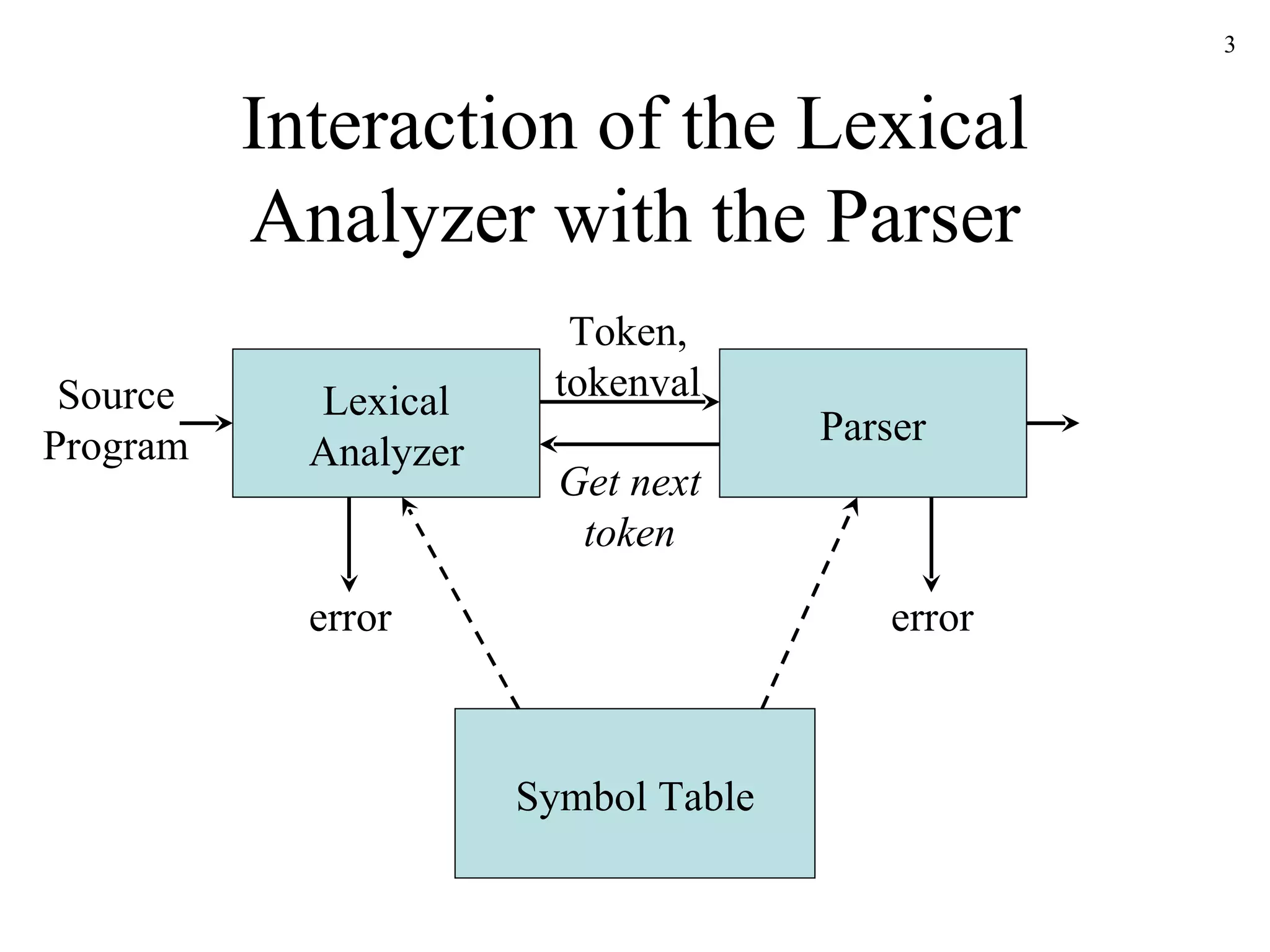
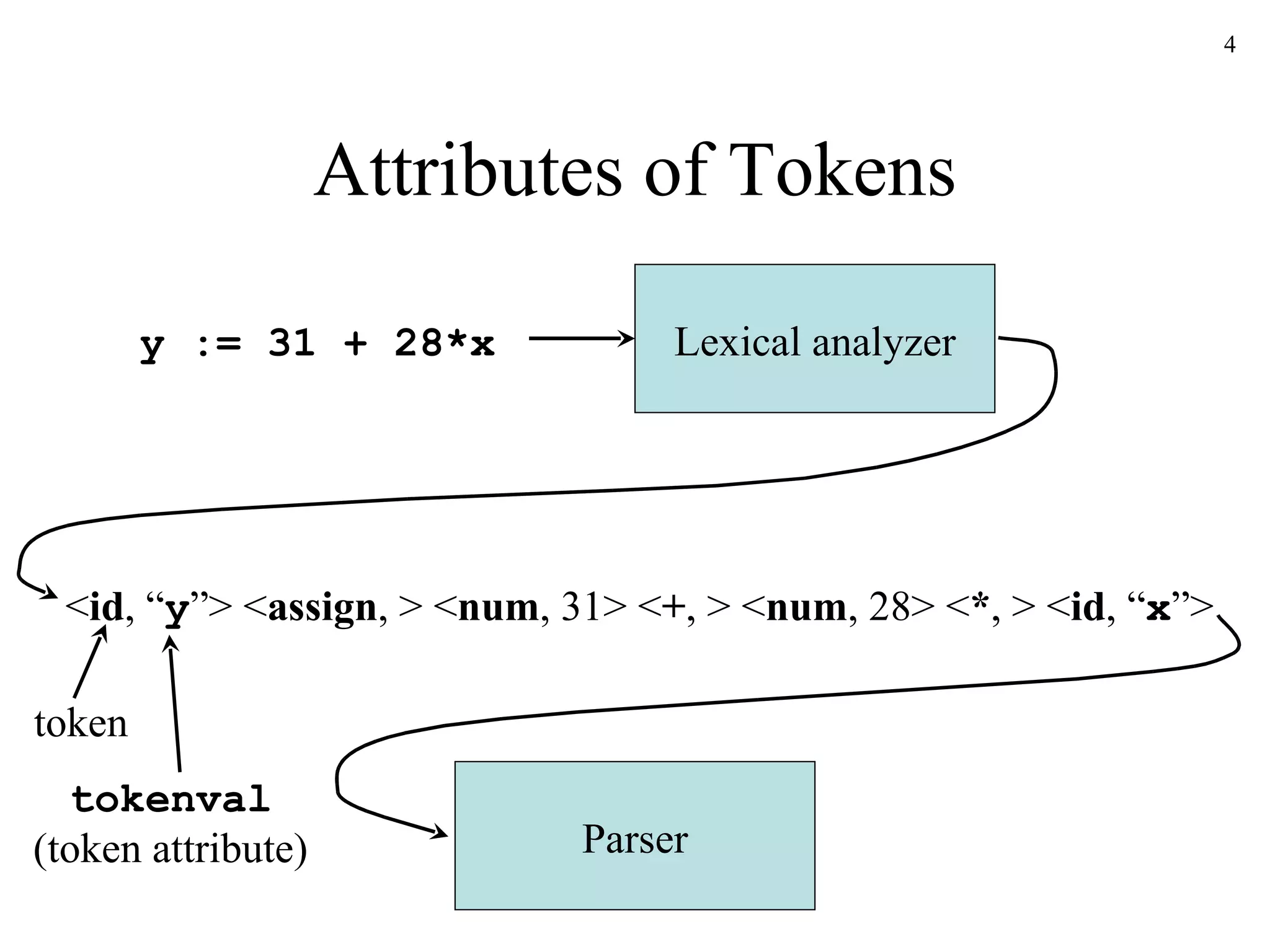
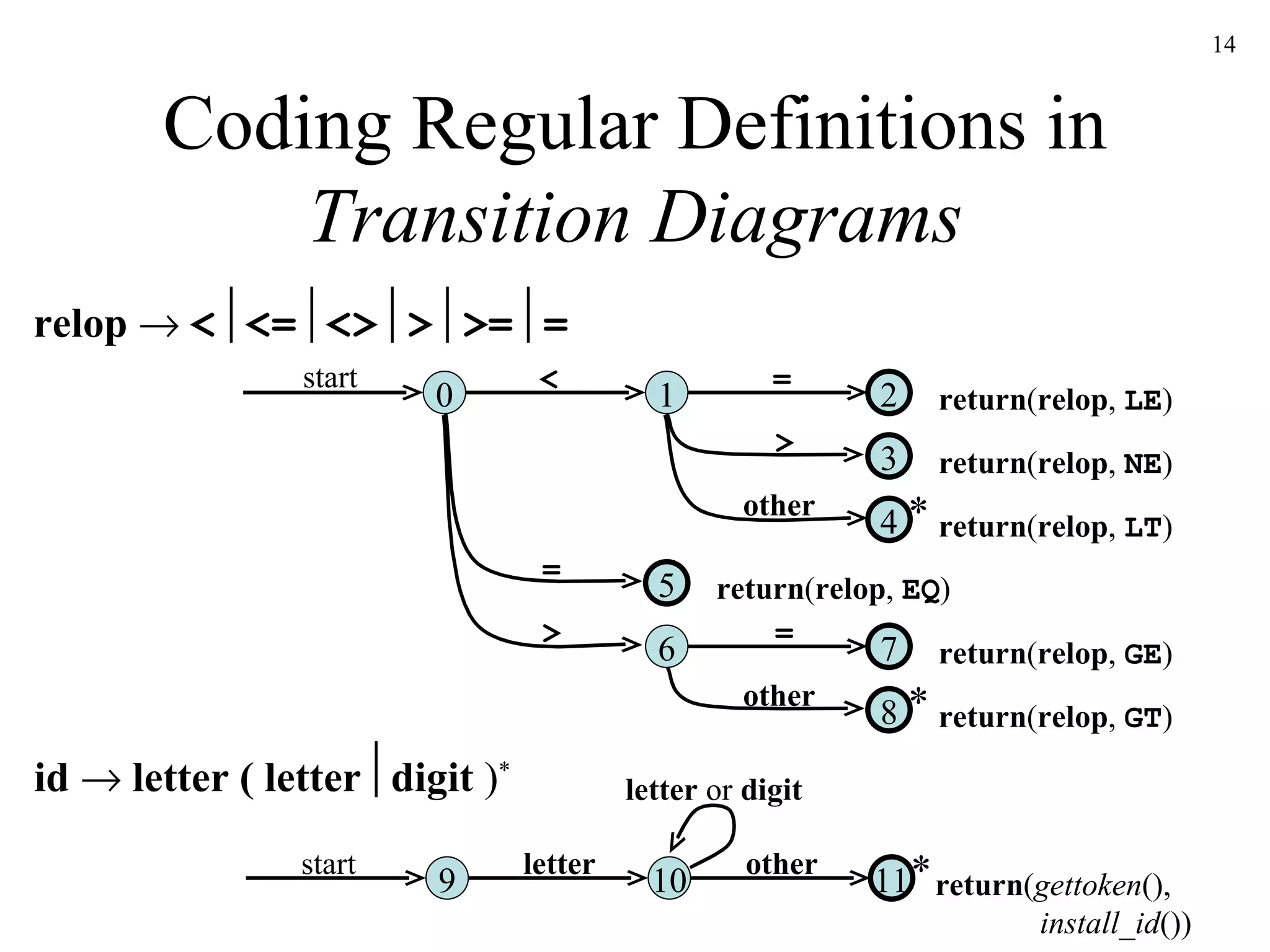
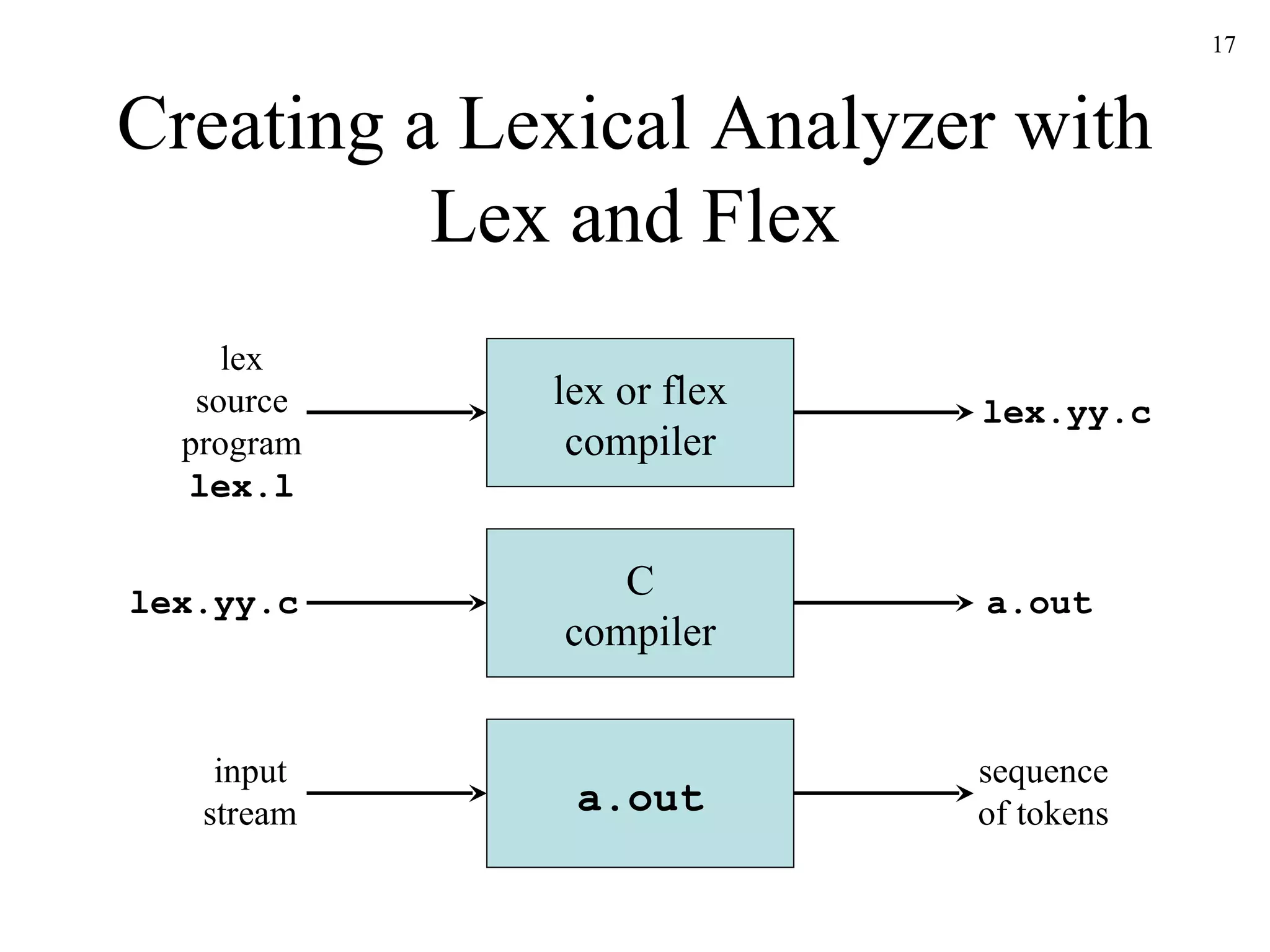
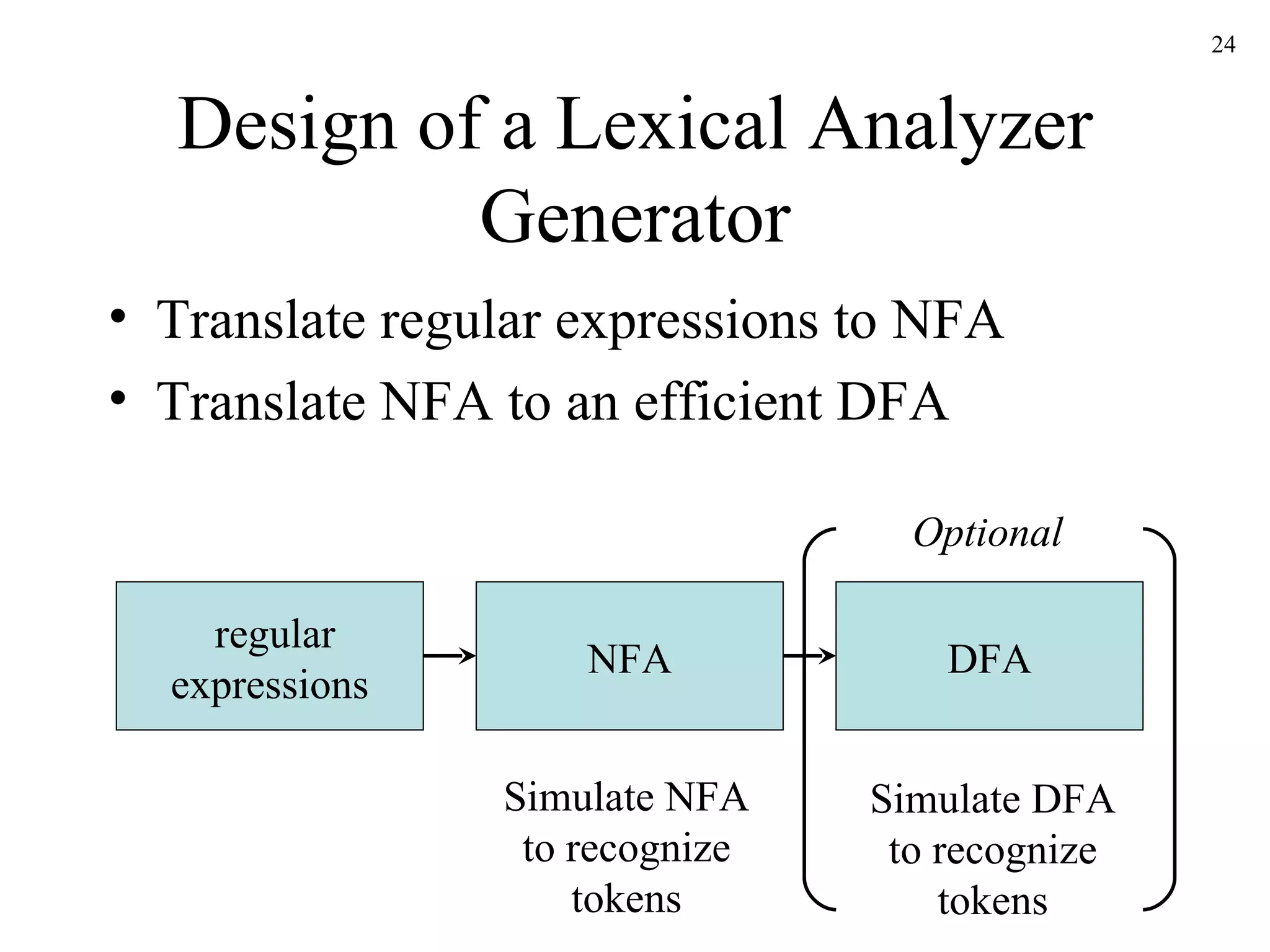
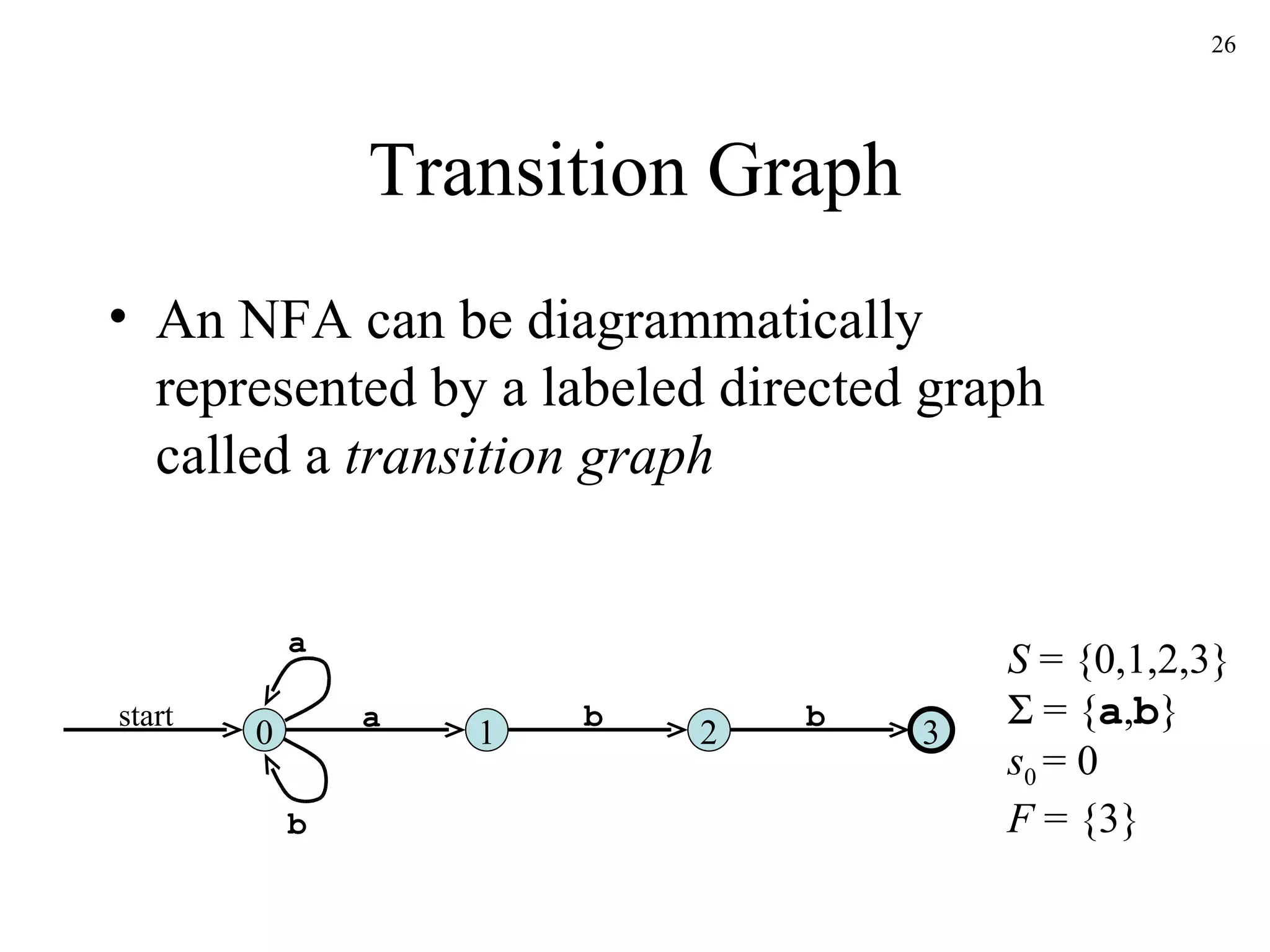
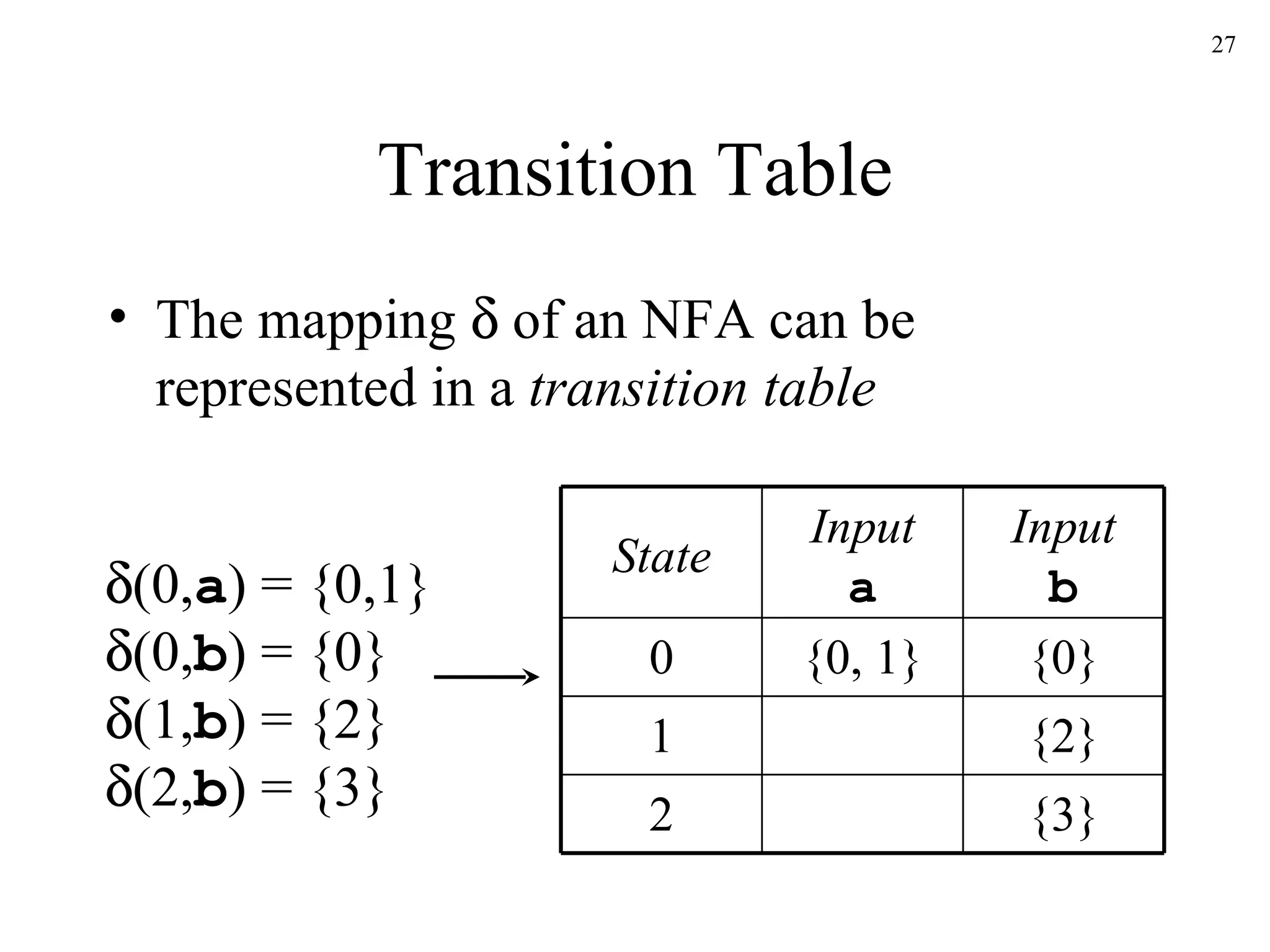
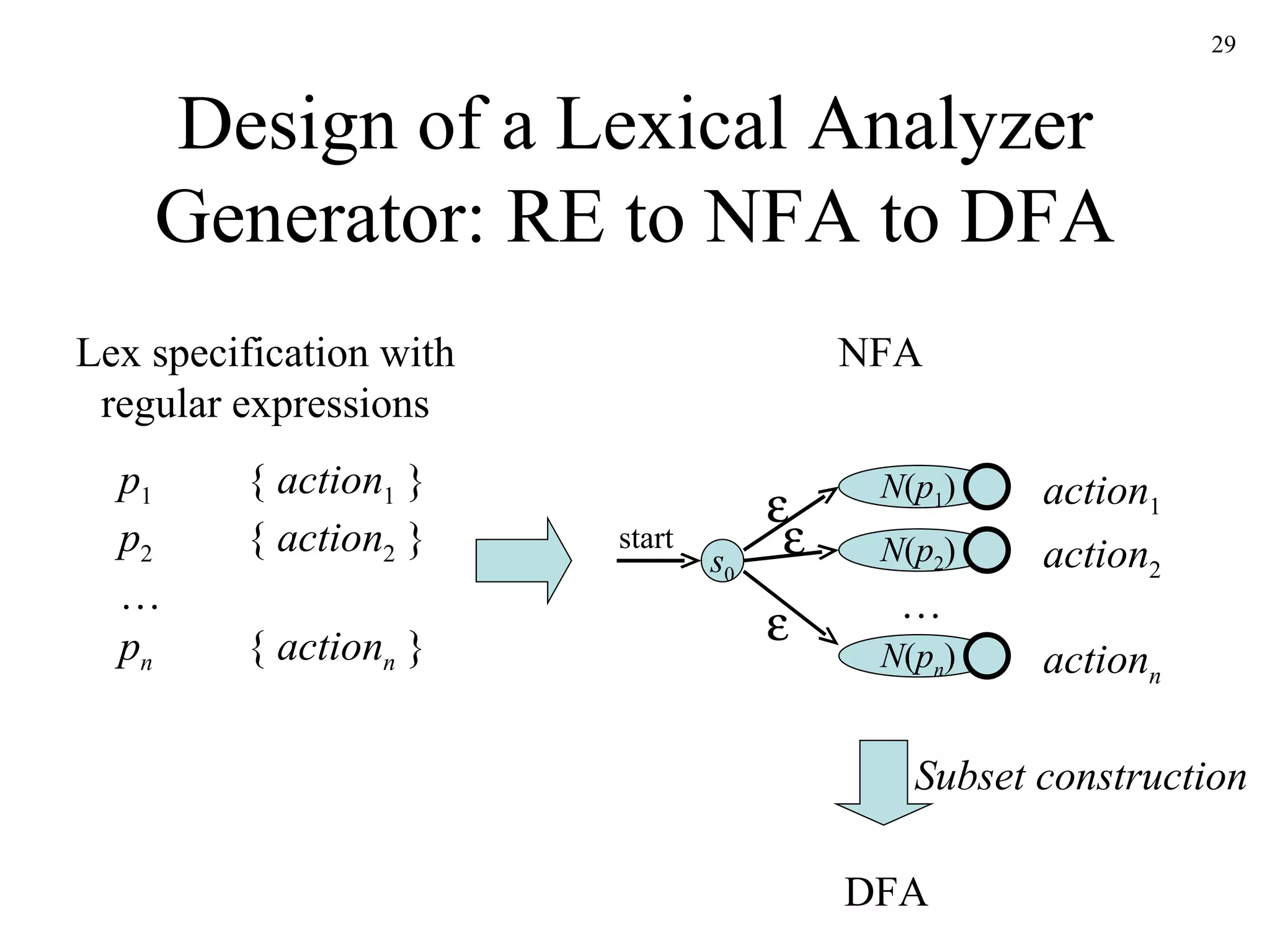
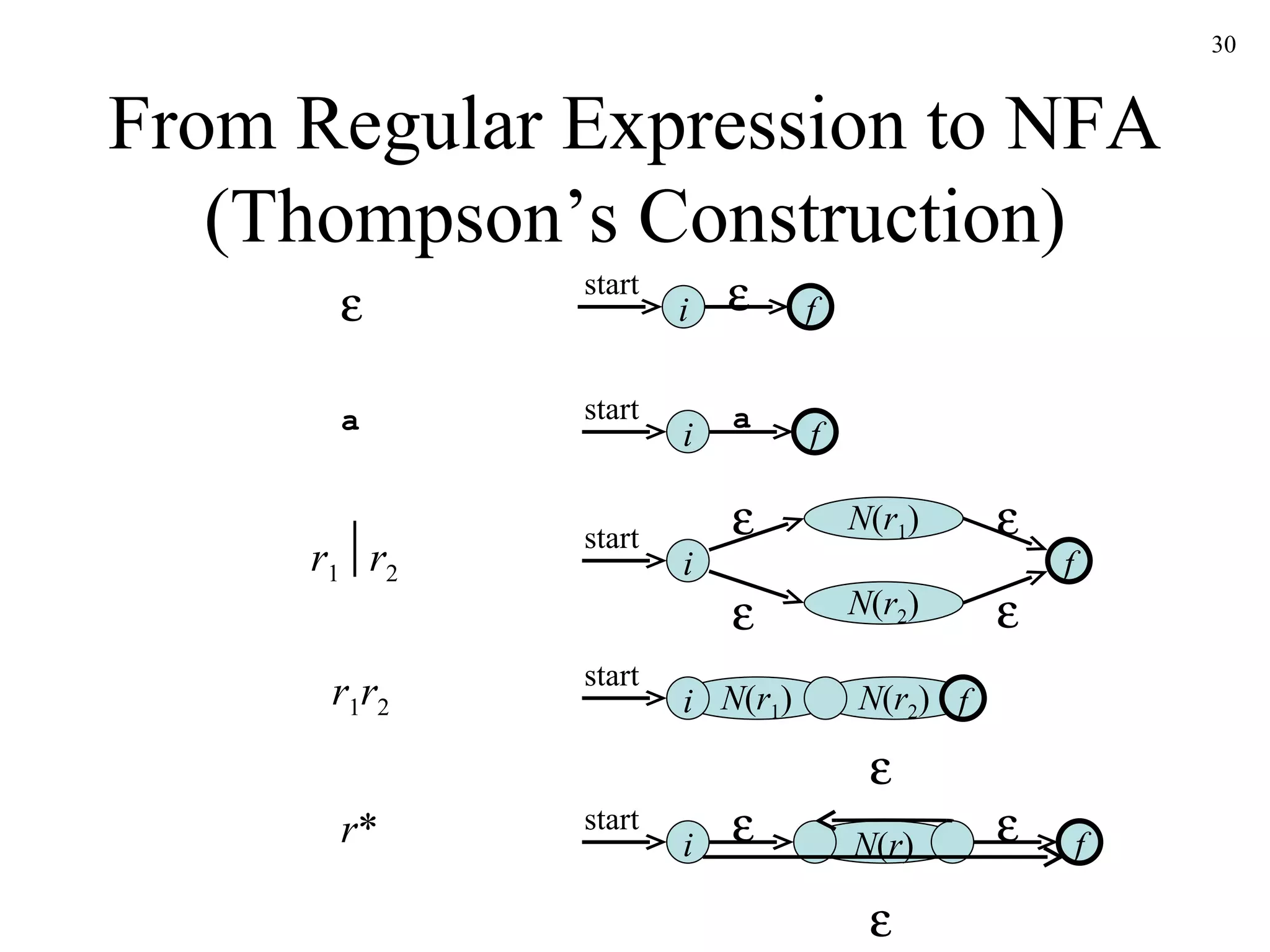
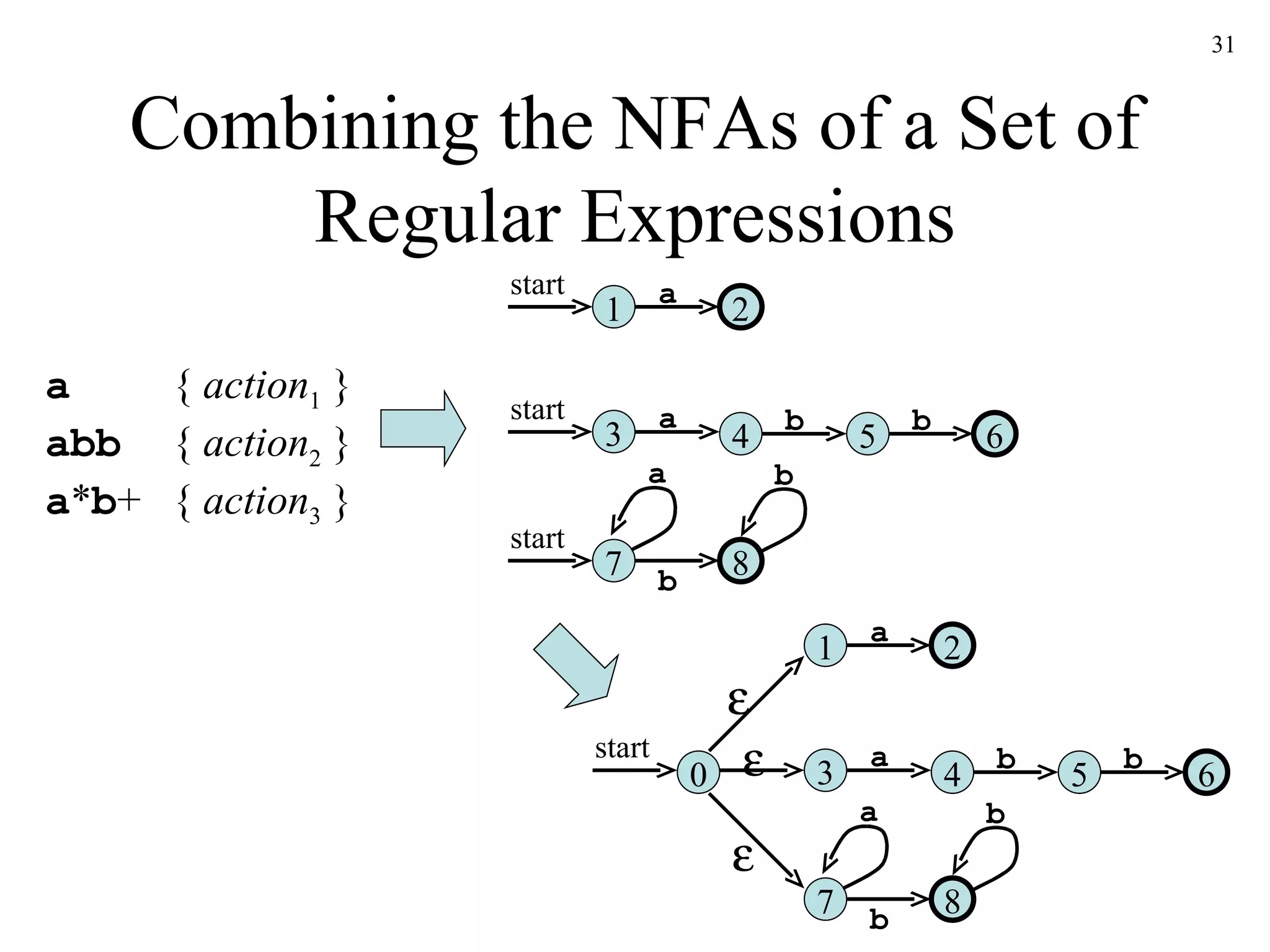
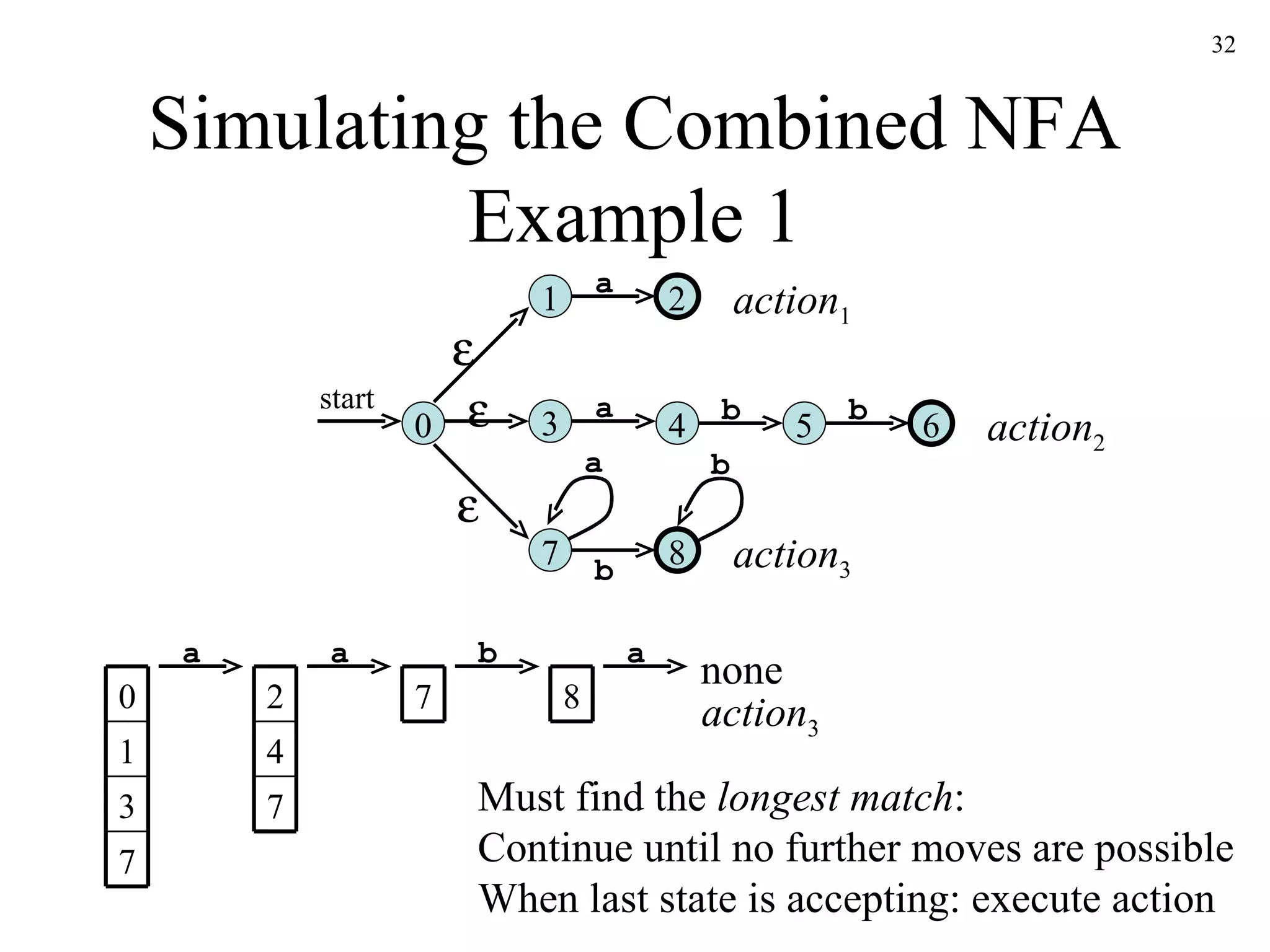
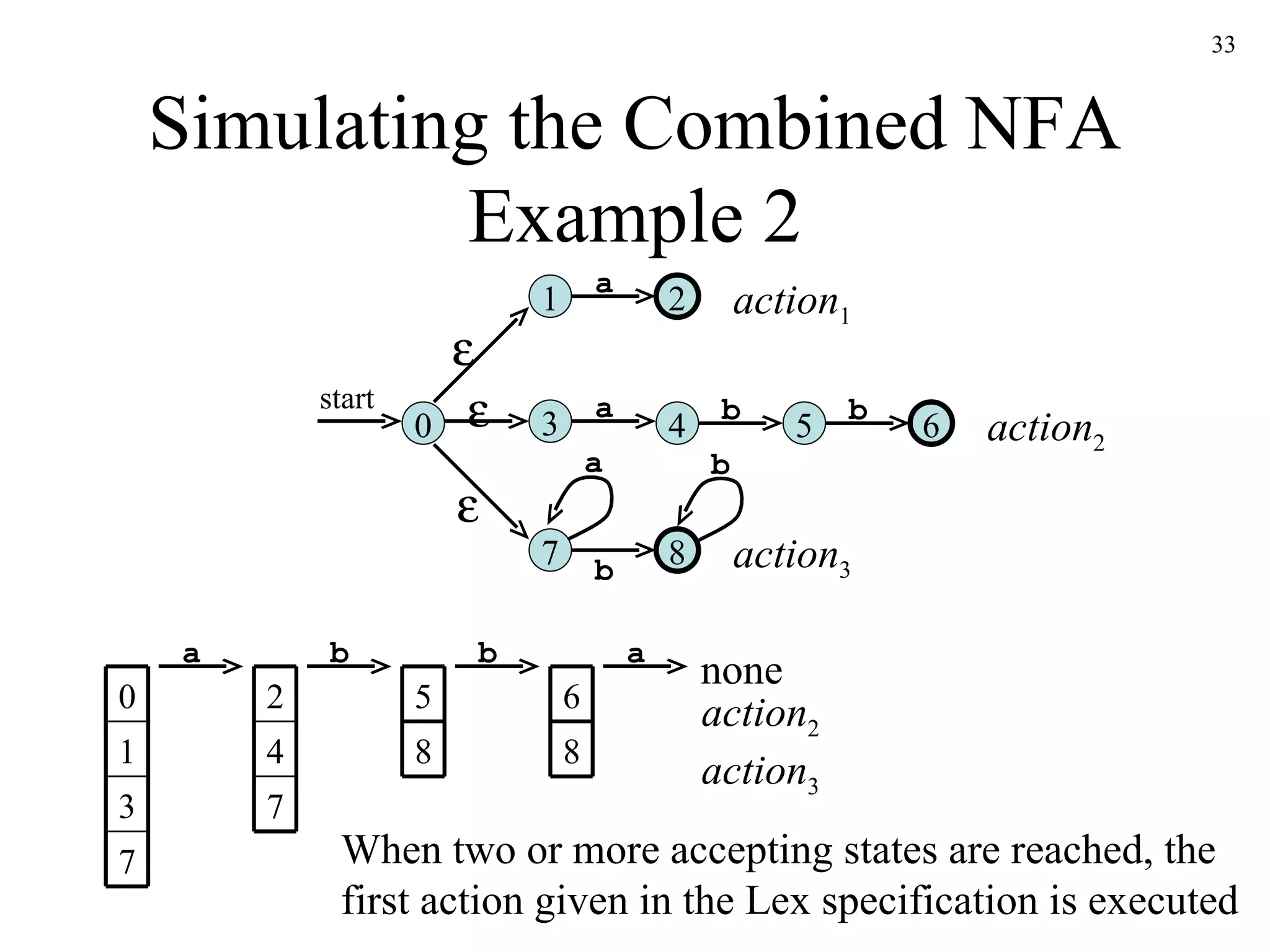
The document discusses lexical analysis and lexical analyzer generators. It provides background on why lexical analysis is a separate phase in compiler