More Related Content

PDF

PPTX
pg_bigmで全文検索するときに気を付けたい5つのポイント(第23回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PPTX
PostgreSQL 12は ここがスゴイ! ~性能改善やpluggable storage engineなどの新機能を徹底解説~ (NTTデータ テクノ... 
PPTX
押さえておきたい、PostgreSQL 13 の新機能!!(Open Source Conference 2021 Online/Hokkaido 発表資料) 
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション 
PDF

PDF

PPTX
What's hot

PDF
pg_bigm(ピージーバイグラム)を用いた全文検索のしくみ 
PDF
PostgreSQLでpg_bigmを使って日本語全文検索 (MySQLとPostgreSQLの日本語全文検索勉強会 発表資料) 
PDF
pgvectorを使ってChatGPTとPostgreSQLを連携してみよう!(PostgreSQL Conference Japan 2023 発表資料) 
PPTX
押さえておきたい、PostgreSQL 13 の新機能!! (PostgreSQL Conference Japan 2020講演資料) 
PPTX
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~ 
PDF
NTT DATA と PostgreSQL が挑んだ総力戦 
PDF

PDF

PPTX
スケールアウトするPostgreSQLを目指して!その第一歩!(NTTデータ テクノロジーカンファレンス 2020 発表資料) 
PDF

PDF
統計情報のリセットによるautovacuumへの影響について(第39回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PPTX
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料) 
PPTX
PostgreSQLのfull_page_writesについて(第24回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PPTX

PDF
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料) 
PDF
PostgreSQL13でのレプリケーション関連の改善について(第14回PostgreSQLアンカンファレンス@オンライン) ![[B23] PostgreSQLのインデックス・チューニング by Tomonari Katsumata](https://cdn.slidesharecdn.com/ss_thumbnails/b23ntt-140624233630-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[B23] PostgreSQLのインデックス・チューニング by Tomonari Katsumata 
PDF
PostgreSQLのリカバリ超入門(もしくはWAL、CHECKPOINT、オンラインバックアップの仕組み) 
PPTX
トランザクションをSerializableにする4つの方法 
PDF
Inside vacuum - 第一回PostgreSQLプレ勉強会 Viewers also liked

PDF
PostgreSQLアーキテクチャ入門(PostgreSQL Conference 2012) 
PDF

PDF
PostgreSQLの運用・監視にまつわるエトセトラ 
PDF

PDF

PDF
PostgreSQL: XID周回問題に潜む別の問題 
PDF
perfを使ったPostgreSQLの解析(前編) 
PDF
perfを使ったPostgreSQLの解析(後編) 
PDF

PDF
JSONBはPostgreSQL9.5でいかに改善されたのか 
PDF

PDF

PDF

PDF

PDF

PDF

PDF
Similar to pg_bigmを用いた全文検索のしくみ(後編)

PDF
pg_bigm(ピージー・バイグラム)を用いた全文検索のしくみ(後編) 
PDF
PostgreSQL 13でのpg_stat_statementsの改善について(第12回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PDF

PDF
JPUGしくみ+アプリケーション勉強会(第20回) 
PDF
YugabyteDBの実行計画を眺める(NewSQL/分散SQLデータベースよろず勉強会 #3 発表資料) 
PDF
PostgreSQL18新機能紹介(db tech showcase 2025 発表資料) 
PDF
MySQL 5.7 InnoDB 日本語全文検索(その2) 
PDF

PDF
アナリティクスをPostgreSQLで始めるべき10の理由@第6回 関西DB勉強会 
PDF

PDF
Pgunconf ゆるいテキスト検索ふたたび - n-gram応用編 
PDF

PDF
データベースシステム論12 - 問い合わせ処理と最適化 
PDF
Pgunconf 20121212-postgeres fdw 
PDF

PDF

PDF
PostgreSQL 9.2 新機能 - 新潟オープンソースセミナー2012 
PPT
20090107 Postgre Sqlチューニング(Sql編) 
PDF

PDF
DSIRNLP#3 LT: 辞書挟み込み型転置インデクスFIg4.5 More from NTT DATA OSS Professional Services

PDF
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント 
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~ 
PDF
Spark SQL - The internal - 
PDF
Apache Hadoopの新機能Ozoneの現状 
PDF
Apache Hadoopの未来 3系になって何が変わるのか? 
PDF
Structured Streaming - The Internal - 
PDF
SIerとオープンソースの美味しい関係 ~コミュニティの力を活かして世界を目指そう~ 
PPTX

PDF
Global Top 5 を目指す NTT DATA の確かで意外な技術力 
PDF
Application of postgre sql to large social infrastructure 
PDF
データ活用をもっともっと円滑に!�~データ処理・分析基盤編を少しだけ~ 
PDF
商用ミドルウェアのPuppet化で気を付けたい5つのこと 
PDF
HDFS Router-based federation 
PDF
HDFS basics from API perspective 
PDF
Application of postgre sql to large social infrastructure jp 
PDF

