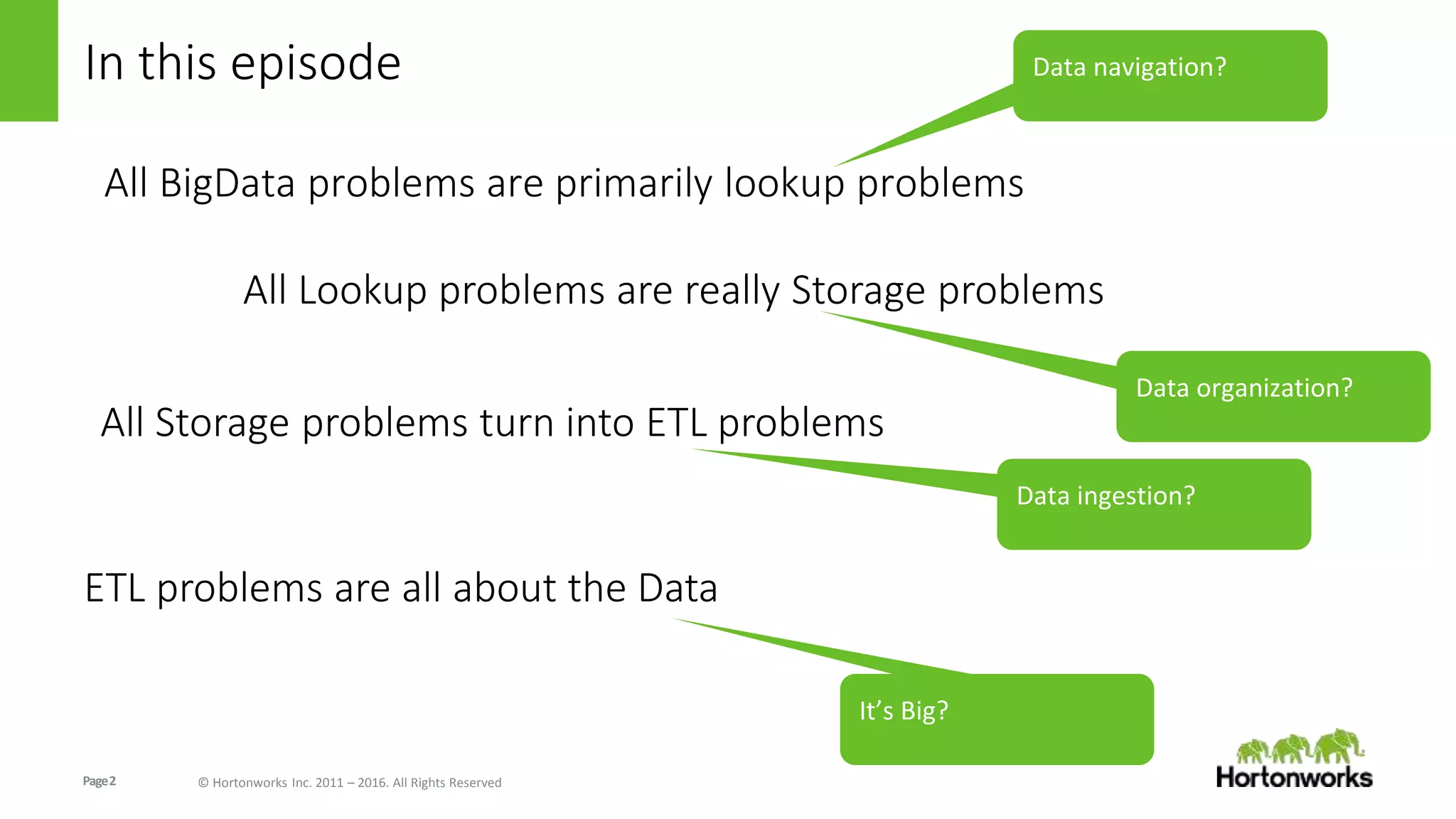
The document discusses various techniques for optimizing data organization and performance in Hive, including:
- Partitioning data by meaningful columns like customer ID or VIN to improve lookup performance.
- Using the right number and size of buckets to avoid performance issues from too many small files or skewed data distribution.
- Denormalizing data and optimizing JOIN queries through techniques like broadcast joins.
- Storing data in its natural types like numbers instead of strings to enable predicate pushdown and better performance.
- Using temporary tables and in-memory storage to optimize queries involving data reorganization or distinct slices.