design and how it simplifies parsing. It also describes how a lexical analyzer interacts with a parser and some key attributes of tokens like lexemes and patterns. Finally, it explains how regular expressions are used to specify patterns for tokens and how tools like Lex and Flex can be used to generate lexical analyzers from regular expression definitions.









![Specification of Patterns for Tokens: Notational Shorthand The following shorthands are often used: r + = rr * r ? = r [ a - z ] = a b c … z Examples: digit [ 0 - 9 ] num digit + ( . digit + )? ( E ( + - )? digit + )?](https://image.slidesharecdn.com/ch3-091220235740-phpapp02/75/Ch3-12-2048.jpg)




![Regular Expressions in Lex x match the character x \. match the character . “ string ” match contents of string of characters . match any character except newline ^ match beginning of a line $ match the end of a line [xyz] match one character x , y , or z (use \ to escape - ) [^xyz] match any character except x , y , and z [a-z] match one of a to z r * closure (match zero or more occurrences) r + positive closure (match one or more occurrences) r ? optional (match zero or one occurrence) r 1 r 2 match r 1 then r 2 (concatenation) r 1 | r 2 match r 1 or r 2 (union) ( r ) grouping r 1 \ r 2 match r 1 when followed by r 2 { d } match the regular expression defined by d](https://image.slidesharecdn.com/ch3-091220235740-phpapp02/75/Ch3-19-2048.jpg)
![Example Lex Specification 1 %{ #include <stdio.h> %} %% [0-9]+ { printf(“%s\n”, yytext); } .|\n { } %% main() { yylex(); } Contains the matching lexeme Invokes the lexical analyzer lex spec.l gcc lex.yy.c -ll ./a.out < spec.l Translation rules](https://image.slidesharecdn.com/ch3-091220235740-phpapp02/75/Ch3-20-2048.jpg)
![Example Lex Specification 2 %{ #include <stdio.h> int ch = 0, wd = 0, nl = 0; %} delim [ \t]+ %% \n { ch++; wd++; nl++; } ^{delim} { ch+=yyleng; } {delim} { ch+=yyleng; wd++; } . { ch++; } %% main() { yylex(); printf("%8d%8d%8d\n", nl, wd, ch); } Regular