Downloaded 116 times








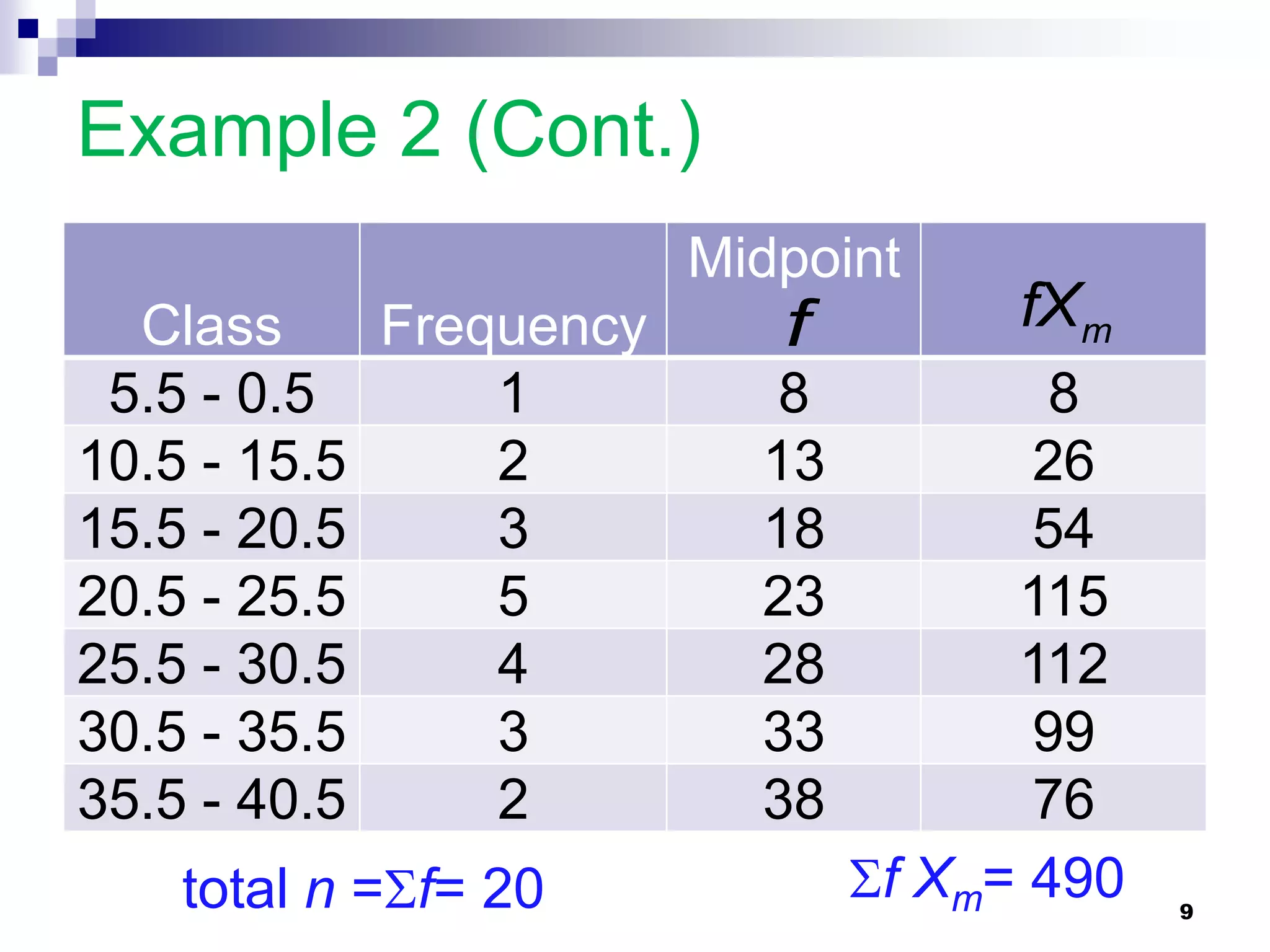













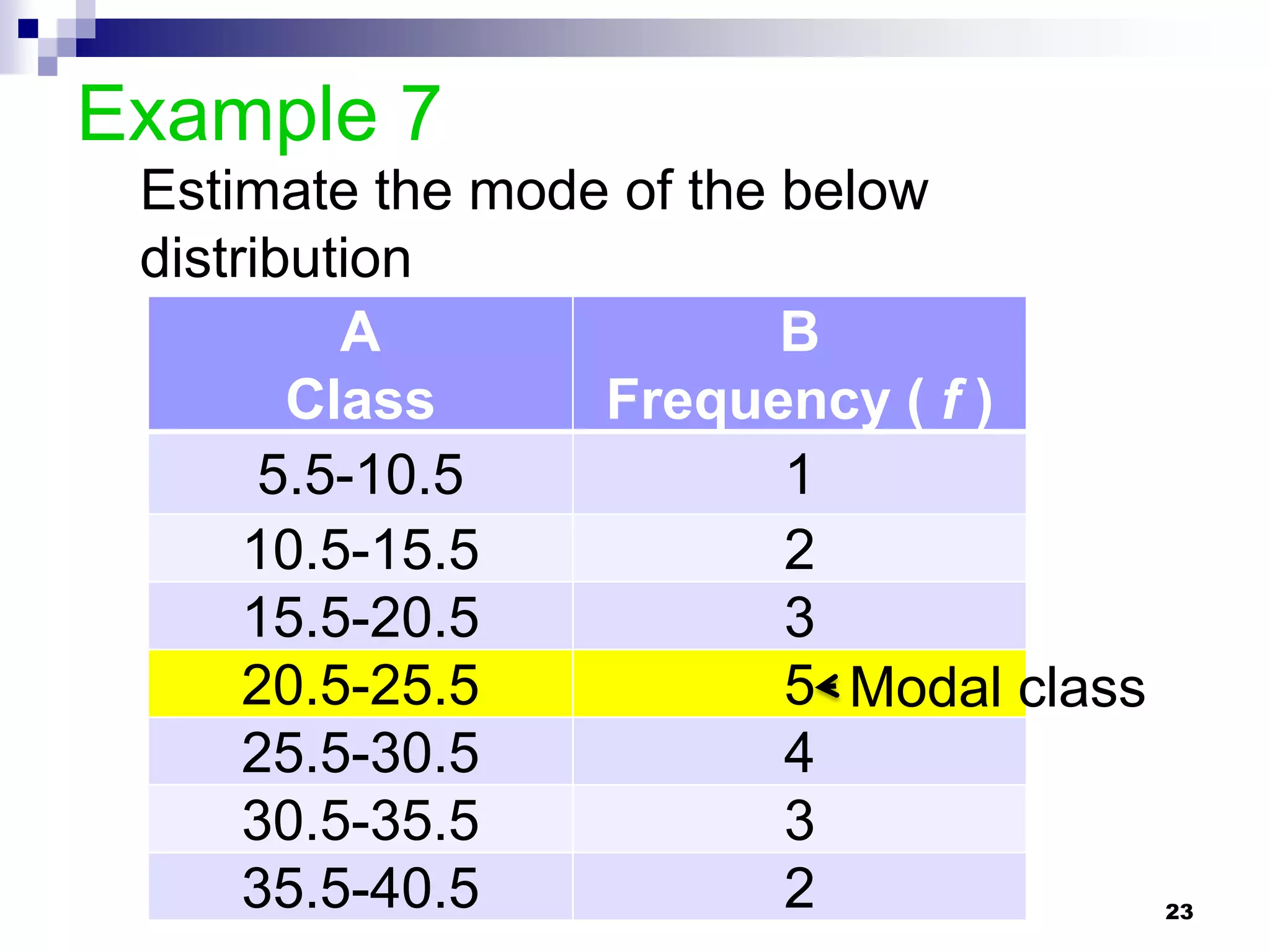





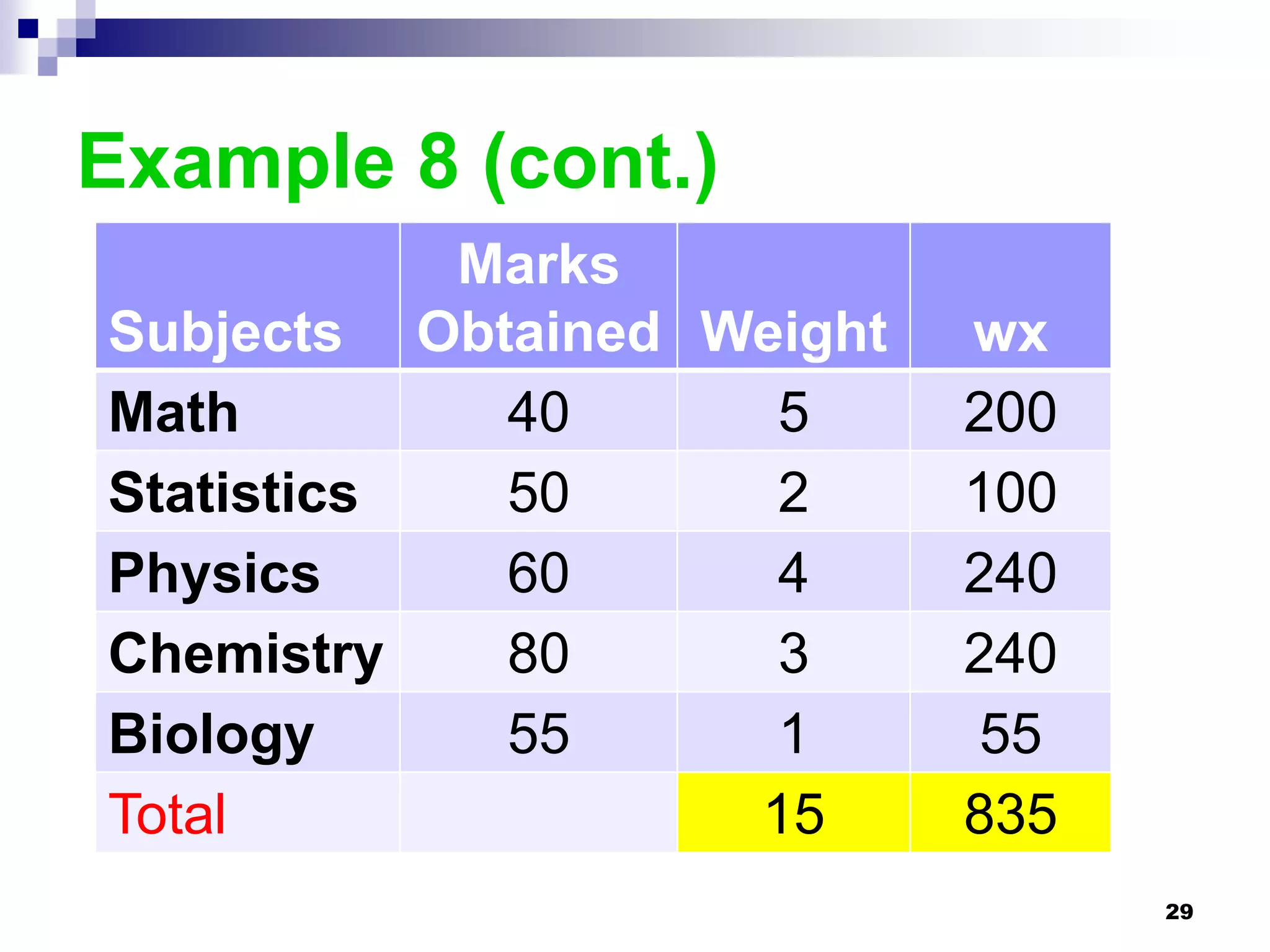

