Downloaded 165 times









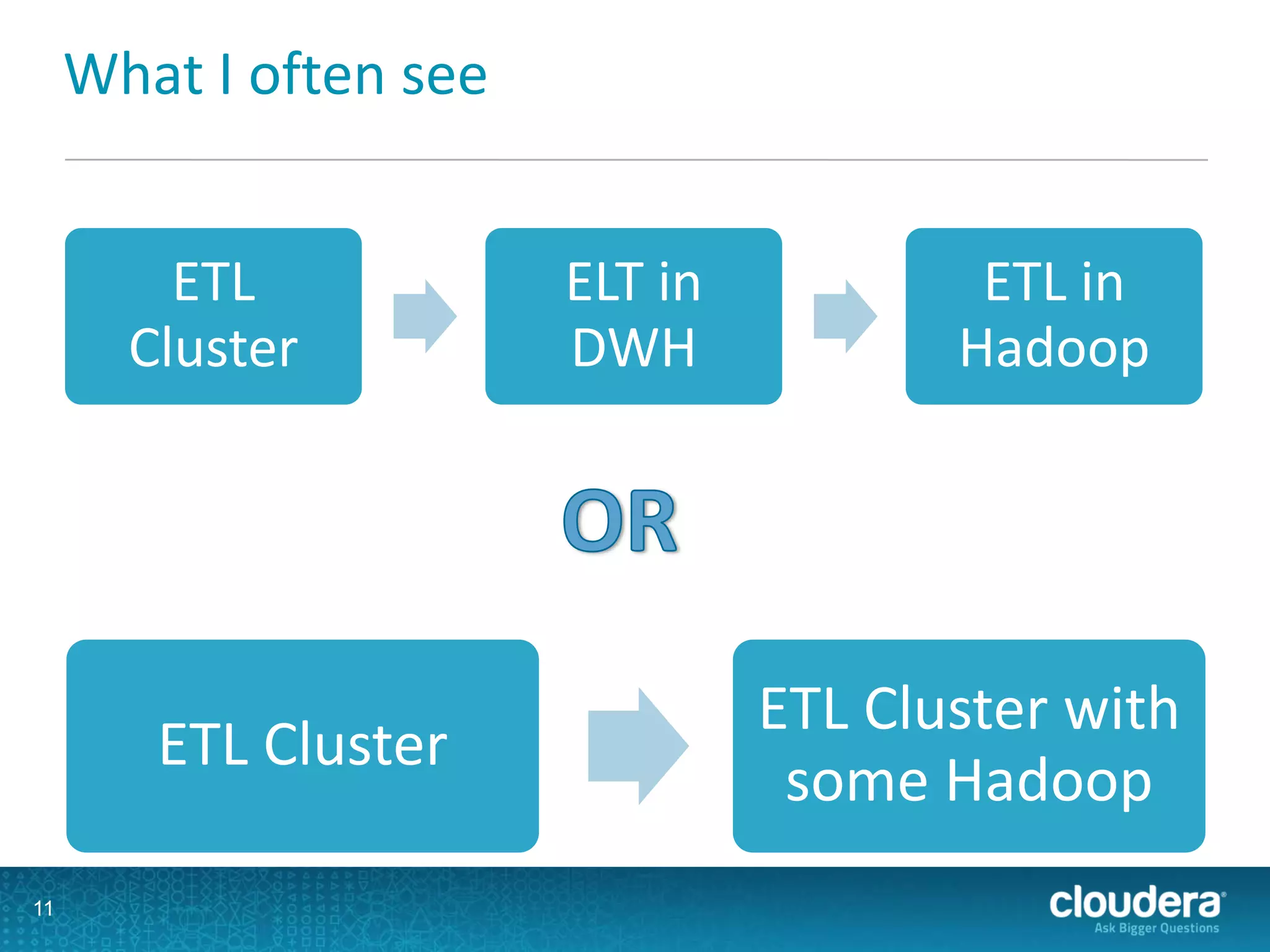
































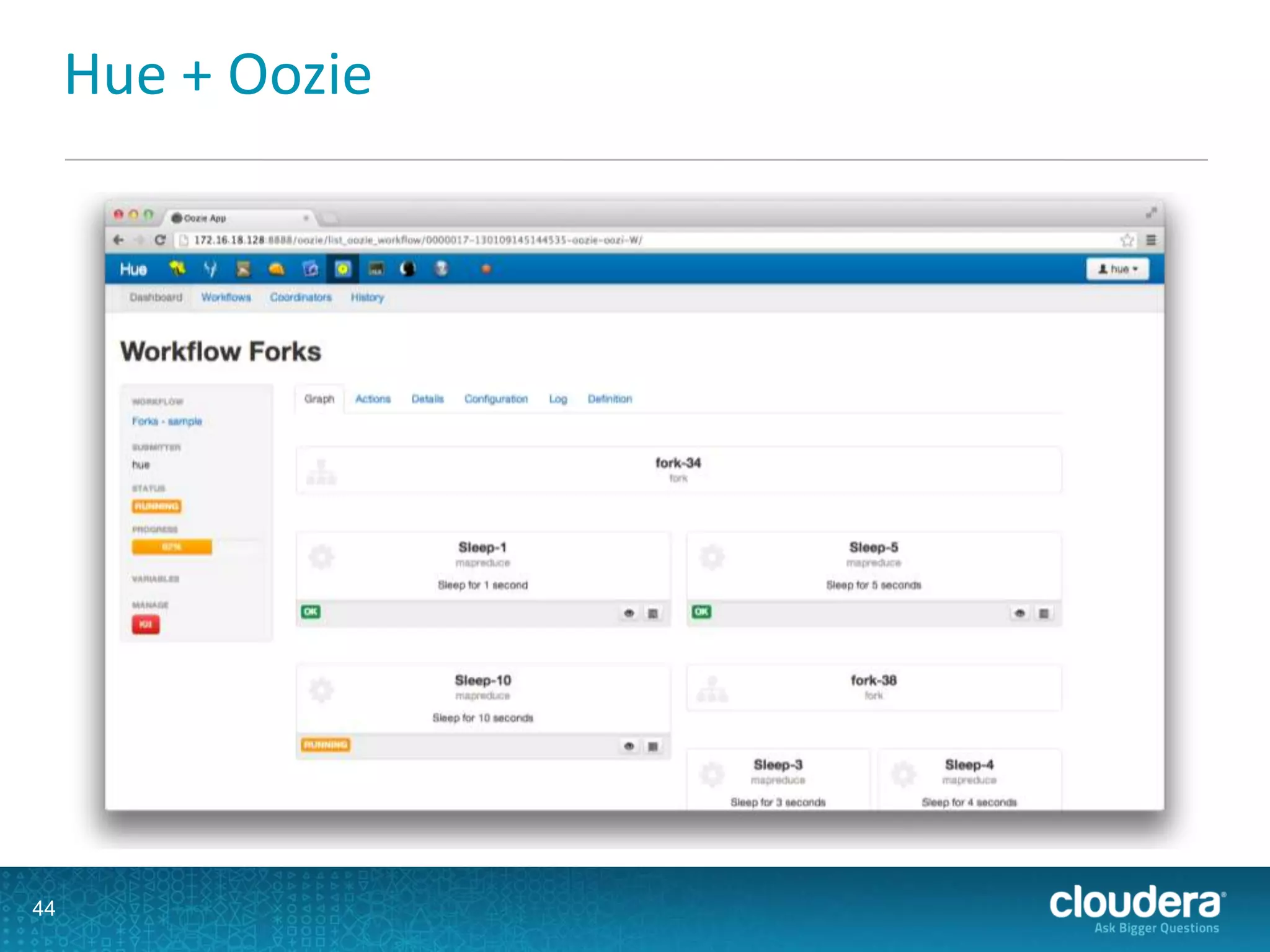




This document discusses scaling ETL processes with Hadoop. It describes using Hadoop for extracting data from various structured and unstructured sources, transforming data using MapReduce and other tools, and loading data into data warehouses or other targets. Specific techniques covered include using Sqoop and Flume for extraction, partitioning and tuning data structures for transformation, and loading data in parallel for scaling. Workflow management with Oozie and monitoring with Cloudera Manager are also discussed.













![[Pulsar summit na 21] Change Data Capture To Data Lakes Using Apache Pulsar/Hudi](https://cdn.slidesharecdn.com/ss_thumbnails/pulsarsummitna21cdcusinghudipulsardeck-210628151056-thumbnail.jpg?width=640&height=640&fit=bounds)





















































