PDF
Apache Hadoop 2.8.0 の新機能 (抜粋) 
PDF

PDF
Apache Hadoop and YARN, current development status 
PDF
Distributed data stores in Hadoop ecosystem pg_bigmを用いた全文検索のしくみ(後編)
- 1.
Copyright © 2013NTT DATA Corporation
NTTデータ
基盤システム事業本部
澤田雅彦
pg_bigm(ピージーバイグラム)を用いた 全文検索のしくみ (後編)
第27回しくみ+アプリケーション勉強会(10/5) - 2.
2
Copyright ©2013NTT DATA Corporation
自己紹介
名前
澤田 雅彦(さわだ まさひこ)
所属
NTTデータ 基盤システム事業本部
2年目です
やっていること
去年:pg_bigmの開発、サポート
今年:レプリケーション関係
- 3.
3
Copyright ©2013NTT DATA Corporation
INDEX
1.前編の復習
2.性能測定(後編)
3.pg_bigm独自機能
4.デモ
5.まとめ - 4.
- 5.
5
Copyright ©2013 NTT DATA Corporation
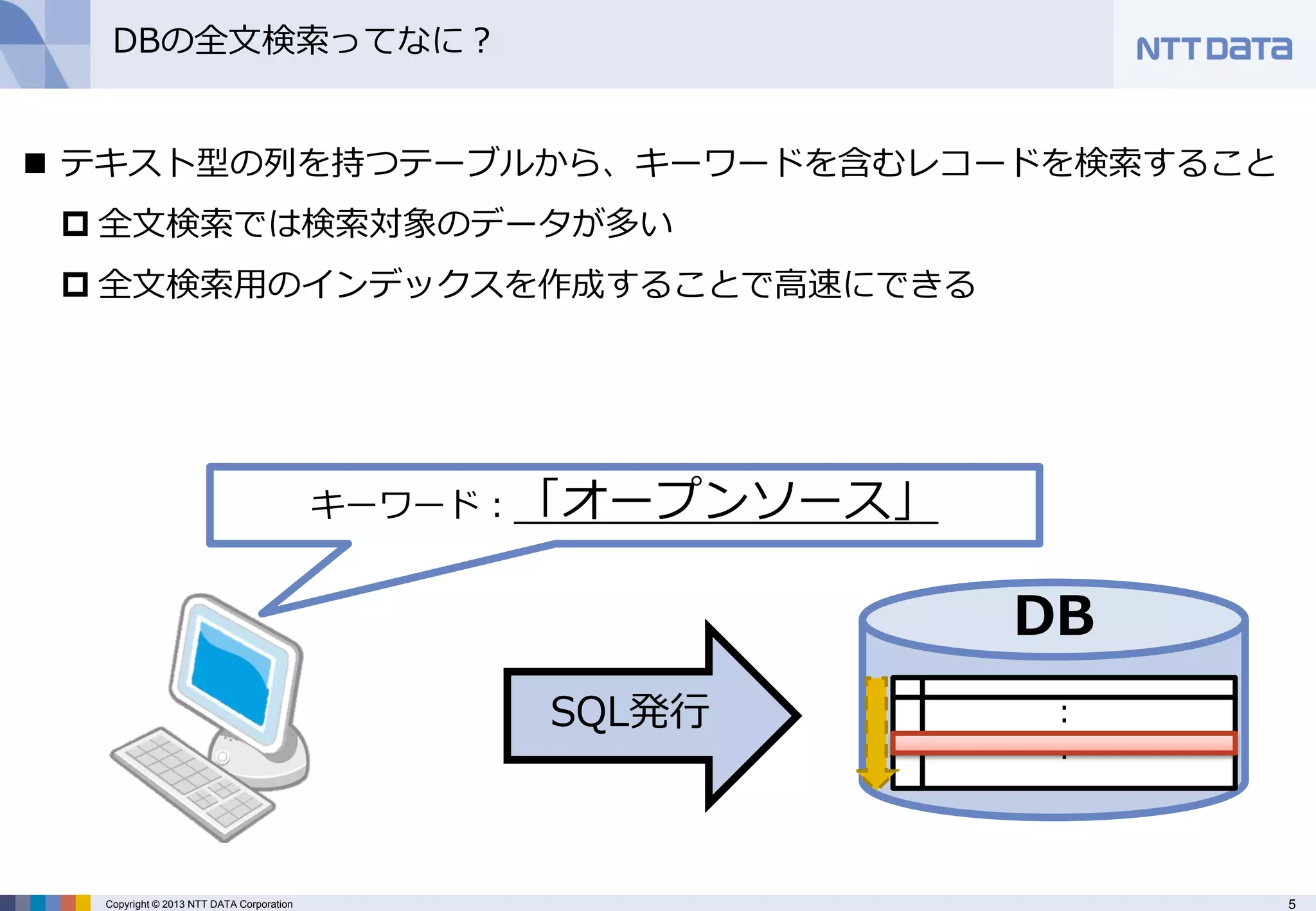
DBの全文検索ってなに?
SQL発行
DB
:
:
テキスト型の列を持つテーブルから、キーワードを含むレコードを検索すること
全文検索では検索対象のデータが多い
全文検索用のインデックスを作成することで高速にできる
キーワード:「オープンソース」 - 6.
6
Copyright ©2013 NTT DATA Corporation
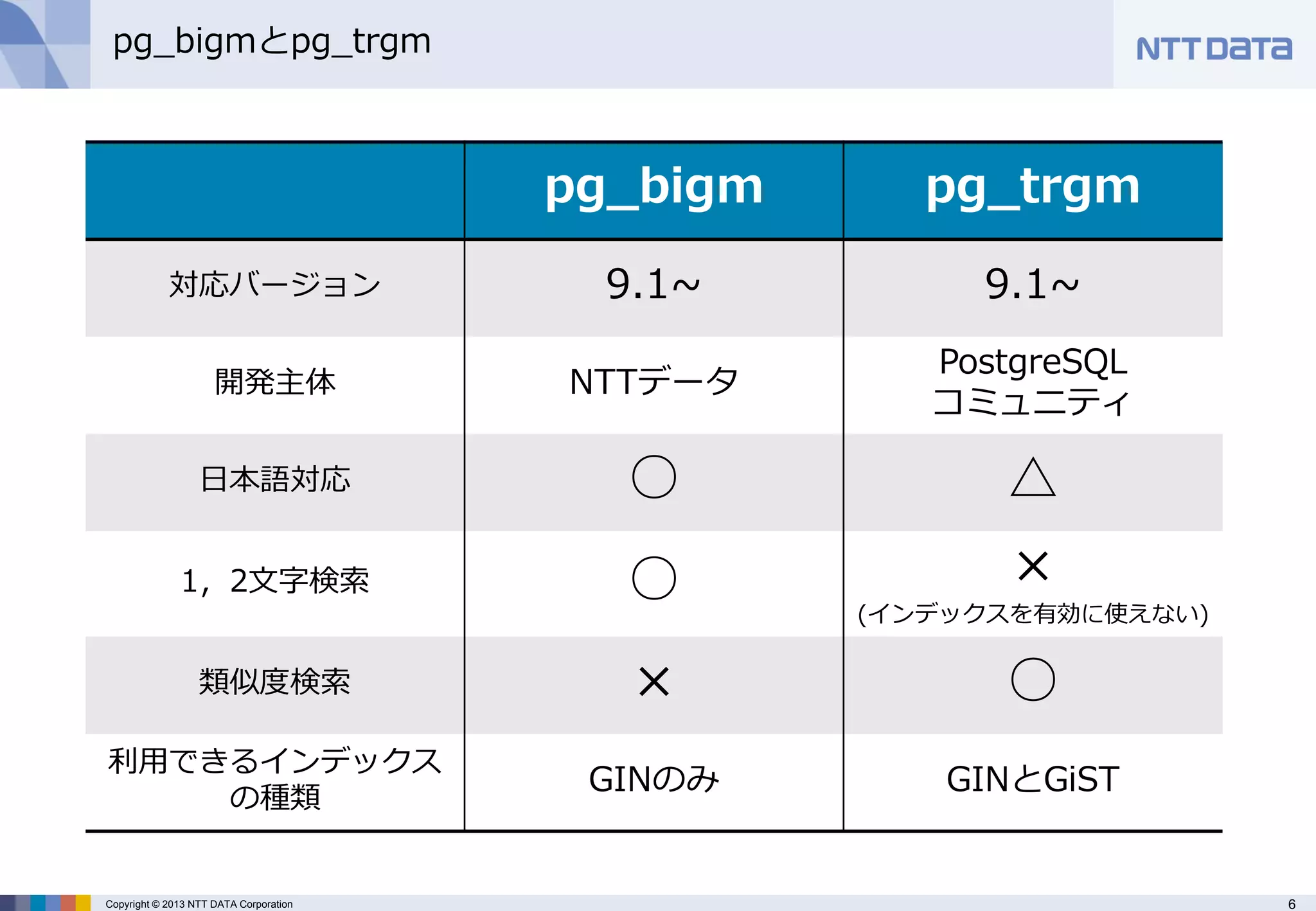
pg_bigmとpg_trgm
pg_bigm
pg_trgm
対応バージョン
9.1~
9.1~
開発主体
NTTデータ
PostgreSQL
コミュニティ
日本語対応
○
△
1,2文字検索
○
×
(インデックスを有効に使えない)
類似度検索
×
○
利用できるインデックス の種類
GINのみ
GINとGiST - 7.
7
Copyright ©2013 NTT DATA Corporation
pg_bigm
pg_trgm
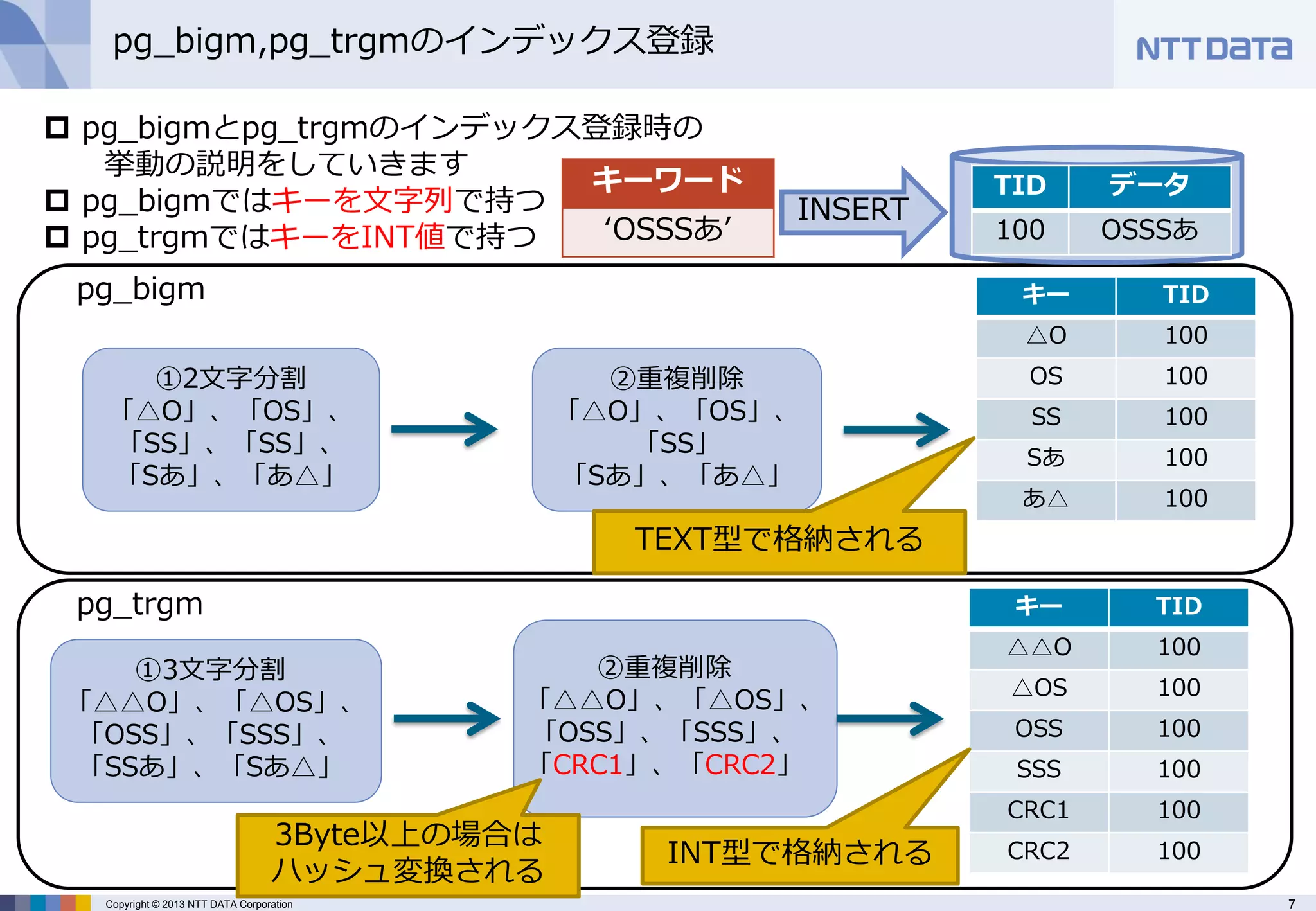
pg_bigmとpg_trgmのインデックス登録時の 挙動の説明をしていきます
pg_bigmではキーを文字列で持つ
pg_trgmではキーをINT値で持つ
pg_bigm,pg_trgmのインデックス登録
キー
TID
△△O
100
△OS
100
OSS
100
SSS
100
CRC1
100
CRC2
100
①3文字分割
「△△O」、「△OS」、
「OSS」、「SSS」、
「SSあ」、「Sあ△」
②重複削除
「△△O」、「△OS」、 「OSS」、「SSS」、 「CRC1」、「CRC2」
①2文字分割
「△O」、「OS」、 「SS」、「SS」、
「Sあ」、「あ△」
②重複削除
「△O」、「OS」、
「SS」
「Sあ」、「あ△」
キー
TID
△O
100
OS
100
SS
