Download as KEY, PPTX









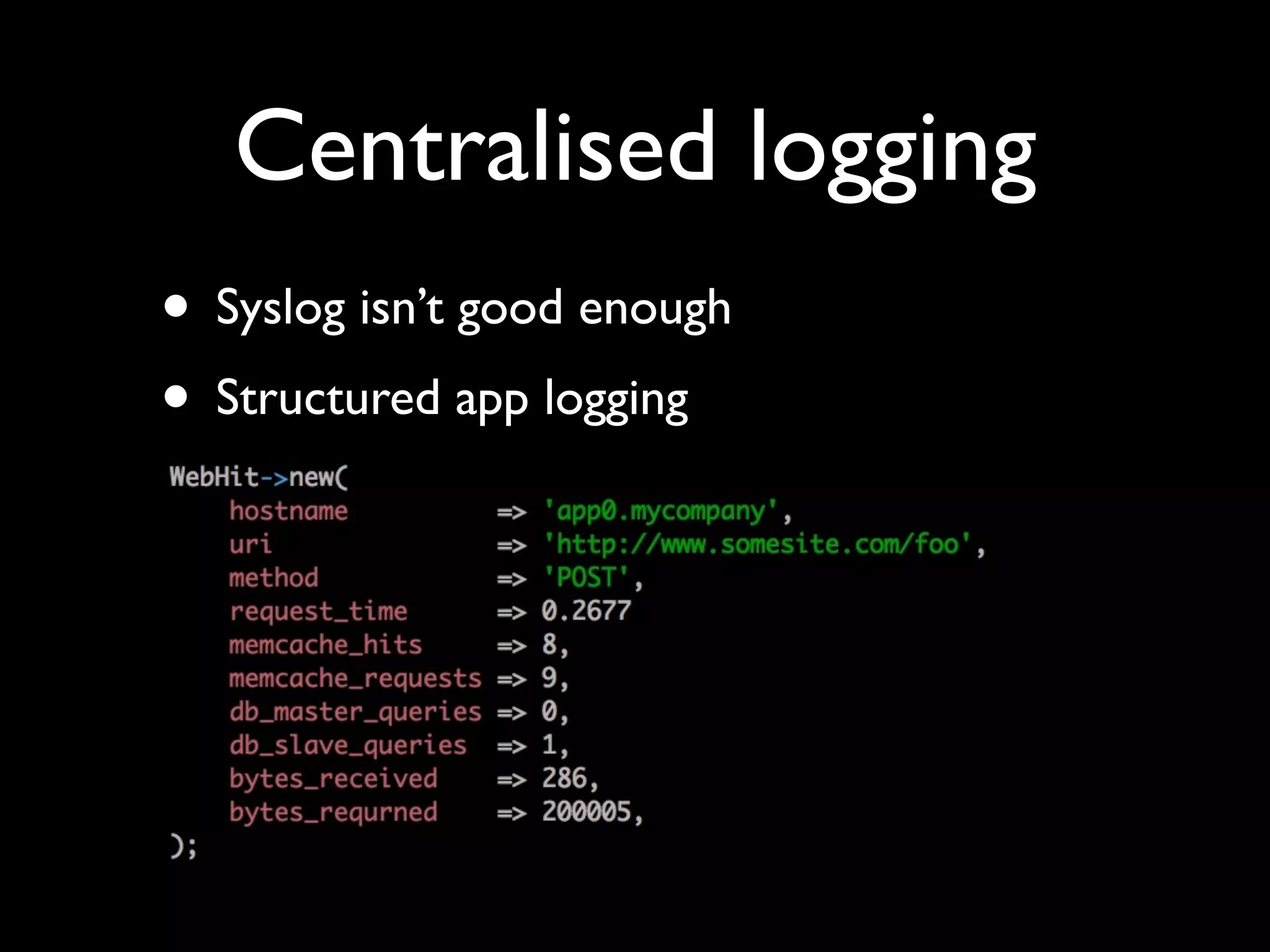






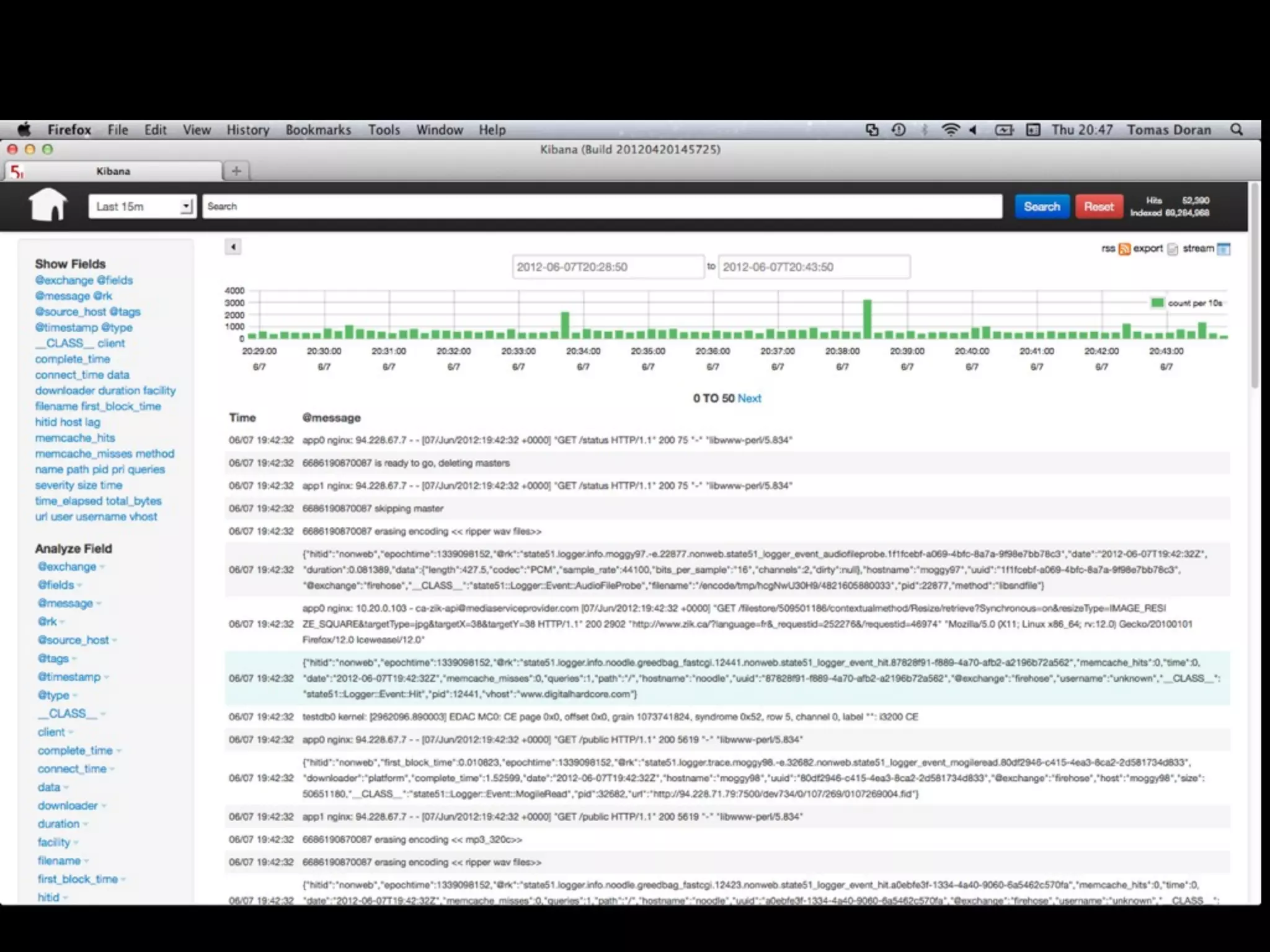
