Downloaded 366 times



























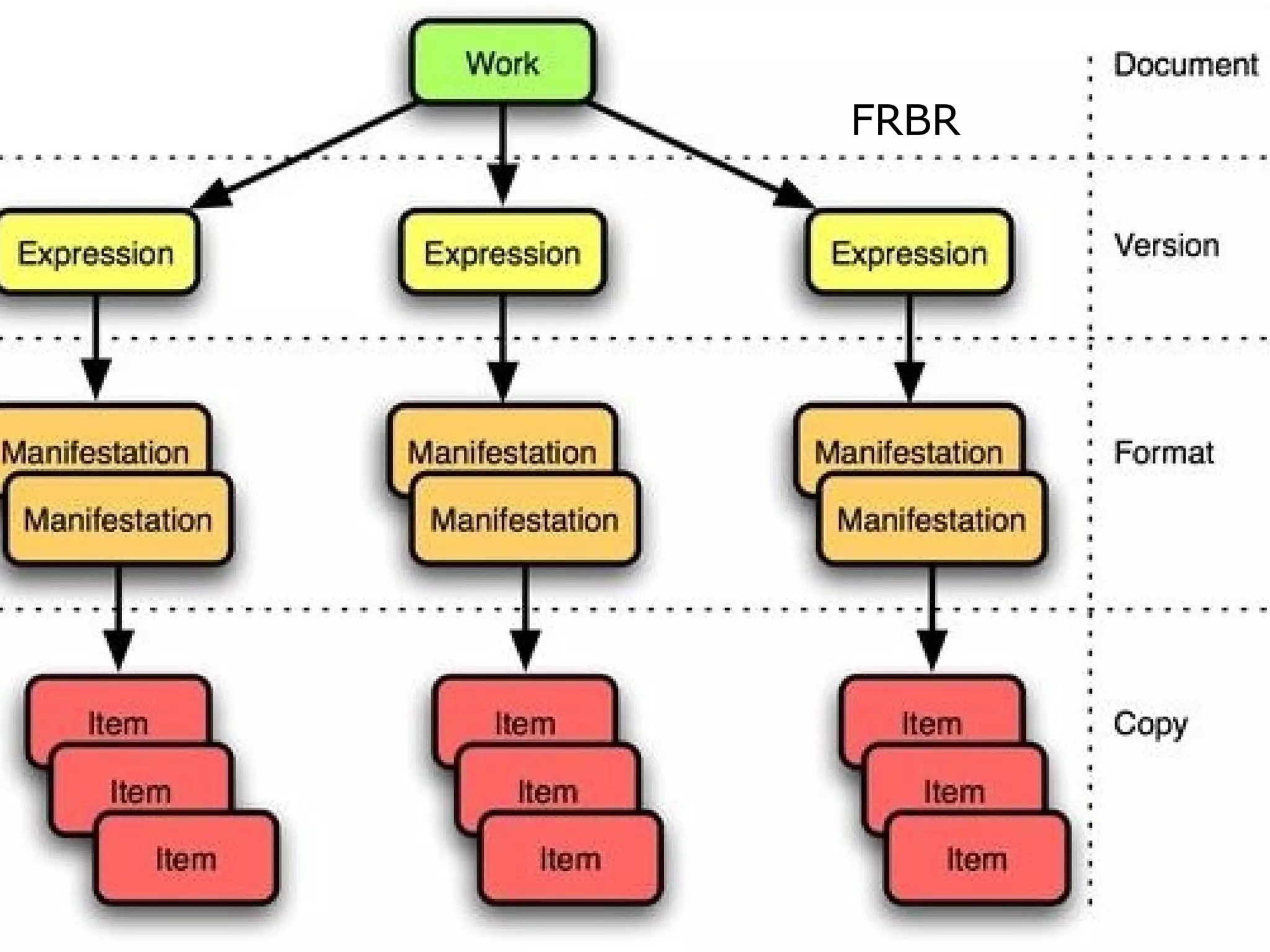




































































































The document discusses the history and importance of metadata. It describes how metadata standards have evolved over time, from MARC for library catalogs to Dublin Core for web pages to RDF for the semantic web. It also discusses how metadata is now commonly used for repositories of research publications and data to help discover and manage institutional assets. While search engines ignore most embedded metadata, standards and policies around metadata have still spread widely across domains like education, libraries, and cultural heritage.











































































