100
Sあ
100
あ△
100
TID
データ
100
OSSSあ
キーワード
‘OSSSあ’
INSERT
3Byte以上の場合は ハッシュ変換される
INT型で格納される
TEXT型で格納される - 8.
8
Copyright ©2013 NTT DATA Corporation
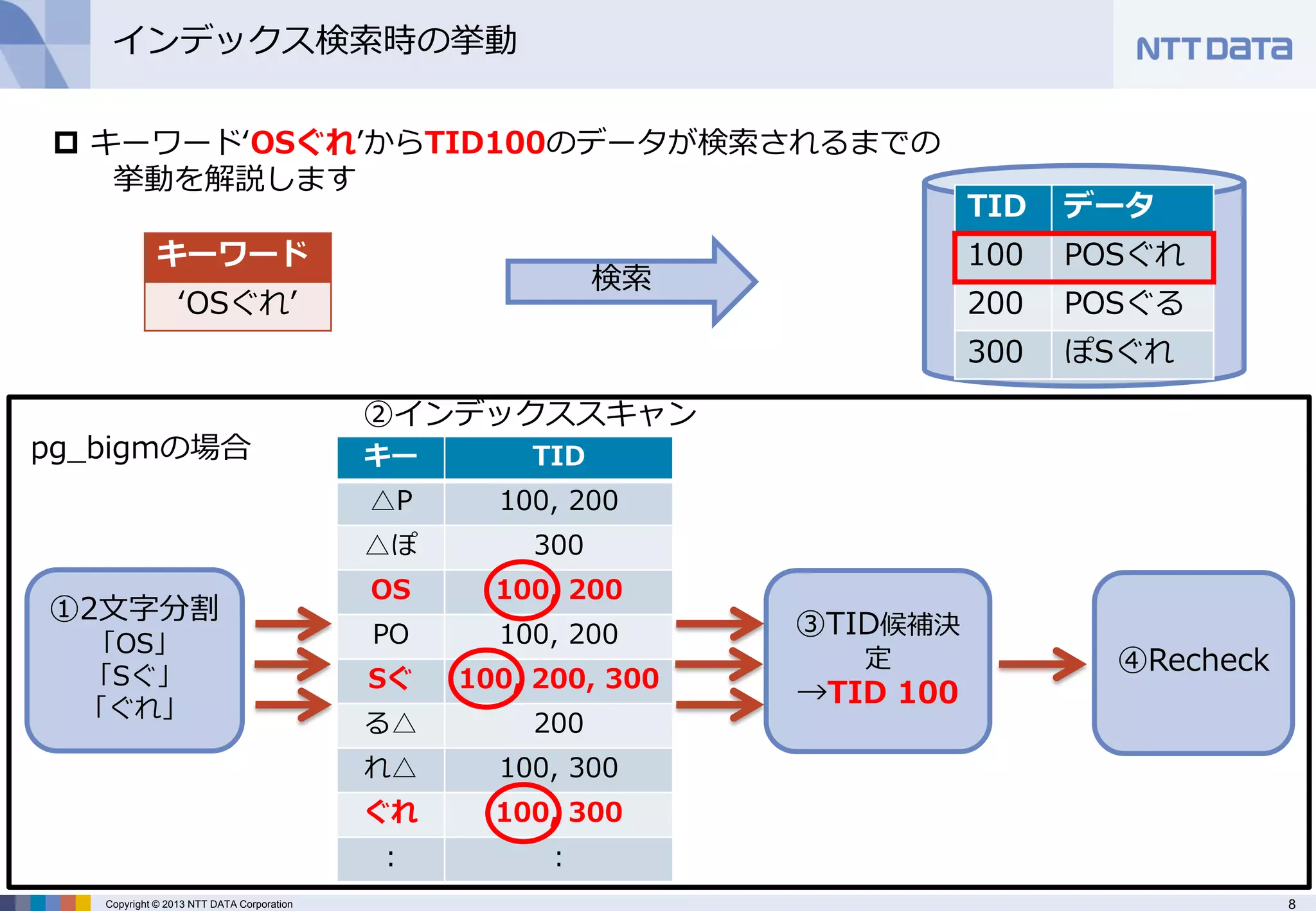
インデックス検索時の挙動
①2文字分割
「OS」
「Sぐ」
「ぐれ」
キーワード‘OSぐれ’からTID100のデータが検索されるまでの 挙動を解説します
②インデックススキャン
TID
データ
100
POSぐれ
200
POSぐる
300
ぽSぐれ
キー
TID
△P
100, 200
△ぽ
300
OS
100, 200
PO
100, 200
Sぐ
100, 200, 300
る△
200
れ△
100, 300
ぐれ
100, 300
:
:
③TID候補決 定 →TID 100
④Recheck
検索
キーワード
‘OSぐれ’
pg_bigmの場合 - 9.
- 10.
10
Copyright ©2013 NTT DATA Corporation
性能測定の概要
1.インデックス作成時間
2.インデックスサイズ
3.検索時間
4.データ挿入時間
測定対象
pg_bigm
pg_trgm
測定項目 以下の項目を実施 - 11.
11
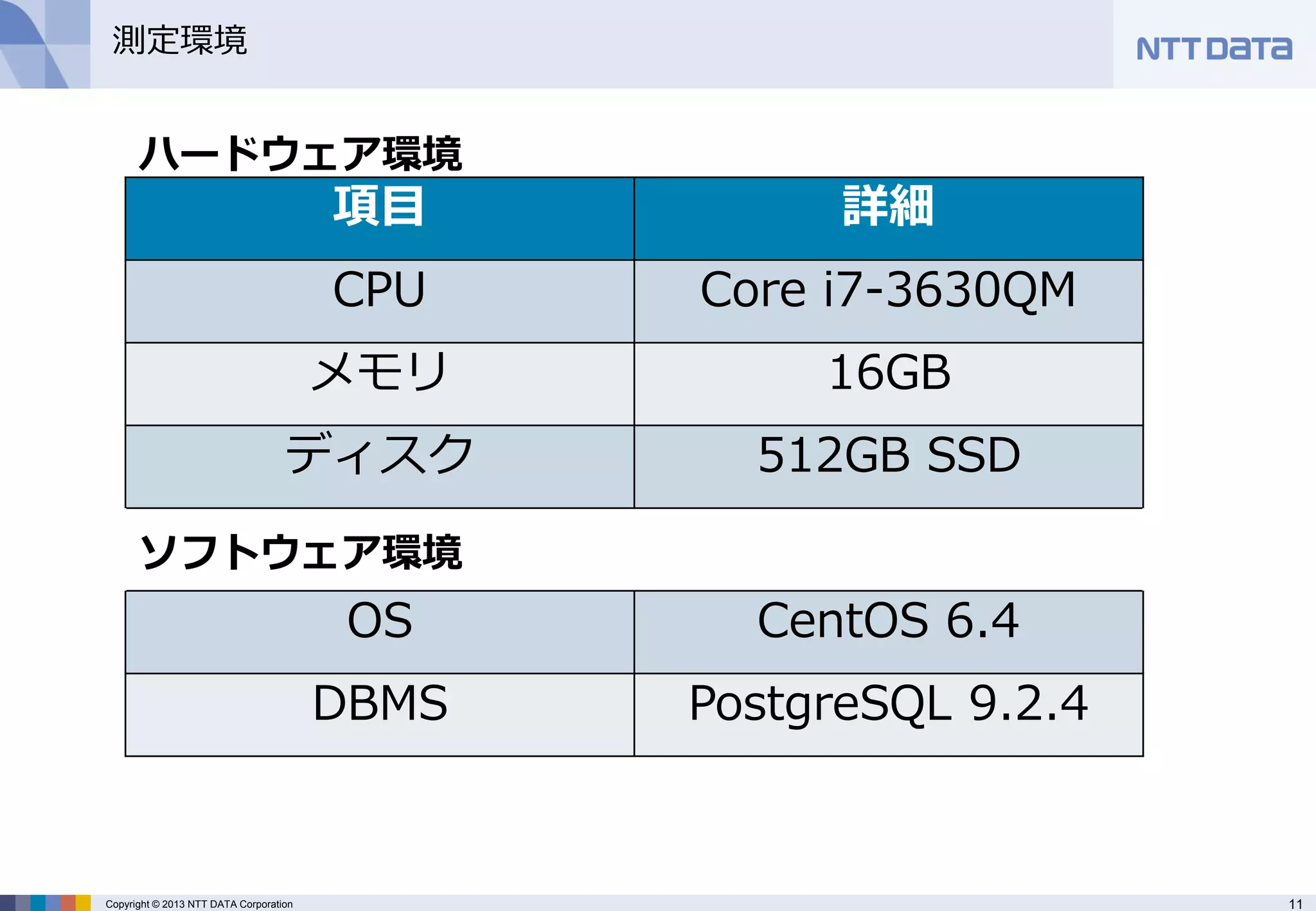
Copyright ©2013 NTT DATA Corporation
測定環境
項目
詳細
CPU
Core i7-3630QM
メモリ
16GB
ディスク
512GB SSD
OS
CentOS 6.4
DBMS
PostgreSQL 9.2.4
ハードウェア環境
ソフトウェア環境 - 12.
12
Copyright ©2013 NTT DATA Corporation
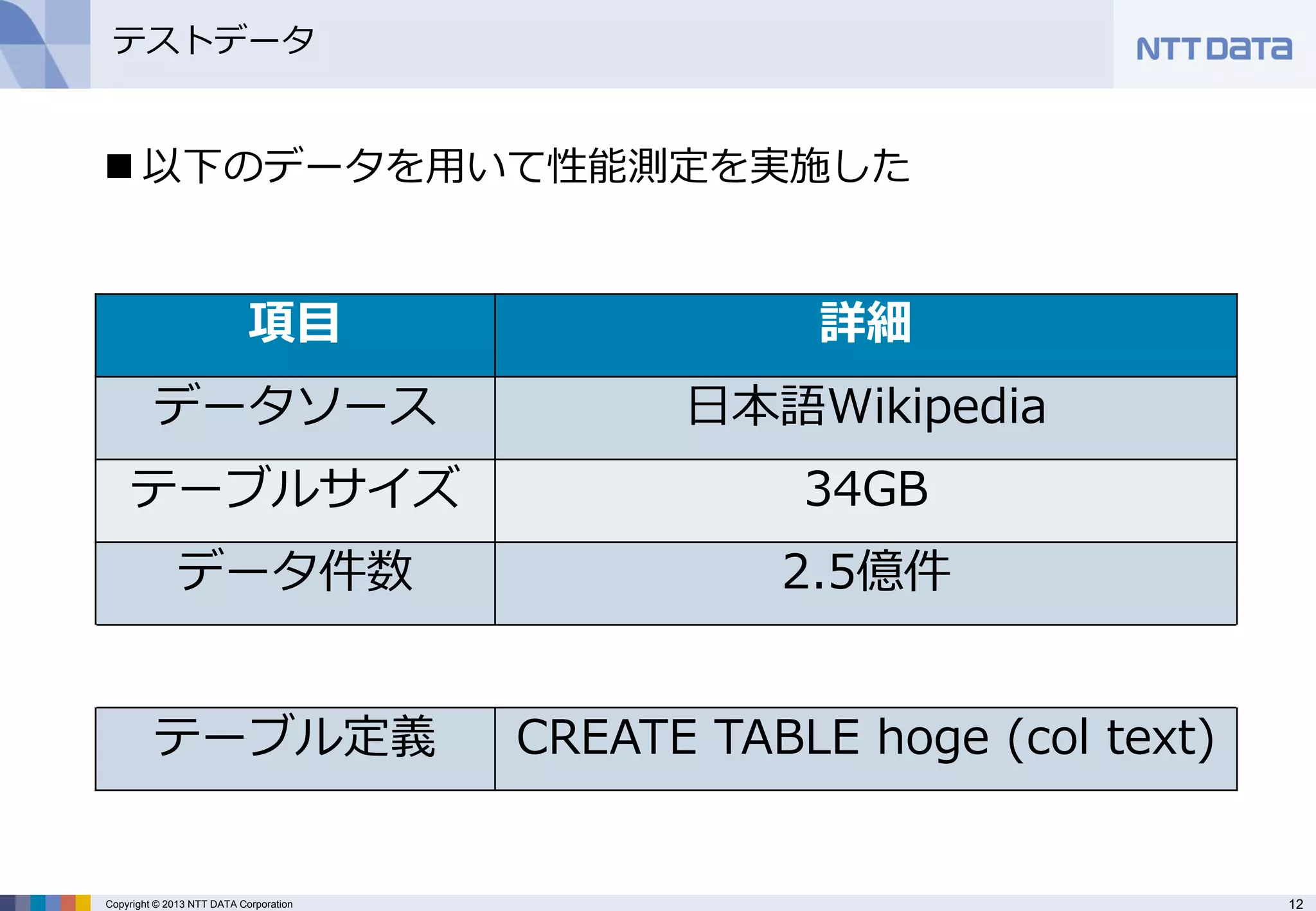
テストデータ
項目
詳細
データソース
日本語Wikipedia
テーブルサイズ
34GB
データ件数
2.5億件
テーブル定義
CREATE TABLE hoge (col text)
以下のデータを用いて性能測定を実施した - 13.
13
Copyright ©2013 NTT DATA Corporation
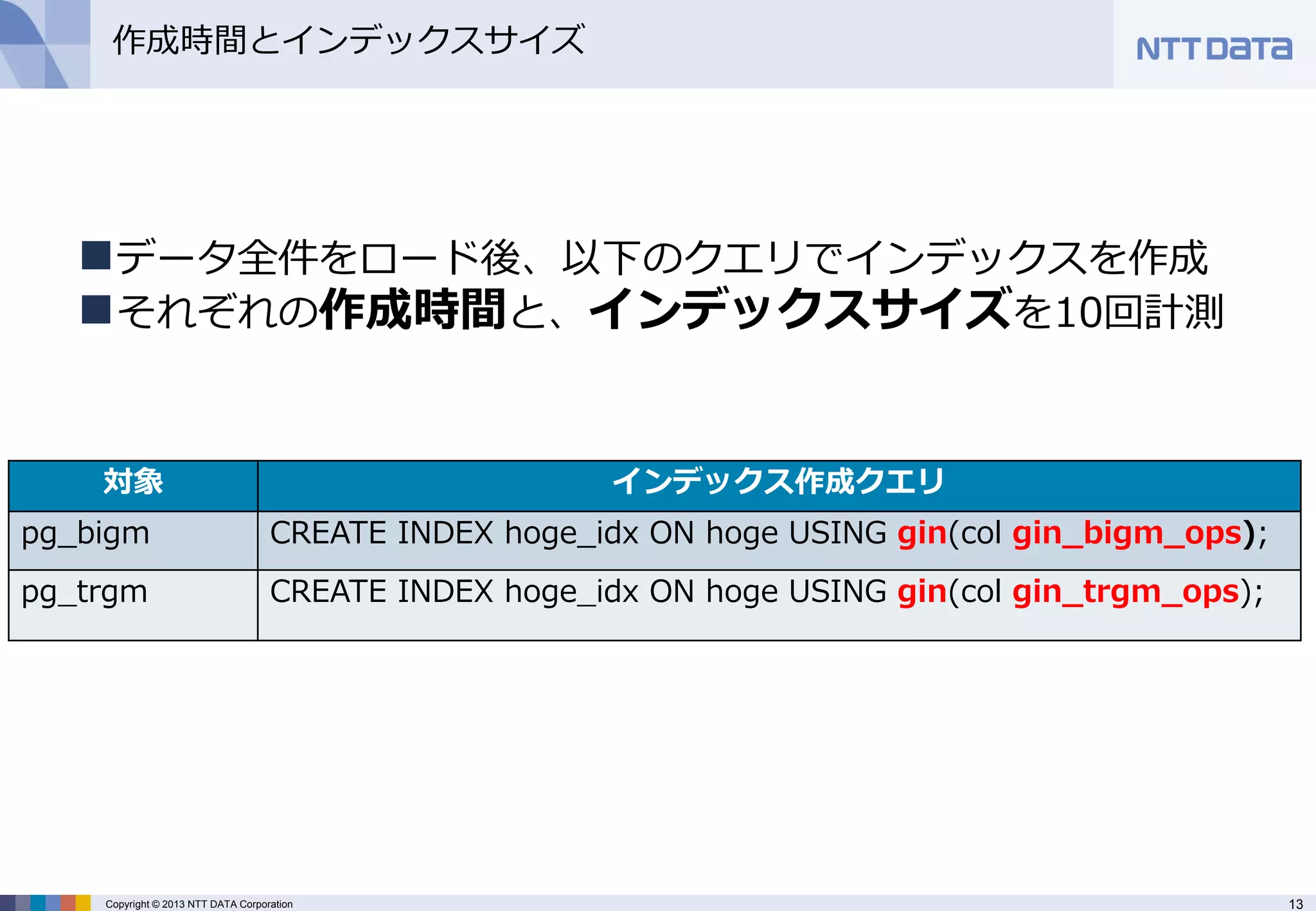
作成時間とインデックスサイズ
対象
インデックス作成クエリ
pg_bigm
CREATE INDEX hoge_idx ON hoge USING gin(col gin_bigm_ops);
pg_trgm
CREATE INDEX hoge_idx ON hoge USING gin(col gin_trgm_ops);
データ全件をロード後、以下のクエリでインデックスを作成
それぞれの作成時間と、インデックスサイズを10回計測 - 14.
14
Copyright ©2013 NTT DATA Corporation
作成時間とインデックスサイズ
pg_bigm
pg_trgm
インデックスサイズ
63GB
78GB
インデックス作成時間
約3時間
約5時間
結果
