Downloaded 729 times








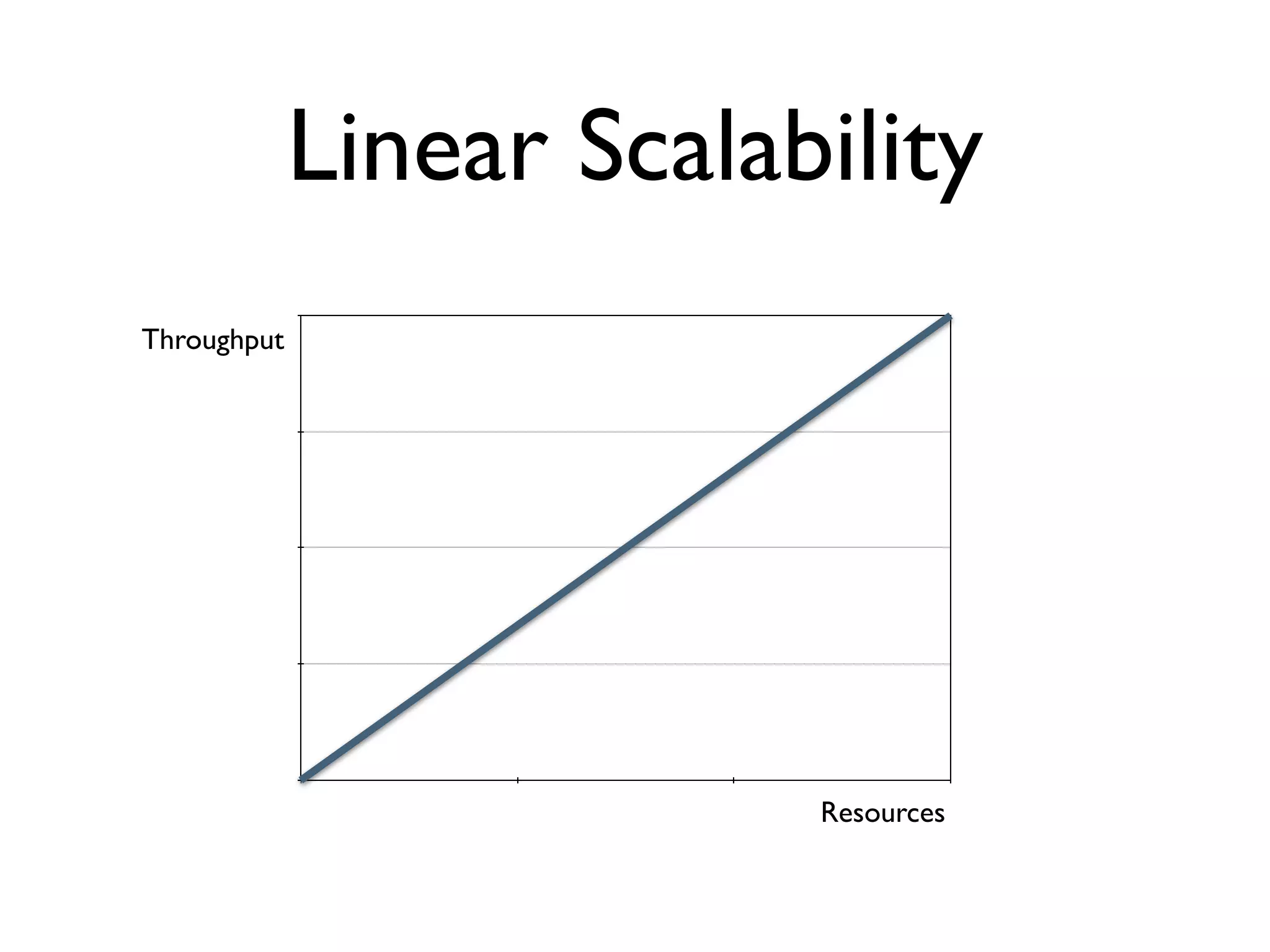
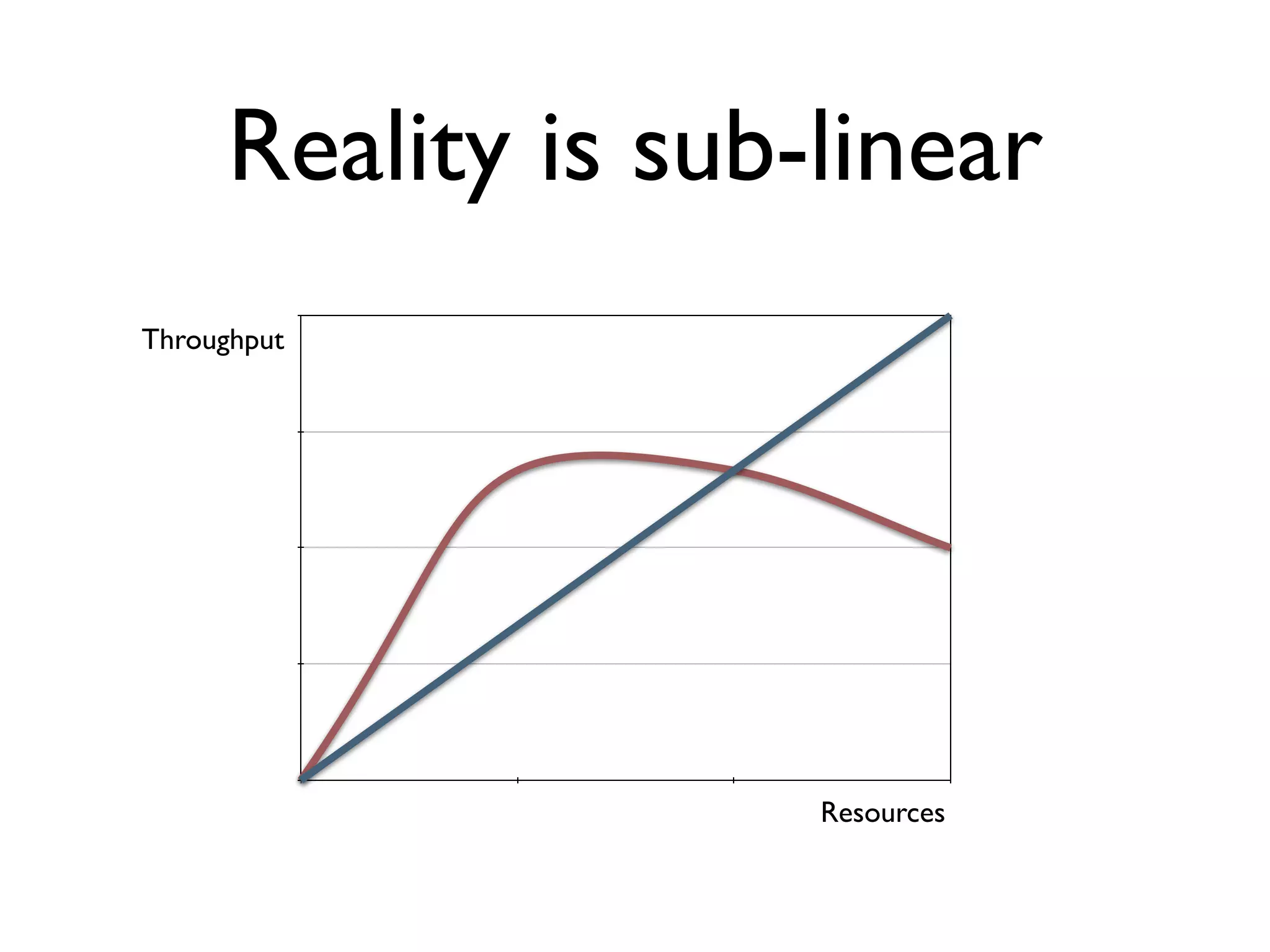





















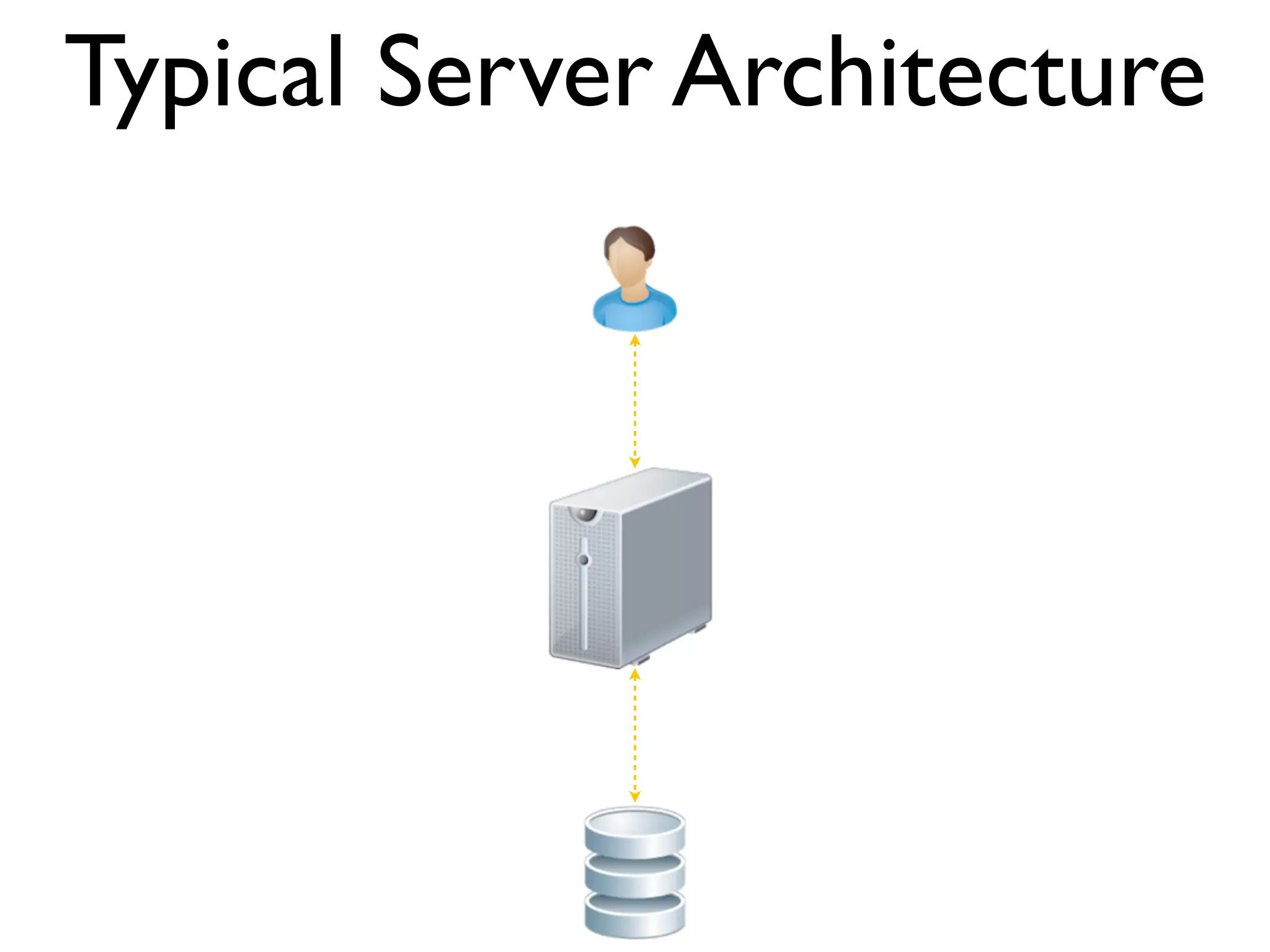
