










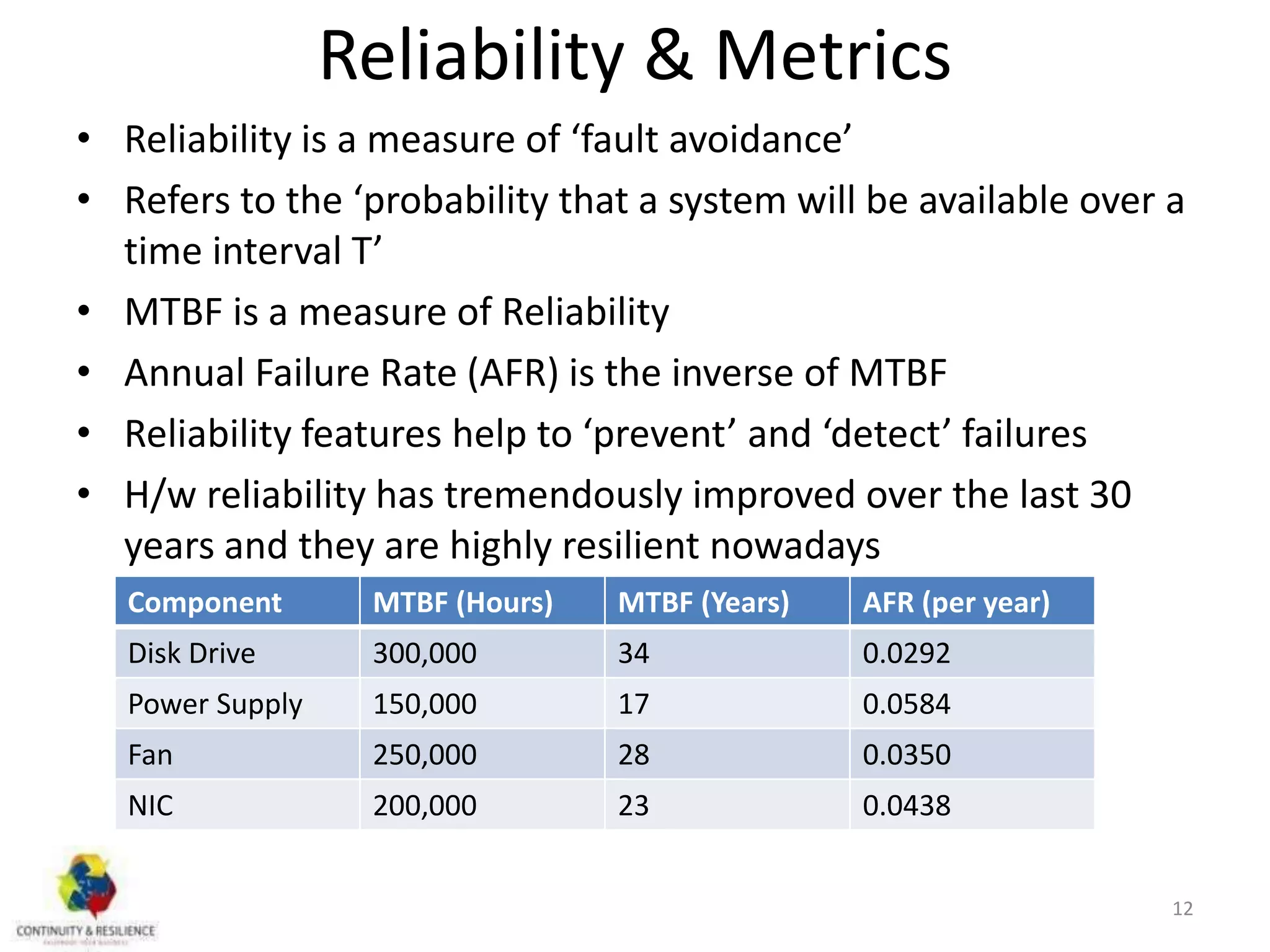


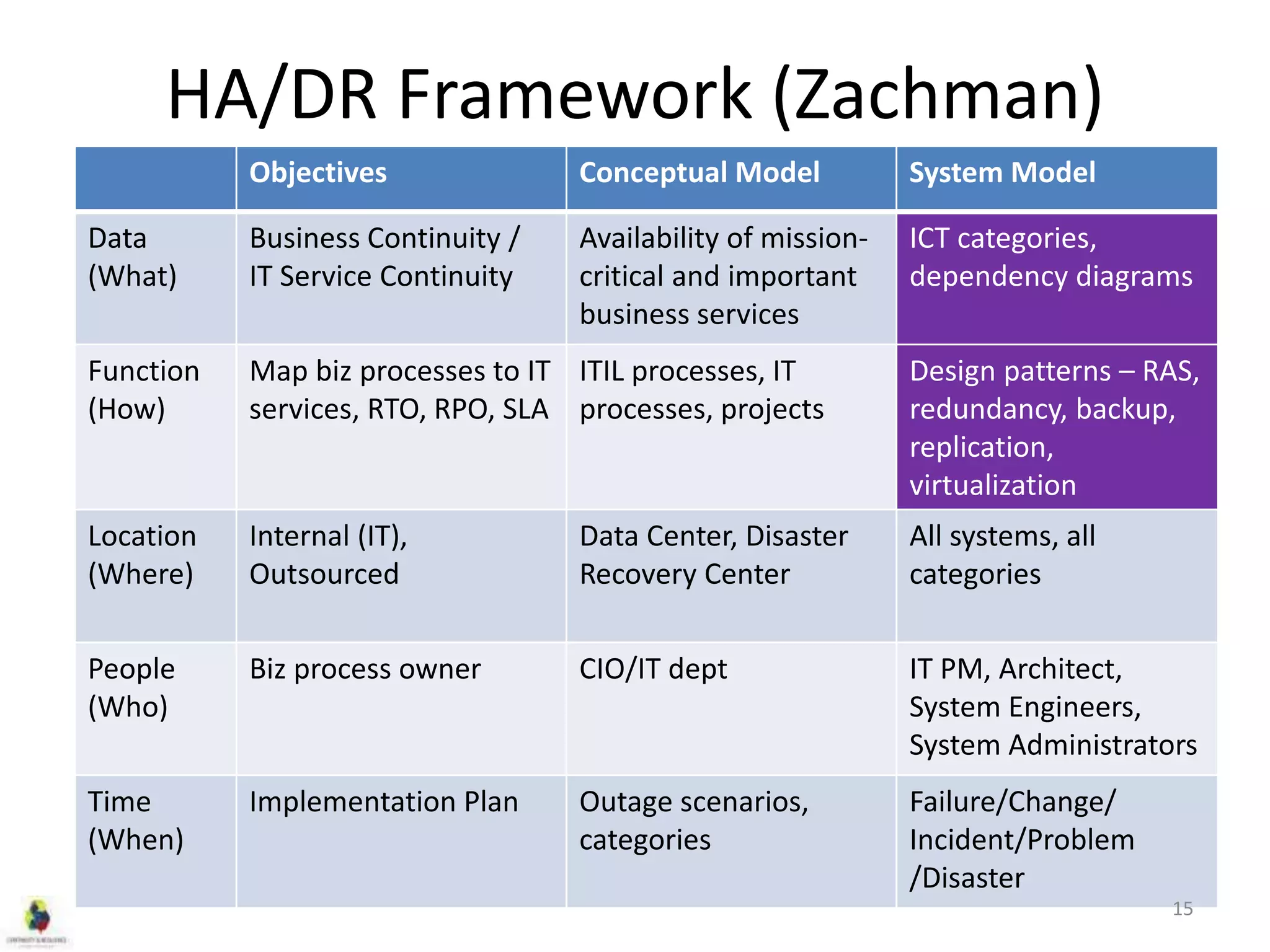




















This document discusses concepts related to high availability and disaster recovery. It defines key terms like availability, reliability, outages, fault tolerance, and redundancy. It describes strategies for high availability including data replication, virtualization, host clustering, and ensuring reliability of network and middleware components. The document emphasizes the importance of basing HA/DR strategies and investments on business needs and conducting proper scoping and planning.






































![Drp International Brochure Version 5.5[1]](https://cdn.slidesharecdn.com/ss_thumbnails/DRPInternationalBrochureversion551-123319755553-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





























