pg_bigmの方がインデックスサイズが小さく、作成時間が短 い結果となった
考察
2文字ずつの分割の方がキーの重複が多いため、pg_bigmの方 がインデックスサイズが小さい →詳細は次のスライド
pg_trgmではインデックス作成時に各3-gram文字列をハッ シュ変換するため、pg_bigmよりも時間がかかる - 15.
15
Copyright ©2013 NTT DATA Corporation
インデックスキーの重複
「あいあい」を2文字、3文字分割する場合
pg_bigm
△あ
あい
いあ
あい
い△
pg_trgm
△△あ
△あい
あいあ
いあい
あい△ - 16.
16
Copyright ©2013 NTT DATA Corporation
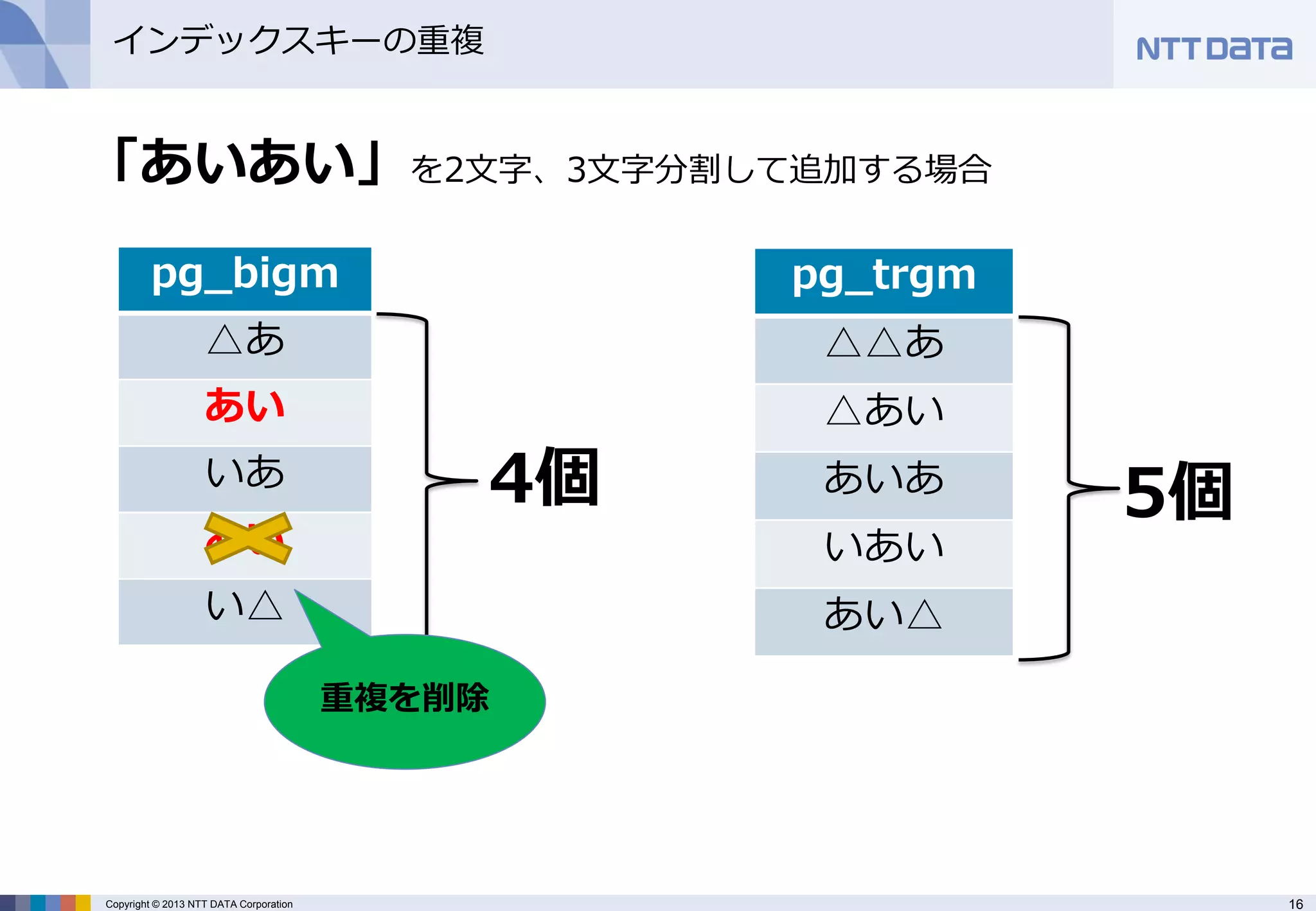
インデックスキーの重複
「あいあい」を2文字、3文字分割して追加する場合
pg_bigm
△あ
あい
いあ
あい
い△
pg_trgm
△△あ
△あい
あいあ
いあい
あい△
5個
4個
重複を削除 - 17.
17
Copyright ©2013 NTT DATA Corporation
インデックスキーの重複
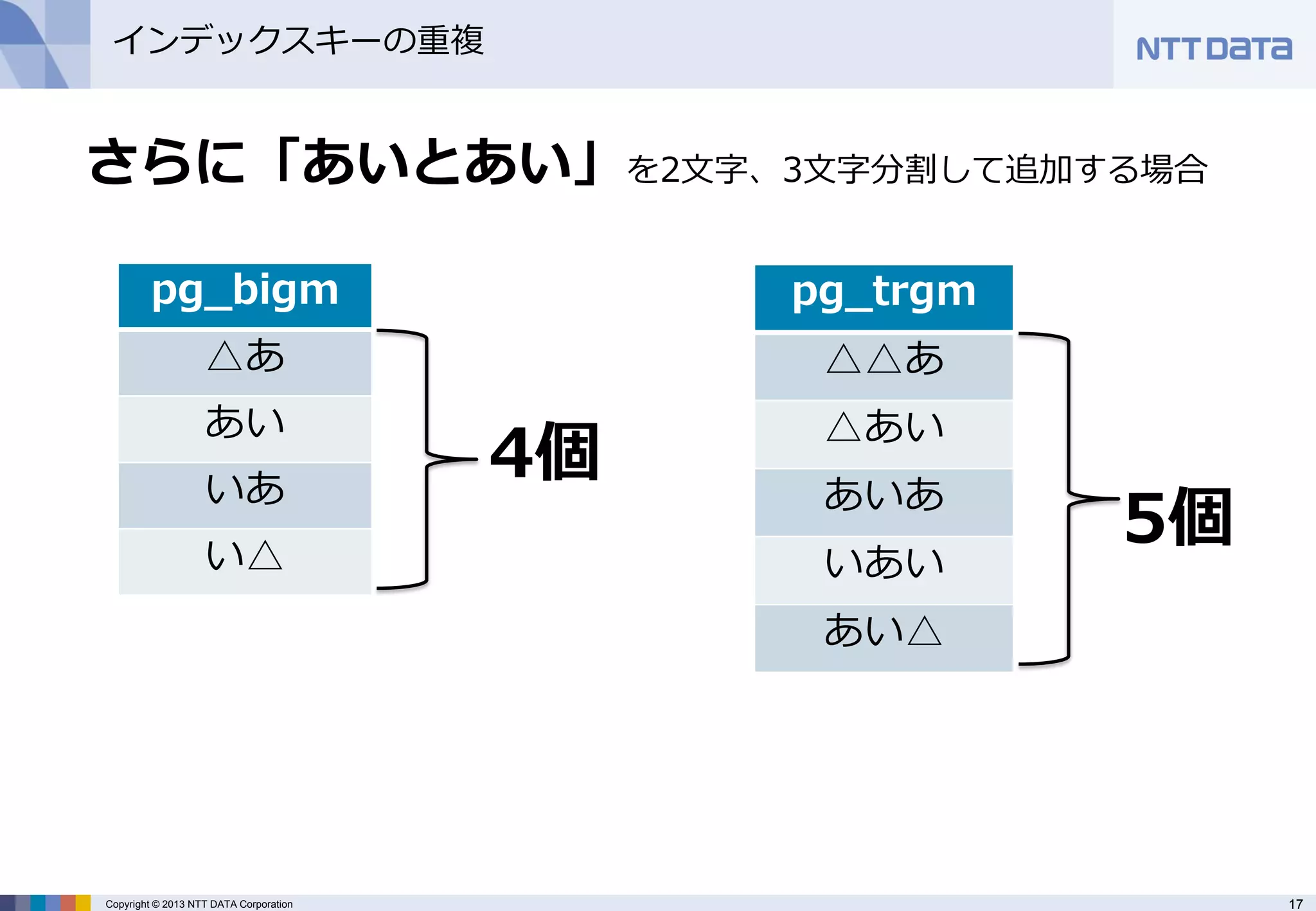
さらに「あいとあい」を2文字、3文字分割して追加する場合
pg_bigm
△あ
あい
いあ
い△
pg_trgm
△△あ
△あい
あいあ
いあい
あい△
5個
4個 - 18.
18
Copyright ©2013 NTT DATA Corporation
インデックスキーの重複
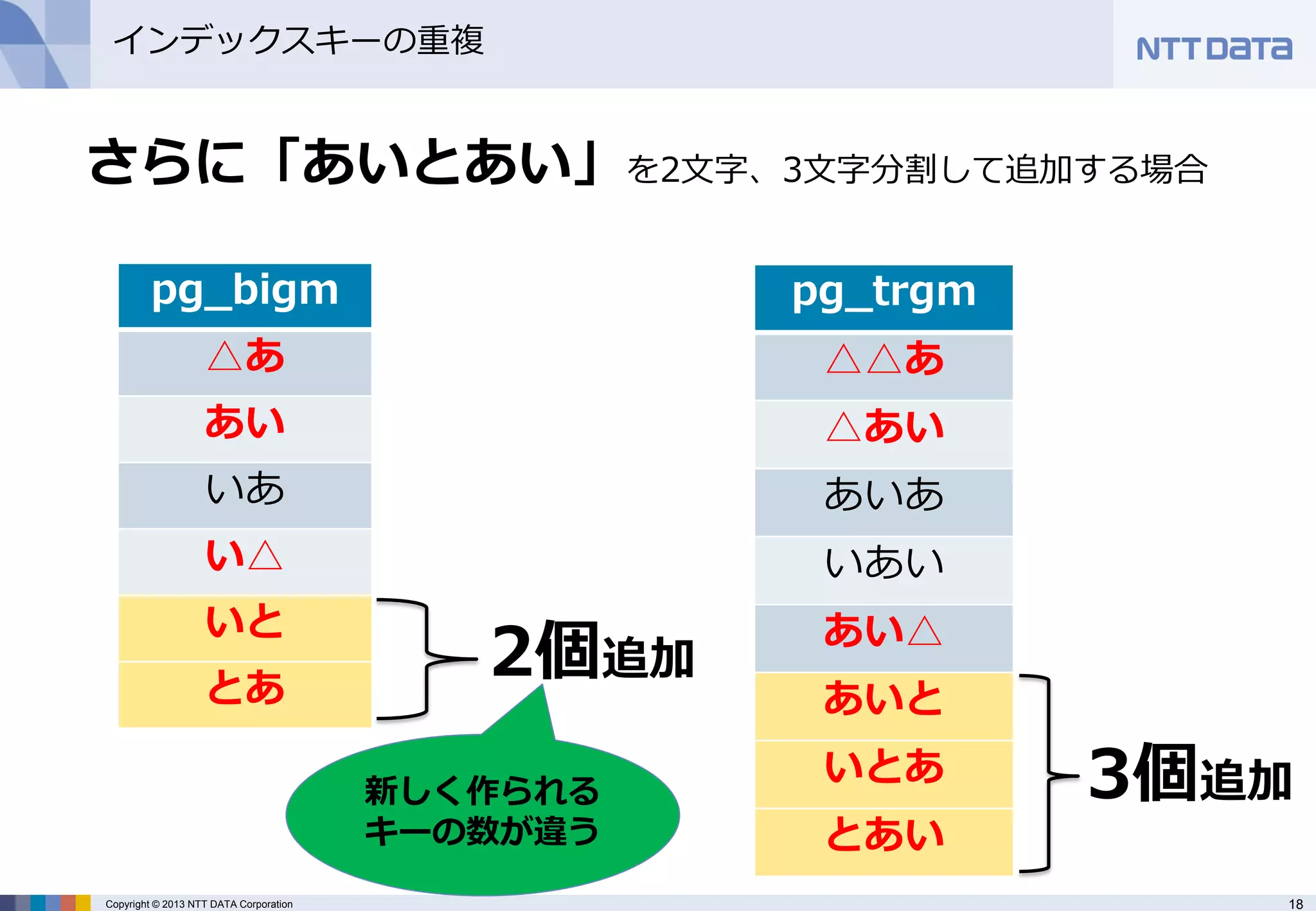
さらに「あいとあい」を2文字、3文字分割して追加する場合
pg_bigm
△あ
あい
いあ
い△
いと
とあ
2個追加
pg_trgm
△△あ
△あい
あいあ
いあい
あい△
あいと
いとあ
とあい
3個追加
新しく作られる キーの数が違う - 19.
19
Copyright ©2013 NTT DATA Corporation
検索時間の検証概要
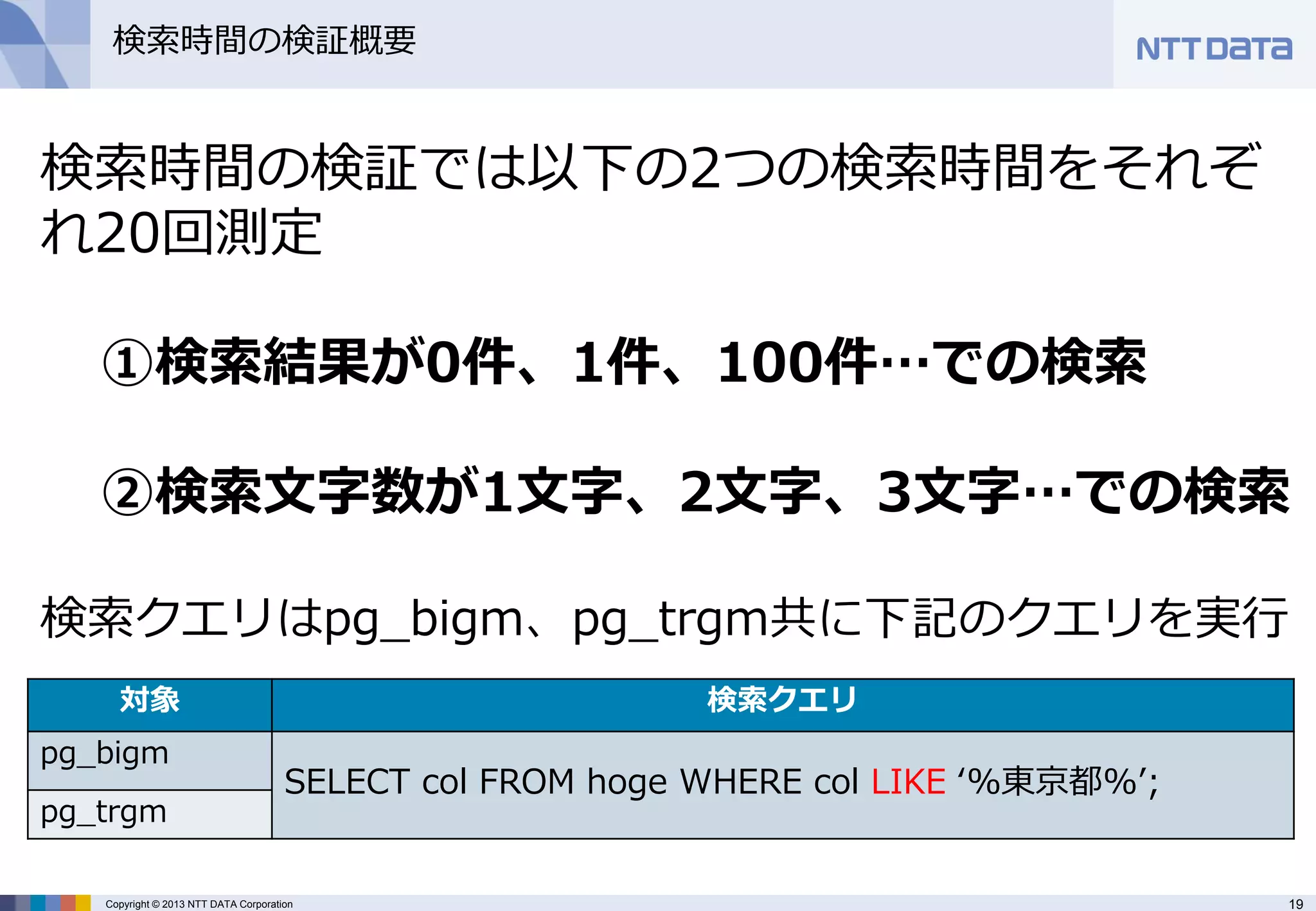
検索時間の検証では以下の2つの検索時間をそれぞ れ20回測定
①検索結果が0件、1件、100件…での検索
②検索文字数が1文字、2文字、3文字…での検索 検索クエリはpg_bigm、pg_trgm共に下記のクエリを実行
対象
検索クエリ
pg_bigm
SELECT col FROM hoge WHERE col LIKE ‘%東京都%’;
pg_trgm - 20.
20
Copyright ©2013 NTT DATA Corporation
検索時間の検証概要 ~検索文字列①~
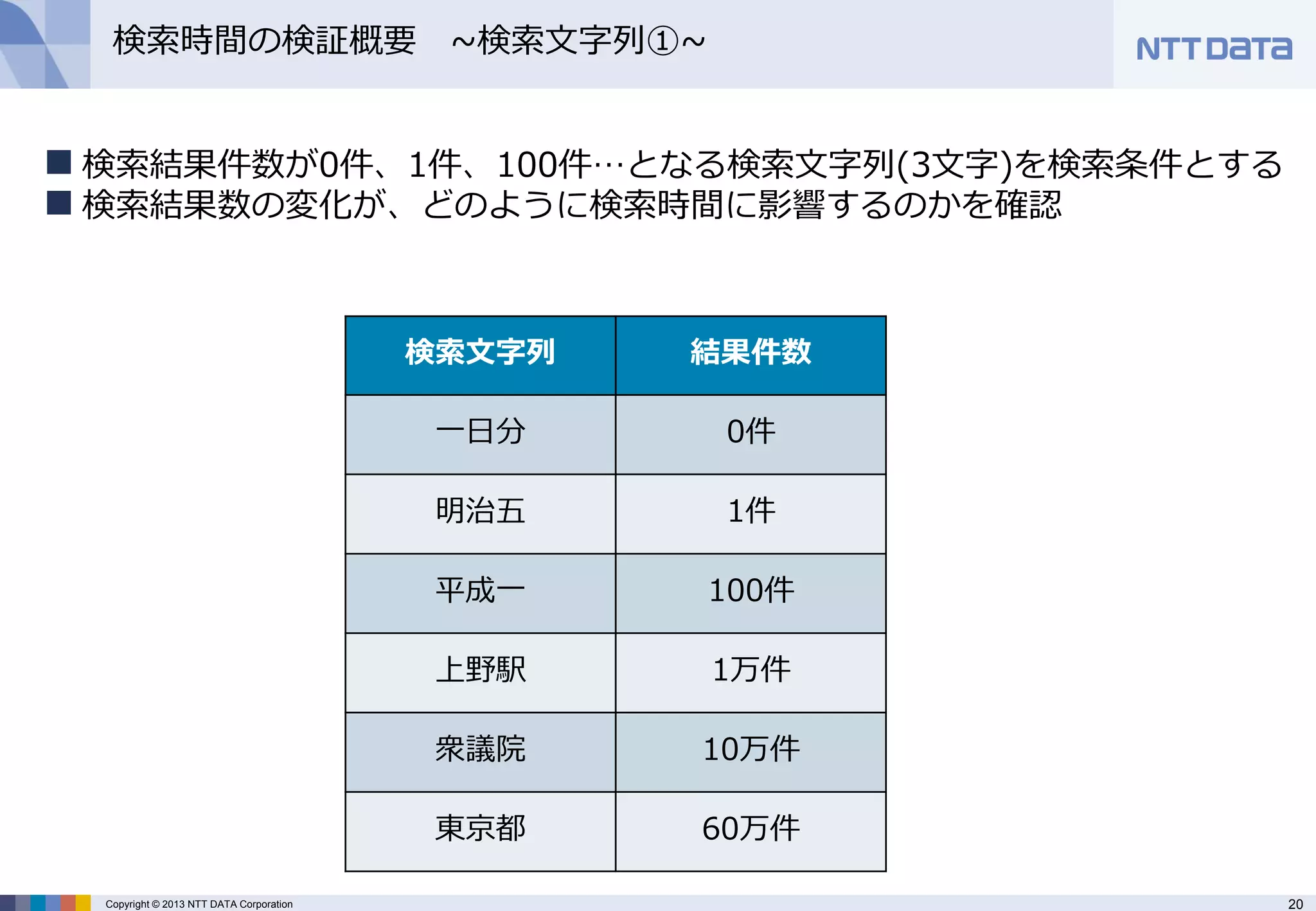
検索文字列
結果件数
一日分
0件
明治五
1件
平成一
100件
上野駅
1万件
衆議院
10万件
東京都
60万件
検索結果件数が0件、1件、100件…となる検索文字列(3文字)を検索条件とする
検索結果数の変化が、どのように検索時間に影響するのかを確認 - 21.
21
Copyright ©2013 NTT DATA Corporation
