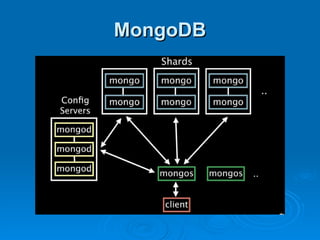
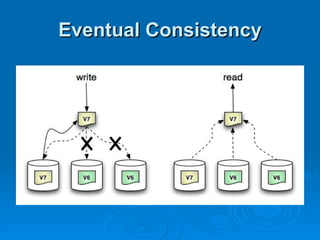
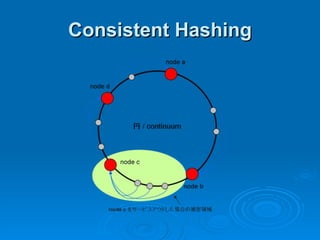
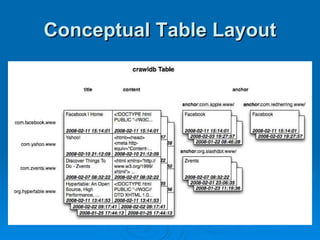
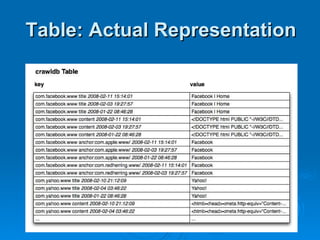
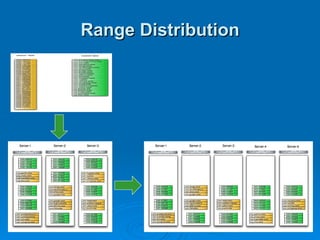
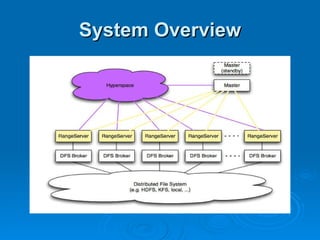
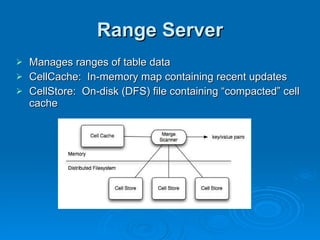
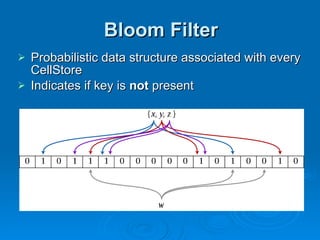
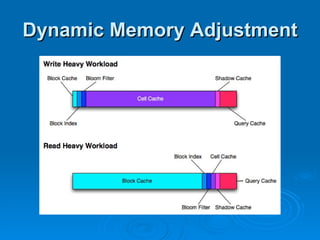
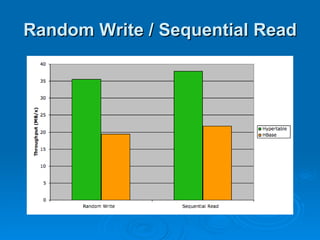
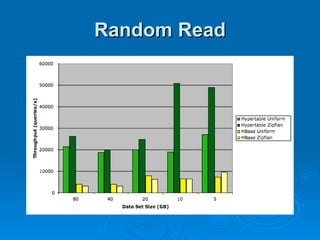
Hypertable is an open source, scalable database modeled after Google's Bigtable database. It provides high performance for massive sparse tables of information using a single primary key index. Key features include auto-sharding of data, support for popular programming languages through a Thrift interface, and deployment at companies using architectures like MongoDB, Cassandra, and Dynamo. It uses techniques like consistent hashing, order-preserving partitioning, and LSM trees to optimize performance.

























![[db tech showcase Tokyo 2017] C23: Lessons from SQLite4 by SQLite.org - Richa...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-sqlite4-20170906-170911071410-thumbnail.jpg?width=640&height=640&fit=bounds)



















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