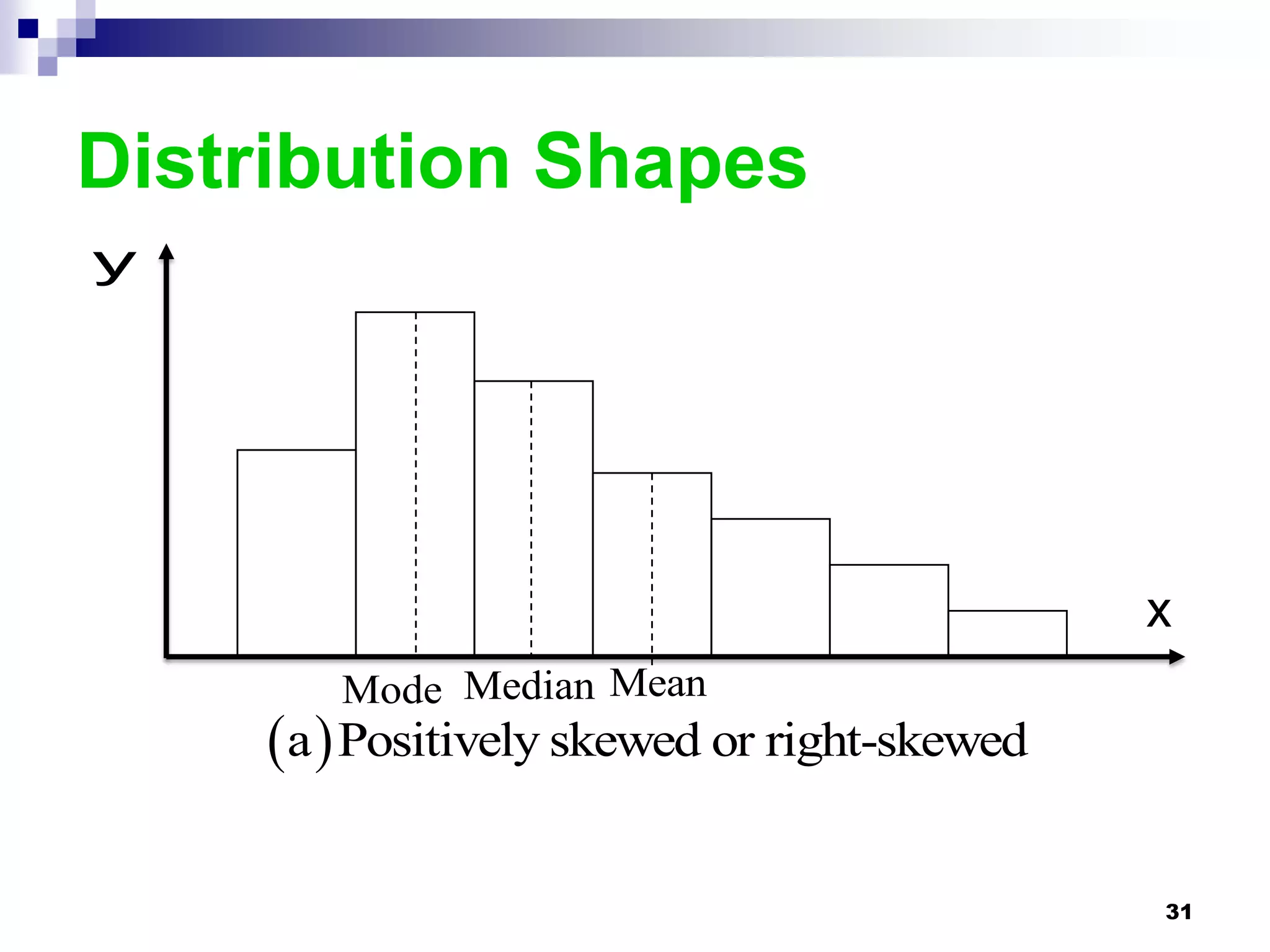
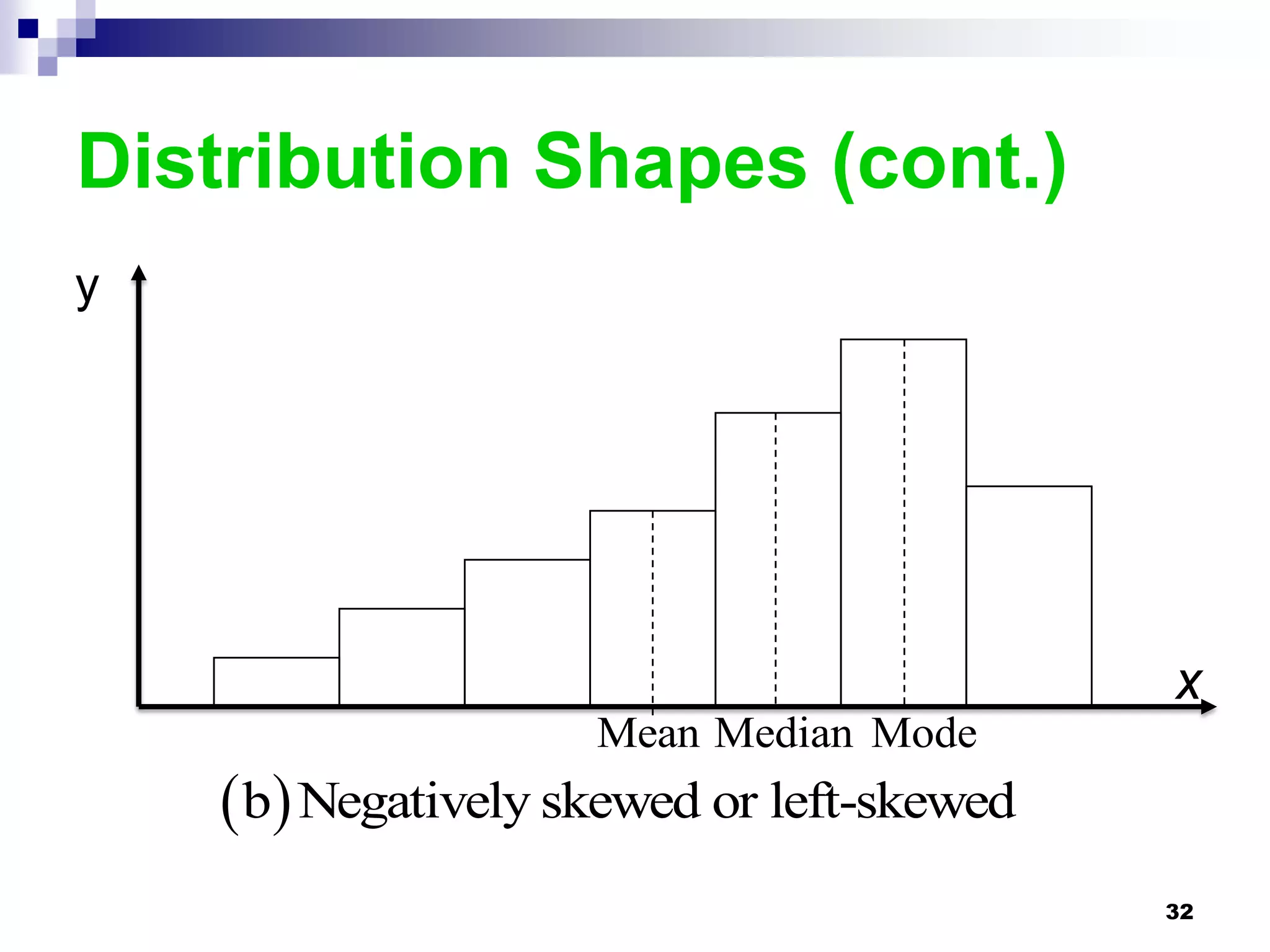
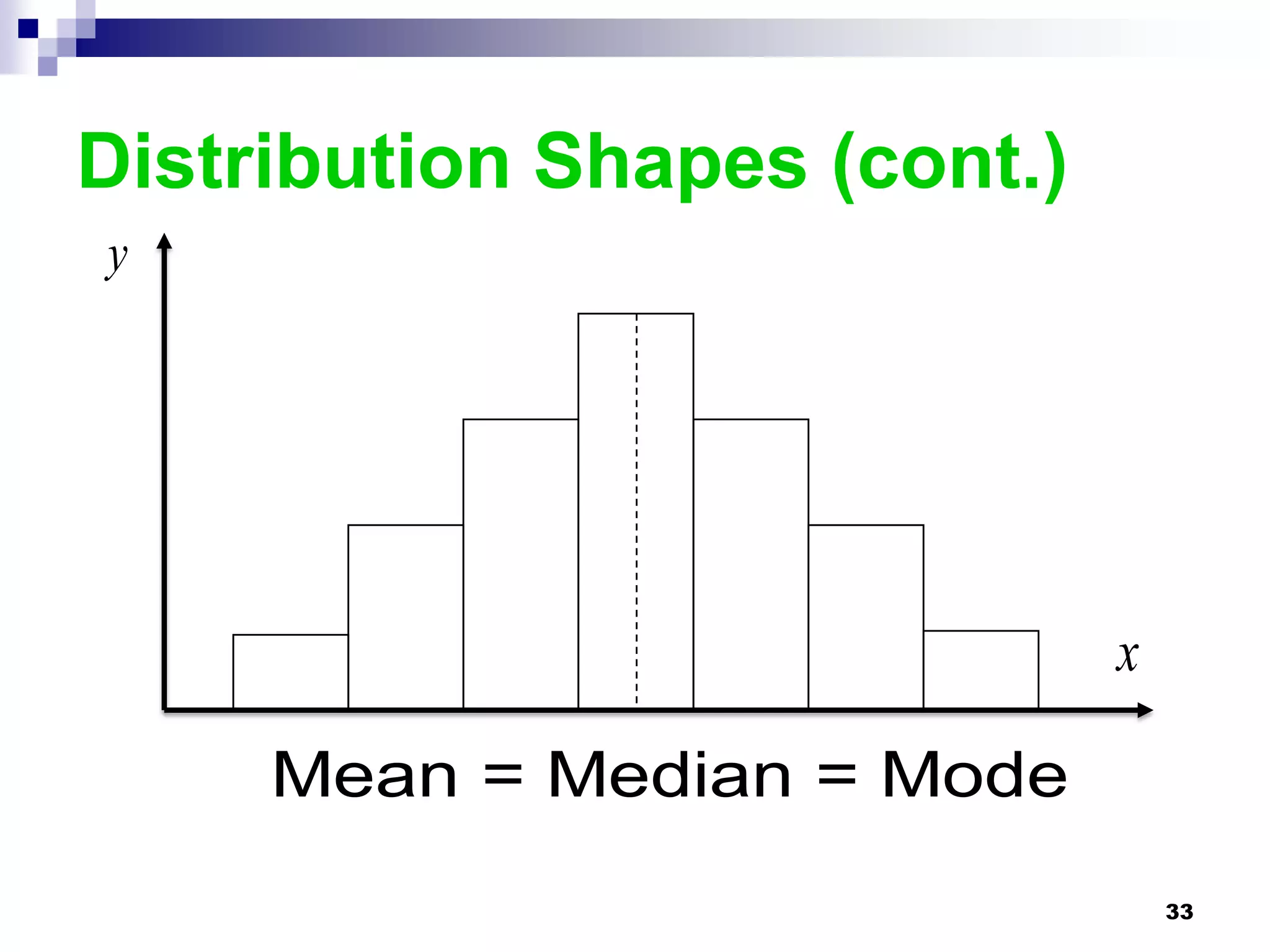




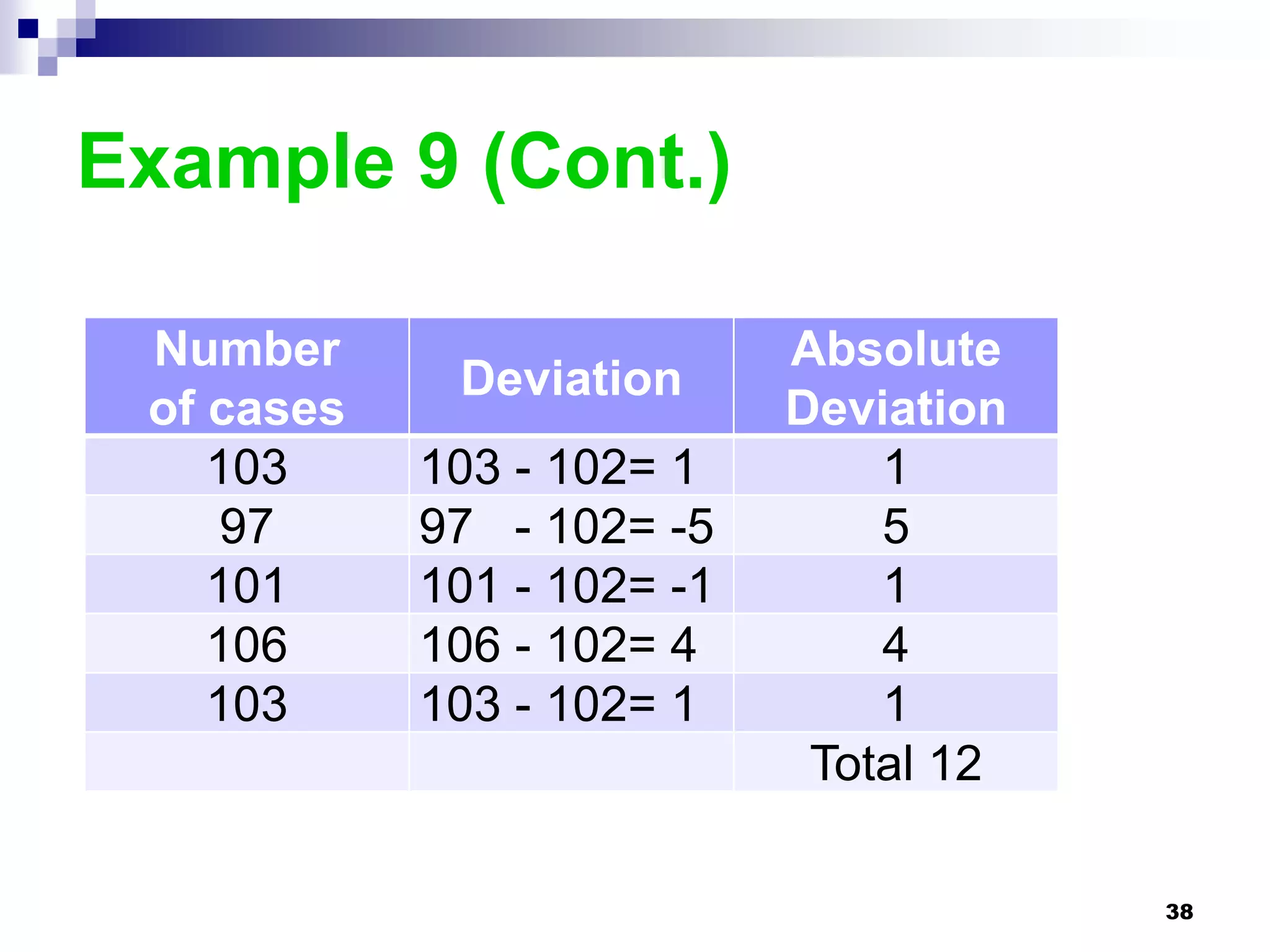