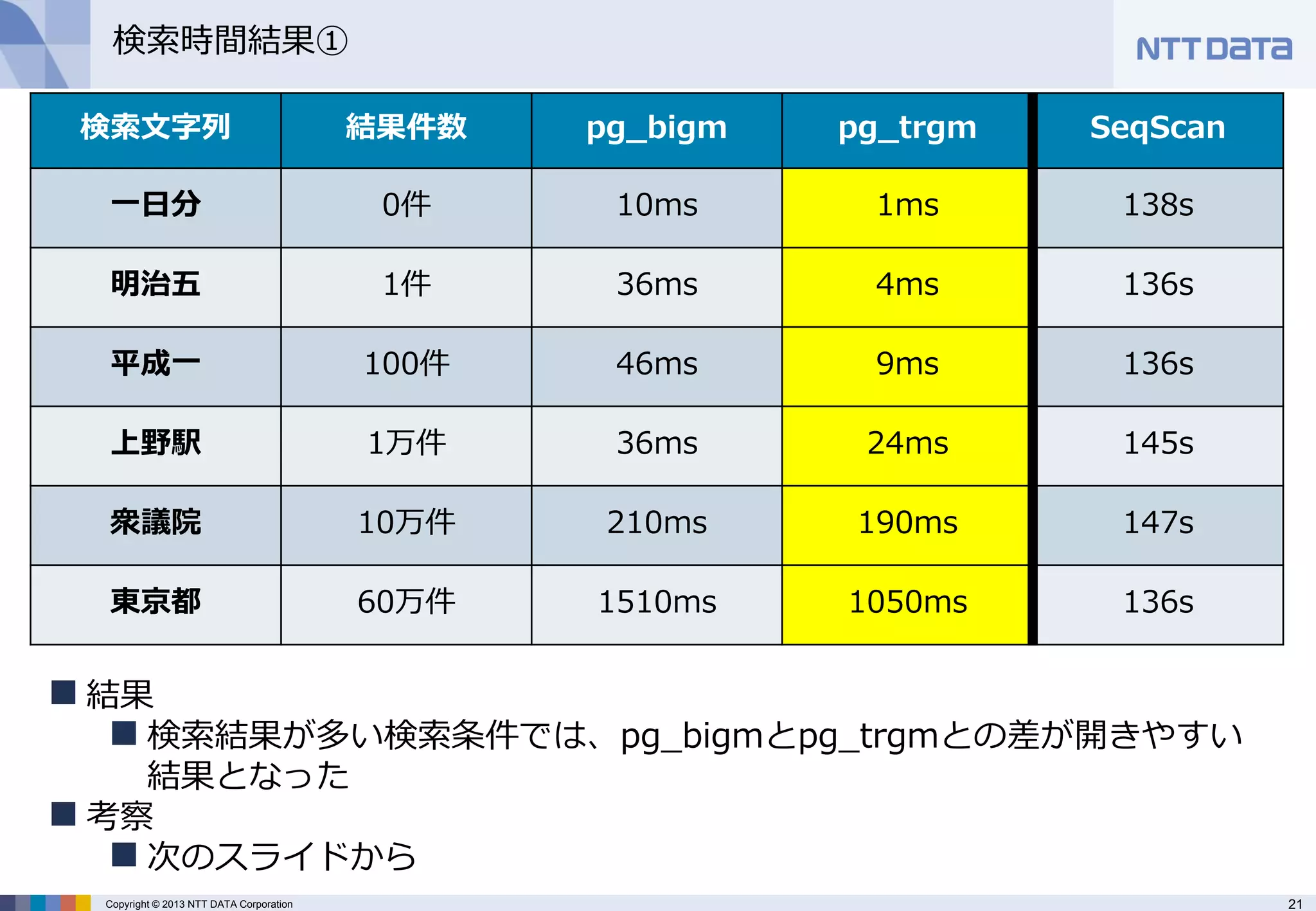
検索時間結果①
検索文字列
結果件数
pg_bigm
pg_trgm
SeqScan
一日分
0件
10ms
1ms
138s
明治五
1件
36ms
4ms
136s
平成一
100件
46ms
9ms
136s
上野駅
1万件
36ms
24ms
145s
衆議院
10万件
210ms
190ms
147s
東京都
60万件
1510ms
1050ms
136s
結果
検索結果が多い検索条件では、pg_bigmとpg_trgmとの差が開きやすい 結果となった
考察
次のスライドから - 22.
22
Copyright ©2013 NTT DATA Corporation
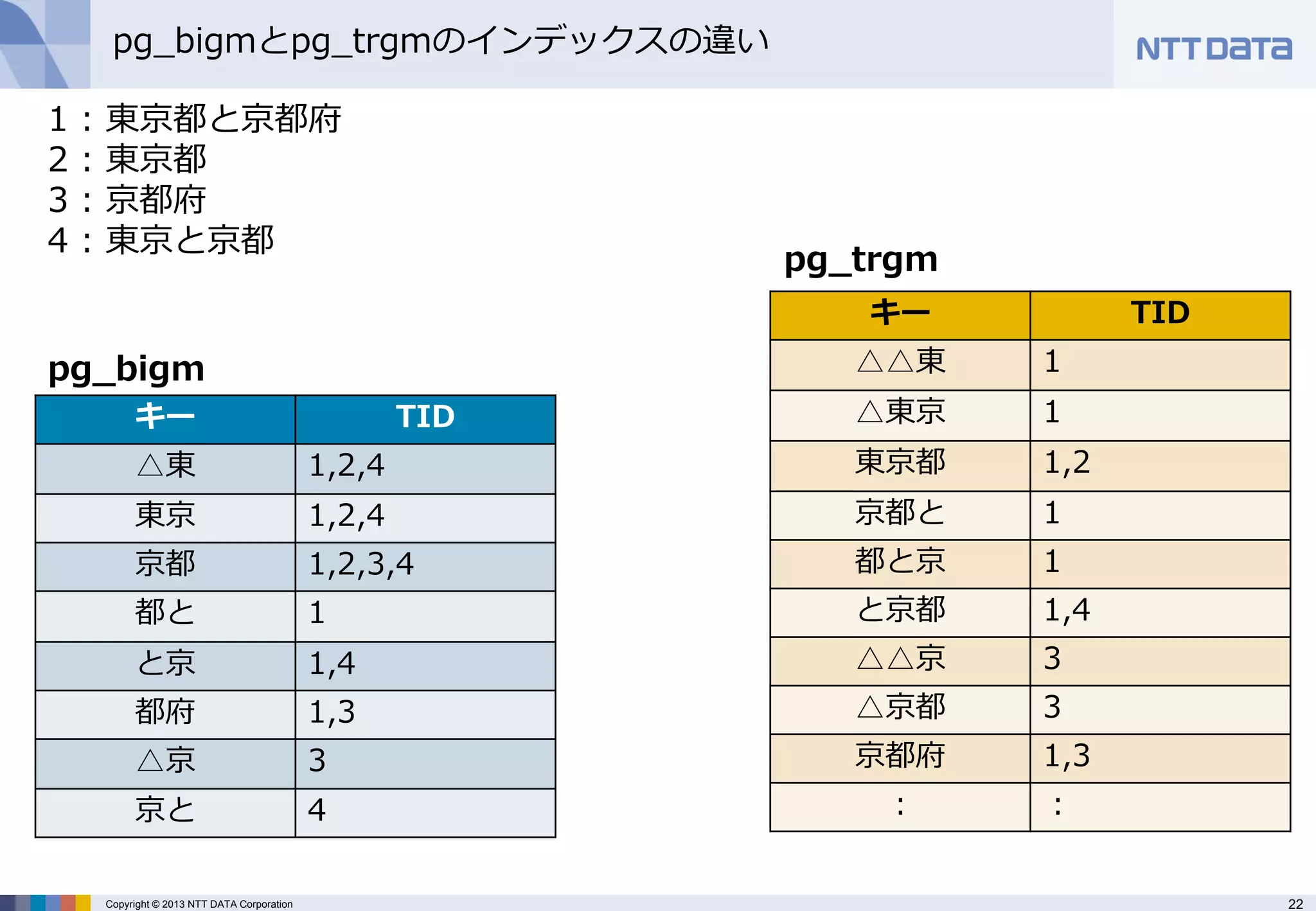
pg_bigmとpg_trgmのインデックスの違い
キー
TID
△東
1,2,4
東京
1,2,4
京都
1,2,3,4
都と
1
と京
1,4
都府
1,3
△京
3
京と
4
キー
TID
△△東
1
△東京
1
東京都
1,2
京都と
1
都と京
1
と京都
1,4
△△京
3
△京都
3
京都府
1,3
:
:
pg_trgm
pg_bigm
1 : 東京都と京都府 2 : 東京都 3 : 京都府 4 : 東京と京都 - 23.
23
Copyright ©2013 NTT DATA Corporation
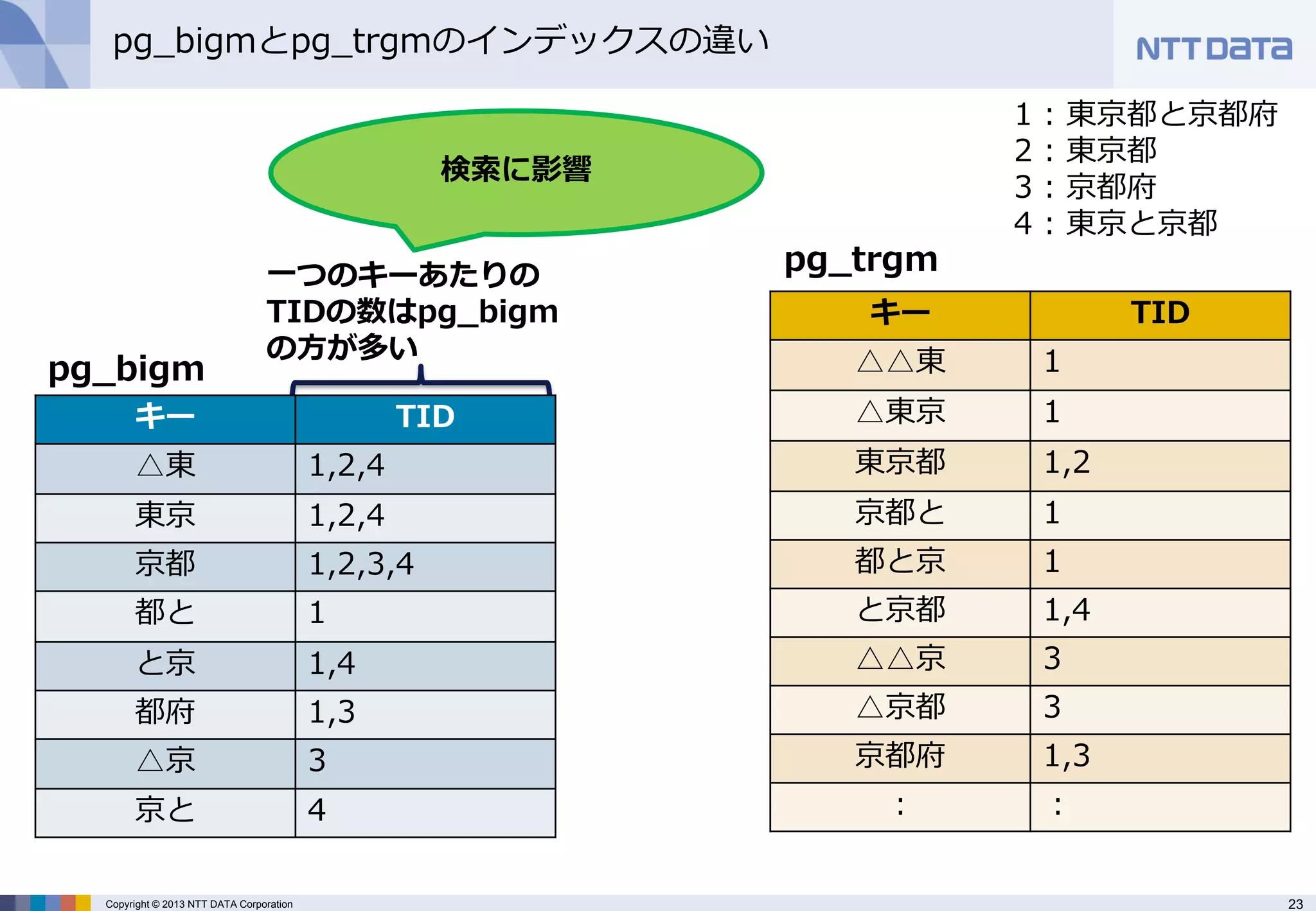
pg_bigmとpg_trgmのインデックスの違い
一つのキーあたりの TIDの数はpg_bigm の方が多い
検索に影響
1 : 東京都と京都府 2 : 東京都 3 : 京都府 4 : 東京と京都
キー
TID
△東
1,2,4
東京
1,2,4
京都
1,2,3,4
都と
1
と京
1,4
都府
1,3
△京
3
京と
4
pg_bigm
キー
TID
△△東
1
△東京
1
東京都
1,2
京都と
1
都と京
1
と京都
1,4
△△京
3
△京都
3
京都府
1,3
:
:
pg_trgm - 24.
24
Copyright ©2013 NTT DATA Corporation
キー
TID
△△東
1
△東京
1
東京都
1,2
京都と
1
都と京
1
と京都
1,4
△△京
3
△京都
3
京都府
1,3
:
:
pg_trgm
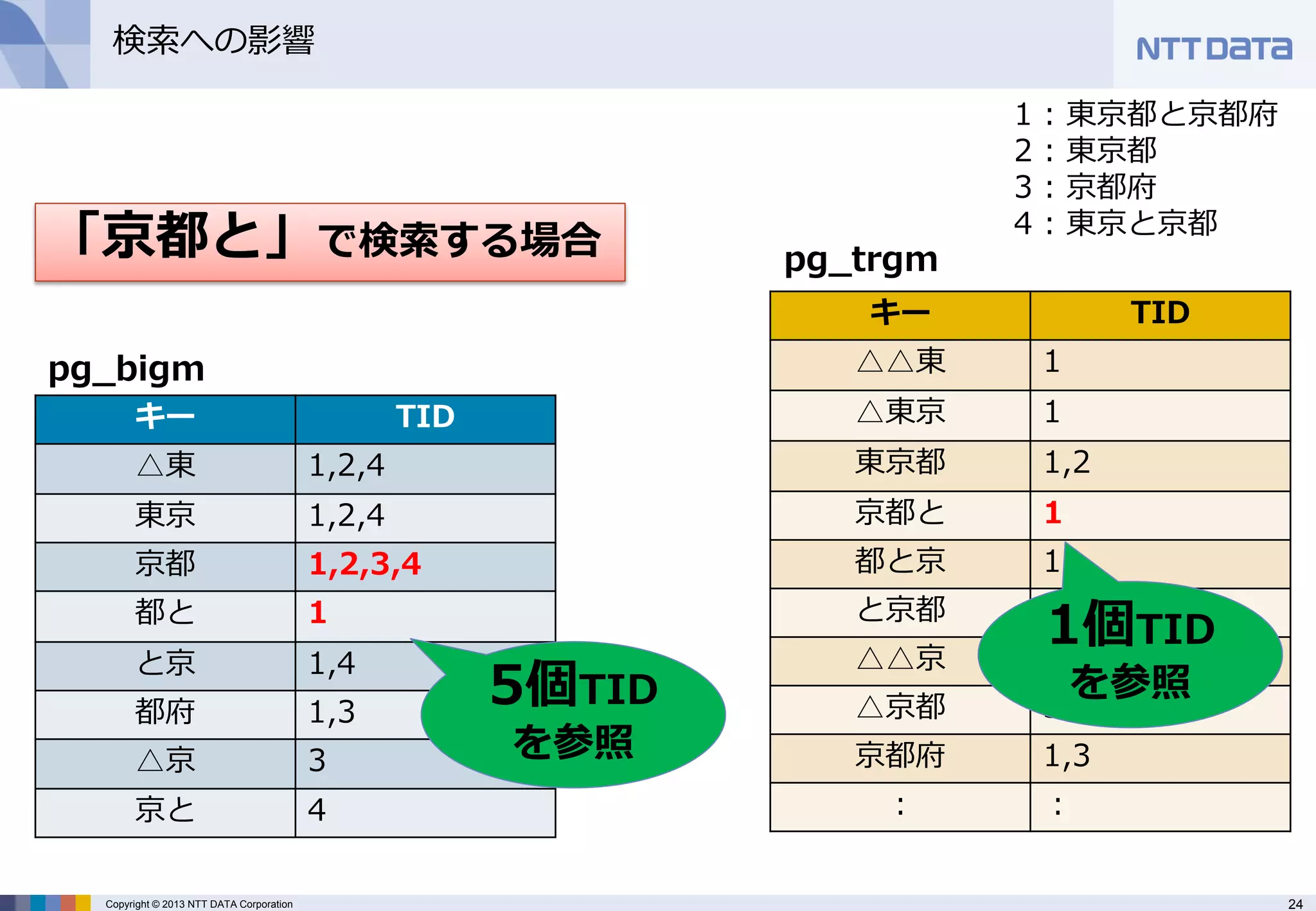
検索への影響
1 : 東京都と京都府
2 : 東京都
3 : 京都府
4 : 東京と京都
1個TID を参照
「京都と」で検索する場合
キー
TID
△東
1,2,4
東京
1,2,4
京都
1,2,3,4
都と
1
と京
1,4
都府
1,3
△京
3
京と
4
pg_bigm
5個TID を参照 - 25.
25
Copyright ©2013 NTT DATA Corporation
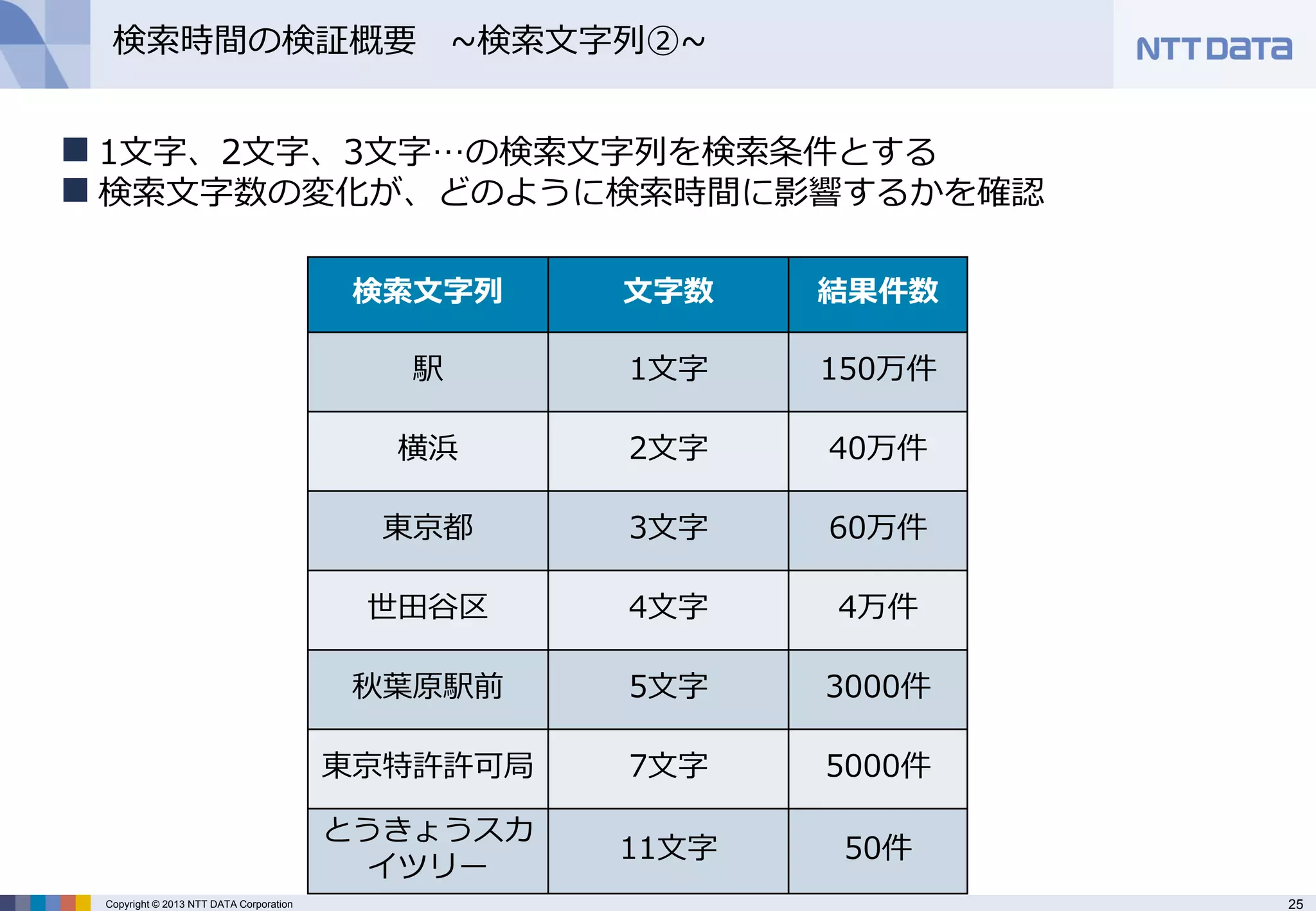
検索時間の検証概要 ~検索文字列②~
1文字、2文字、3文字…の検索文字列を検索条件とする
検索文字数の変化が、どのように検索時間に影響するかを確認
検索文字列
文字数
結果件数
駅
1文字
150万件