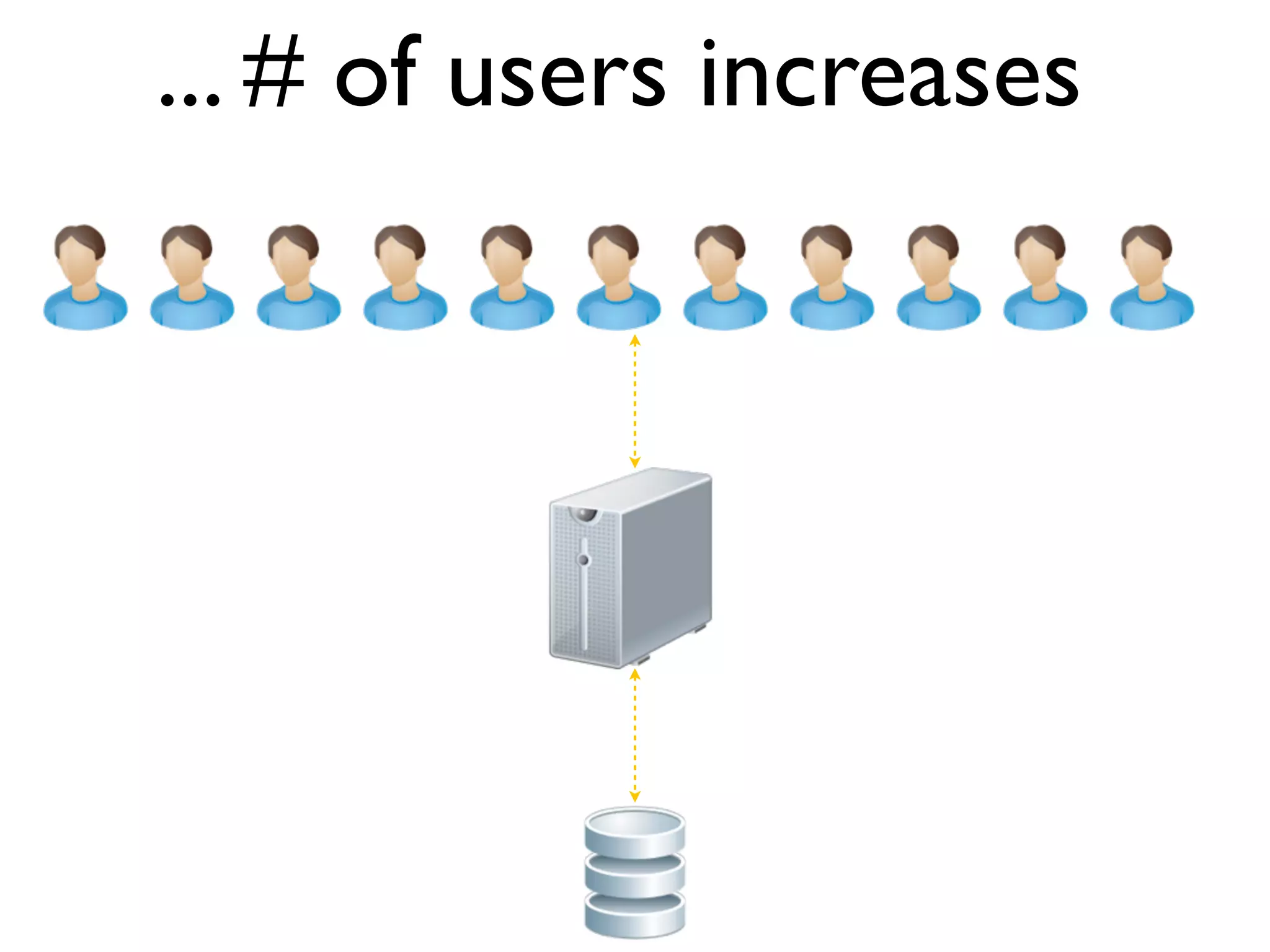
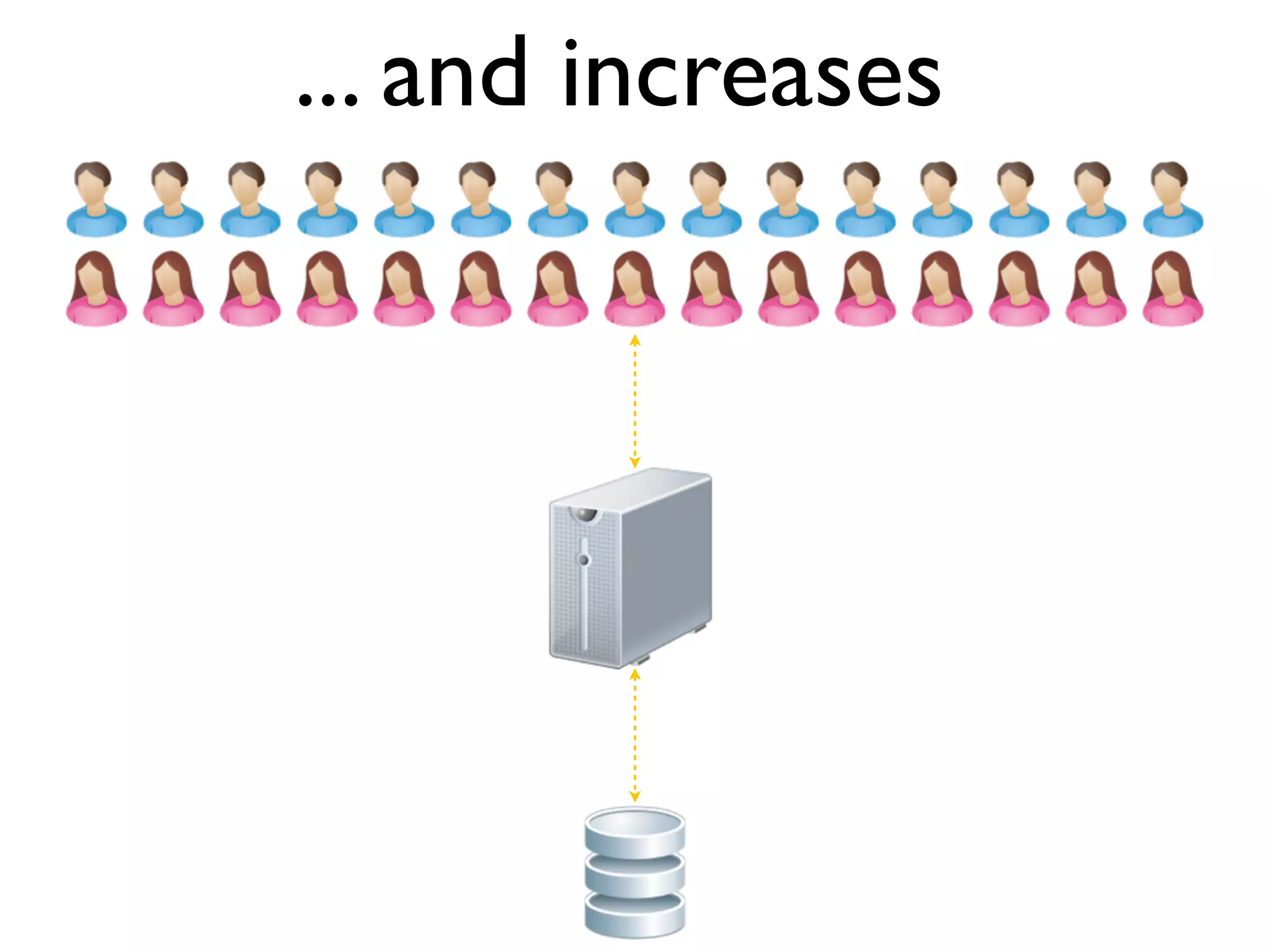
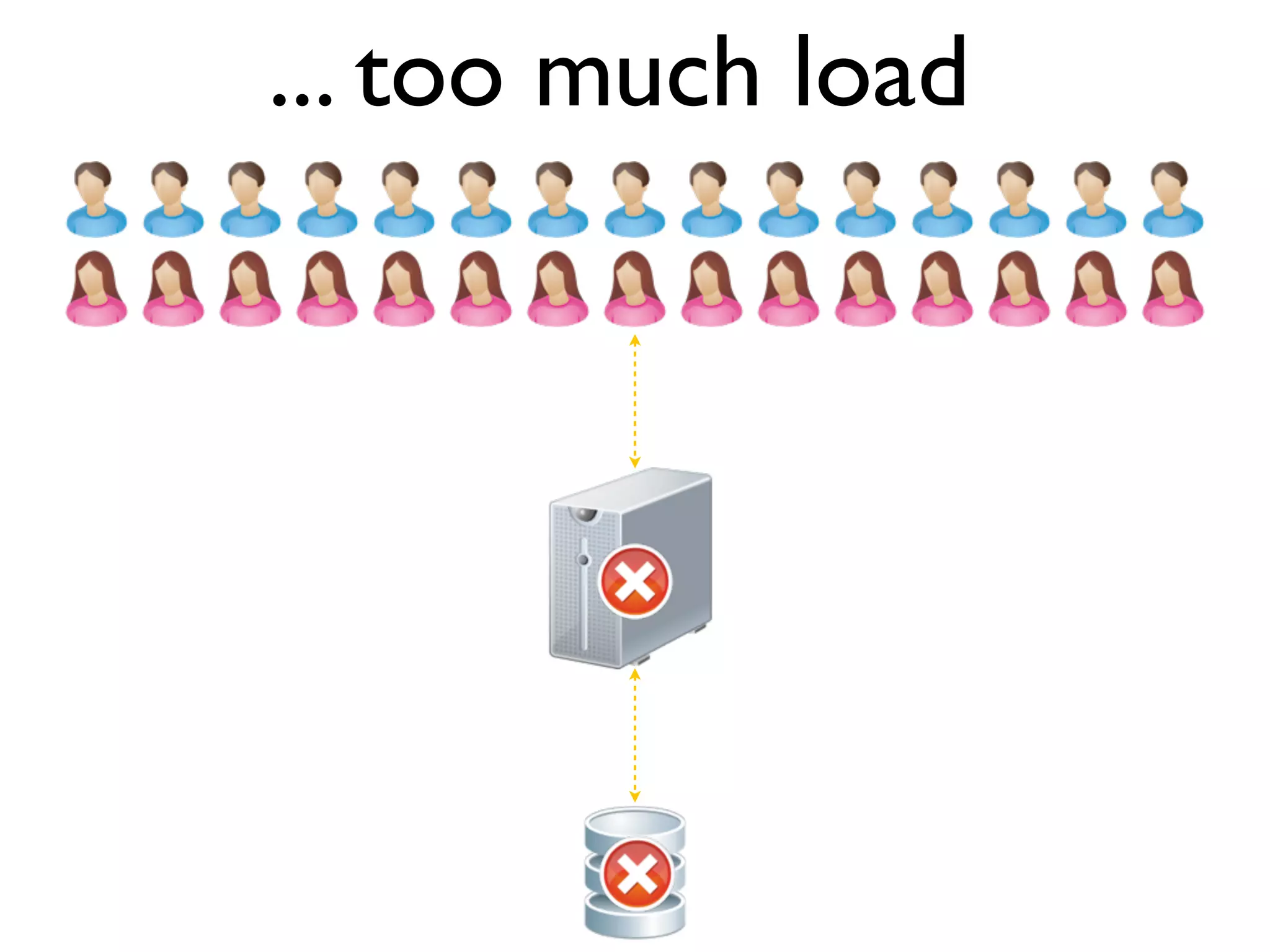
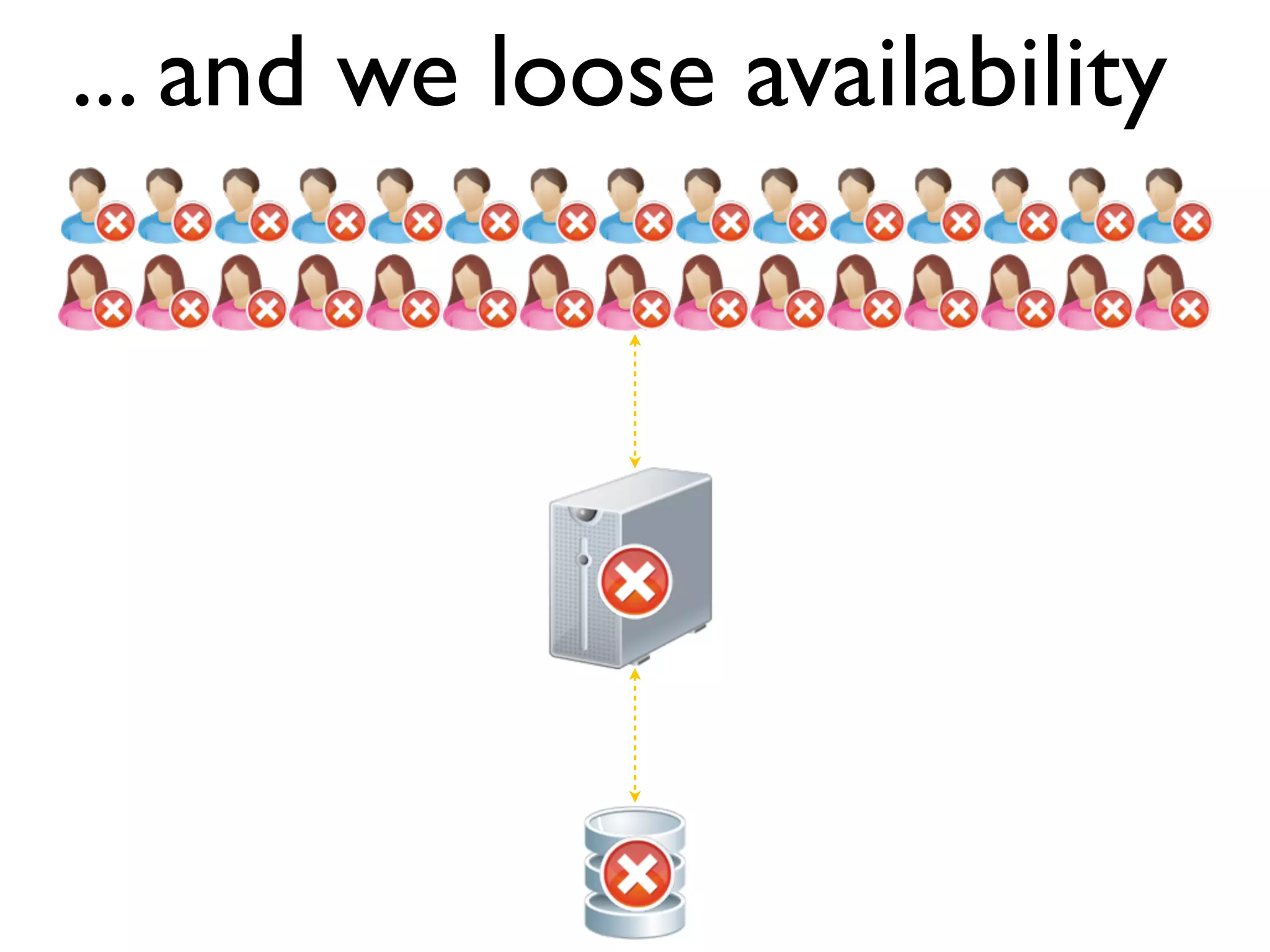
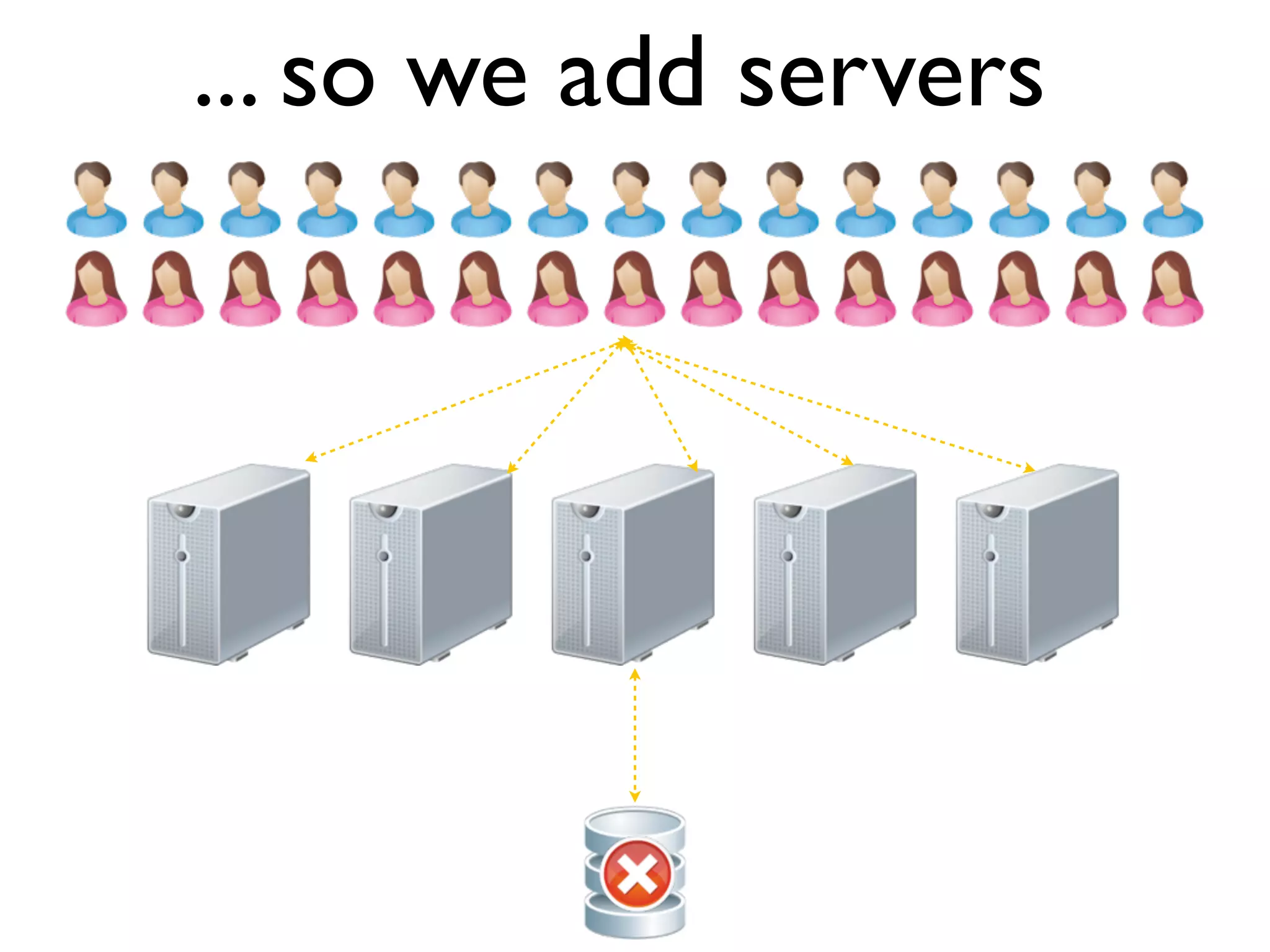