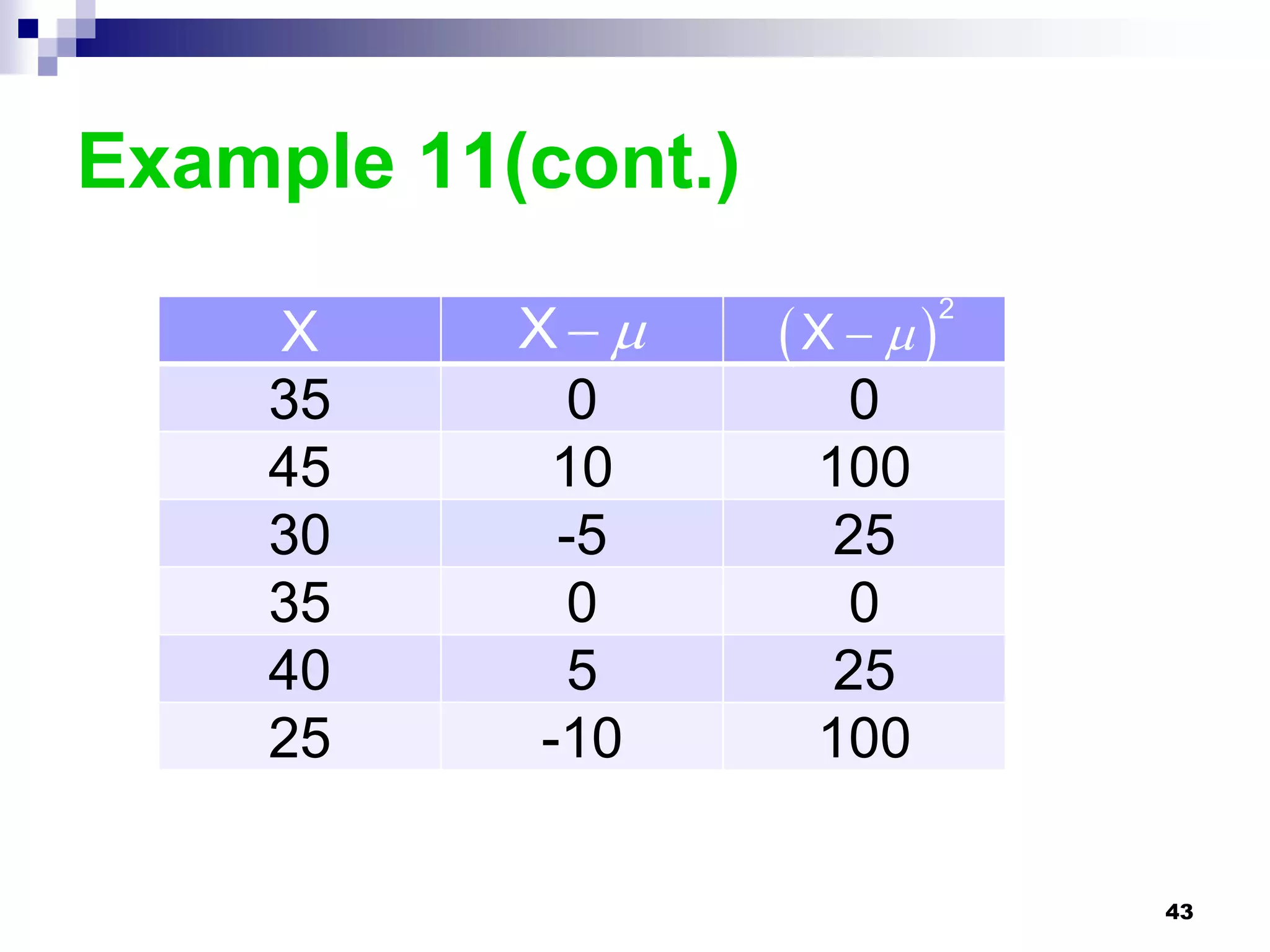










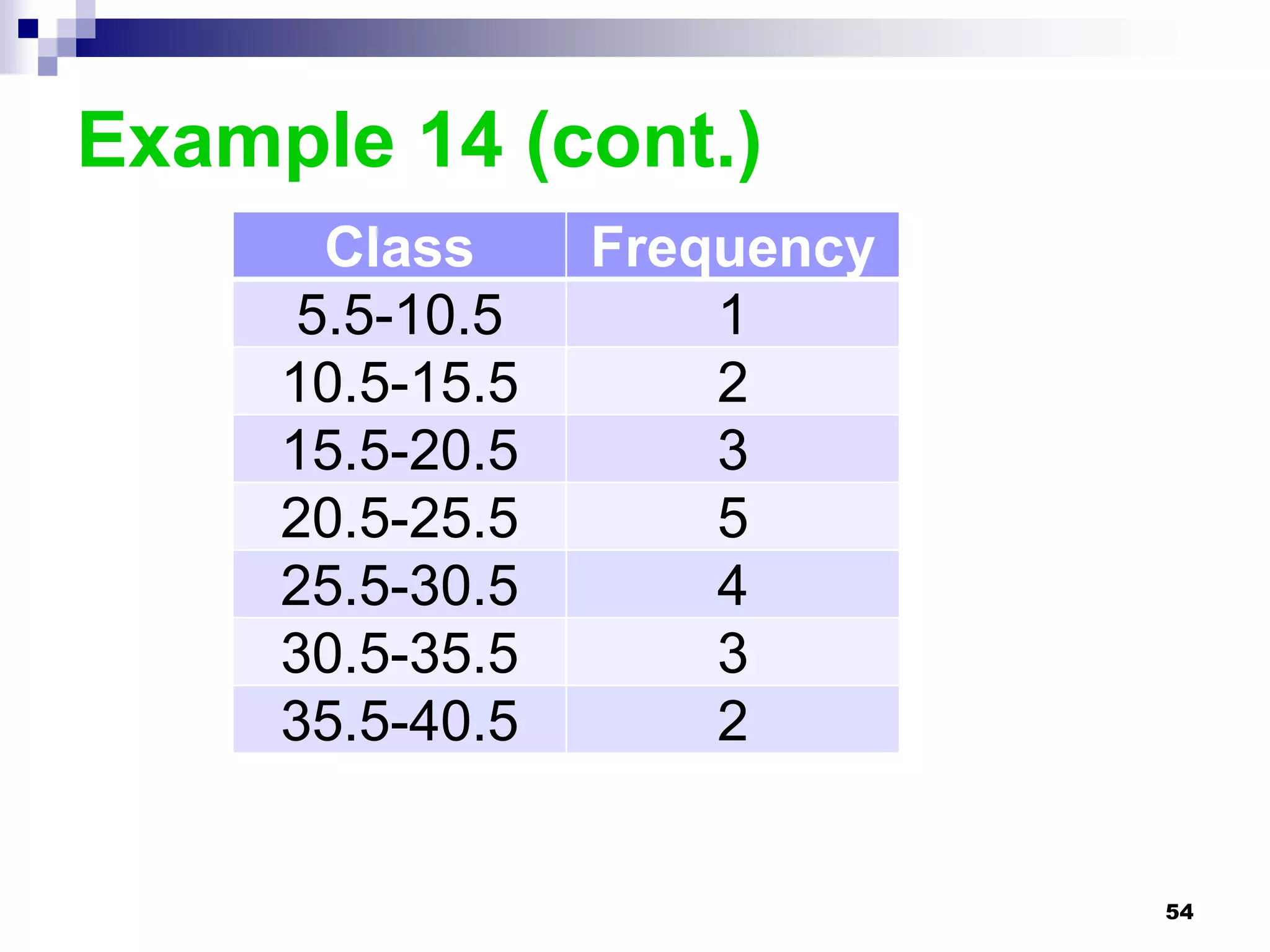
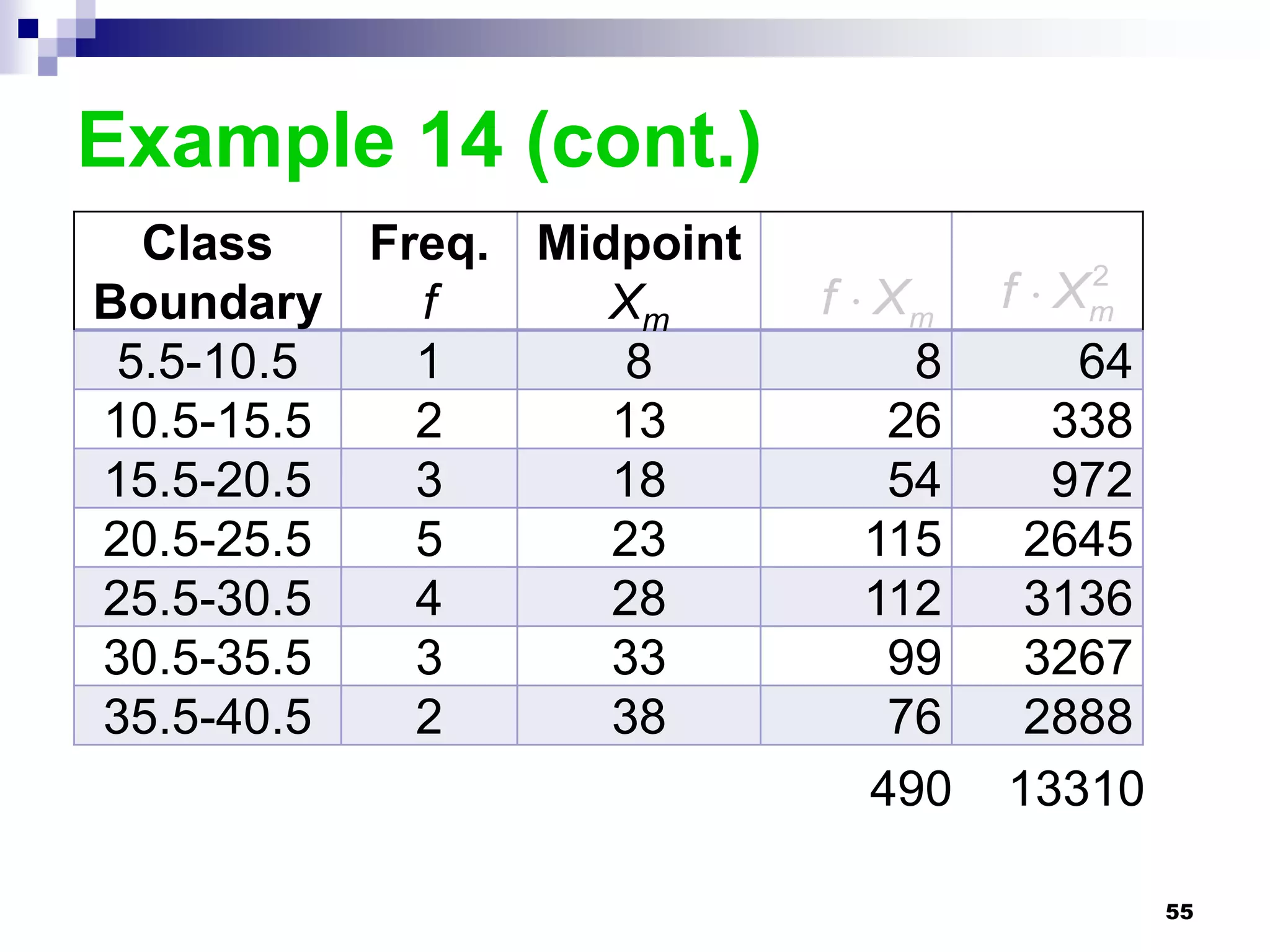






