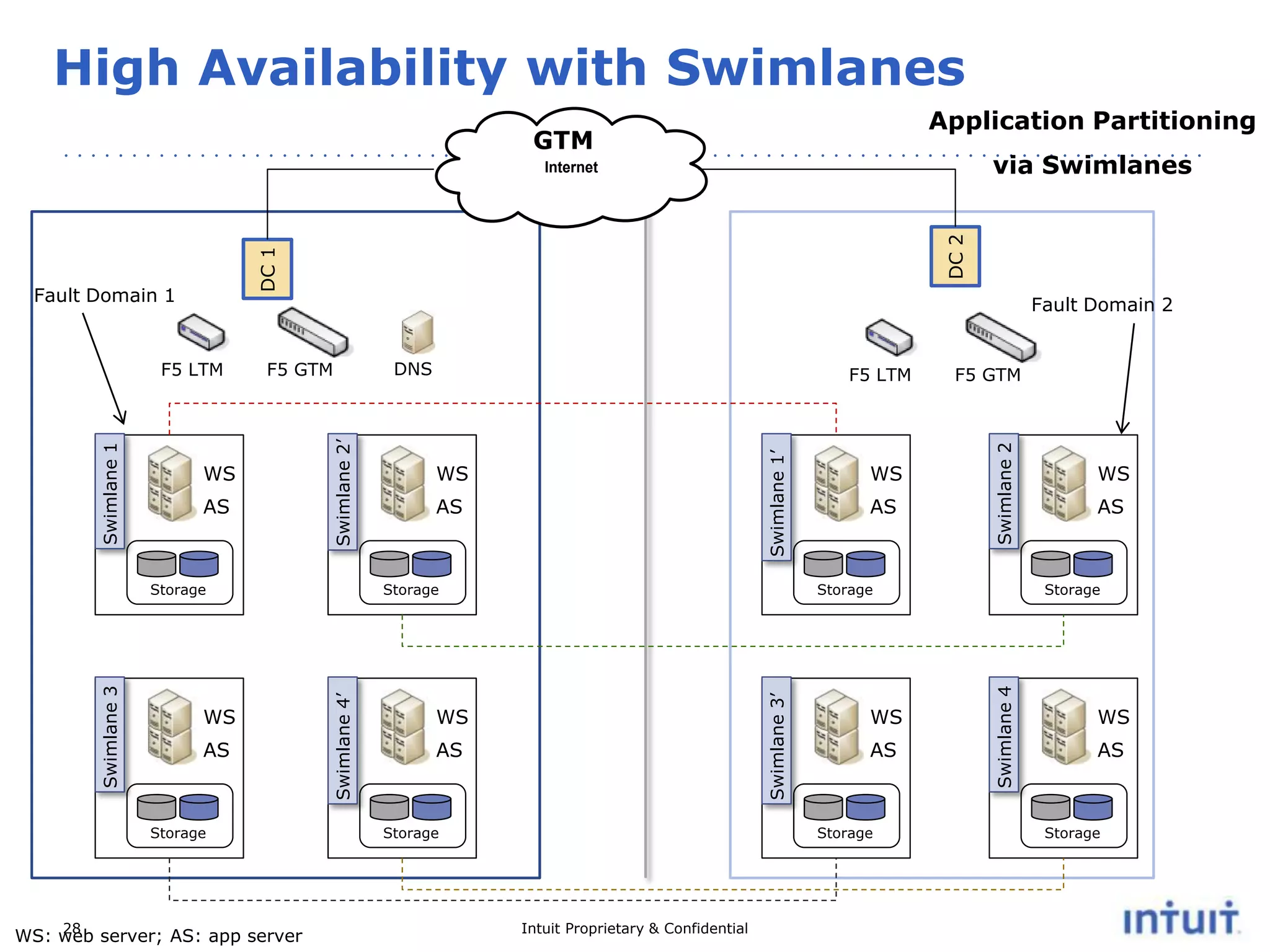
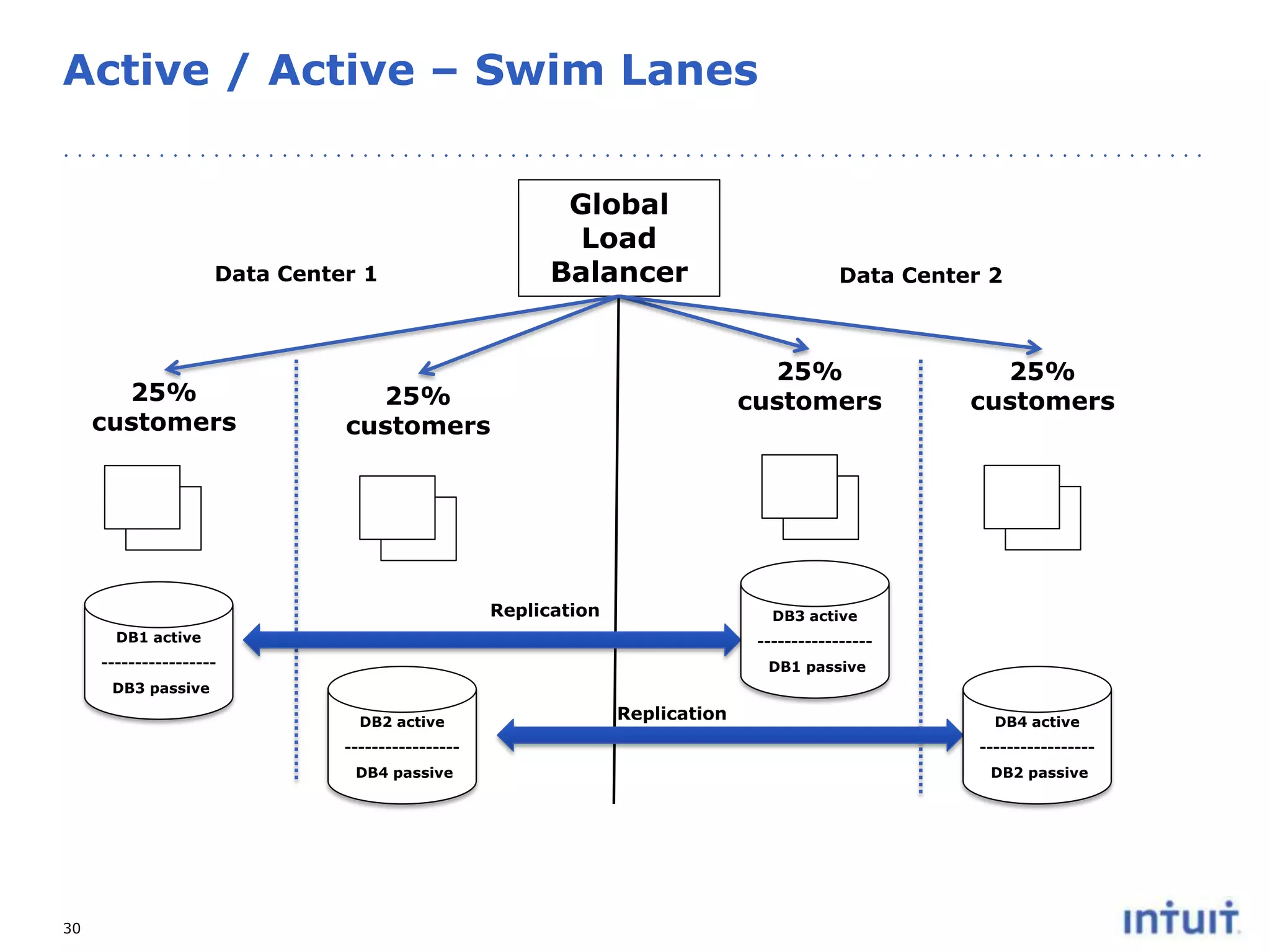
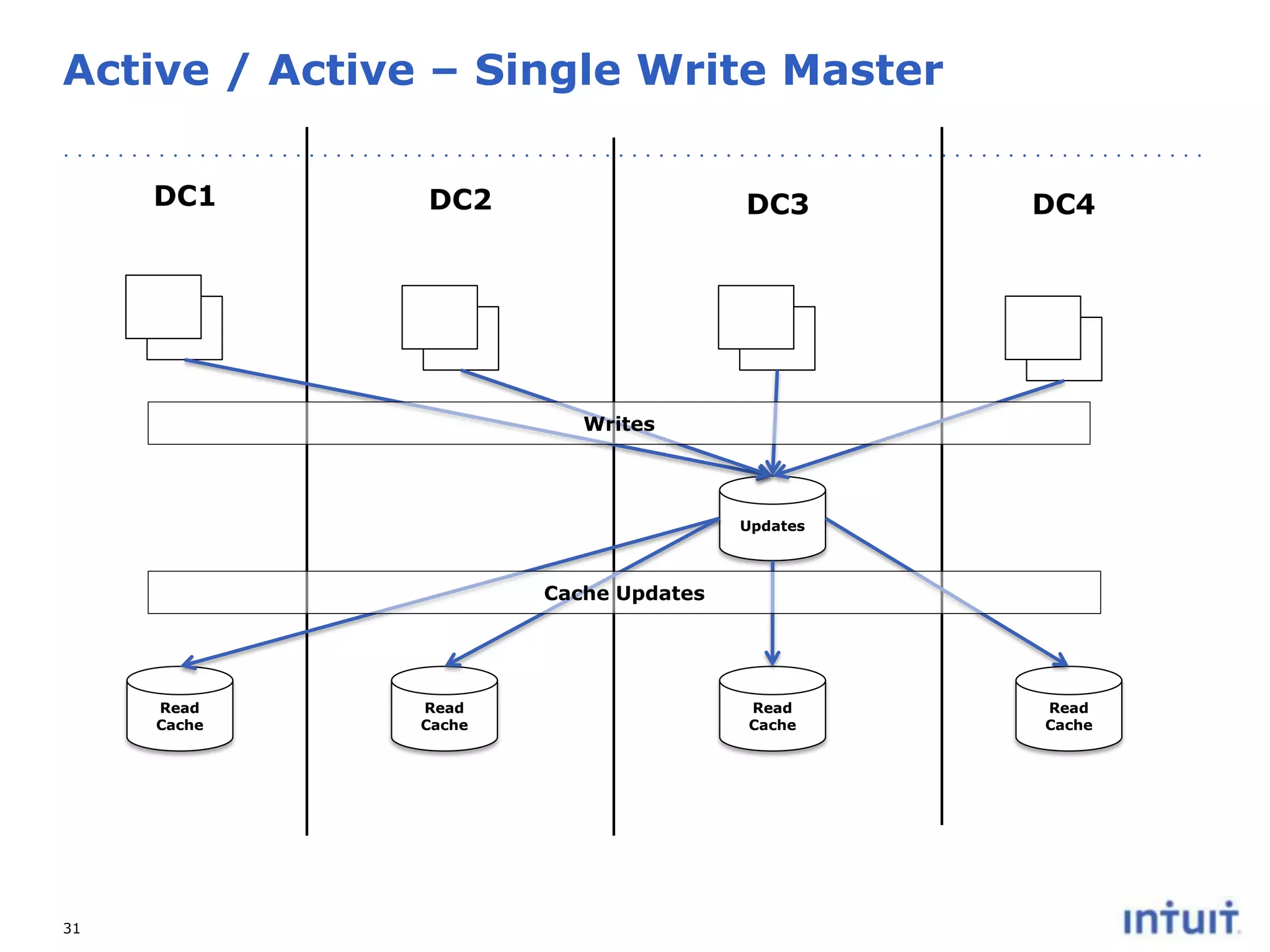
