Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
SF
Uploaded by
Shintaro Fukushima
PDF, PPTX
19,546 views
最近のRのランダムフォレストパッケージ -ranger/Rborist-
R, Random Forest, ranger, Rborist
Data & Analytics
◦
Read more
18
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 35
2
/ 35
3
/ 35
4
/ 35
5
/ 35
6
/ 35
7
/ 35
8
/ 35
9
/ 35
10
/ 35
Most read
11
/ 35
12
/ 35
13
/ 35
14
/ 35
15
/ 35
16
/ 35
17
/ 35
18
/ 35
19
/ 35
Most read
20
/ 35
21
/ 35
22
/ 35
23
/ 35
24
/ 35
25
/ 35
26
/ 35
27
/ 35
28
/ 35
29
/ 35
30
/ 35
31
/ 35
32
/ 35
33
/ 35
34
/ 35
35
/ 35
More Related Content
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
PPTX
馬に蹴られるモデリング
by
Shushi Namba
PDF
負の二項分布について
by
Hiroshi Shimizu
PDF
ノンパラベイズ入門の入門
by
Shuyo Nakatani
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PDF
自然言語処理による議論マイニング
by
Naoaki Okazaki
PDF
StanとRでベイズ統計モデリング読書会 Chapter 7(7.6-7.9) 回帰分析の悩みどころ ~統計の力で歌うまになりたい~
by
nocchi_airport
PDF
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
階層ベイズとWAIC
by
Hiroshi Shimizu
馬に蹴られるモデリング
by
Shushi Namba
負の二項分布について
by
Hiroshi Shimizu
ノンパラベイズ入門の入門
by
Shuyo Nakatani
機械学習のためのベイズ最適化入門
by
hoxo_m
自然言語処理による議論マイニング
by
Naoaki Okazaki
StanとRでベイズ統計モデリング読書会 Chapter 7(7.6-7.9) 回帰分析の悩みどころ ~統計の力で歌うまになりたい~
by
nocchi_airport
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
What's hot
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PPTX
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
PDF
階層ベイズによるワンToワンマーケティング入門
by
shima o
PDF
Granger因果による 時系列データの因果推定(因果フェス2015)
by
Takashi J OZAKI
PPTX
多目的遺伝的アルゴリズム
by
MatsuiRyo
PDF
レコメンドエンジン作成コンテストの勝ち方
by
Shun Nukui
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
by
Deep Learning JP
PPTX
金融時系列のための深層t過程回帰モデル
by
Kei Nakagawa
PPTX
How to use in R model-agnostic data explanation with DALEX & iml
by
Satoshi Kato
PDF
スパースモデリングによる多次元信号・画像復元
by
Shogo Muramatsu
PDF
ブースティング入門
by
Retrieva inc.
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
PPTX
協力ゲーム理論でXAI (説明可能なAI) を目指すSHAP (Shapley Additive exPlanation)
by
西岡 賢一郎
PDF
ベータ分布の謎に迫る
by
Ken'ichi Matsui
PDF
[DL輪読会]Control as Inferenceと発展
by
Deep Learning JP
PPTX
データサイエンス概論第一=2-1 データ間の距離と類似度
by
Seiichi Uchida
PPTX
SHAP値の考え方を理解する(木構造編)
by
Kazuyuki Wakasugi
PDF
XGBoostからNGBoostまで
by
Tomoki Yoshida
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
2 6.ゼロ切断・過剰モデル
by
logics-of-blue
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
階層ベイズによるワンToワンマーケティング入門
by
shima o
Granger因果による 時系列データの因果推定(因果フェス2015)
by
Takashi J OZAKI
多目的遺伝的アルゴリズム
by
MatsuiRyo
レコメンドエンジン作成コンテストの勝ち方
by
Shun Nukui
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
by
Deep Learning JP
金融時系列のための深層t過程回帰モデル
by
Kei Nakagawa
How to use in R model-agnostic data explanation with DALEX & iml
by
Satoshi Kato
スパースモデリングによる多次元信号・画像復元
by
Shogo Muramatsu
ブースティング入門
by
Retrieva inc.
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
協力ゲーム理論でXAI (説明可能なAI) を目指すSHAP (Shapley Additive exPlanation)
by
西岡 賢一郎
ベータ分布の謎に迫る
by
Ken'ichi Matsui
[DL輪読会]Control as Inferenceと発展
by
Deep Learning JP
データサイエンス概論第一=2-1 データ間の距離と類似度
by
Seiichi Uchida
SHAP値の考え方を理解する(木構造編)
by
Kazuyuki Wakasugi
XGBoostからNGBoostまで
by
Tomoki Yoshida
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
2 6.ゼロ切断・過剰モデル
by
logics-of-blue
Similar to 最近のRのランダムフォレストパッケージ -ranger/Rborist-
PPTX
RandomForestとR package
by
Shuma Ishigami
PDF
統計解析ソフトR
by
Yoshitomo Akimoto
PDF
PFI Christmas seminar 2009
by
Preferred Networks
PDF
2013 JOI春合宿 講義6 機械学習入門
by
Hiroshi Yamashita
PPTX
R超入門機械学習をはじめよう
by
幹雄 小川
PDF
R+pythonでKAGGLEの2値予測に挑戦!