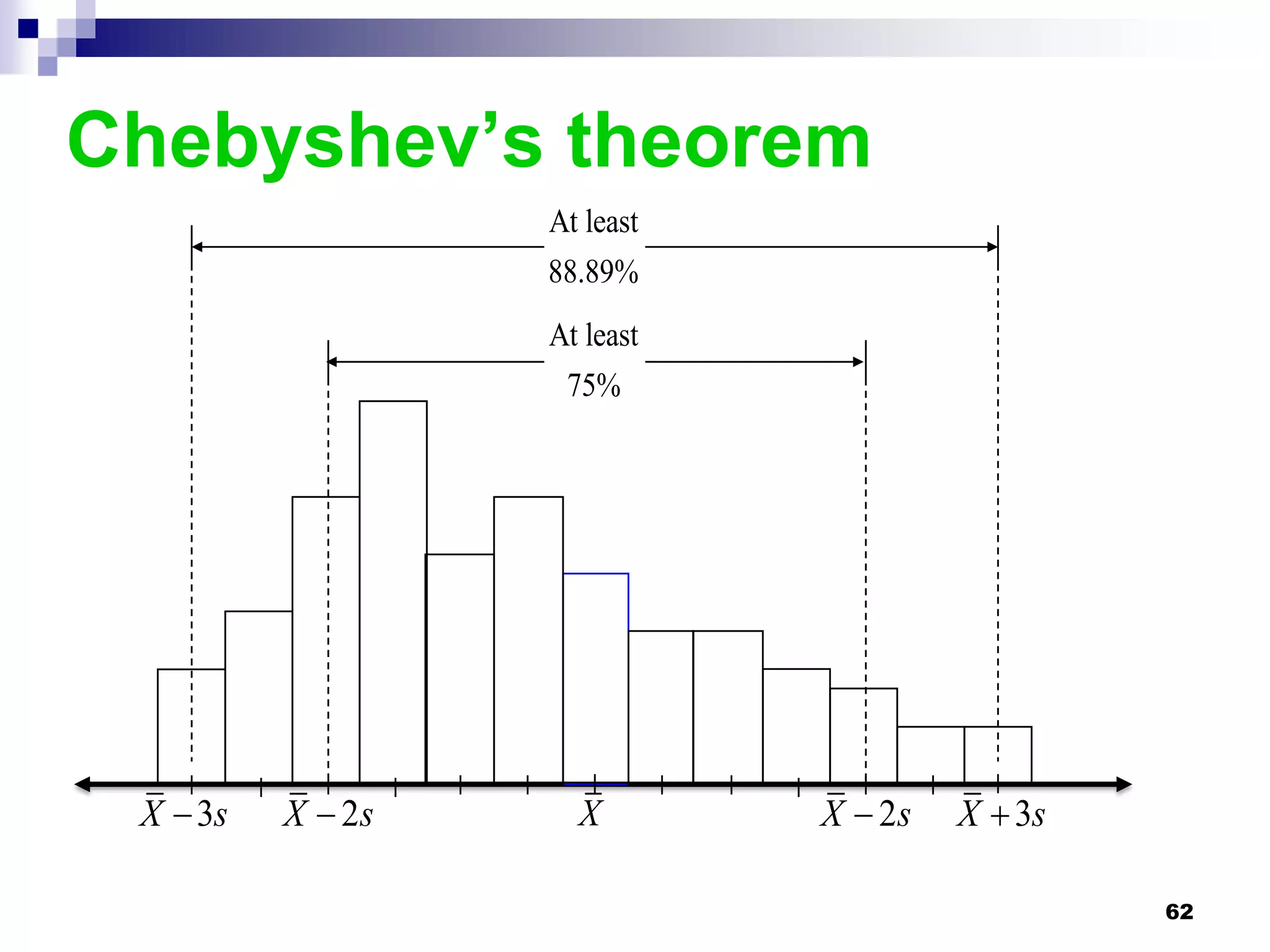





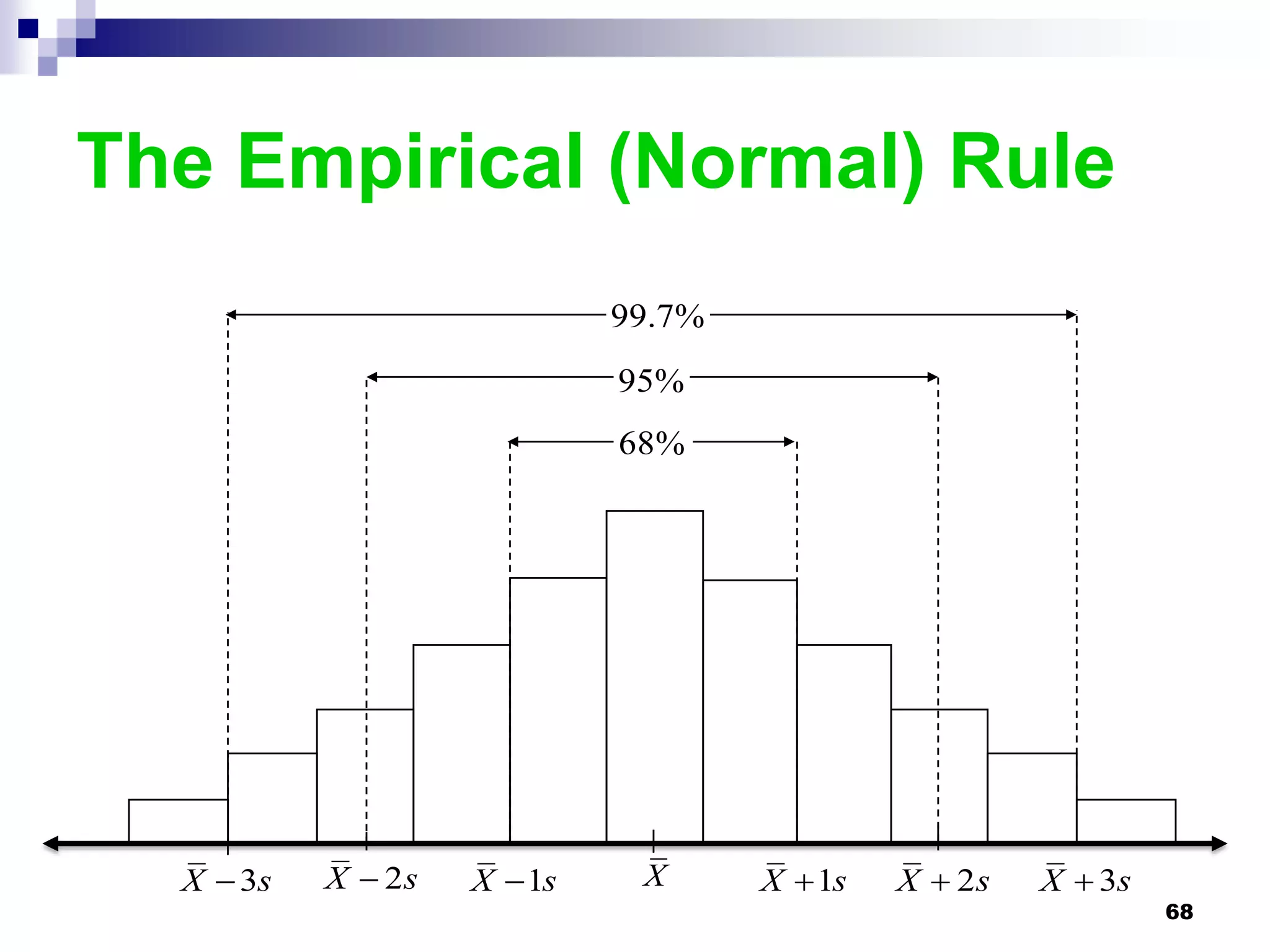













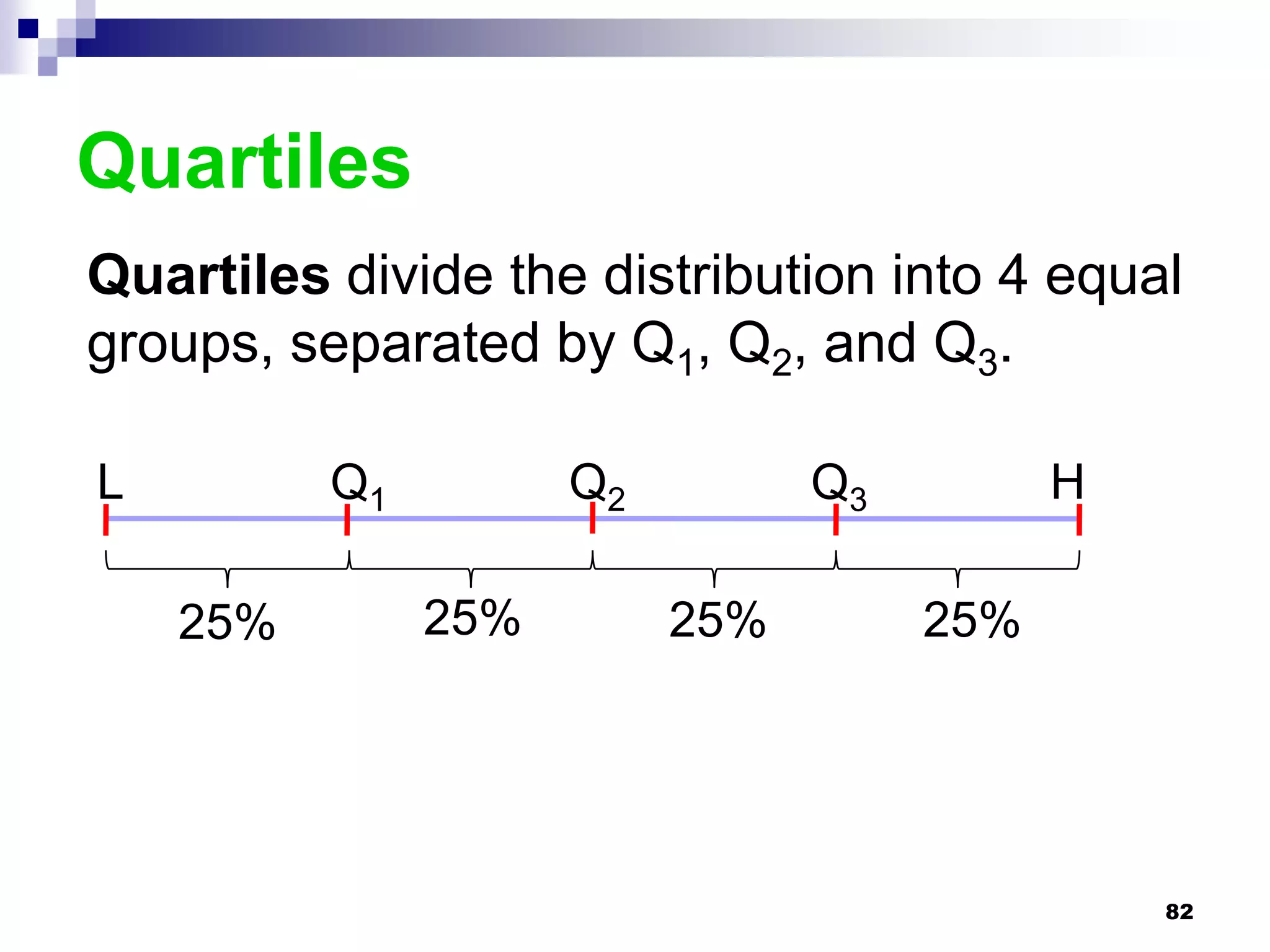







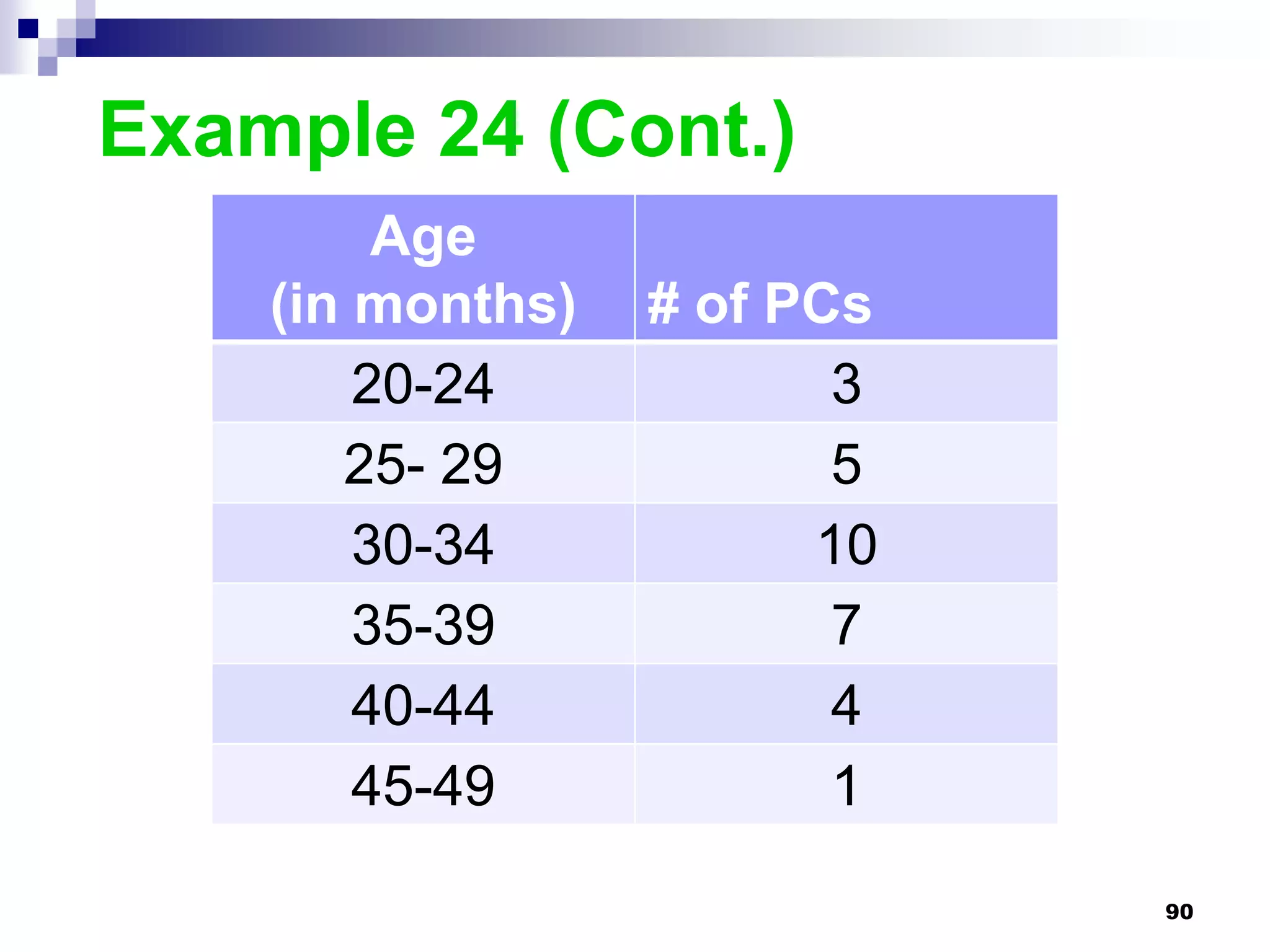