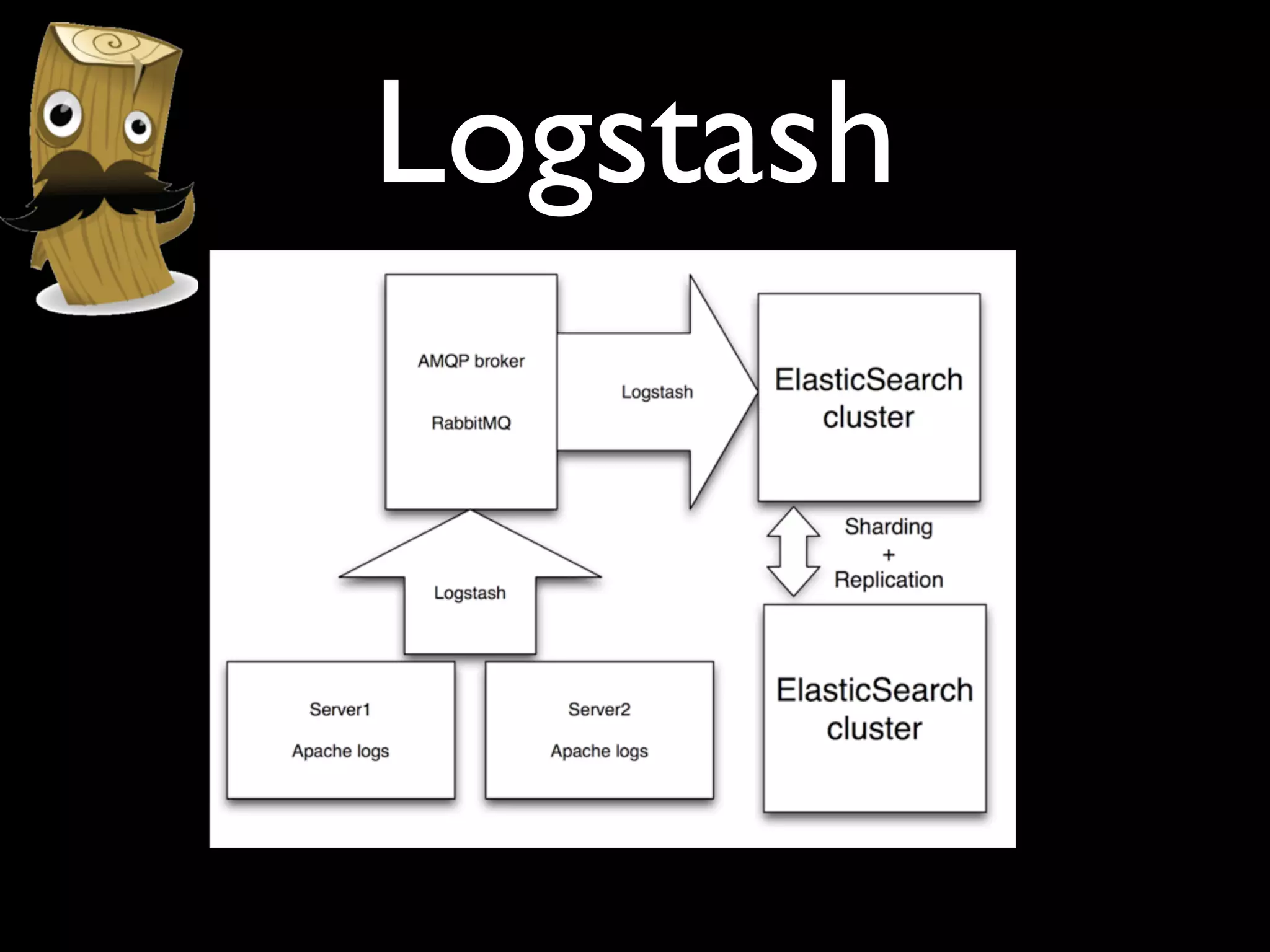