by
Yurie Oka
PDF
分類問題 - 機械学習ライブラリ scikit-learn の活用
by
y-uti
PPTX
Rプログラミング01 はじめの一歩
by
wada, kazumi
PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
PDF
SappoRo.R #2 初心者向けWS資料
by
考司 小杉
PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
PDF
ランダムフォレストとそのコンピュータビジョンへの応用
by
Kinki University
PPTX
32bit Windowsで頑張るRandom Forest
by
fqz7c3
PDF
Oracle Cloud Developers Meetup@東京
by
tuchimur
PDF
Rにおける大規模データ解析(第10回TokyoWebMining)
by
Shintaro Fukushima
PPTX
R seminar on igraph
by
Kazuhiro Takemoto
PDF
Introduction to NumPy & SciPy
by
Shiqiao Du
PDF
Tokyo.R #19 発表資料 「Rで色々やってみました」
by
Masayuki Isobe
PDF
はじパタ8章 svm
by
tetsuro ito
PDF
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
by
Yasutomo Kawanishi
RandomForestとR package
by
Shuma Ishigami
統計解析ソフトR
by
Yoshitomo Akimoto
PFI Christmas seminar 2009
by
Preferred Networks
2013 JOI春合宿 講義6 機械学習入門
by
Hiroshi Yamashita
R超入門機械学習をはじめよう
by
幹雄 小川
R+pythonでKAGGLEの2値予測に挑戦!
by
Yurie Oka
分類問題 - 機械学習ライブラリ scikit-learn の活用
by
y-uti
Rプログラミング01 はじめの一歩
by
wada, kazumi
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
SappoRo.R #2 初心者向けWS資料
by
考司 小杉
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
ランダムフォレストとそのコンピュータビジョンへの応用
by
Kinki University
32bit Windowsで頑張るRandom Forest
by
fqz7c3
Oracle Cloud Developers Meetup@東京
by
tuchimur
Rにおける大規模データ解析(第10回TokyoWebMining)
by
Shintaro Fukushima
R seminar on igraph
by
Kazuhiro Takemoto
Introduction to NumPy & SciPy
by
Shiqiao Du
Tokyo.R #19 発表資料 「Rで色々やってみました」
by
Masayuki Isobe
はじパタ8章 svm
by
tetsuro ito
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
by
Yasutomo Kawanishi
More from Shintaro Fukushima
PDF
20230216_Python機械学習プログラミング.pdf
by
Shintaro Fukushima
PDF
機械学習品質管理・保証の動向と取り組み
by
Shintaro Fukushima
PDF
Materials Informatics and Python
by
Shintaro Fukushima
PDF
BPstudy sklearn 20180925
by
Shintaro Fukushima
PDF
Why dont you_create_new_spark_jl
by
Shintaro Fukushima
PDF
Rユーザのためのspark入門
by
Shintaro Fukushima
PDF
Juliaによる予測モデル構築・評価
by
Shintaro Fukushima
PDF
Juliaで並列計算
by
Shintaro Fukushima
PDF
機械学習を用いた予測モデル構築・評価
by
Shintaro Fukushima
PDF
データサイエンスワールドからC++を眺めてみる
by
Shintaro Fukushima
PDF
data.tableパッケージで大規模データをサクッと処理する
by
Shintaro Fukushima
PDF
アクションマイニングを用いた最適なアクションの導出
by
Shintaro Fukushima
PDF
R3.0.0 is relased
by
Shintaro Fukushima
PDF
外れ値
by
Shintaro Fukushima
PDF
Rでreproducible research
by
Shintaro Fukushima
PDF
統計解析言語Rにおける大規模データ管理のためのboost.interprocessの活用
by
Shintaro Fukushima
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PDF
mmapパッケージを使ってお手軽オブジェクト管理
by
Shintaro Fukushima
PDF
Numpy scipyで独立成分分析
by
Shintaro Fukushima
PDF
Rで学ぶロバスト推定
by
Shintaro Fukushima
20230216_Python機械学習プログラミング.pdf
by
Shintaro Fukushima
機械学習品質管理・保証の動向と取り組み
by
Shintaro Fukushima
Materials Informatics and Python
by
Shintaro Fukushima
BPstudy sklearn 20180925
by
Shintaro Fukushima
Why dont you_create_new_spark_jl
by
Shintaro Fukushima
Rユーザのためのspark入門
by
Shintaro Fukushima
Juliaによる予測モデル構築・評価
by
Shintaro Fukushima
Juliaで並列計算
by
Shintaro Fukushima
機械学習を用いた予測モデル構築・評価
by
Shintaro Fukushima
データサイエンスワールドからC++を眺めてみる
by
Shintaro Fukushima
data.tableパッケージで大規模データをサクッと処理する
by
Shintaro Fukushima
アクションマイニングを用いた最適なアクションの導出
by
Shintaro Fukushima
R3.0.0 is relased
by
Shintaro Fukushima
外れ値
by
Shintaro Fukushima
Rでreproducible research
by
Shintaro Fukushima
統計解析言語Rにおける大規模データ管理のためのboost.interprocessの活用
by
Shintaro Fukushima
不均衡データのクラス分類
by
Shintaro Fukushima
mmapパッケージを使ってお手軽オブジェクト管理
by
Shintaro Fukushima
Numpy scipyで独立成分分析
by
Shintaro Fukushima
Rで学ぶロバスト推定
by
Shintaro Fukushima
最近のRのランダムフォレストパッケージ -ranger/Rborist-
1.
最近のRの ランダムフォレストパッケージ - ranger /
Rborist - 2015年10月10日 第51回Tokyo.R @sfchaos 1
2.
自己紹介 ■ twitterID: @sfchaos ■
仕事: クルマのデータマイニング ■ 興味: ノンパラメトリックベイズ/混合メンバシップ モデル/Julia/Spark 2
3.
宣伝1 ■ データサイエンティスト養成読本 機械学習入門編 ■ 豪華な執筆陣!! ■
祝・刊行1ヶ月!! ■ 機械学習の入門に最適な一冊. ■ 「機械学習って何で注目されているの? 意味ある の?」or「機械学習ってなんでもできるんでしょ!?」 という人には第I部特集1がオススメ. 3
4.