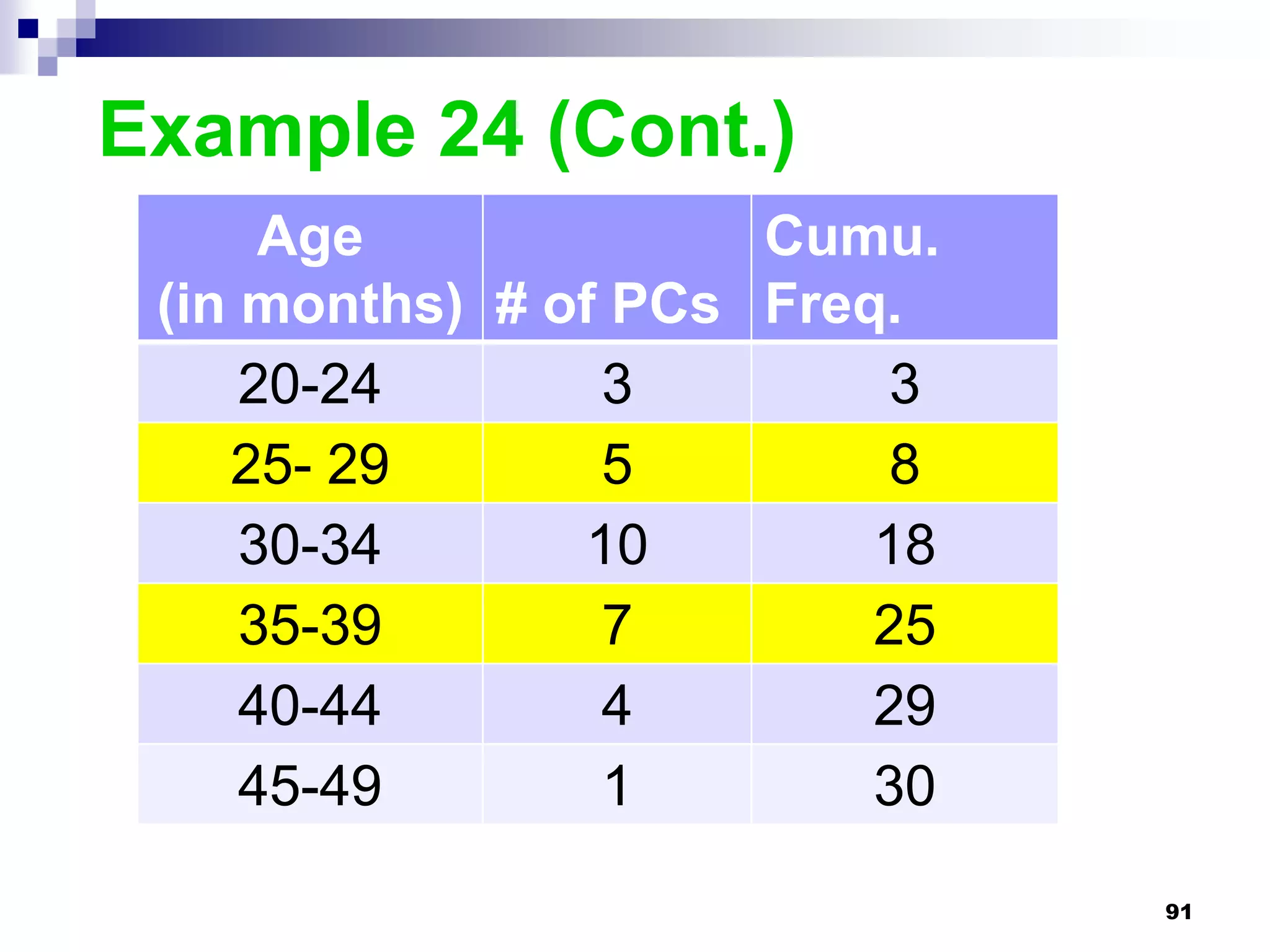


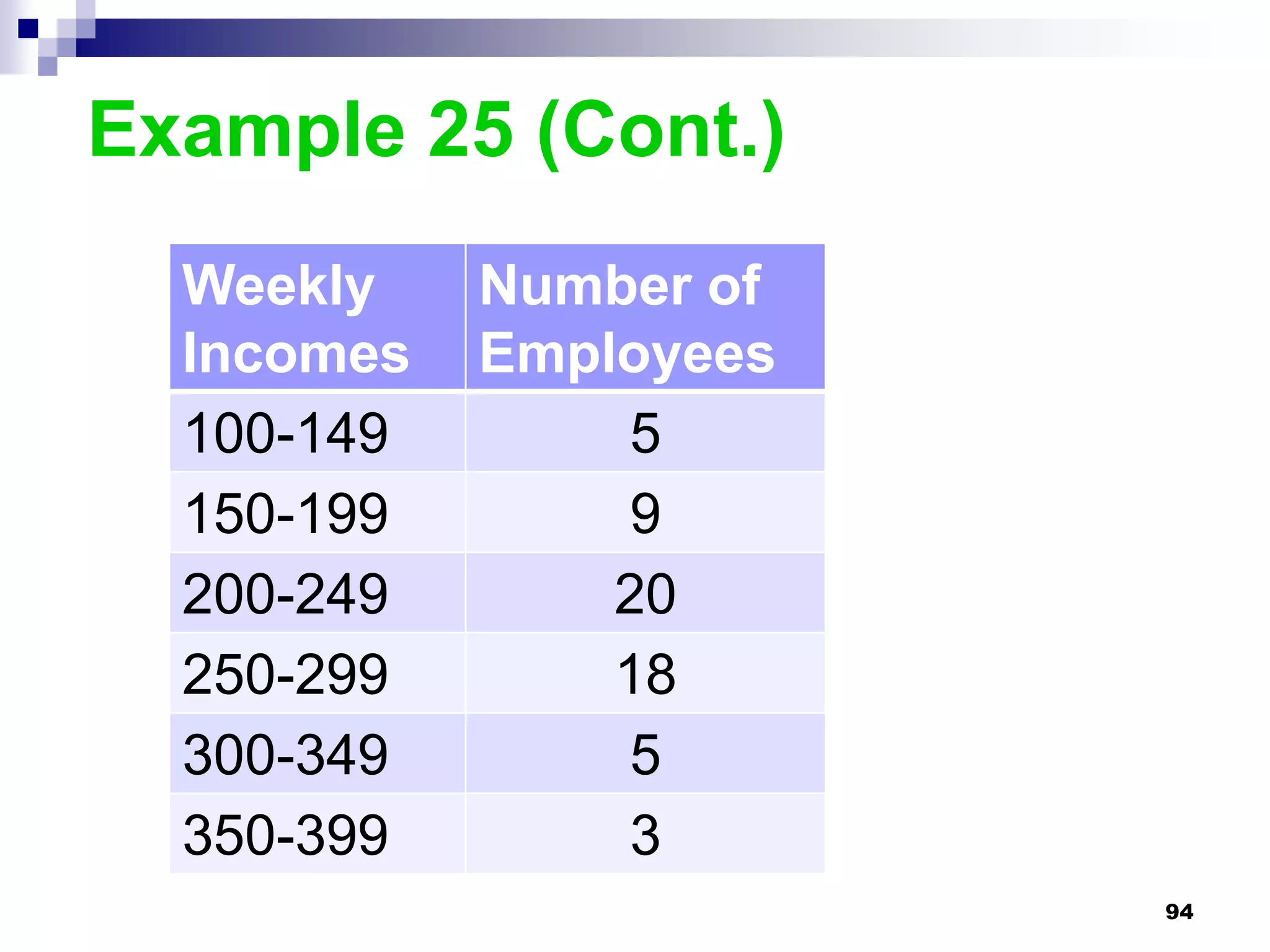








This chapter discusses measures of central tendency, dispersion, and position. It defines statistics, parameters, population and sample means, medians, modes, and weighted means. It discusses estimating means and medians for grouped data using class midpoints and boundaries. Examples are provided to demonstrate calculating measures for raw data and frequency distributions. Measures of variability like range, mean deviation, variance, and standard deviation are also introduced.


























































