横浜
2文字
40万件
東京都
3文字
60万件
世田谷区
4文字
4万件
秋葉原駅前
5文字
3000件
東京特許許可局
7文字
5000件
とうきょうスカ イツリー
11文字
50件 - 26.
26
Copyright ©2013 NTT DATA Corporation
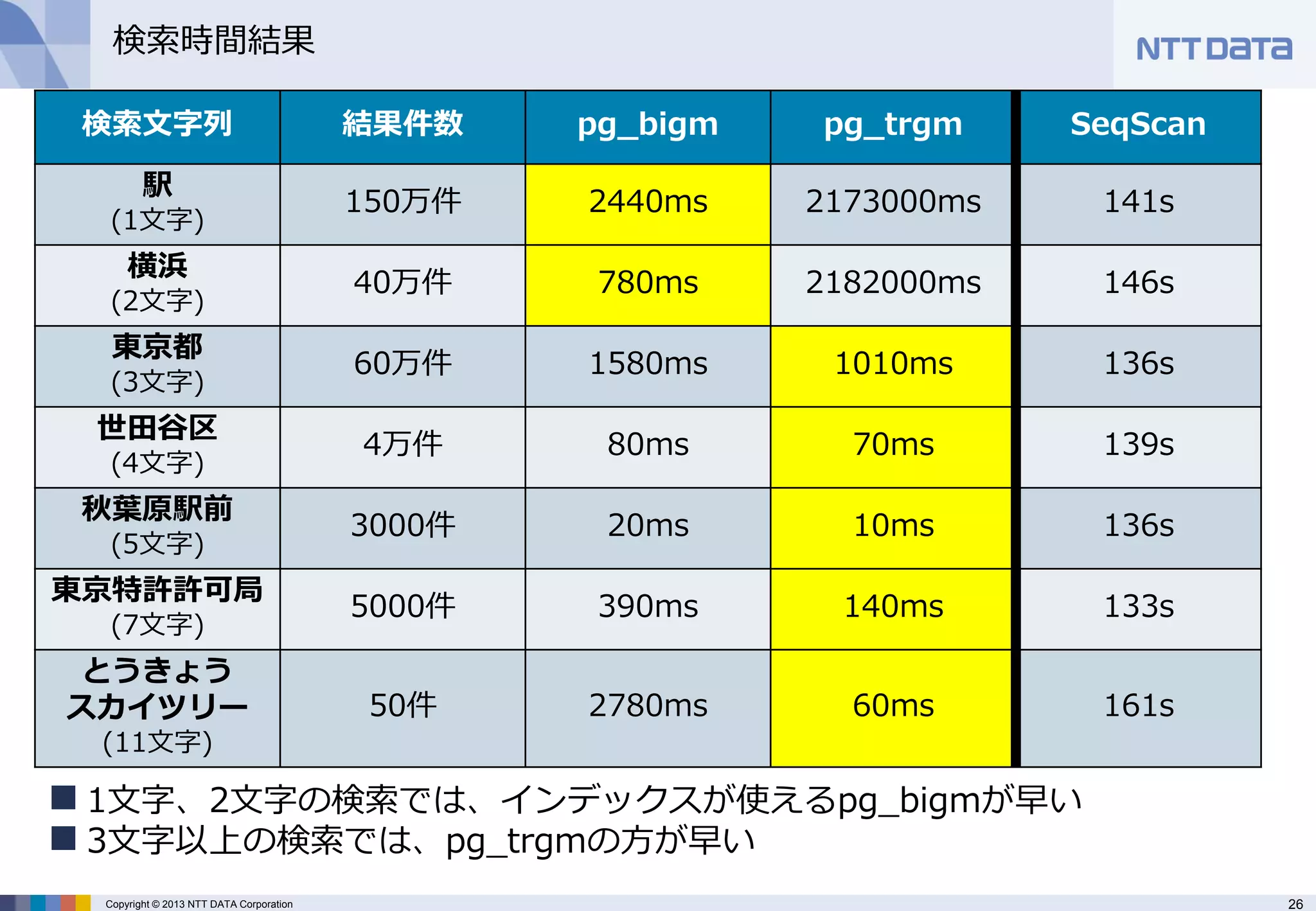
検索時間結果
検索文字列
結果件数
pg_bigm
pg_trgm
SeqScan
駅
(1文字)
150万件
2440ms
2173000ms
141s
横浜
(2文字)
40万件
780ms
2182000ms
146s
東京都
(3文字)
60万件
1580ms
1010ms
136s
世田谷区
(4文字)
4万件
80ms
70ms
139s
秋葉原駅前
(5文字)
3000件
20ms
10ms
136s
東京特許許可局
(7文字)
5000件
390ms
140ms
133s
とうきょう
スカイツリー
(11文字)
50件
2780ms
60ms
161s
1文字、2文字の検索では、インデックスが使えるpg_bigmが早い
3文字以上の検索では、pg_trgmの方が早い - 27.
27
Copyright ©2013 NTT DATA Corporation
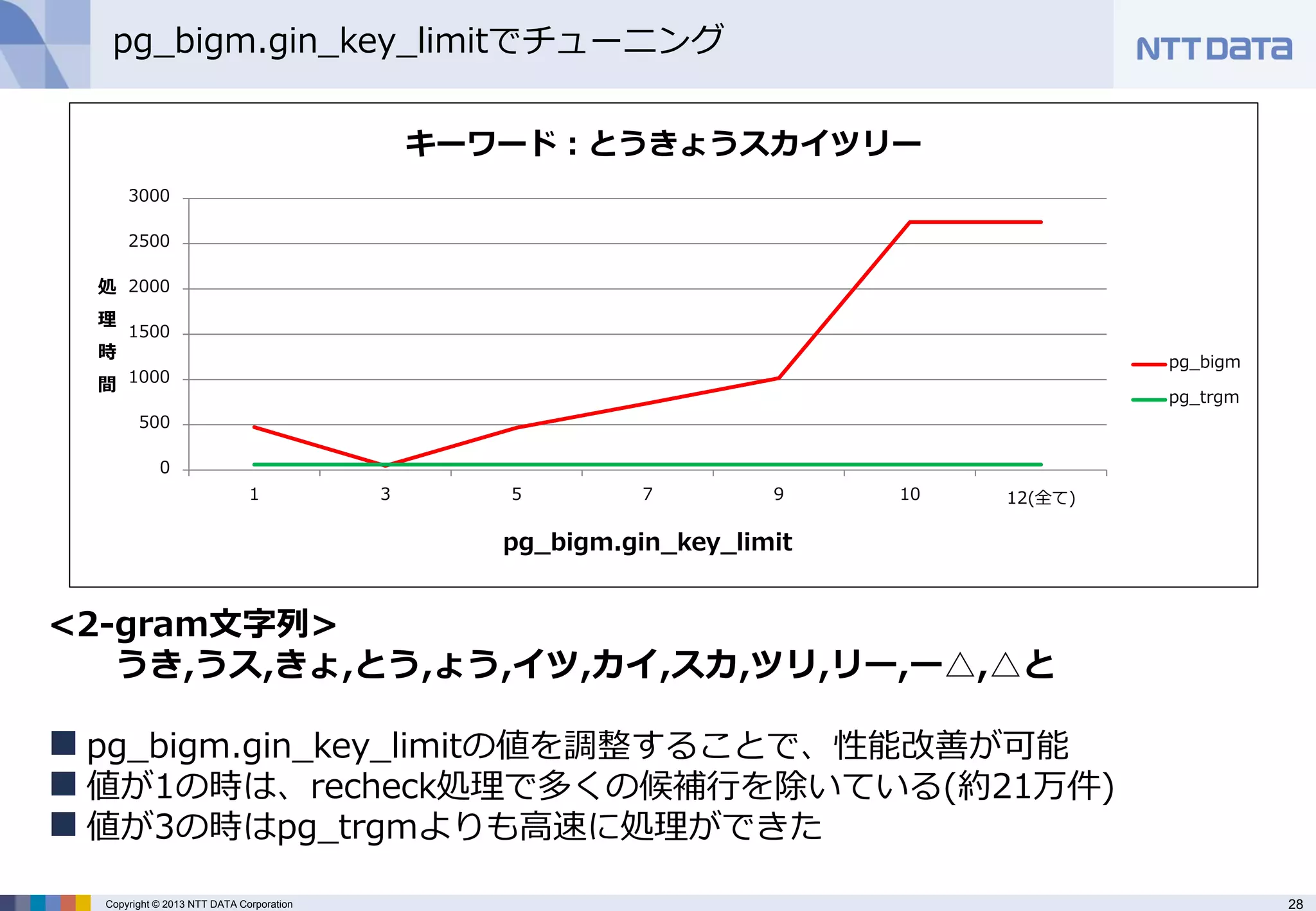
pg_bigm.gin_key_limitでチューニング
pg_bigm.gin_key_limitパラメータで検索時に使用する2- gram文字列の個数の最大数を指定することでチューニングが可 能
「とうきょうスカイツリー」で全文検索をした場合、
2-gram文字列は、
うき,うス,きょ,とう,ょう,イツ,カイ,スカ,ツリ,リー,ー△,△と
12個
pg_bigm.gin_key_limitで この最大数を指定 - 28.
28
Copyright ©2013 NTT DATA Corporation
pg_bigm.gin_key_limitでチューニング
0
500
1000
1500
2000
2500
3000
1
3
5
7
9
10
12(全て)
処 理 時 間
pg_bigm.gin_key_limit
キーワード:とうきょうスカイツリー
pg_bigm
pg_trgm
<2-gram文字列> うき,うス,きょ,とう,ょう,イツ,カイ,スカ,ツリ,リー,ー△,△と
pg_bigm.gin_key_limitの値を調整することで、性能改善が可能
値が1の時は、recheck処理で多くの候補行を除いている(約21万件)
値が3の時はpg_trgmよりも高速に処理ができた - 29.
29
Copyright ©2013 NTT DATA Corporation
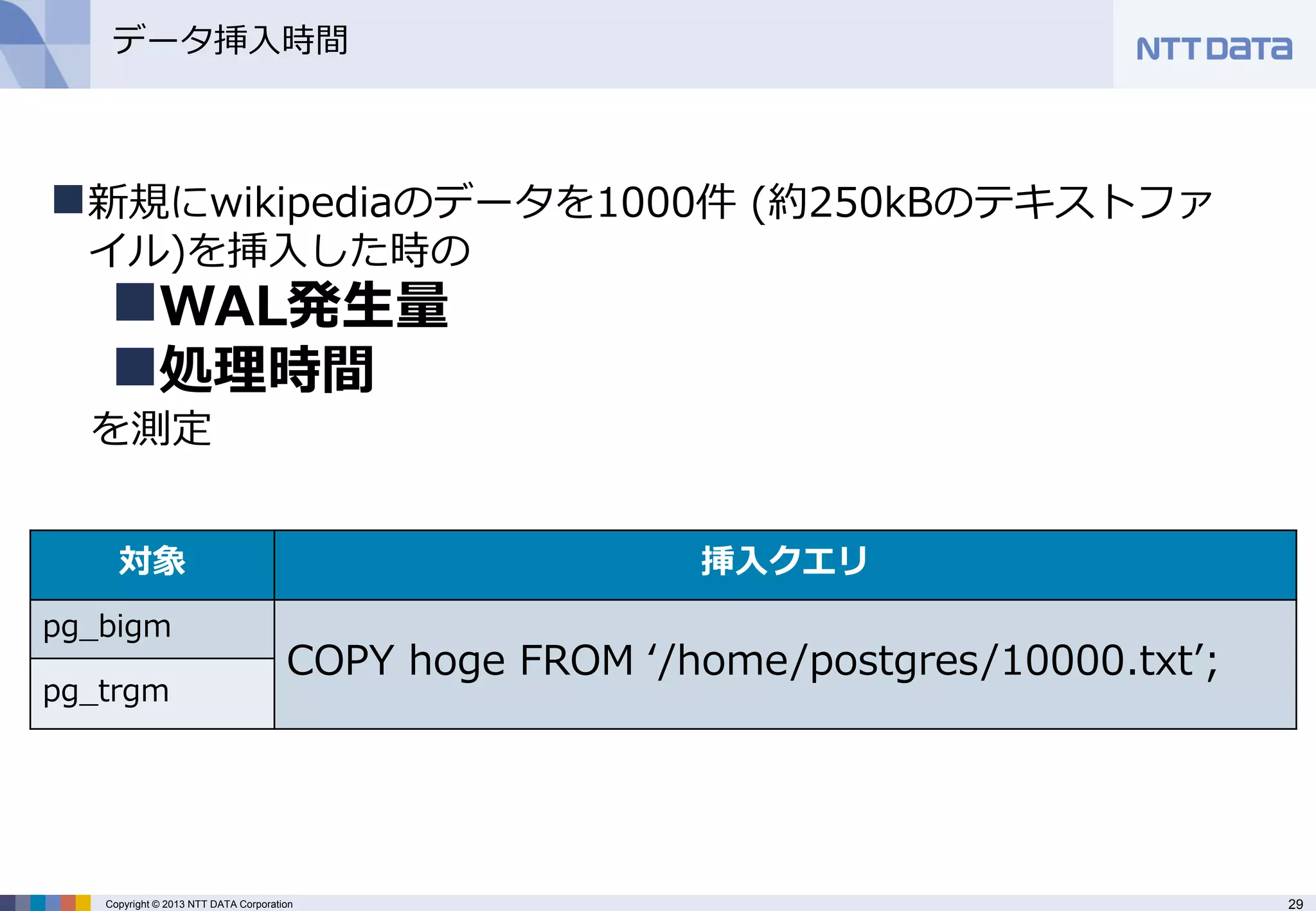
データ挿入時間
新規にwikipediaのデータを1000件 (約250kBのテキストファ イル)を挿入した時の
WAL発生量
処理時間 を測定
対象
挿入クエリ
pg_bigm
COPY hoge FROM ‘/home/postgres/10000.txt’;
pg_trgm - 30.
30
Copyright ©2013 NTT DATA Corporation