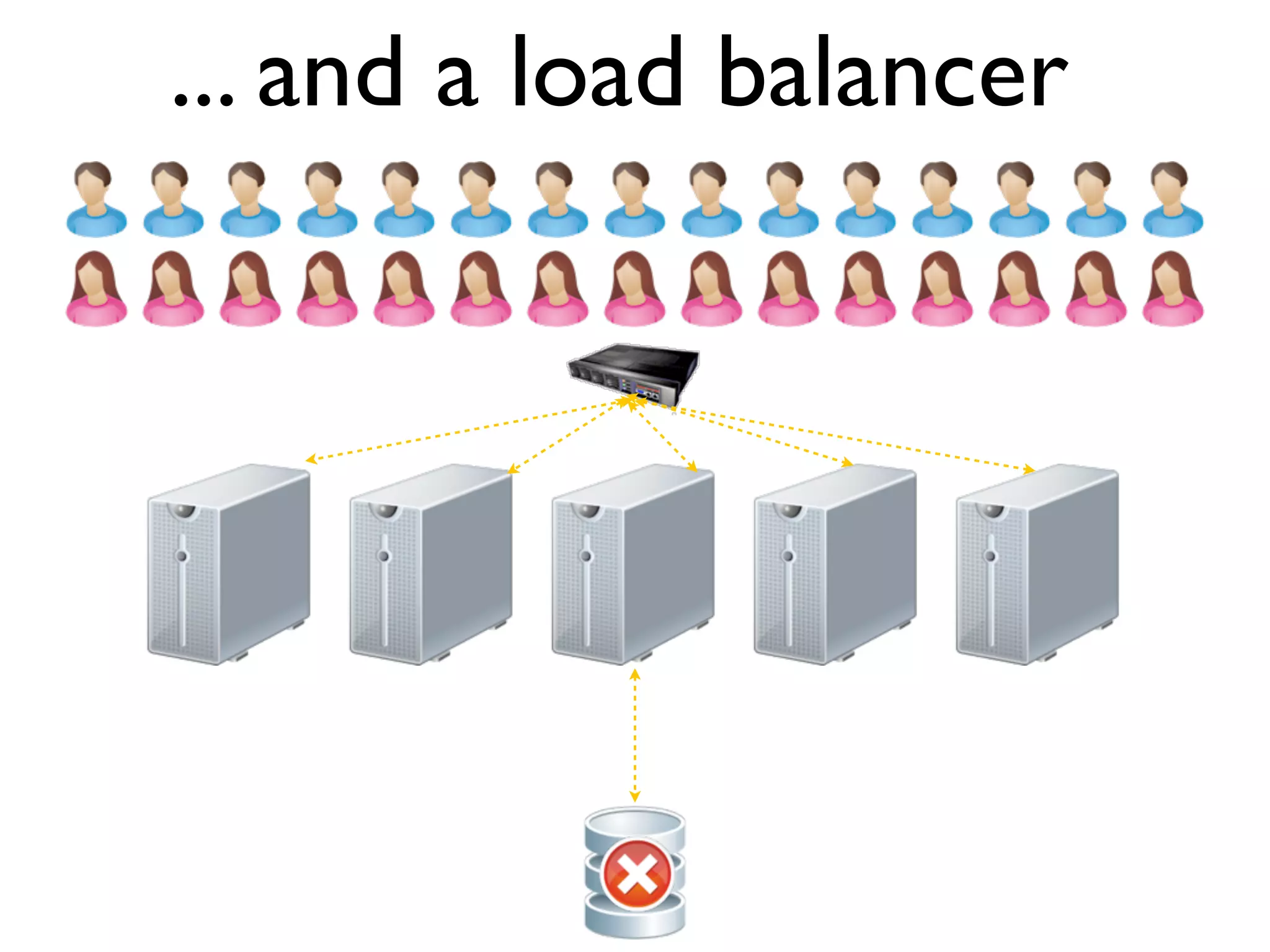
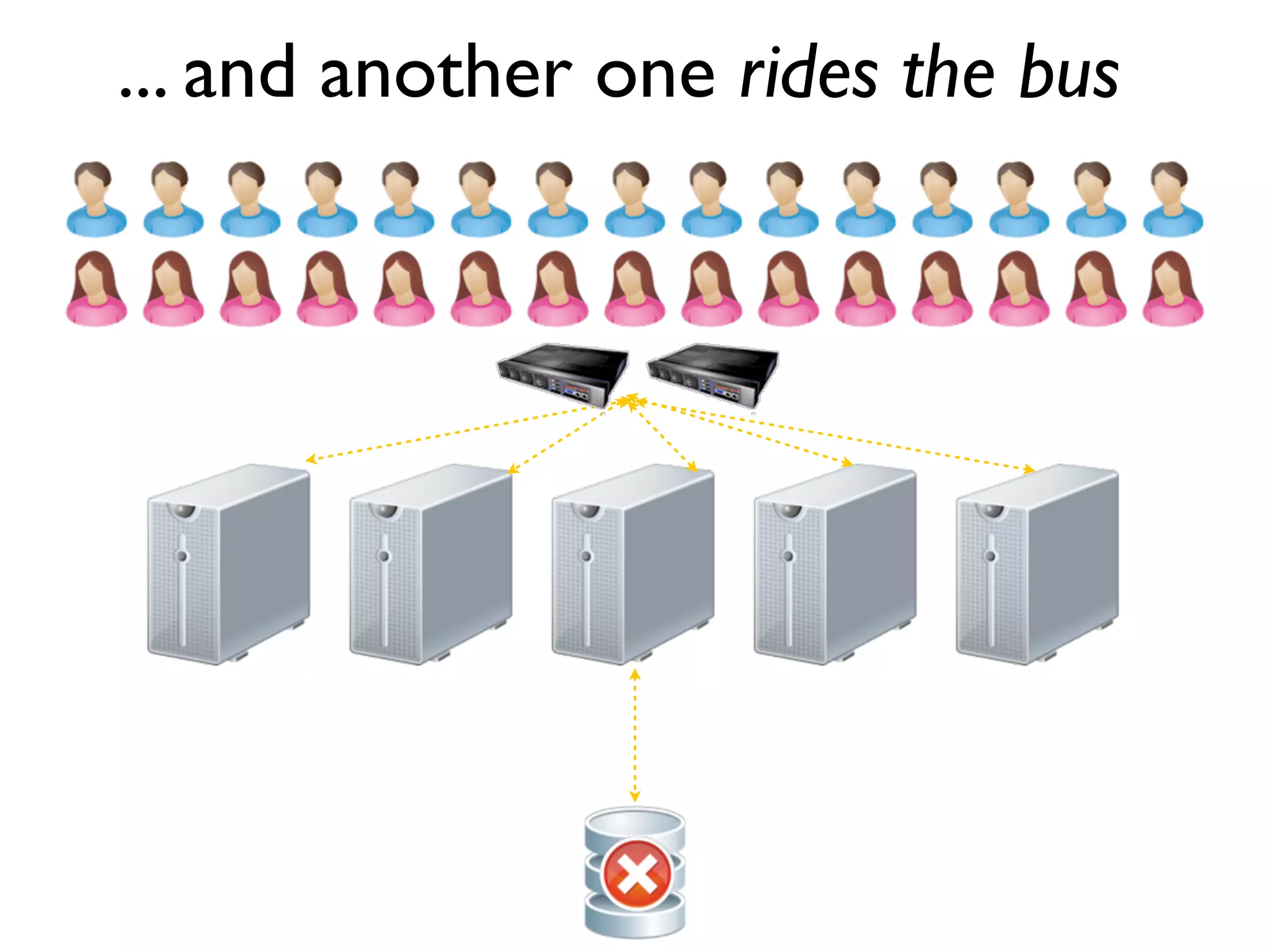
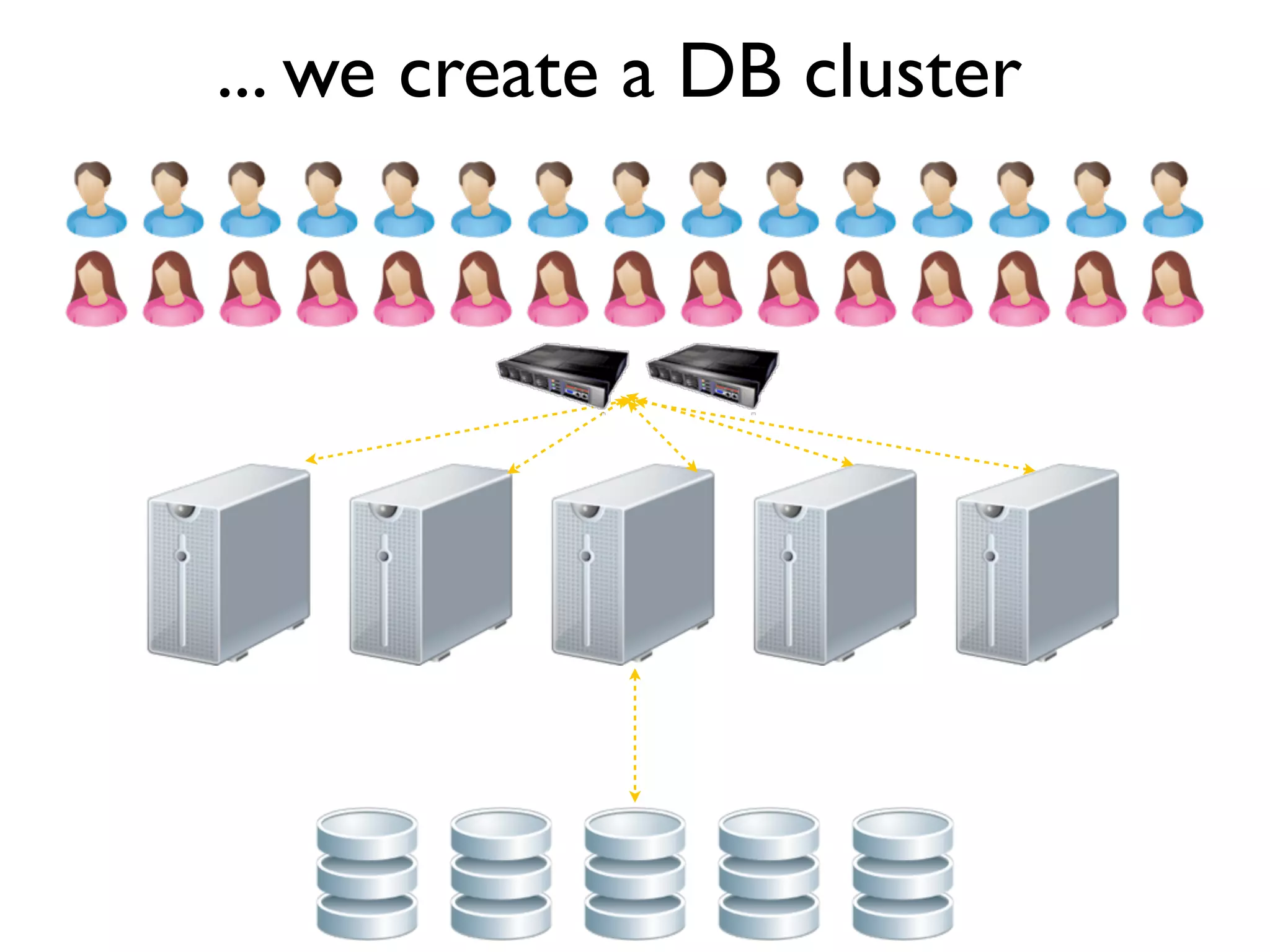


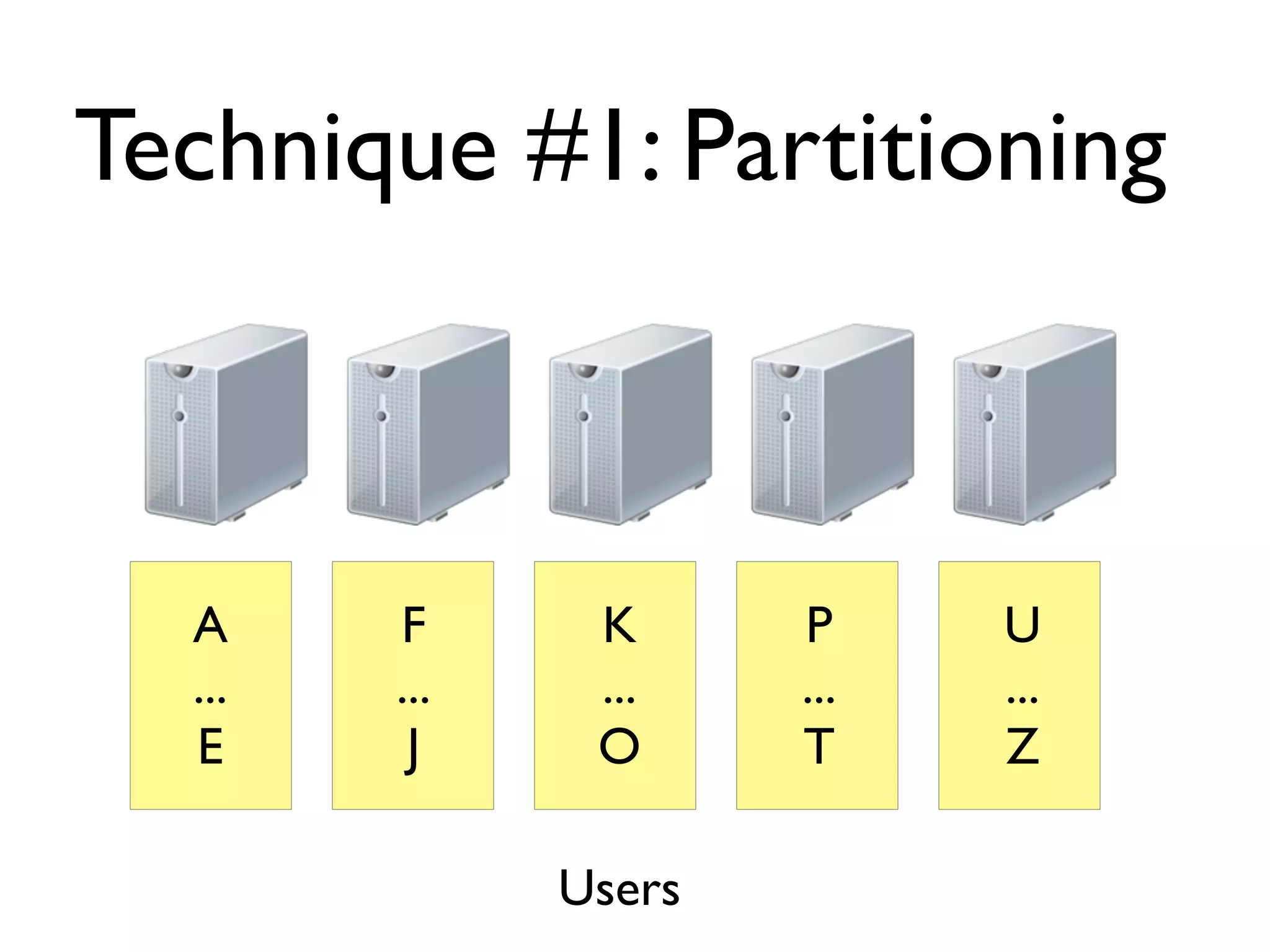



