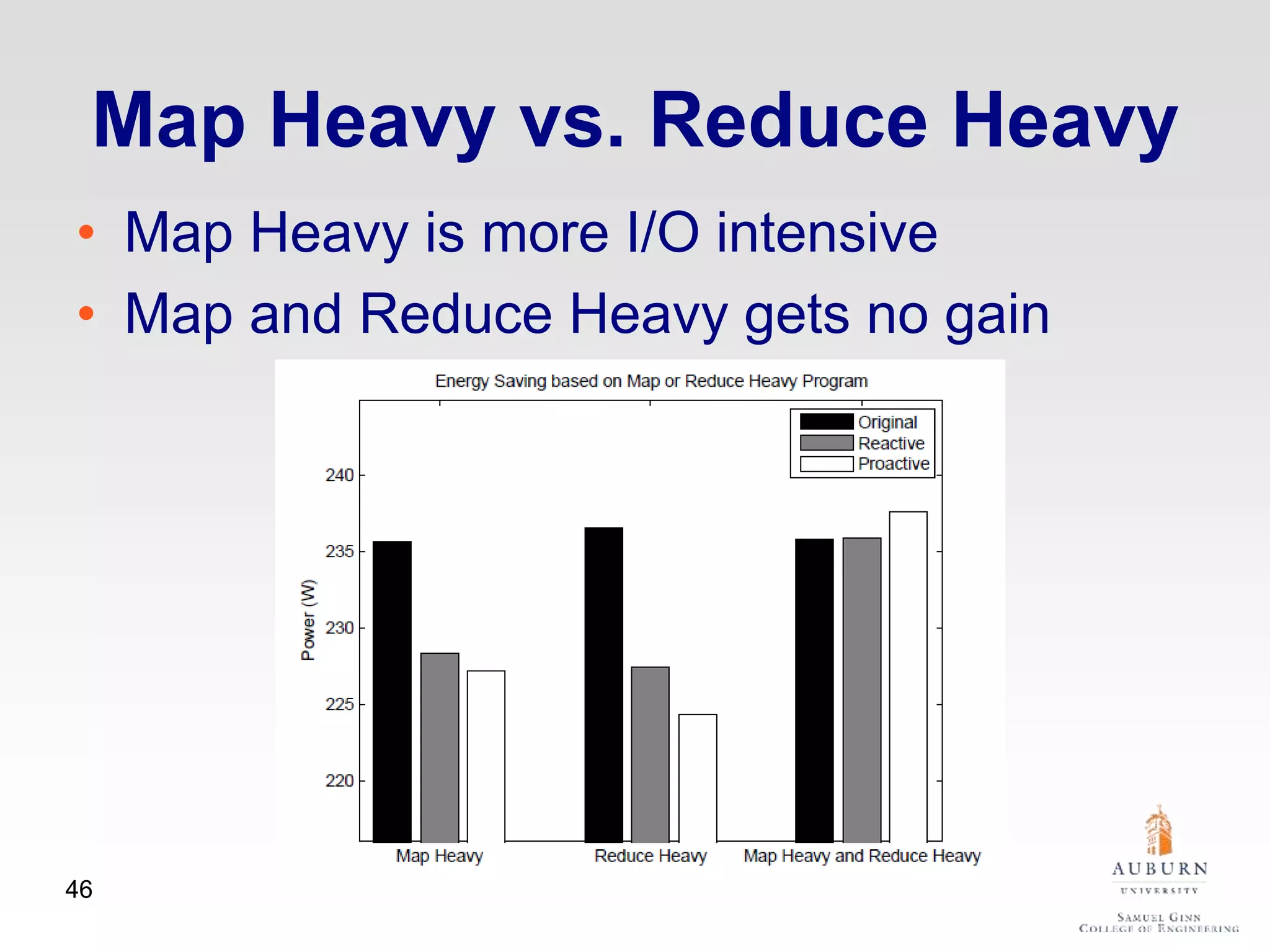






The document discusses thermal and energy-saving techniques for data centers, highlighting a research goal to estimate the temperature of data nodes based on CPU and I/O utilization. It introduces ITAD as a method for measuring temperature and NAP as an energy-saving technique for Hadoop clusters. Additionally, it presents various models and algorithms for optimizing energy efficiency in server operations.


































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