データ挿入時間
pg_bigm
pg_trgm
WAL発生量
9*16MB
11*16MB
処理時間
10914.53ms
22906.03ms
結果
pg_bigmの方がWALの発生量が小さい
pg_bigmの方がデータ挿入時間が短い
考察
pg_trgmではキー登録時にハッシュ変換があるため、処理時 間に差が出た - 31.
- 32.
32
Copyright ©2013 NTT DATA Corporation
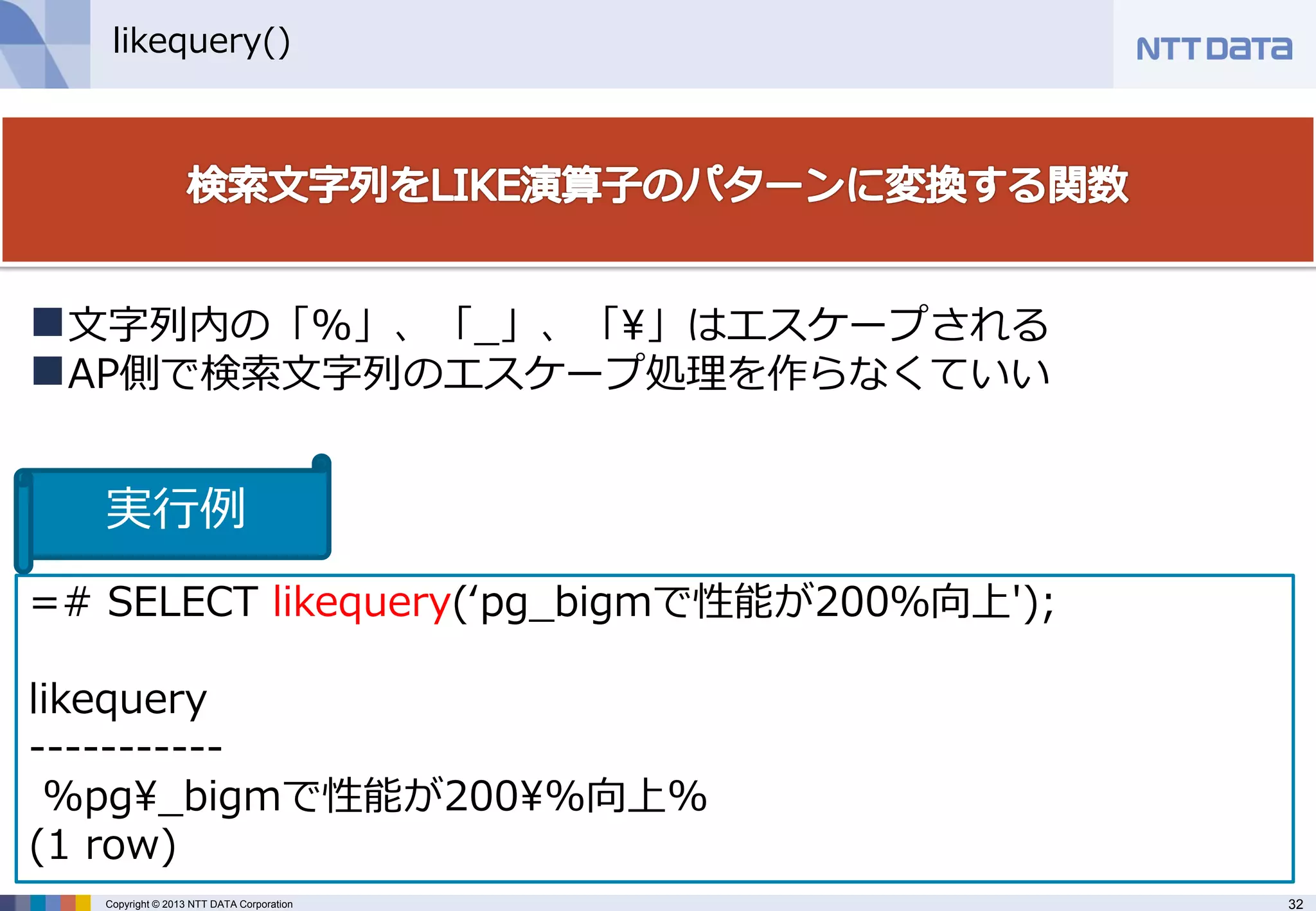
likequery()
=# SELECT likequery(‘pg_bigmで性能が200%向上'); likequery ----------- %pg¥_bigmで性能が200¥%向上% (1 row)
文字列内の「%」、「_」、「¥」はエスケープされる
AP側で検索文字列のエスケープ処理を作らなくていい
実行例 - 33.
33
Copyright ©2013 NTT DATA Corporation
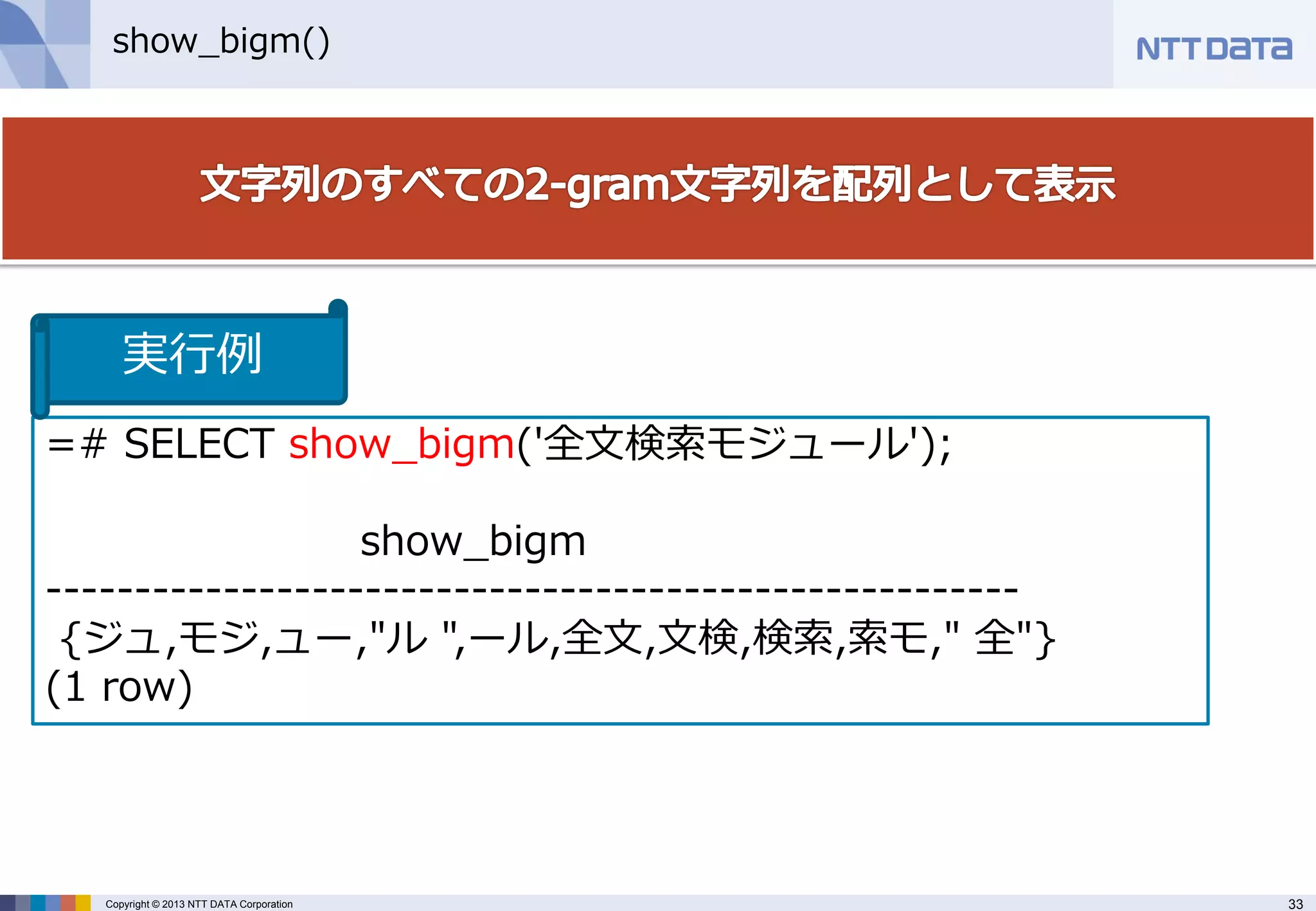
show_bigm()
=# SELECT show_bigm('全文検索モジュール');
show_bigm
-------------------------------------------------------
{ジュ,モジ,ュー,"ル ",ール,全文,文検,検索,索モ," 全"}
(1 row)
実行例 - 34.
34
Copyright ©2013 NTT DATA Corporation
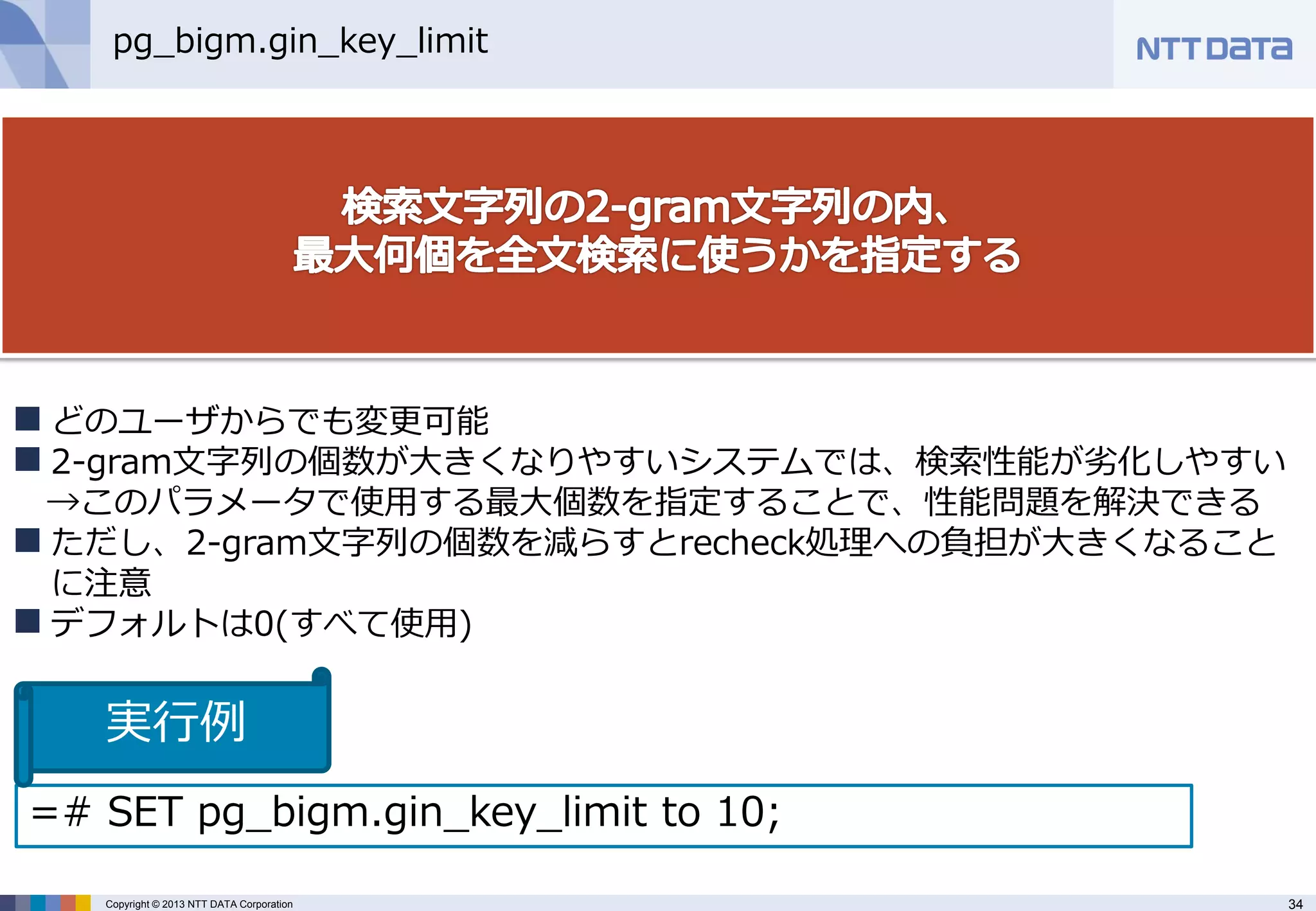
pg_bigm.gin_key_limit
どのユーザからでも変更可能
2-gram文字列の個数が大きくなりやすいシステムでは、検索性能が劣化しやすい →このパラメータで使用する最大個数を指定することで、性能問題を解決できる
ただし、2-gram文字列の個数を減らすとrecheck処理への負担が大きくなること に注意
デフォルトは0(すべて使用)
=# SET pg_bigm.gin_key_limit to 10;
実行例 - 35.
35
Copyright ©2013 NTT DATA Corporation
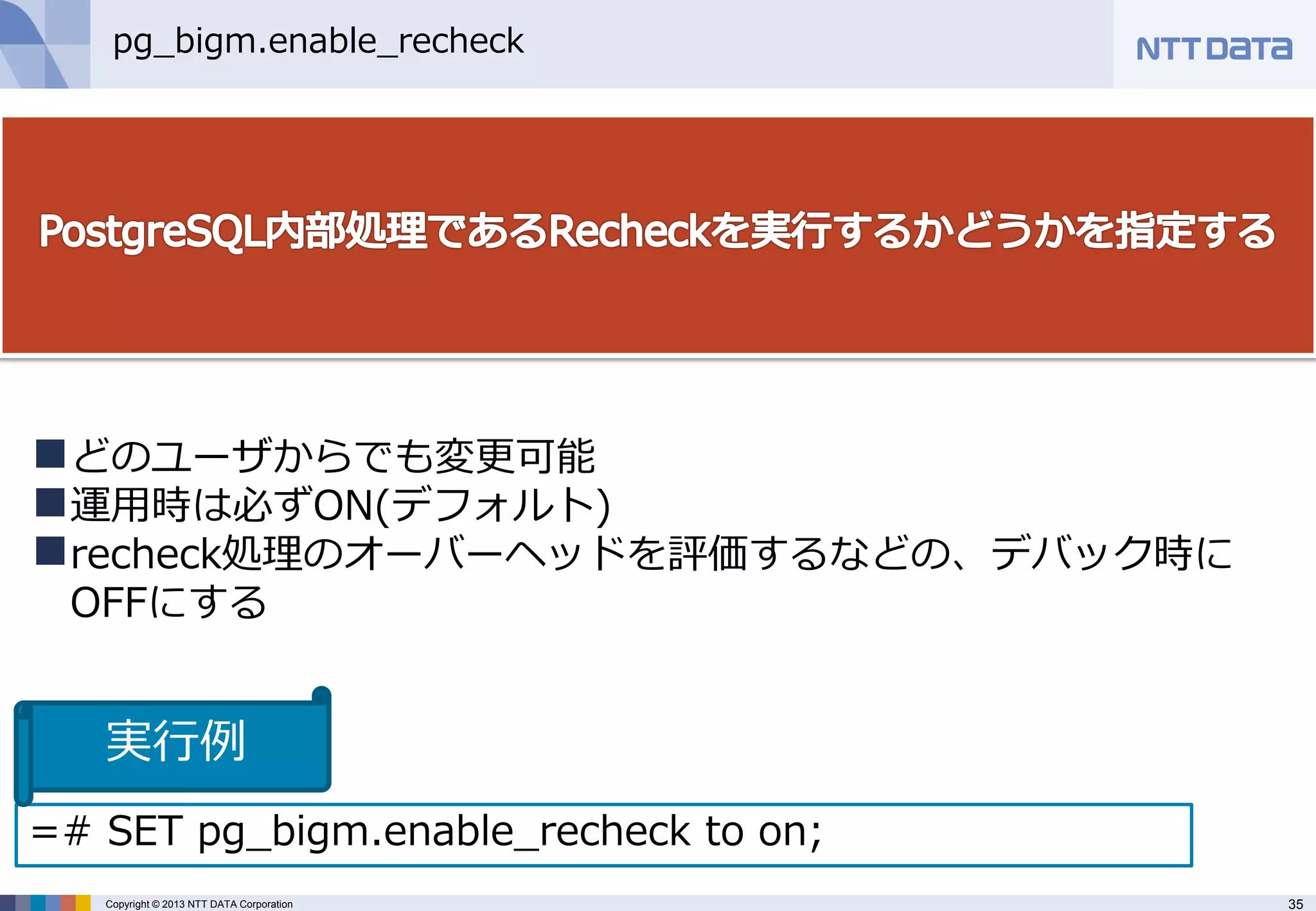
pg_bigm.enable_recheck
どのユーザからでも変更可能
運用時は必ずON(デフォルト)
recheck処理のオーバーヘッドを評価するなどの、デバック時に OFFにする
=# SET pg_bigm.enable_recheck to on;
実行例 - 36.
- 37.
37
Copyright ©2013 NTT DATA Corporation
デモ
以下のデモを通して、pg_bigmのインストールや、全 文検索実行まで紹介いたします。
pg_bigmインストール
全文検索インデックス作成
全文検索
インデックスを用いた検索
SeqScanとの速度の違い
1文字、2文字での検索 - 38.
- 39.
39
Copyright ©2013 NTT DATA Corporation
まとめ