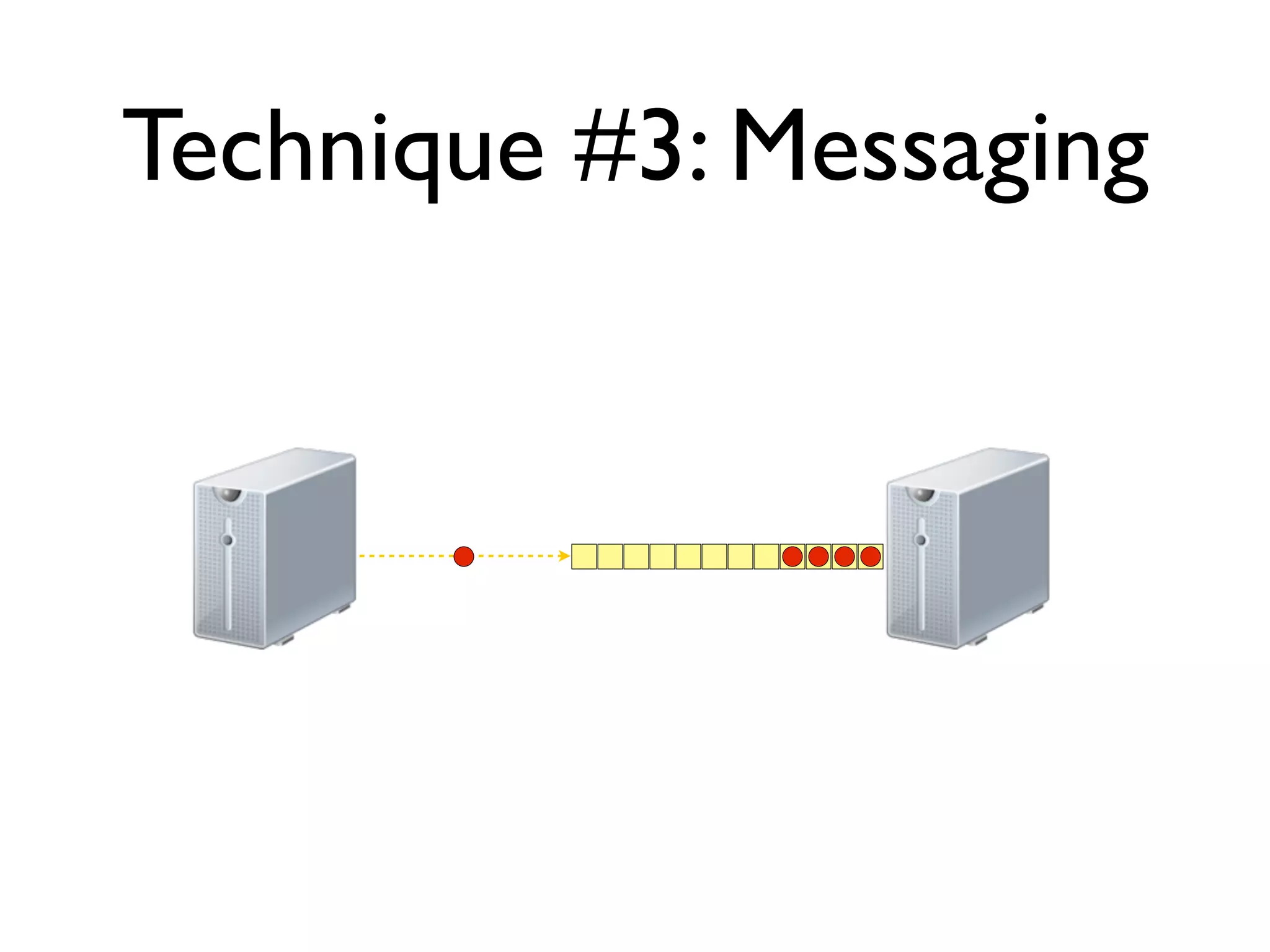







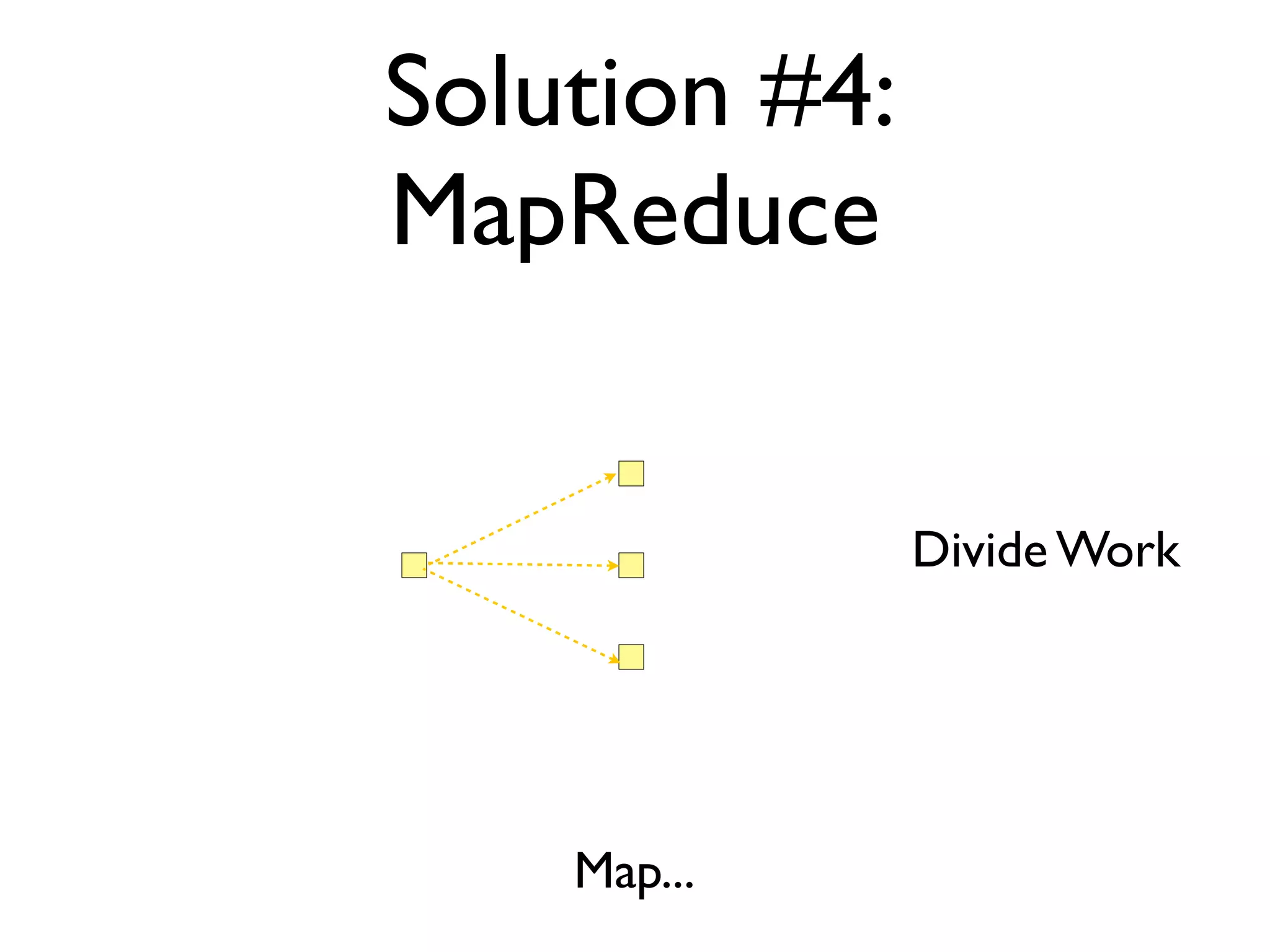
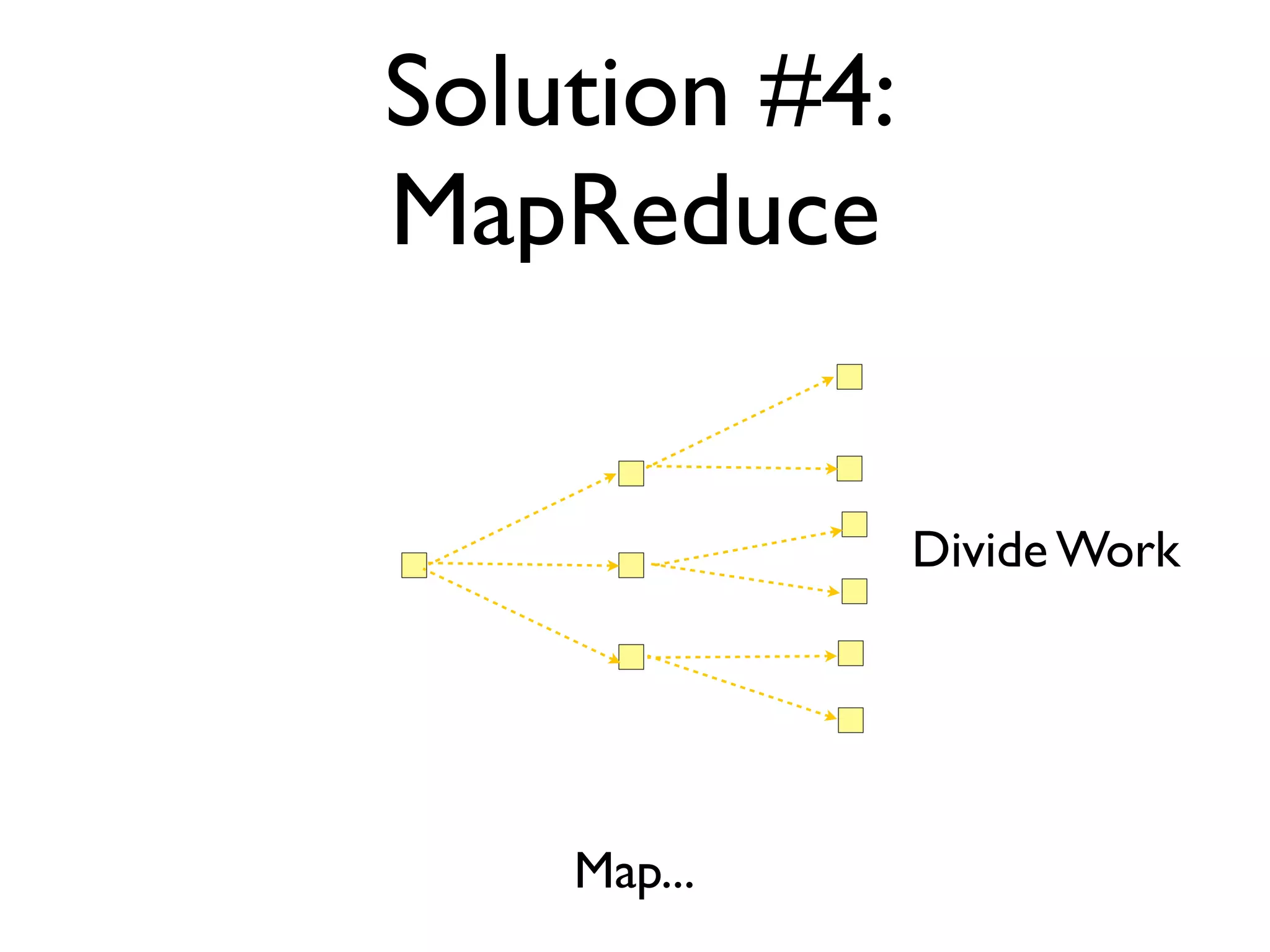
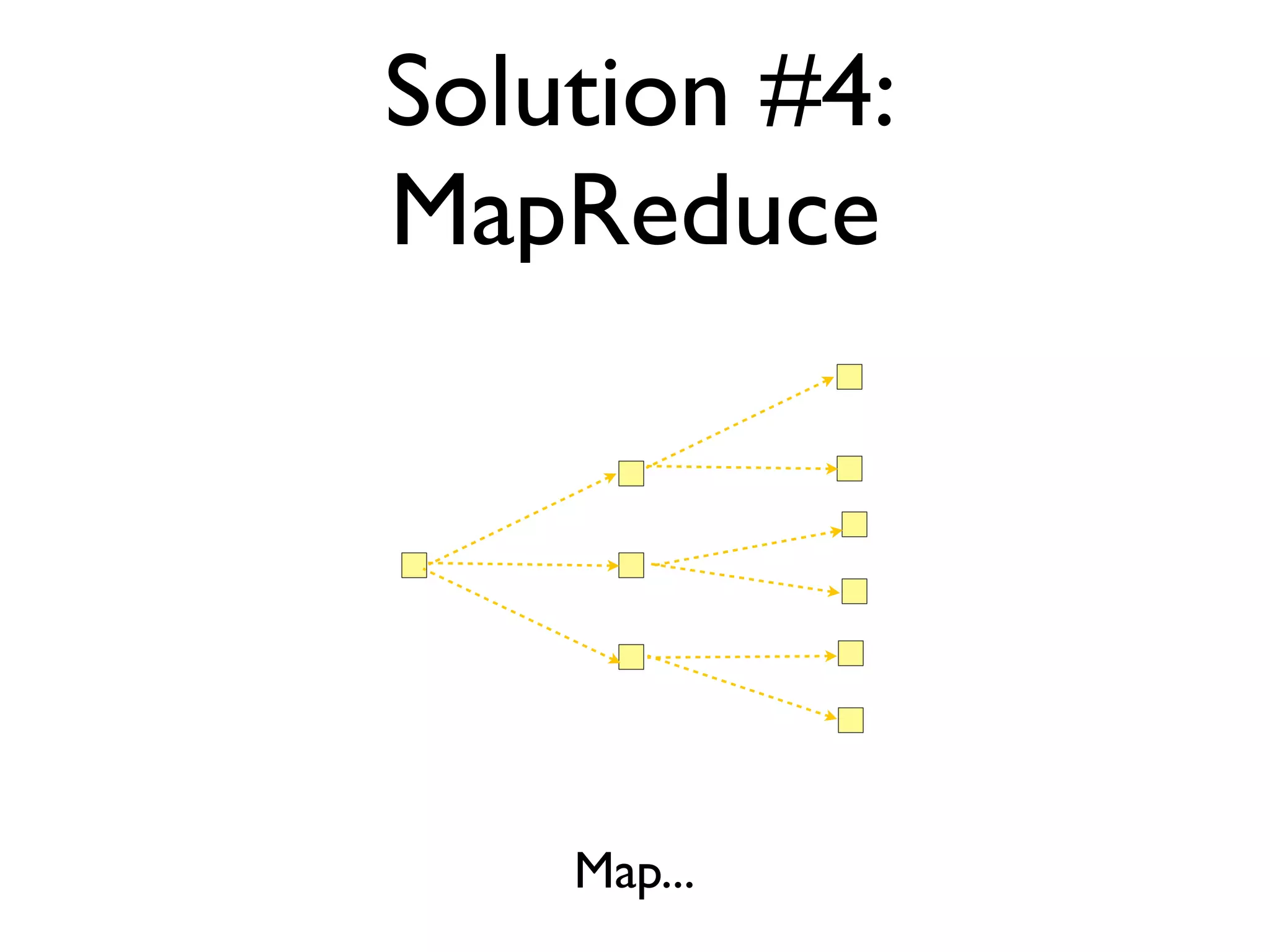
