Download as PDF, PPTX




























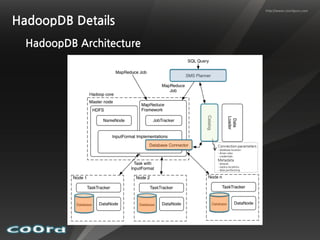













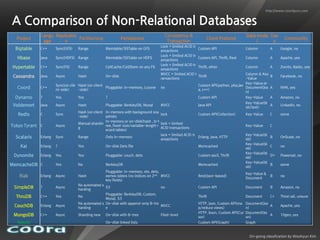





Hybrid systems that integrate MapReduce and RDBMS aim to combine the best of both worlds. In-database MapReduce systems like Greenplum and HadoopDB run MapReduce programs directly on relational data for high performance and to leverage existing RDBMS features like SQL, security, backup/recovery and analytics tools. File-only systems like Pig and Hive are easier for developers but provide less integration with RDBMS functionality. Overall the relationship between MapReduce and RDBMS continues to evolve as each aims to address the other's limitations.















