definition Translation rules](https://image.slidesharecdn.com/ch3-091220235740-phpapp02/75/Ch3-21-2048.jpg)
![Example Lex Specification 3 %{ #include <stdio.h> %} digit [0-9] letter [A-Za-z] id {letter}({letter}|{digit})* %% {digit}+ { printf(“number: %s\n”, yytext); } {id} { printf(“ident: %s\n”, yytext); } . { printf(“other: %s\n”, yytext); } %% main() { yylex(); } Regular definitions Translation rules](https://image.slidesharecdn.com/ch3-091220235740-phpapp02/75/Ch3-22-2048.jpg)
![Example Lex Specification 4 %{ /* definitions of manifest constants */ #define LT (256) … %} delim [ \t\n] ws {delim}+ letter [A-Za-z] digit [0-9] id {letter}({letter}|{digit})* number {digit}+(\.{digit}+)?(E[+\-]?{digit}+)? %% {ws} { } if {return IF;} then {return THEN;} else {return ELSE;} {id} {yylval = install_id(); return ID;} {number} {yylval = install_num(); return NUMBER;} “<“ {yylval = LT; return RELOP;} “<=“ {yylval = LE; return RELOP;} “ =“ {yylval = EQ; return RELOP;} “ <>“ {yylval = NE; return RELOP;} “>“ {yylval = GT; return RELOP;} “ >=“ {yylval = GE; return RELOP;} %% int install_id() … Return token to parser Token attribute Install yytext as identifier in symbol table](https://image.slidesharecdn.com/ch3-091220235740-phpapp02/75/Ch3-23-2048.jpg)