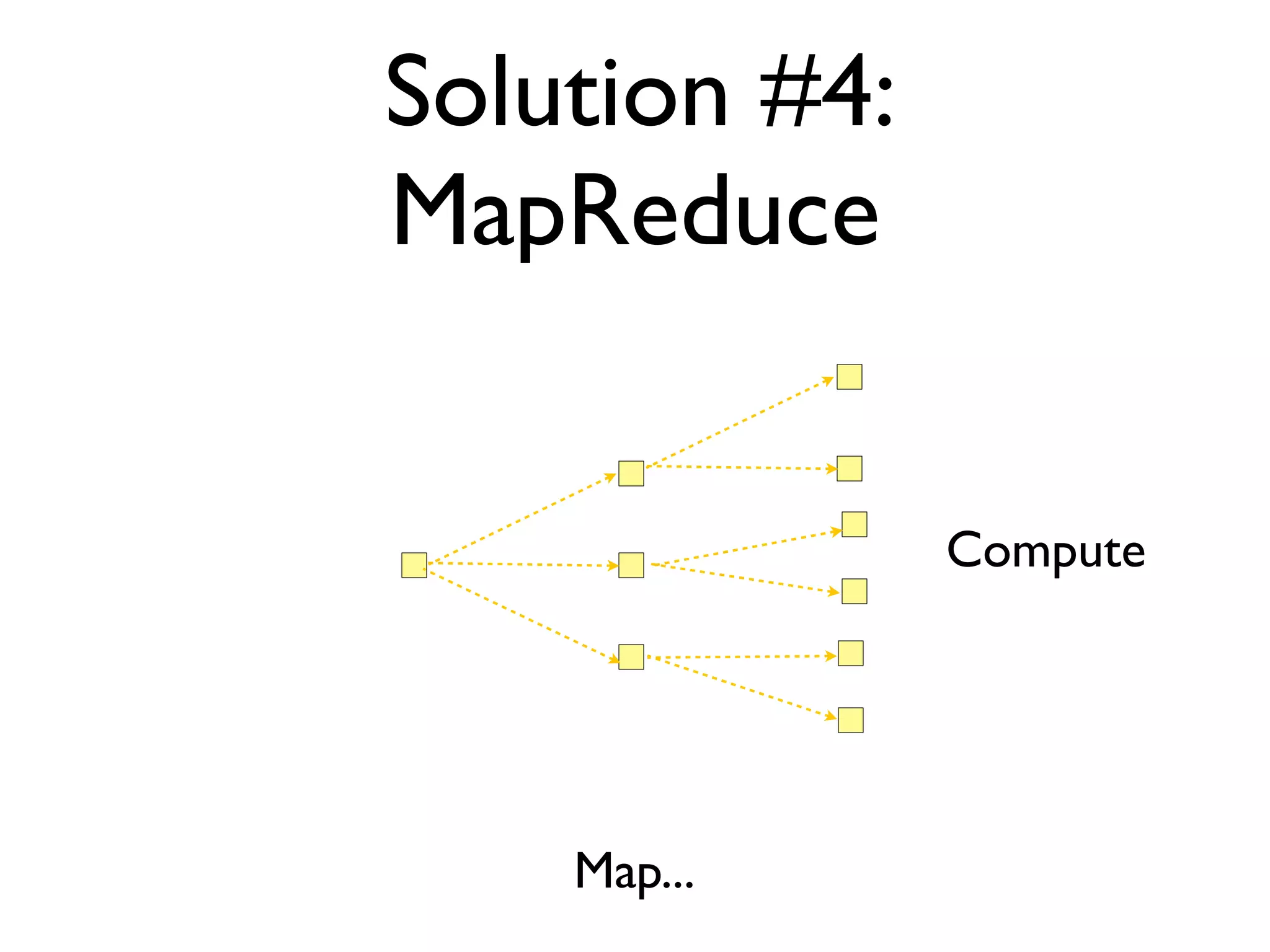
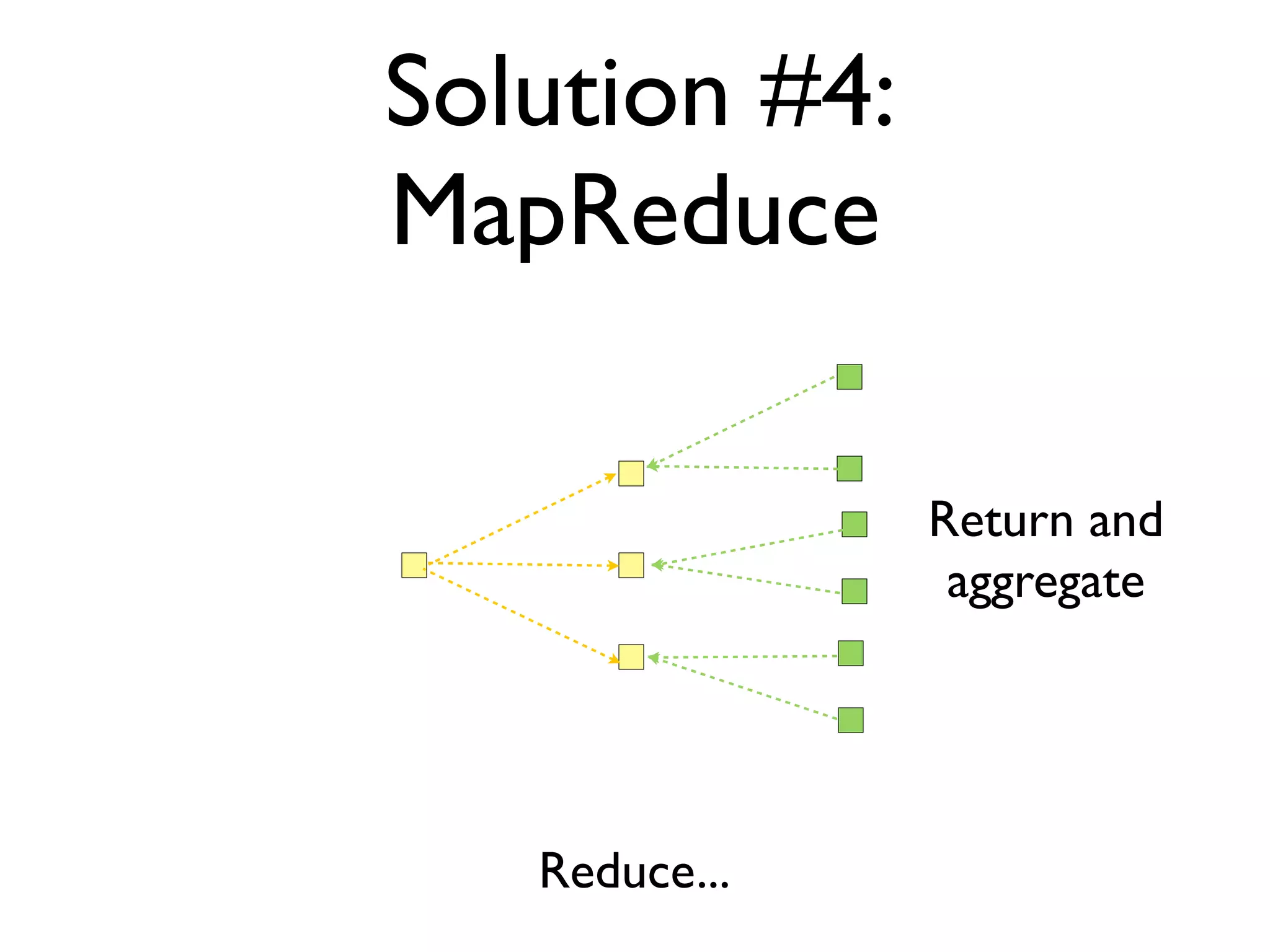
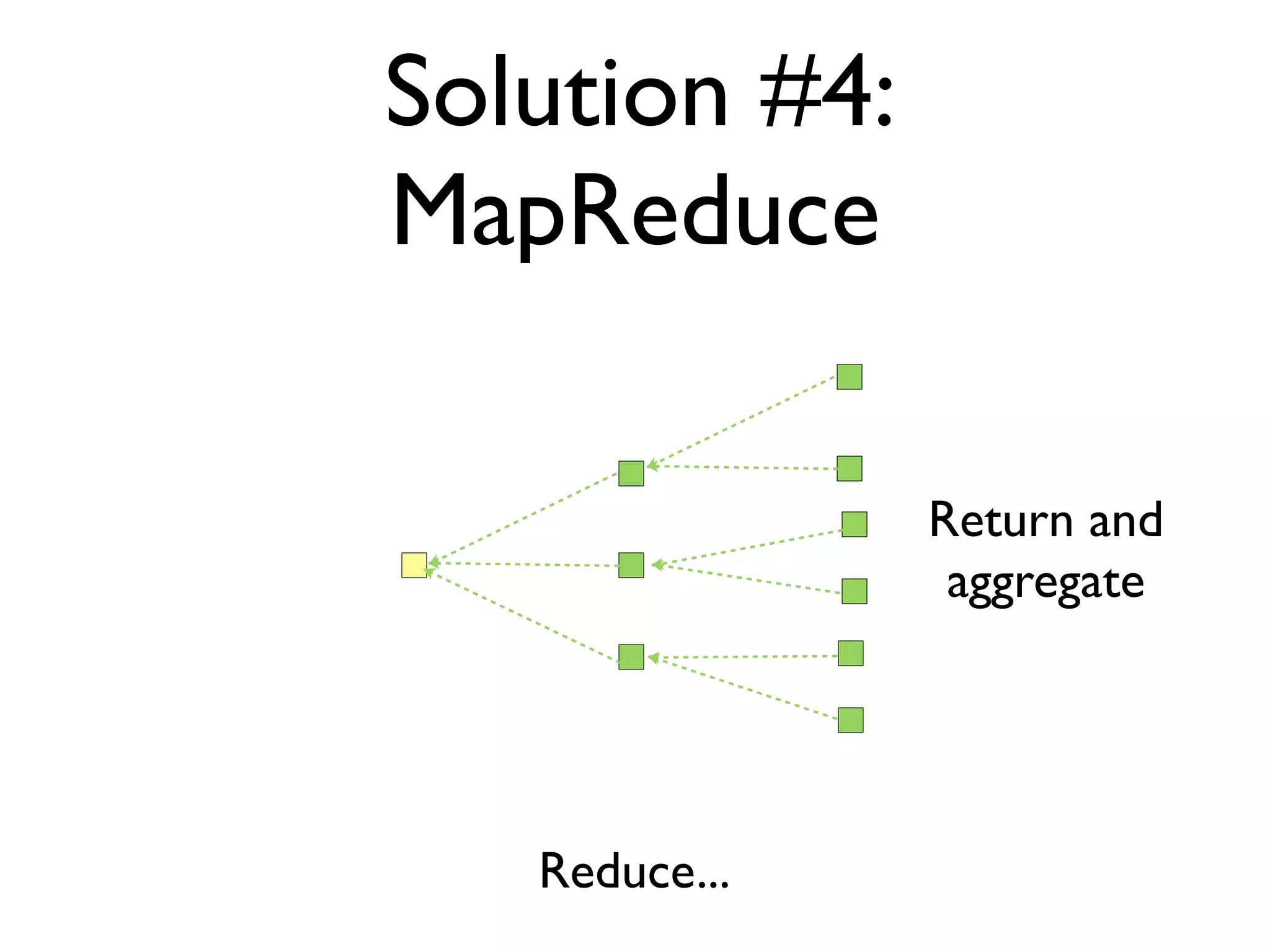
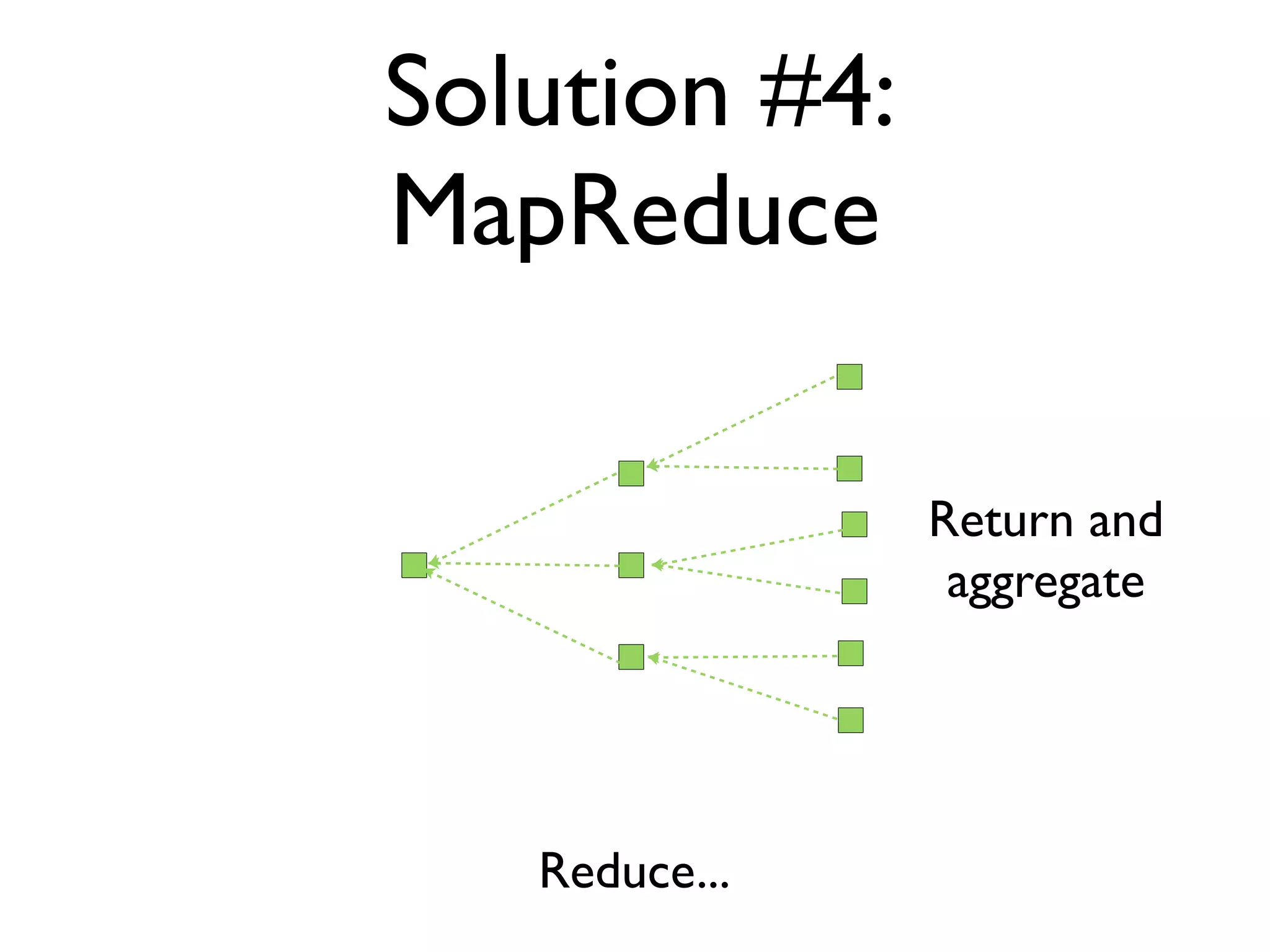






The document discusses strategies for writing scalable software in Java, emphasizing the differences between vertical and horizontal scalability. Key concepts include the importance of parallelizing work, reducing contention, and various techniques like partitioning, replication, and messaging for managing scalability in distributed systems. It also highlights modern solutions like non-SQL databases, distributed key/value stores, MapReduce, and data grids to enhance performance and reliability.























































