宣伝1 ■第1部 しくみと概要を学ぼう! ■特集1 機械学習を使いたい人のための入門講座 ■特集2
機械学習の基礎知識 ■特集3 ビジネスに導入する機械学習 ■特集4 深層学習最前線 ■第2部 手を動かして学ぼう! ■特集1 機械学習ソフトウェアの概観 ■特集2 Pythonによる機械学習入門 ■特集3 推薦システム入門 ■特集4 Pythonで画像認識にチャレンジ ■特集5 Jubatusによる異常検知 4
5.
宣伝2 ■ 「岩波データサイエンス Vol.1」 ■
豪華な執筆陣!! ■ 特集は,ベイズ推論とMCMCのソフトウェア ■ 芥川賞受賞作家・円城塔さんの掌編小説も!! ■ 雑誌のように気軽に手にとって,本のように骨のあ る本 ■ 書評 http://d.hatena.ne.jp/sfchaos/20151010 5
6.
アジェンダ ■ 最近のRの機械学習パッケージ ■ rangerとRborist(ランダムフォレスト) ■
rangerでの疎行列の扱い ■ まとめ 6
7.
1. 最近のRの機械学習パッケージ 7
8.
最近のトピック ■ 新しいランダムフォレスト実装の台頭 (ranger/Rborist) ■
勾配ブースティングの隆盛 (xgboost) ■ mlrパッケージの台頭? (caretと肩を並べつつある?) ■・・・ 8
9.
最近のトピック ■ 新しいランダムフォレスト実装の台頭 (ranger/Rborist) ■ 勾配ブースティングの隆盛
(xgboost) ■・・・ 9 今回はランダムフォレストの 新しいパッケージについて
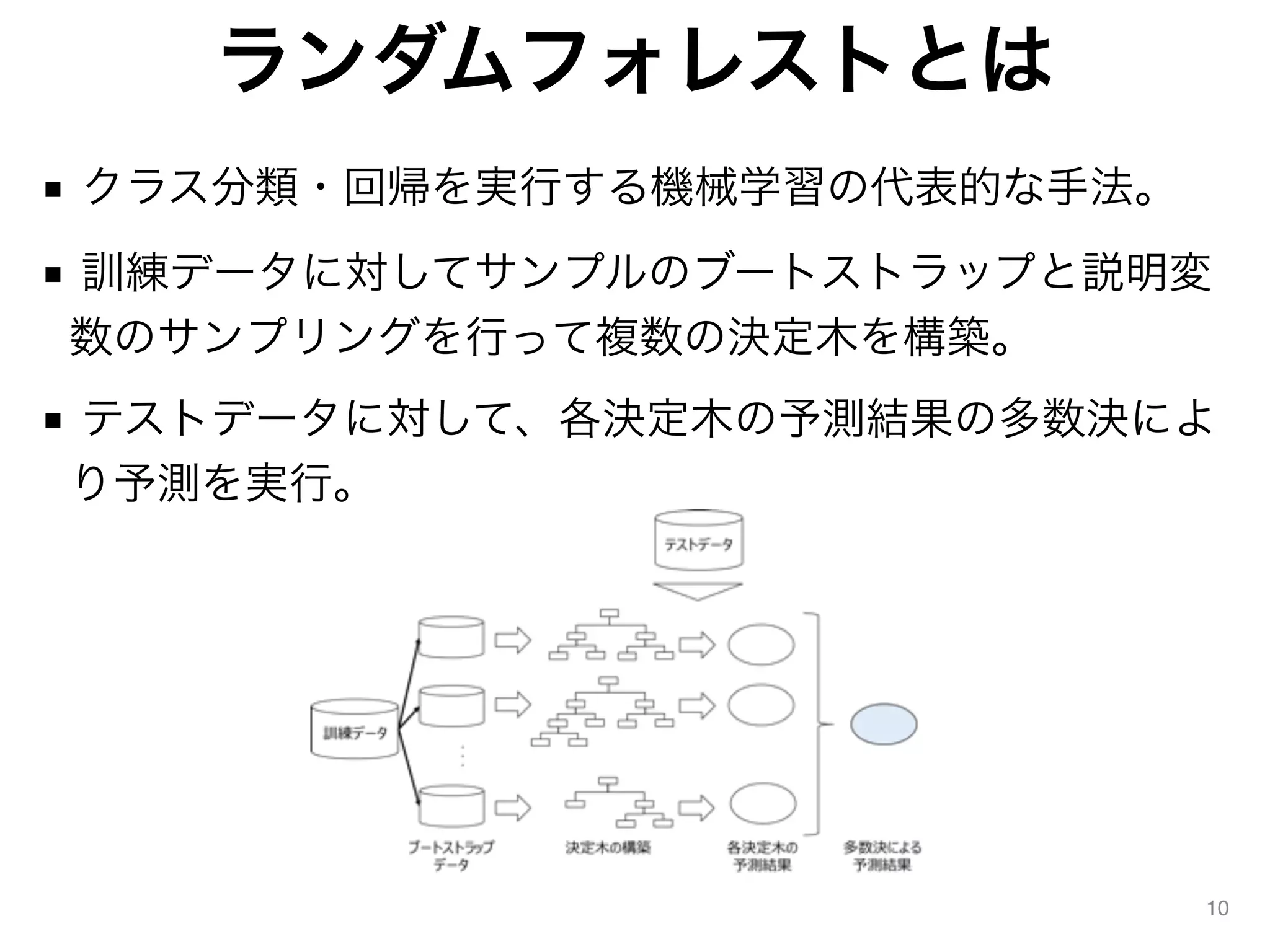
10.