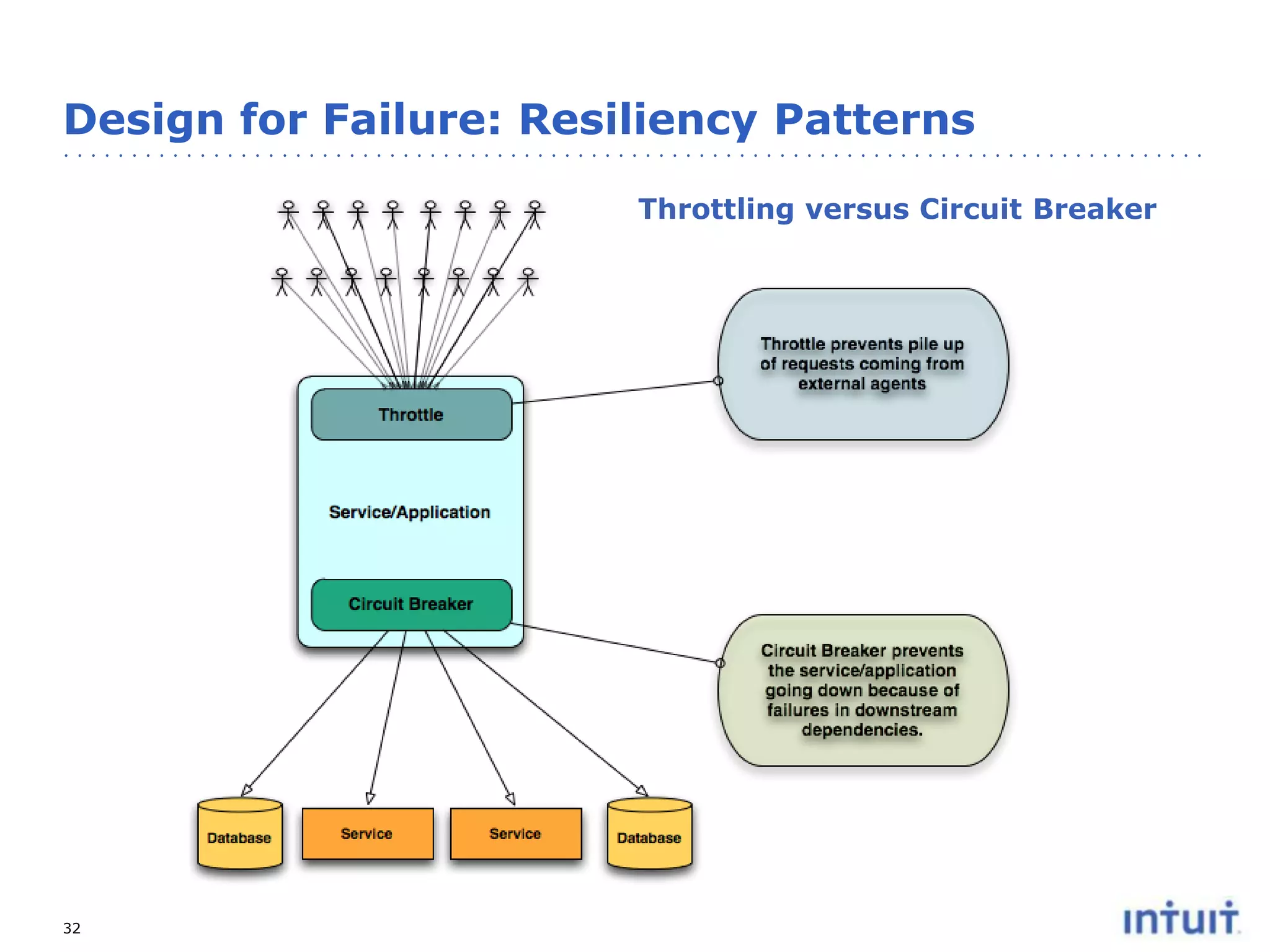
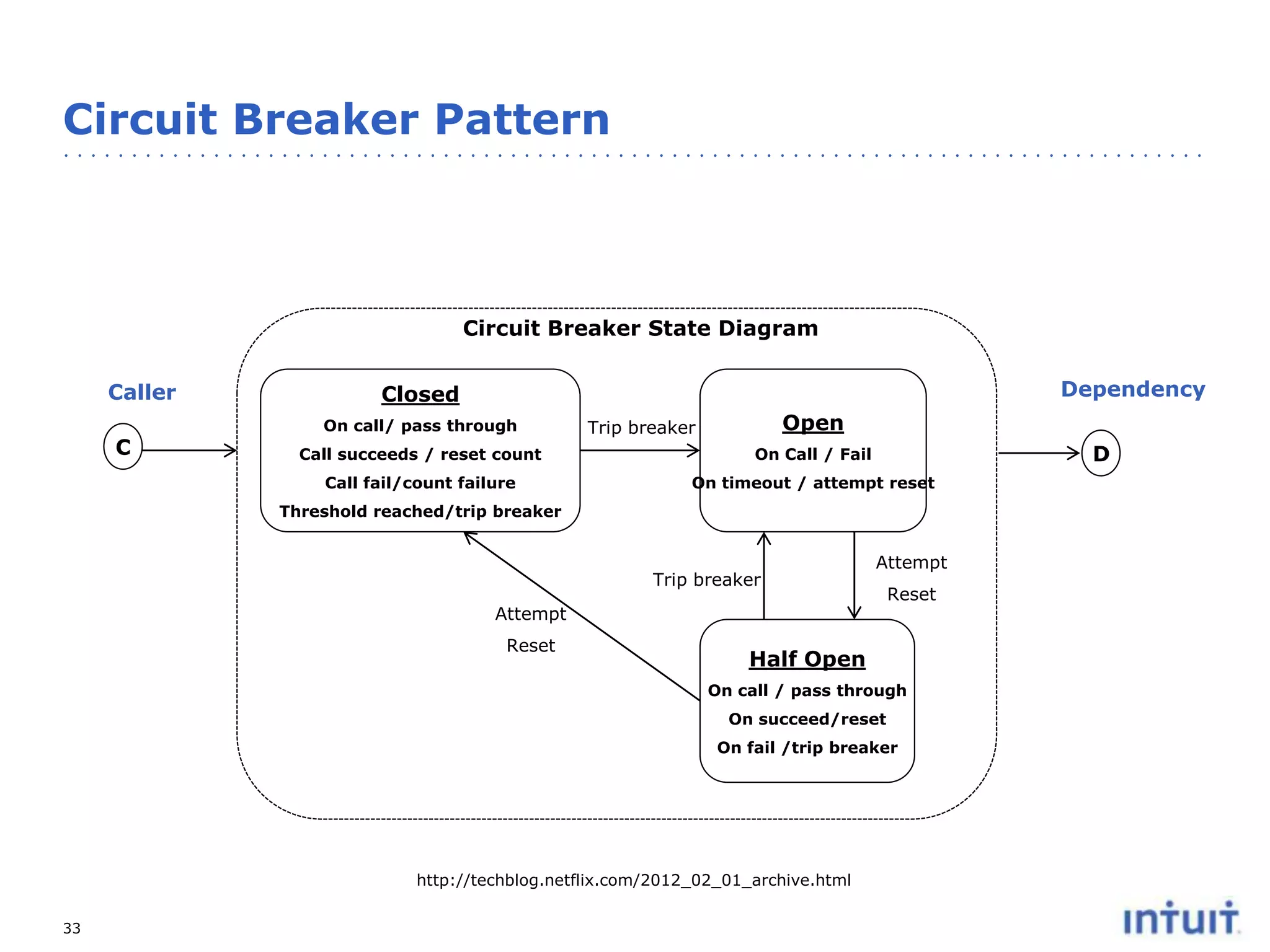
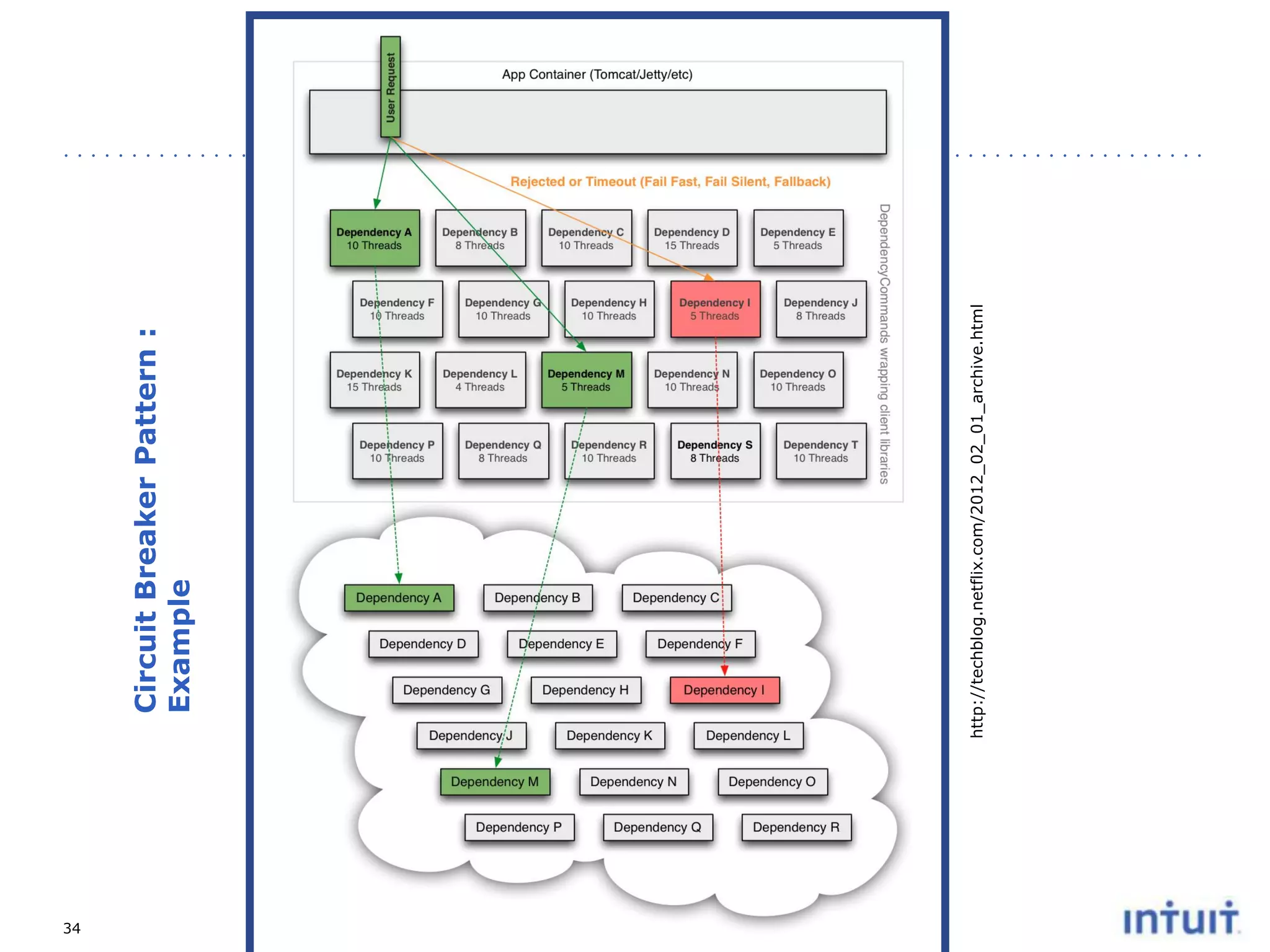