全文検索を高速に行うために、pg_bigmやpg_trgmを 用いて全文検索用インデックスを作成する
インデックスサイズ
pg_bigmの方が小さい
インデックス作成時間
pg_bigmの方が早い
検索
検索結果数が多いほど、pg_trgmの方が早い →pg_bigm.gin_key_limit等でチューニング可能
1,2文字検索ではインデックスを使えるため pg_bigmの方が早い
pg_bigm新バージョンリリース! - 40.
40
Copyright ©2013 NTT DATA Corporation
pg_bigm新バージョンがリリース予定
pg_bigm新バージョンでは主に以下の内容が更新されています
類似度検索も 現在開発中 - 41.
- 42.
- 43.
43
Copyright ©2013 NTT DATA Corporation
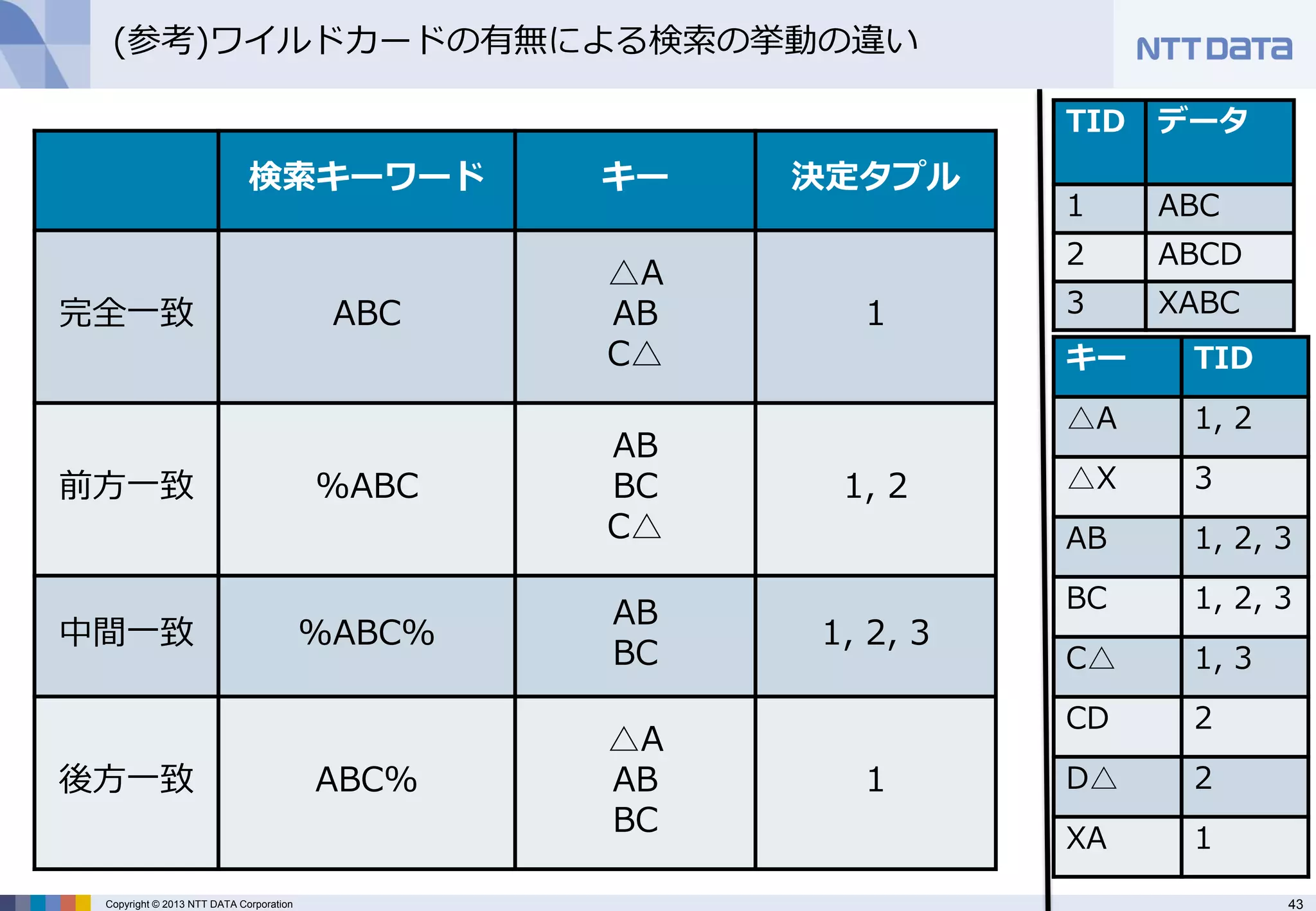
(参考)ワイルドカードの有無による検索の挙動の違い
キー
TID
△A
1, 2
△X
3
AB
1, 2, 3
BC
1, 2, 3
C△
1, 3
CD
2
D△
2
XA
1
TID
データ
1
ABC
2
ABCD
3
XABC
検索キーワード
キー
決定タプル
完全一致
ABC
△A
AB
C△
1
前方一致
%ABC
AB
BC
C△
1, 2
中間一致
%ABC%
AB
BC
1, 2, 3
後方一致
ABC%
△A
AB
BC
1 - 44.
44
Copyright ©2013 NTT DATA Corporation
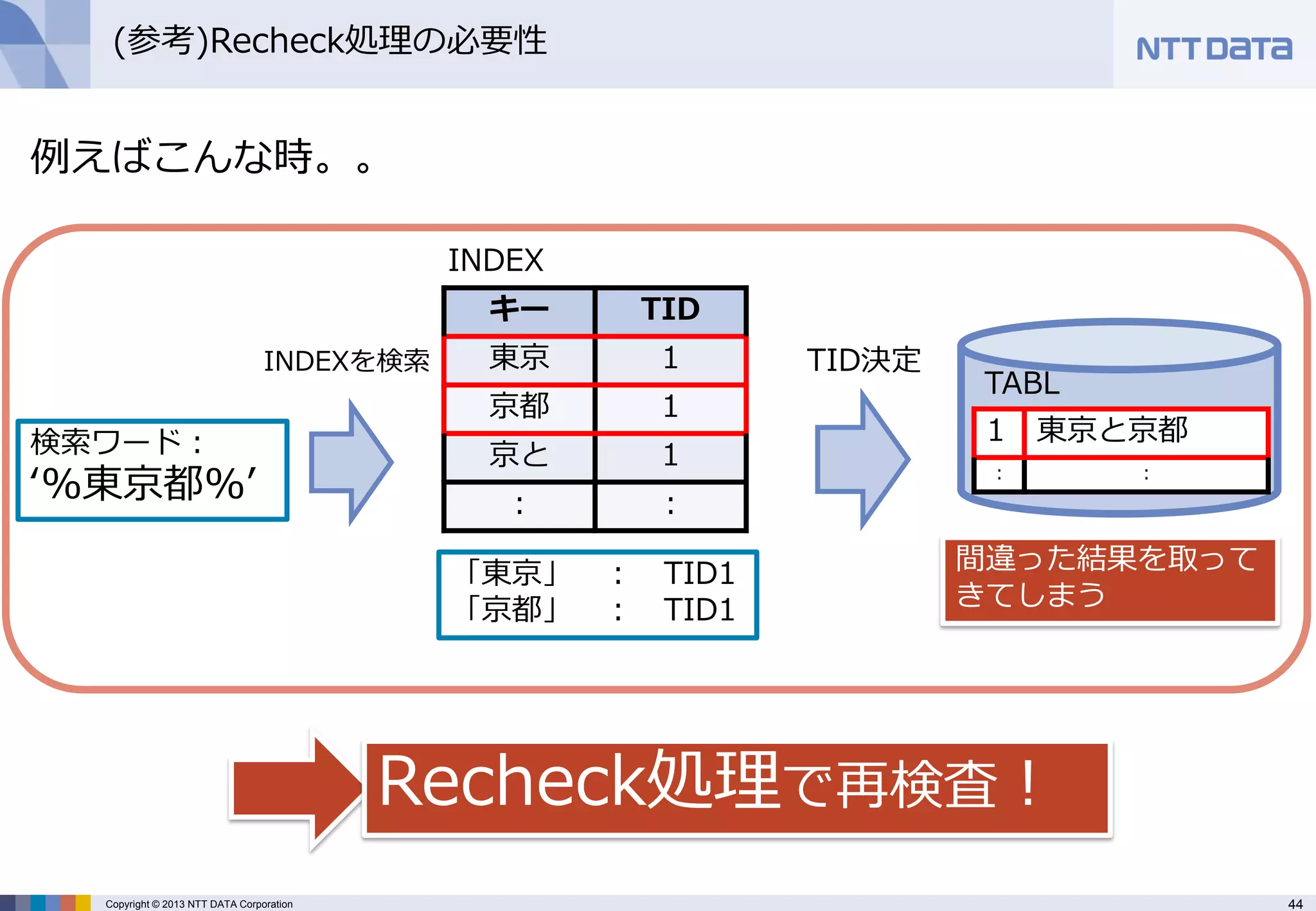
(参考)Recheck処理の必要性
キー
TID
東京
1
京都
1
京と
1
:
:
検索ワード: ‘%東京都%’
「東京」 : TID1 「京都」 : TID1
TABLE
INDEX
間違った結果を取って きてしまう
INDEXを検索
TID決定
Recheck処理で再検査!
例えばこんな時。。
1
東京と京都
:
: - 45.
45
Copyright ©2013 NTT DATA Corporation
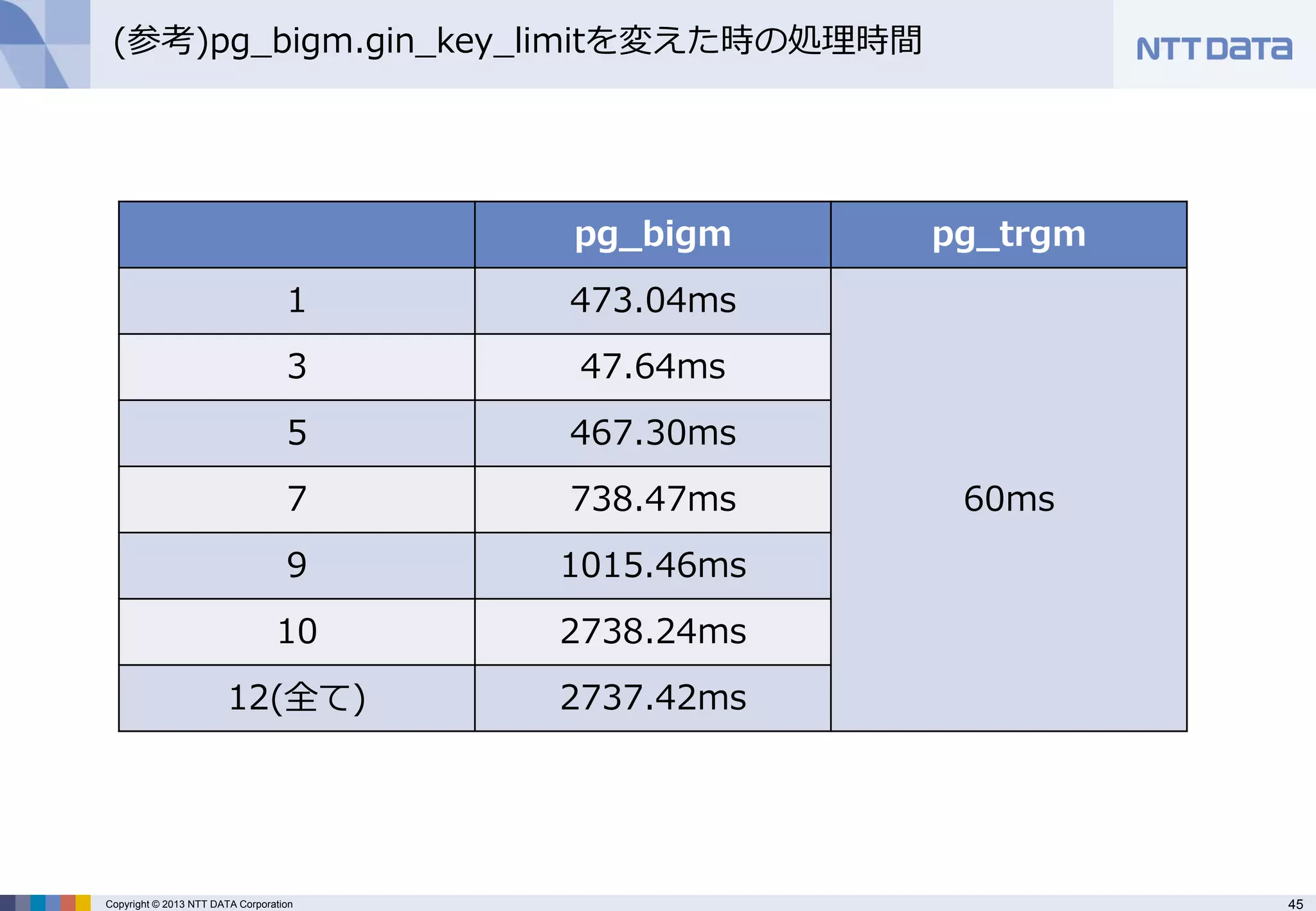
(参考)pg_bigm.gin_key_limitを変えた時の処理時間
pg_bigm
pg_trgm
1
473.04ms
60ms
3
47.64ms
5
467.30ms
7
738.47ms
9
1015.46ms
10
2738.24ms
12(全て)
2737.42ms - 46.
46
Copyright ©2013 NTT DATA Corporation
(参考)部分一致とは?
①2文字分割
「本」
②インデックススキャン
キー
TID
:
:
末尾
100, 200
本日
200, 300
本屋
500
本当
400
札束
200
:
:
③TID候補決 定
④ Recheck
キーワード
‘%本%’
2文字分割後、1文字のキーワードが生成された場合、部分一致を行う関数が実行される (例)検索キーワードが’%東%’の場合など
部分一致では1文字の検索キーワードと各キーの先頭を比較して、一致、不一致を判断す る
pg_bigmでは部分一致関数を実装しているため、2文字”以下”の検索ができる