ランダムフォレストとは ■ クラス分類・回帰を実行する機械学習の代表的な手法。 ■ 訓練データに対してサンプルのブートストラップと説明変 数のサンプリングを行って複数の決定木を構築。 ■
テストデータに対して、各決定木の予測結果の多数決によ り予測を実行。 10
11.
randomForestパッケージ ■ 従来の定番. ■ partyパッケージとかも(条件付き推測木). 11
12.
ranger/Rborist ■ ranger: A
Fast Implementation of Random Forests for High Dimensional Data in C++ and R http://arxiv.org/abs/1508.04409 ■ ranger(RANdom forest GEneRator) ■ rangerもRboristも中身はC++. ■ rangerはスレッド並列化が可能. 12
13.
ranger/Rborist ■ 新たなランダムフォレストのパッケージ ■ @dichikaさんのブログを参照. RでランダムフォレストやるならRboristかrangerか http://d.hatena.ne.jp/dichika/20150828/p1 13
14.
ranger/Rborist ■ これまでにも,いくつかのブログで取り上げられている ■ "ranger:
A Fast Implementation of Random Forests”のメモ書き http://yamano357.hatenadiary.com/entry/2015/09/17/230536 ■ TagTeam :: Predicting Titanic deaths on Kaggle V: Ranger - R- bloggers - Statistics and Visualization http://tagteam.harvard.edu/hub_feeds/1981/feed_items/ 2126439 ■ [R言語]library("ranger")とlibrary("randomForest")の速度を比較 する - gepulog http://blog.gepuro.net/archives/130 ■ 新型のランダムフォレスト(Random Forest)パッケージ比較: Rborist・ranger・randomForest - My Life as a Mock Quant http://d.hatena.ne.jp/teramonagi/20150914/1442226764 14
15.
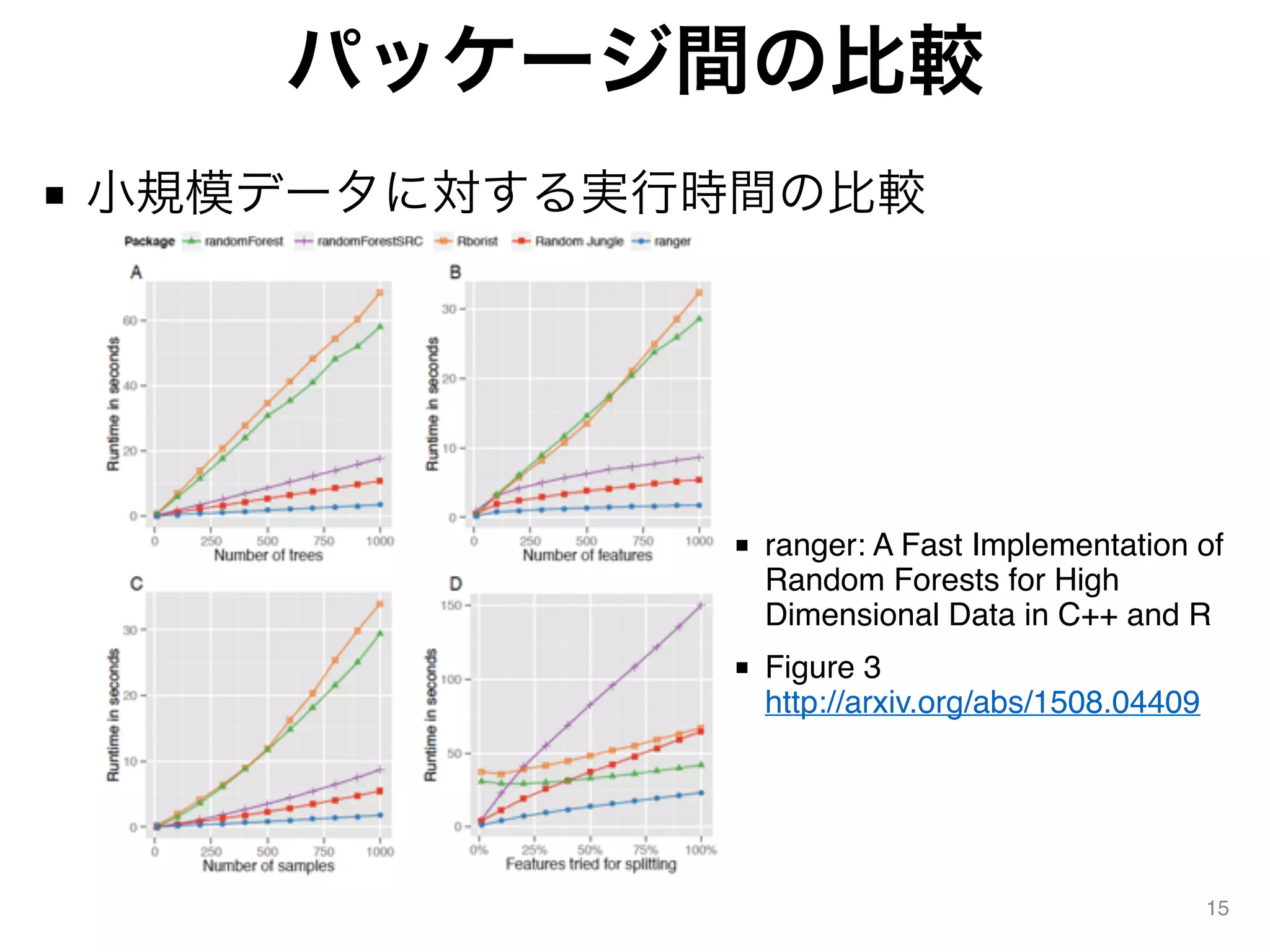
パッケージ間の比較 ■ 小規模データに対する実行時間の比較 15 ■ ranger:
A Fast Implementation of Random Forests for High Dimensional Data in C++ and R ■ Figure 3 http://arxiv.org/abs/1508.04409
16.