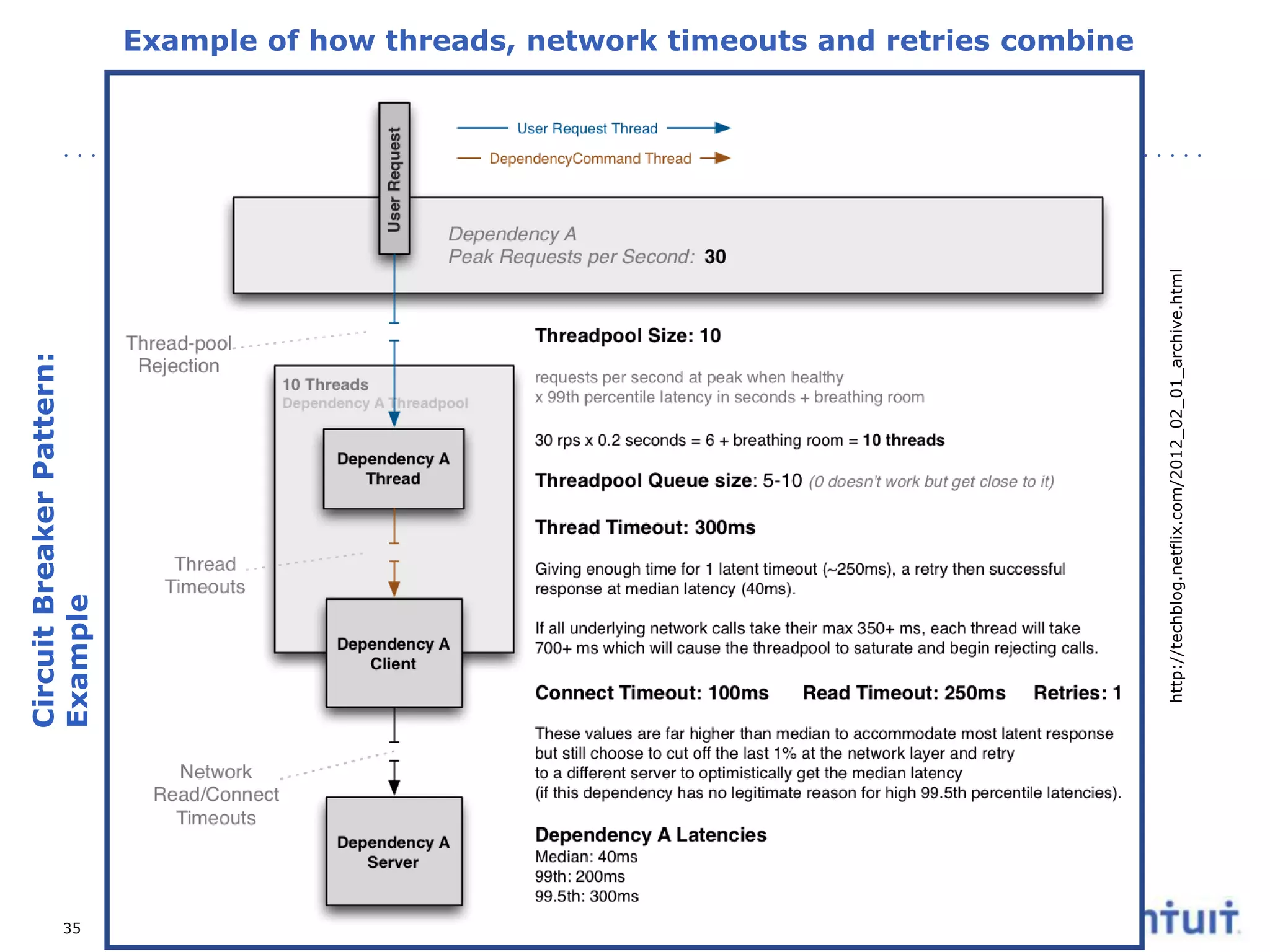
The document discusses the operation of highly available cloud services, emphasizing the importance of anticipating failure and designing for high availability. It outlines key strategies, processes, and technologies involved in ensuring service reliability, including monitoring business metrics, incident management, and architectural principles like fault isolation. Additionally, it covers the implementation of various patterns and tools to support scalability and disaster recovery in cloud environments.







































































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)





