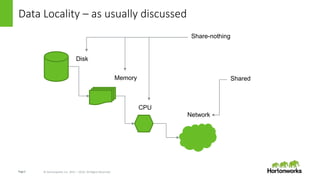
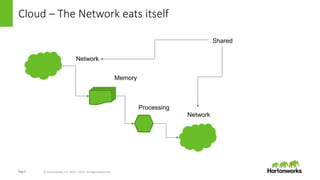
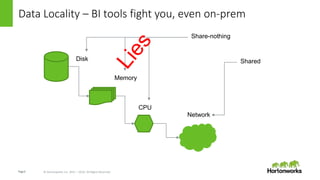
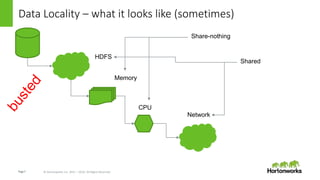
This document discusses how data locality is challenged in cloud computing environments where data is distributed across remote networks. It introduces LLAP (Locality is Locality Abstraction for Pipelines), a caching technique used by Hortonworks Data Cloud that decentralizes data in columnar caches across nodes to improve query performance even when data is remote. The document explains how LLAP handles issues like distributed transactions and node failures to maintain cache consistency and affinity without losing performance. Overall, LLAP aims to overcome data locality issues in the cloud by leveraging efficient caching techniques.


![Page4 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
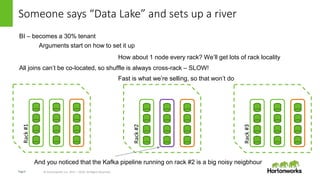
Cutaway Demo – LLAP on Cloud
TL;DW - repeat LLA+S3 benchmark on HDC
3 LLAP (m4.xlarge) nodes, Fact table has 864,001,869 rows
--------------------------------------------------------------------------------
VERTICES: 06/06 [==========================>>] 100% ELAPSED TIME: 1.68 s
--------------------------------------------------------------------------------
INFO : Status: DAG finished successfully in 1.63 seconds
INFO :
Hortonworks Data Cloud LLAP is >25x faster
EMR](https://image.slidesharecdn.com/llap-locality-170829012045/85/Llap-Locality-is-Dead-4-320.jpg)



![Page14 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
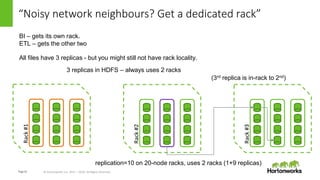
LLAP cache: ACID transactional snapshots
LLAP cache is built to handle Hive ACID 2.x data with overlapping read transactions.
With failure tolerance across retries
Q1Q2 LLAP
Partition=1 [txns=<1,2>]
Partition=1 [txns=<1>]
✔
✔
Partition=1 (retry) [txns=<1,2>]
Partition=1 (retry) [txns=<1>]
✔
✔
HIVE-12631
This works with a single cached
copy for any rows which are
common across the
transactions.
The retries work even if txn=2
deleted a row which existed in
txn=1.
Q2 is a txn ahead of Q1
Same partition, different data (in cache)](https://image.slidesharecdn.com/llap-locality-170829012045/85/Llap-Locality-is-Dead-14-320.jpg)
![Page15 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
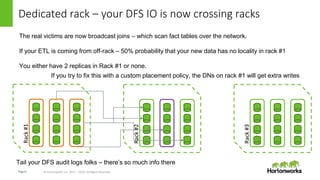
Locality is dead, long live cache affinity
Rack#1
1
3 2
Split #1 [2,3,1]
Split #2 [3,1,2]
If node #2 fails or is too busy, scheduler will skip.
When a node reboots, it takes up lowest open slot when it comes up
A reboot might cause an empty slot, but won’t cause cache misses on others](https://image.slidesharecdn.com/llap-locality-170829012045/85/Llap-Locality-is-Dead-15-320.jpg)



























































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)








