Downloaded 72 times






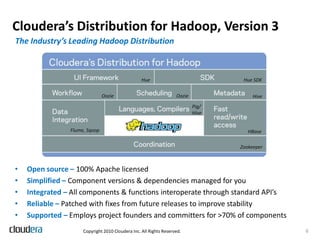

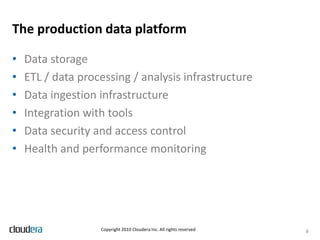











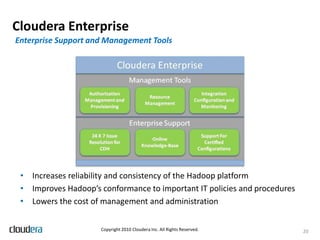



This document discusses lessons learned from productionizing Hadoop clusters. It emphasizes the importance of proper planning, data ingestion infrastructure, ETL processing tools, authentication and authorization, monitoring, and filling gaps not addressed by the Hadoop core software. The document provides best practices and considerations for setting up a complete and enterprise-ready Hadoop system.























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)