パッケージ間の比較 ■対象データ:シミュレーションされた100,000サン プル,100特徴量 16 ■ ranger: A
Fast Implementation of Random Forests for High Dimensional Data in C++ and R ■ Table 2 http://arxiv.org/abs/1508.04409
17.
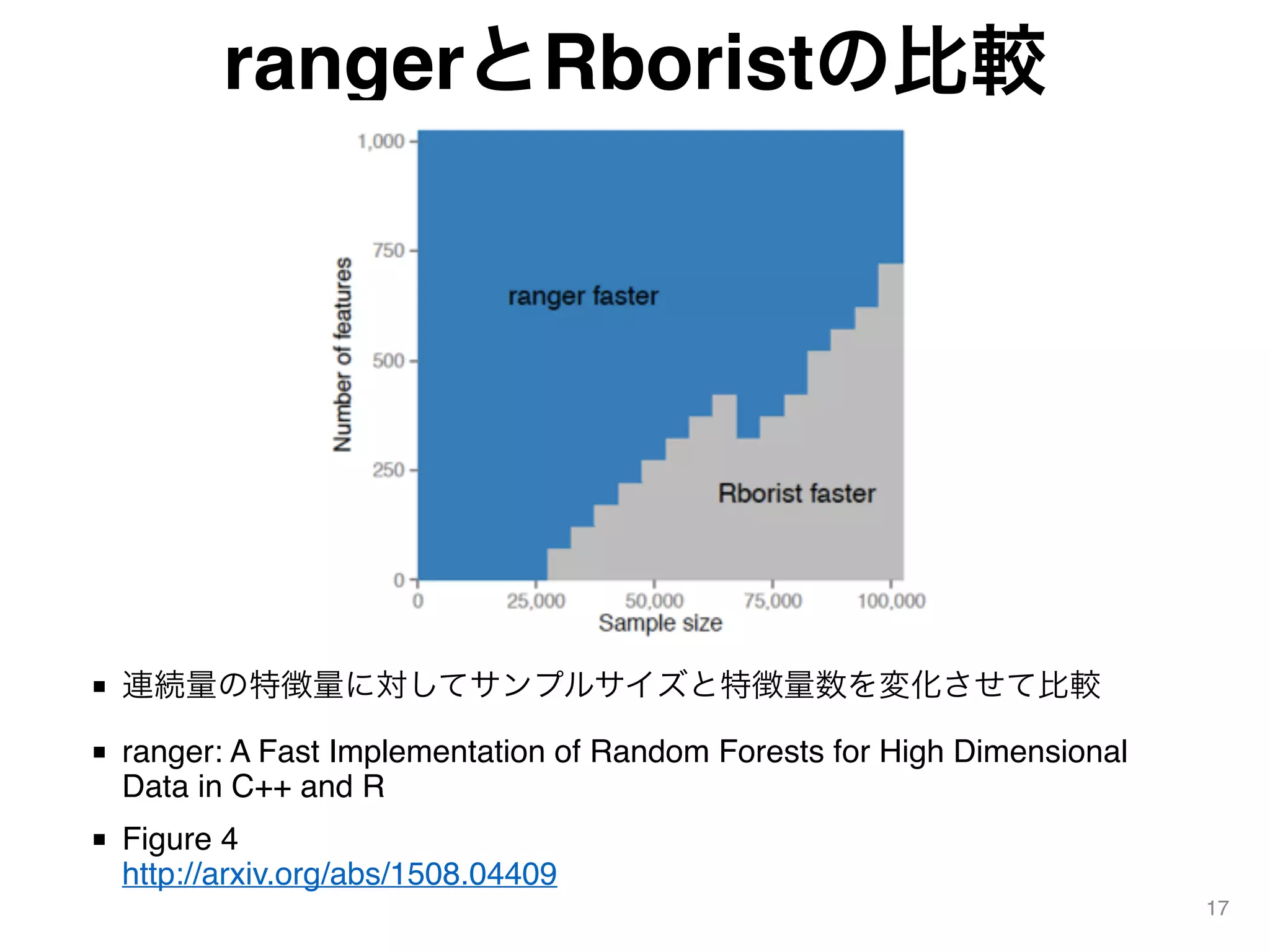
rangerとRboristの比較 17 ■ 連続量の特徴量に対してサンプルサイズと特徴量数を変化させて比較 ■ ranger:
A Fast Implementation of Random Forests for High Dimensional Data in C++ and R ■ Figure 4 http://arxiv.org/abs/1508.04409
18.
2. rangerとRborist (ランダムフォレスト) 18
19.
パッケージのインストール ■ CRANからインストール 19 > install.packages(c(“randomForest”,
“ranger”, “Rborist”))
20.
使用方法 20 > randomForest(目的変数 ~.,
data=データ) > ranger(目的変数 ~., data=データ)) > Rborist(説明変数, 目的変数)
21.
比較実験 ■ spamデータセット 21 > library(kernlab) >
data(spam) > dim(spam) [1] 4601 58
22.