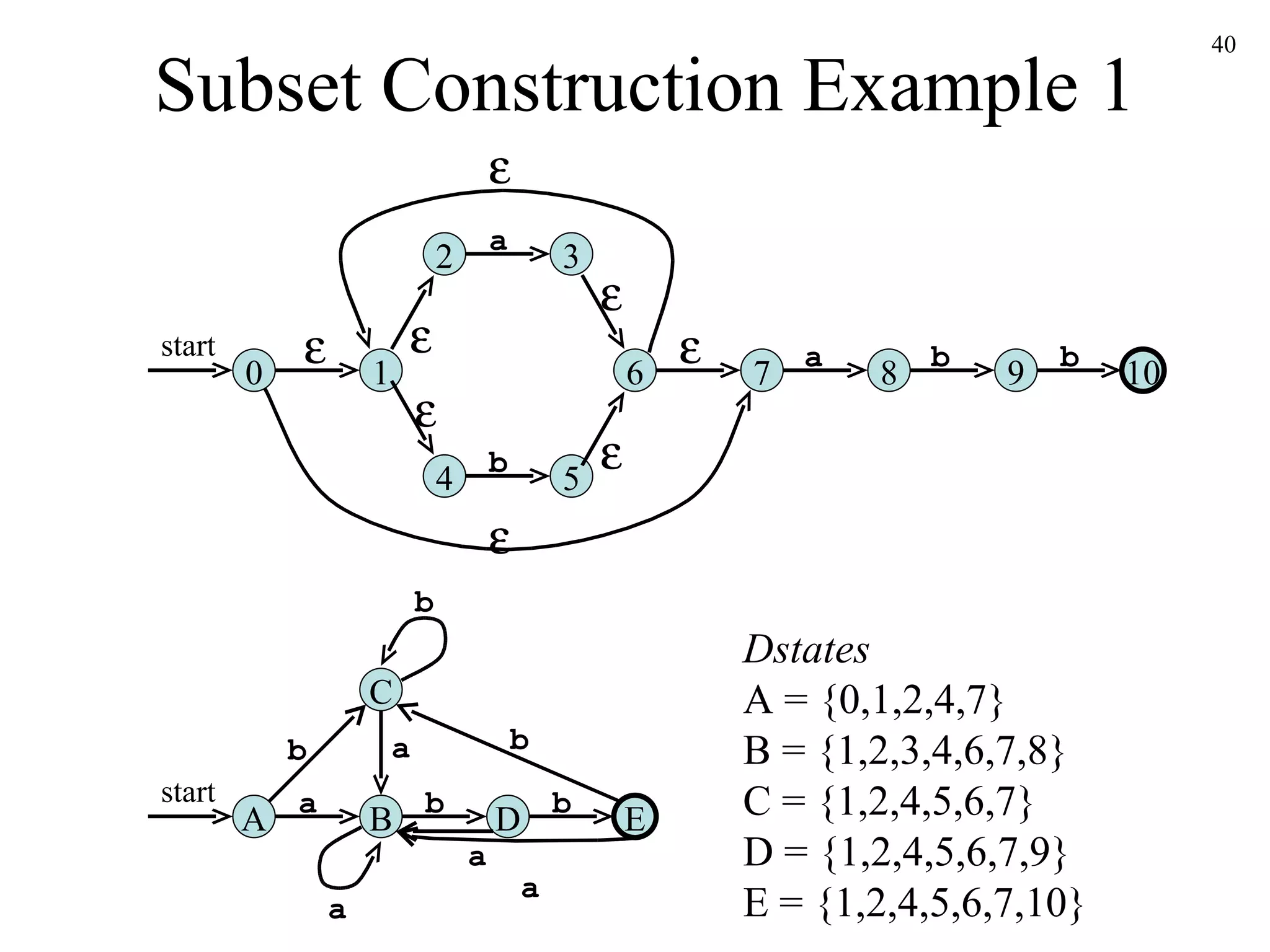
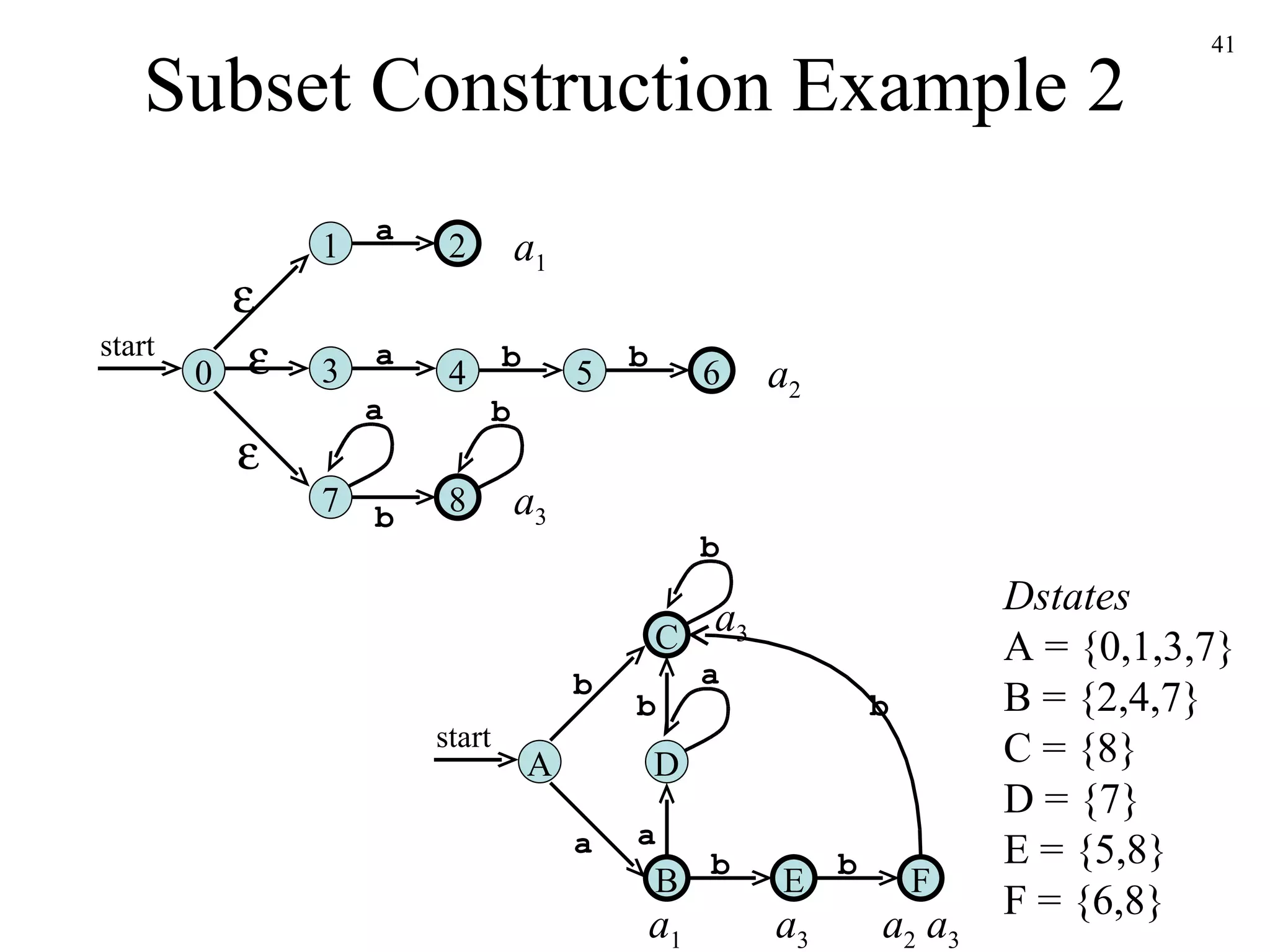
![The Subset Construction Algorithm Initially, -closure ( s 0 ) is the only state in Dstates and it is unmarked while there is an unmarked state T in Dstates do mark T for each input symbol a do U := -closure ( move ( T,a )) if U is not in Dstates then add U as an unmarked state to Dstates end if Dtran [ T , a ] := U end do end do](https://image.slidesharecdn.com/ch3-091220235740-phpapp02/75/Ch3-39-2048.jpg)




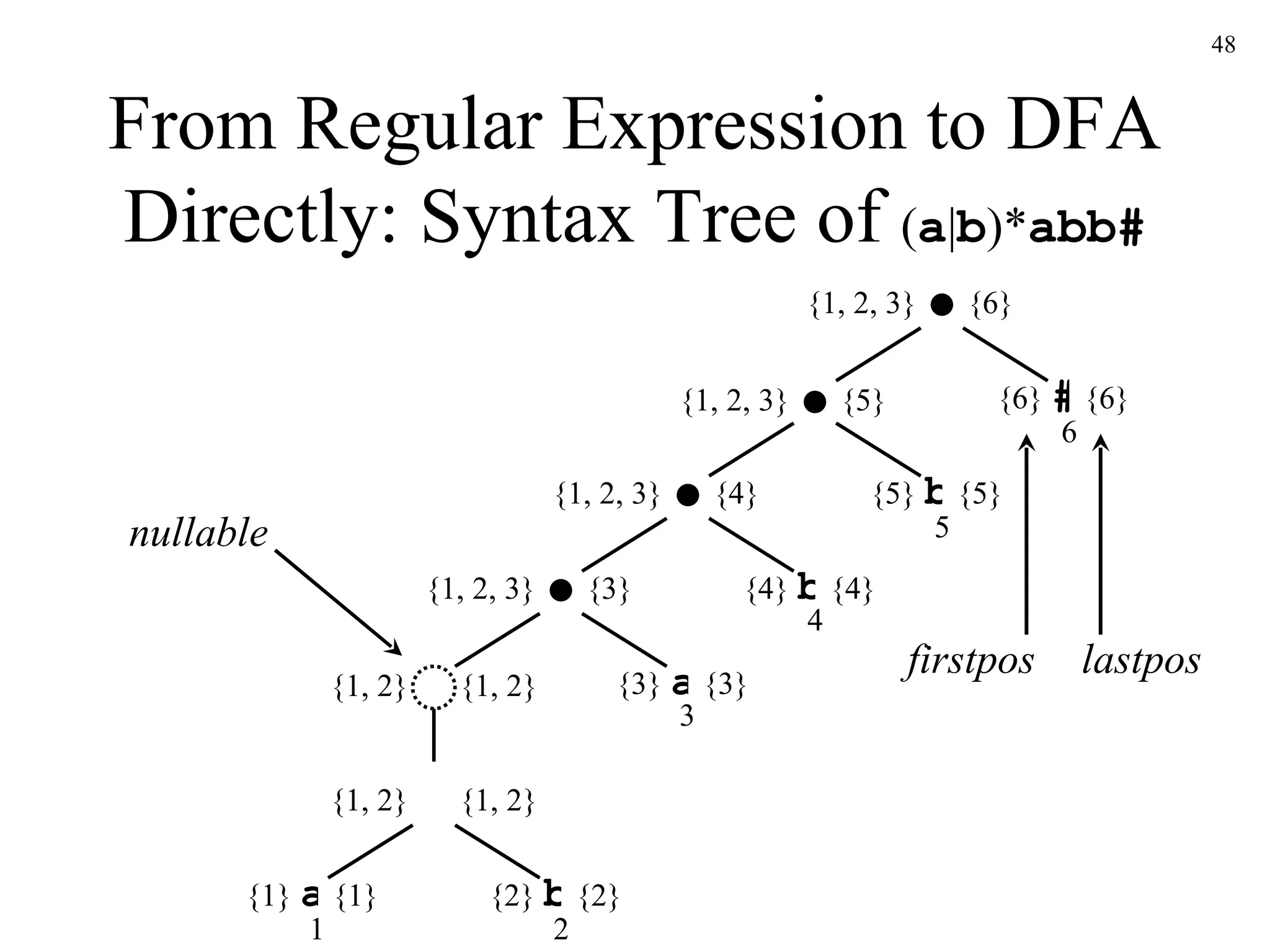

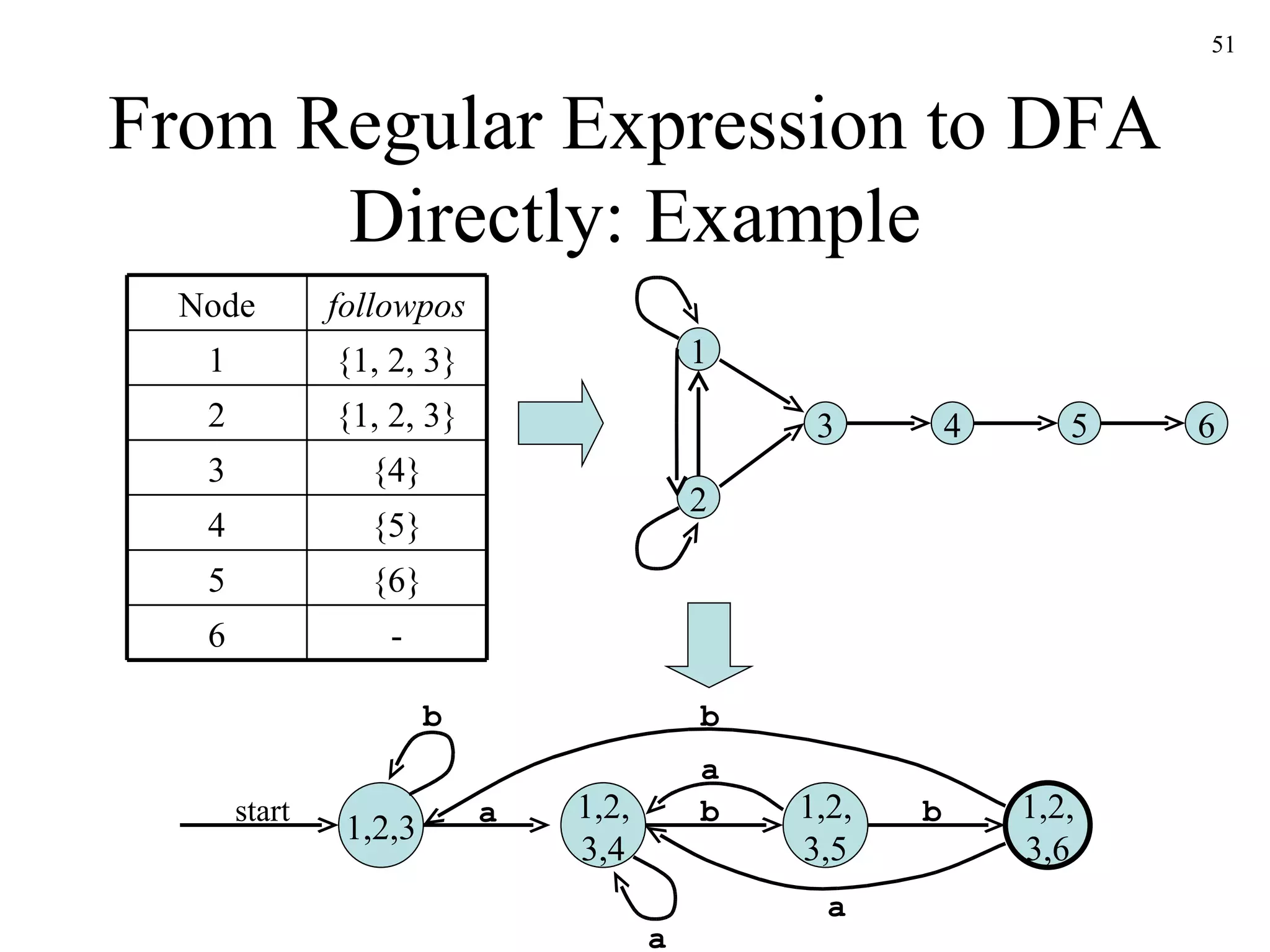
![From Regular Expression to DFA Directly: Algorithm s 0 := firstpos ( root ) where root is the root of the syntax tree Dstates := { s 0 } and is unmarked while there is an unmarked state T in Dstates do mark T for each input symbol a do let U be the set of positions that are in followpos ( p ) for some position p in T , such that the symbol at position p is a if U is not empty and not in Dstates then add U as an unmarked state to Dstates end if Dtran [ T,a ] := U end do end do](https://image.slidesharecdn.com/ch3-091220235740-phpapp02/75/Ch3-50-2048.jpg)











































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)