比較実験 22 > # randomForest >
system.time(randomForest(type ~., data=spam, ntree=1000)) ユーザ システム 経過 20.885 0.176 21.265 > # ranger > system.time(ranger(type ~., data=spam, num.trees=1000, + seed=71)) ユーザ システム 経過 8.688 0.113 2.534 > # ranger(省メモリモード) > system.time(ranger(type ~., data=spam, seed=71, + save.memory=TRUE)) ユーザ システム 経過 29.017 0.113 8.171 > # Rborist > system.time(Rborist(spam %>% select(-type), spam$type)) ユーザ システム 経過 7.948 0.630 8.616
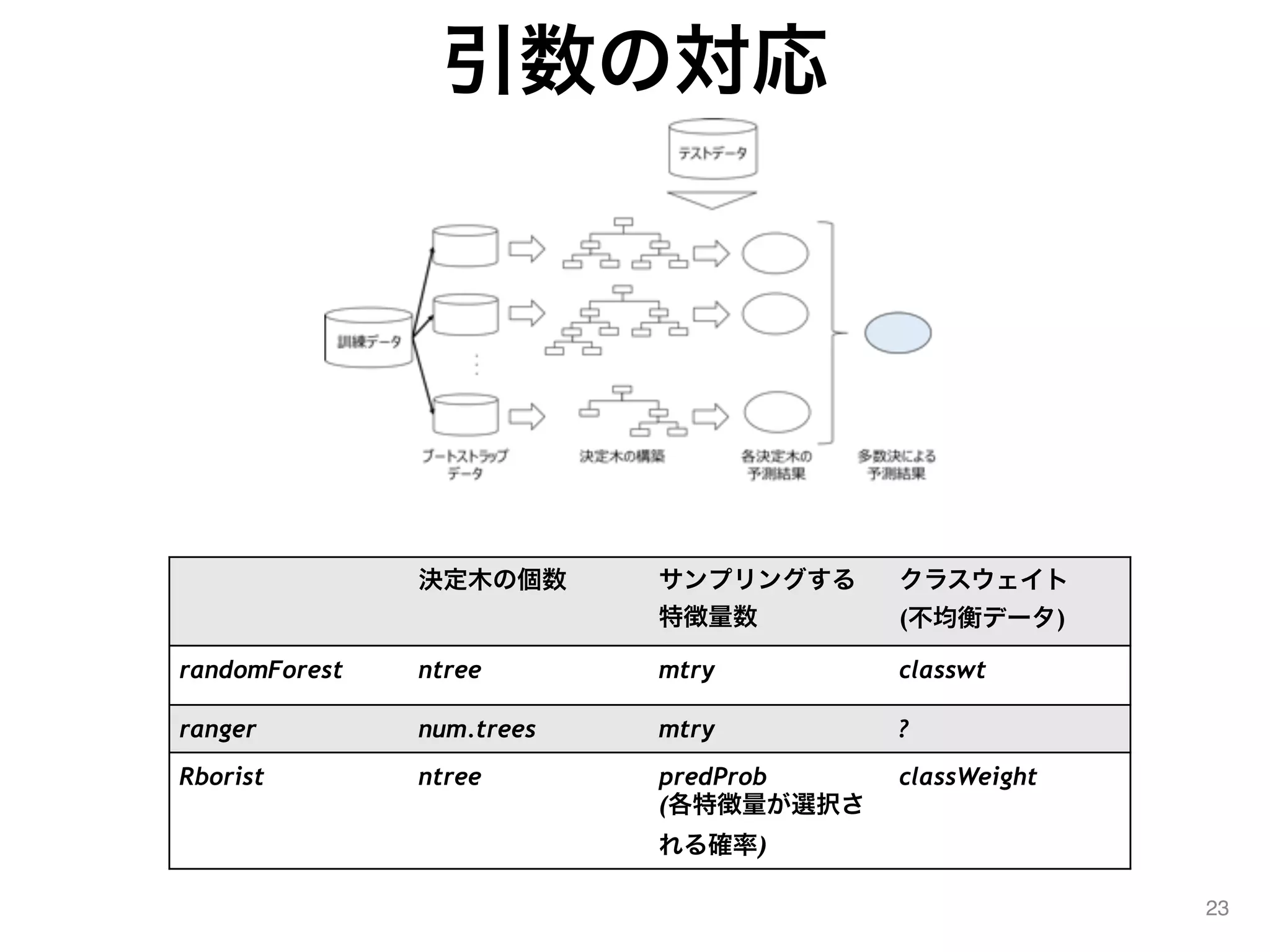
23.
引数の対応 23 決定木の個数 サンプリングする 特徴量数 クラスウェイト (不均衡データ) randomForest ntree
mtry classwt ranger num.trees mtry ? Rborist ntree predProb (各特徴量が選択さ れる確率) classWeight
24.
3. rangerでの疎行列の扱い 24
25.
rangerの疎行列の扱い 25 http://yamano357.hatenadiary.com/entry/2015/09/17/230536 !!!
26.
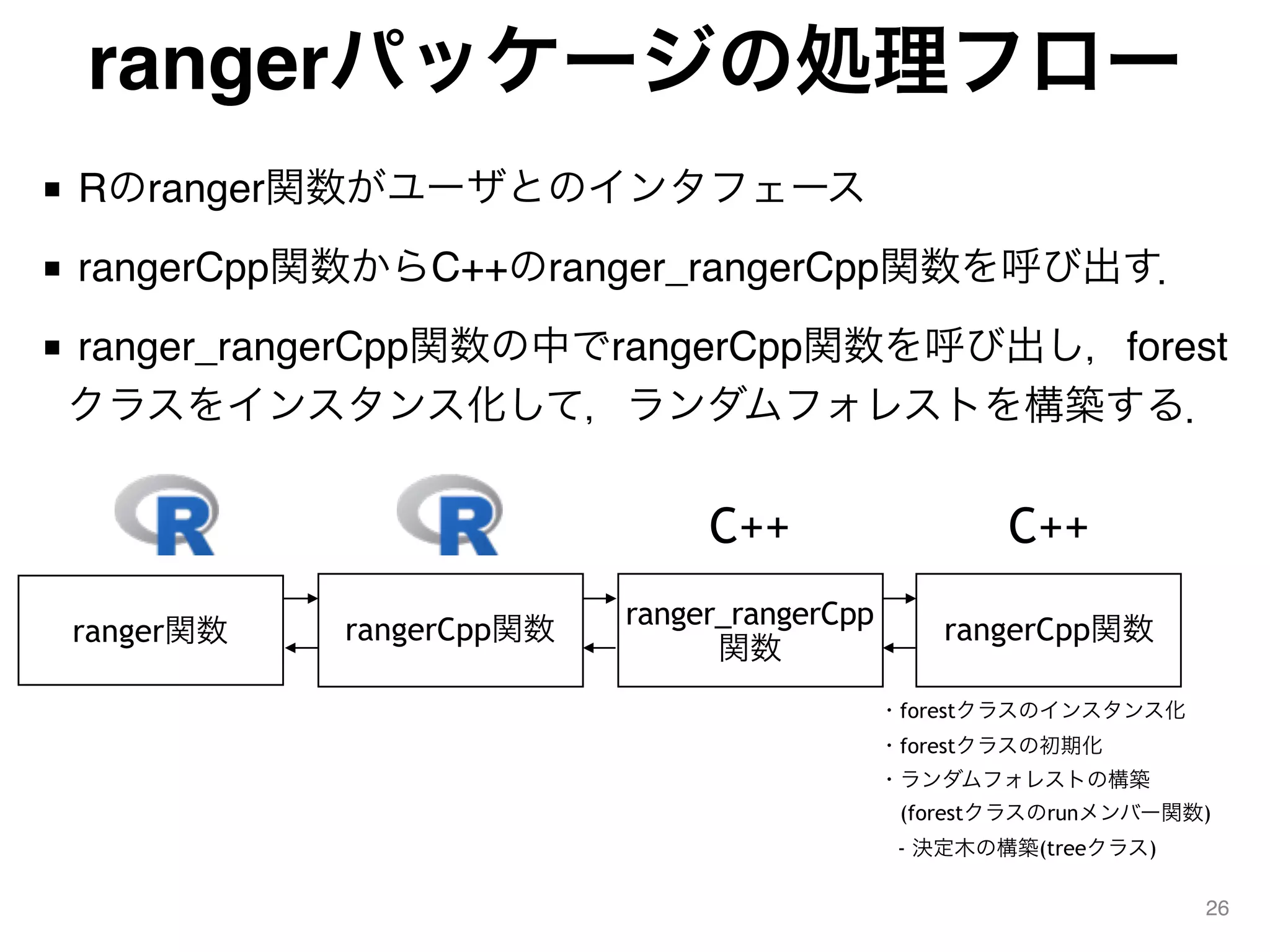
rangerパッケージの処理フロー ■ Rのranger関数がユーザとのインタフェース ■ rangerCpp関数からC++のranger_rangerCpp関数を呼び出す. ■
ranger_rangerCpp関数の中でrangerCpp関数を呼び出し,forest クラスをインスタンス化して,ランダムフォレストを構築する. 26 ranger関数 rangerCpp関数 C++ ・forestクラスのインスタンス化 ・forestクラスの初期化 ・ランダムフォレストの構築 (forestクラスのrunメンバー関数) - 決定木の構築(treeクラス) ranger_rangerCpp 関数 rangerCpp関数 C++
27.
rangerCpp関数の引数 27 ## Call Ranger result
<- rangerCpp(treetype, dependent.variable.name, data.final, variable.names, mtry, num.trees, verbose, seed, num.threads, write.forest, importance.mode, min.node.size, split.select.weights, use.split.select.weights, always.split.variables, use.always.split.variables, status.variable.name, prediction.mode, loaded.forest, sparse.data, replace, probability, unordered.factor.variables, use.unordered.factor.variables, save.memory, splitrule)
28.
ranger_rangerCpp関数の引数 28 cppExport SEXP ranger_rangerCpp(SEXP
treetypeSEXP, … , SEXP splitrule_rSEXP) { … Rcpp::traits::input_parameter< Rcpp::RawMatrix >::type sparse_data(sparse_dataSEXP); … }
29.
rangerでの疎行列対応 ■ 疎行列に対応しているのはgwaa.dataクラスのオブ ジェクトのみ(GenABELパッケージ). 29 ## GenABEL
GWA data if (class(data) == "gwaa.data") { snp.names <- data@gtdata@snpnames sparse.data <- data@gtdata@gtps@.Data data <- data@phdata if ("id" %in% names(data)) { data$"id" <- NULL } gwa.mode <- TRUE save.memory <- FALSE } else { sparse.data <- as.matrix(0) gwa.mode <- FALSE } R/ranger.R 166-179
30.
gwaa.dataクラスの使用 ■ 試しに,GenABEL.dataパッケージのge03d2データ セットを指定してみる. ■ 遺伝子のデータ? 30
31.
gwaa.dataクラスの使用 ■ こんなデータ 31 > library(GenABEL.data) >
data(ge03d2) > str(ge03d2) Formal class 'gwaa.data' [package "GenABEL"] with 2 slots ..@ phdata:'data.frame': 950 obs. of 8 variables: .. ..$ id : chr [1:950] "id4" "id10" "id25" "id33" ... .. ..$ sex : int [1:950] 0 1 0 0 0 0 1 1 0 1 ... .. ..$ age : num [1:950] 51.6 53.7 66 44.7 49.9 ... .. ..$ dm2 : int [1:950] 1 1 1 1 1 1 1 1 1 1 ... .. ..$ height: num [1:950] 152 170 165 174 157 ... .. ..$ weight: num [1:950] 83 65.6 69.6 69.7 84.3 ... .. ..$ diet : int [1:950] 0 0 0 0 0 0 0 0 0 0 ... .. ..$ bmi : num [1:950] 36 22.6 25.6 22.9 34.1 ... ..@ gtdata:Formal class 'snp.data' [package "GenABEL"] with 11 slots .. .. ..@ nbytes : num 238 .. .. ..@ nids : int 950 •••
32.
gwaa.dataクラスの使用 ■ phdataで回帰を実行してみる 32 > #
欠損値の除去 > ge03d2@phdata <- na.omit(ge03d2@phdata) > head(ge03d2@phdata) id sex age dm2 height weight diet bmi id4 id4 0 51.63771 1 151.7863 83.03480 0 36.04086 id10 id10 1 53.73938 1 170.3180 65.59815 0 22.61363 id25 id25 0 66.01148 1 164.7949 69.55278 0 25.61103 id33 id33 0 44.66715 1 174.4638 69.73042 0 22.90929 id35 id35 0 49.87941 1 157.1834 84.27884 0 34.11185 id58 id58 0 36.99524 1 165.0929 89.53816 0 32.85122 > # BMIを目的変数とする回帰モデルの構築 > model.rg <- ranger(bmi ~., data=ge03d2)
33.
スパースデータのデータ構造 ■ このとき,sparse.dataは次のようになっている. 33 ## GenABEL
GWA data if (class(data) == "gwaa.data") { snp.names <- data@gtdata@snpnames sparse.data <- data@gtdata@gtps@.Data data <- data@phdata if ("id" %in% names(data)) { data$"id" <- NULL } gwa.mode <- TRUE save.memory <- FALSE } else { sparse.data <- as.matrix(0) gwa.mode <- FALSE } R/ranger.R 166-179 > dim(sparse.data) [1] 238 7589 > class(sparse.data) [1] “matrix” > sparse.data[1:3, 1:3] [,1] [,2] [,3] [1,] 99 95 ae [2,] 57 55 db [3,] 9a 55 2f > mode(sparse.data) [1] "raw" モードがraw
34.
4. まとめ 34
35.
まとめ ■ Rでランダムフォレスト実行のパッケージとして, ranger, Rborist等が開発されている. ■
rangerで疎行列を扱えるのは,現状,gwaa.dataク ラスのオブジェクトのみ. 35
Download












![ranger/Rborist
■ これまでにも,いくつかのブログで取り上げられている
■ "ranger: A Fast Implementation of Random Forests”のメモ書き
http://yamano357.hatenadiary.com/entry/2015/09/17/230536
■ TagTeam :: Predicting Titanic deaths on Kaggle V: Ranger - R-
bloggers - Statistics and Visualization
http://tagteam.harvard.edu/hub_feeds/1981/feed_items/
2126439
■ [R言語]library("ranger")とlibrary("randomForest")の速度を比較
する - gepulog
http://blog.gepuro.net/archives/130
■ 新型のランダムフォレスト(Random Forest)パッケージ比較:
Rborist・ranger・randomForest - My Life as a Mock Quant
http://d.hatena.ne.jp/teramonagi/20150914/1442226764
14](https://image.slidesharecdn.com/newrfpkgdist20151010-151010083024-lva1-app6891/75/R-ranger-Rborist-14-2048.jpg)




![比較実験
■ spamデータセット
21
> library(kernlab)
> data(spam)
> dim(spam)
[1] 4601 58](https://image.slidesharecdn.com/newrfpkgdist20151010-151010083024-lva1-app6891/75/R-ranger-Rborist-21-2048.jpg)







![gwaa.dataクラスの使用
■ こんなデータ
31
> library(GenABEL.data)
> data(ge03d2)
> str(ge03d2)
Formal class 'gwaa.data' [package "GenABEL"] with 2 slots
..@ phdata:'data.frame': 950 obs. of 8 variables:
.. ..$ id : chr [1:950] "id4" "id10" "id25"
"id33" ...
.. ..$ sex : int [1:950] 0 1 0 0 0 0 1 1 0 1 ...
.. ..$ age : num [1:950] 51.6 53.7 66 44.7 49.9 ...
.. ..$ dm2 : int [1:950] 1 1 1 1 1 1 1 1 1 1 ...
.. ..$ height: num [1:950] 152 170 165 174 157 ...
.. ..$ weight: num [1:950] 83 65.6 69.6 69.7 84.3 ...
.. ..$ diet : int [1:950] 0 0 0 0 0 0 0 0 0 0 ...
.. ..$ bmi : num [1:950] 36 22.6 25.6 22.9 34.1 ...
..@ gtdata:Formal class 'snp.data' [package "GenABEL"]
with 11 slots
.. .. ..@ nbytes : num 238
.. .. ..@ nids : int 950
•••](https://image.slidesharecdn.com/newrfpkgdist20151010-151010083024-lva1-app6891/75/R-ranger-Rborist-31-2048.jpg)

![スパースデータのデータ構造
■ このとき,sparse.dataは次のようになっている.
33
## GenABEL GWA data
if (class(data) == "gwaa.data") {
snp.names <- data@gtdata@snpnames
sparse.data <- data@gtdata@gtps@.Data
data <- data@phdata
if ("id" %in% names(data)) {
data$"id" <- NULL
}
gwa.mode <- TRUE
save.memory <- FALSE
} else {
sparse.data <- as.matrix(0)
gwa.mode <- FALSE
}
R/ranger.R 166-179
> dim(sparse.data)
[1] 238 7589
> class(sparse.data)
[1] “matrix”
> sparse.data[1:3, 1:3]
[,1] [,2] [,3]
[1,] 99 95 ae
[2,] 57 55 db
[3,] 9a 55 2f
> mode(sparse.data)
[1] "raw"
モードがraw](https://image.slidesharecdn.com/newrfpkgdist20151010-151010083024-lva1-app6891/75/R-ranger-Rborist-33-2048.jpg)
















![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)












