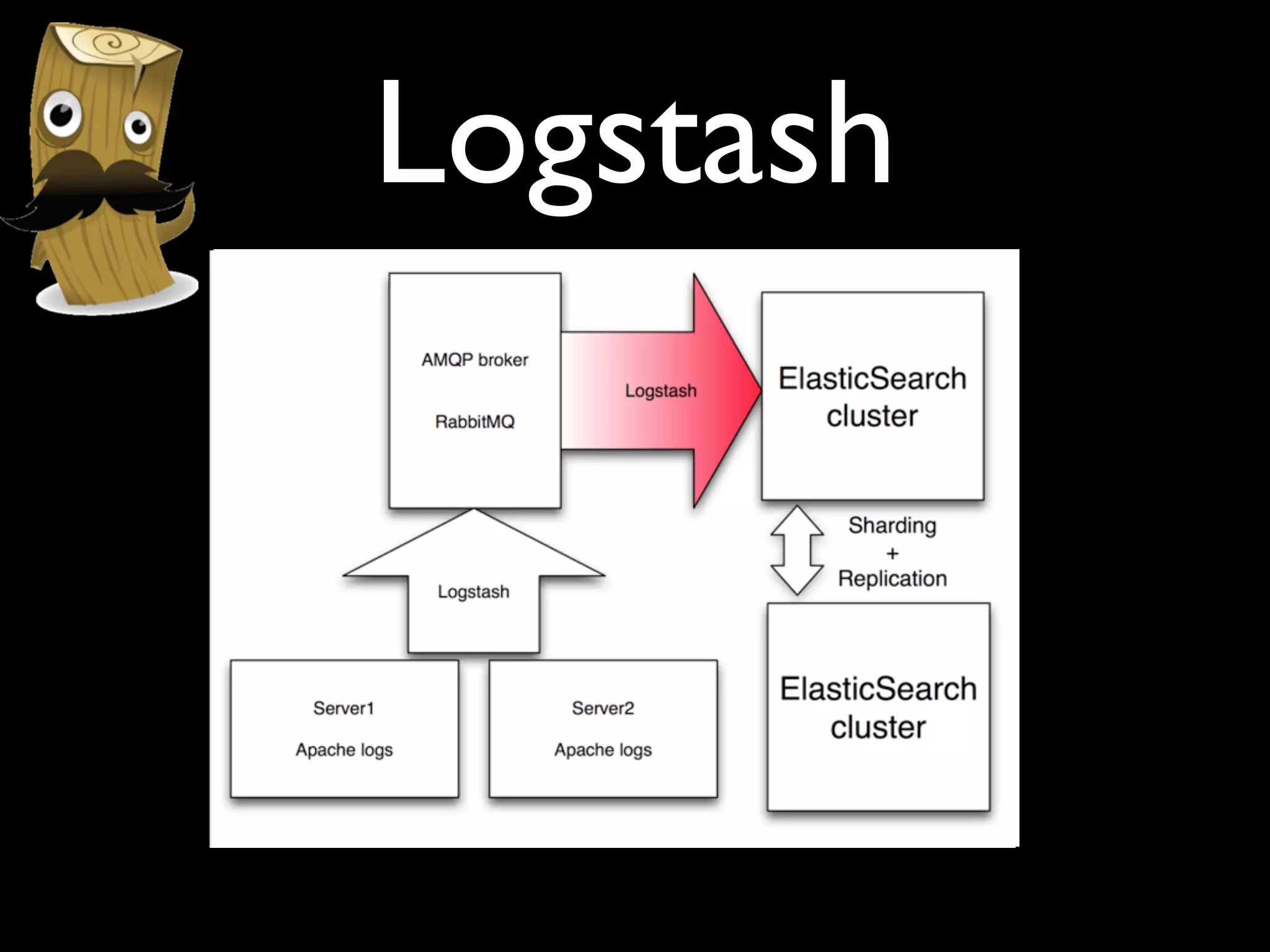
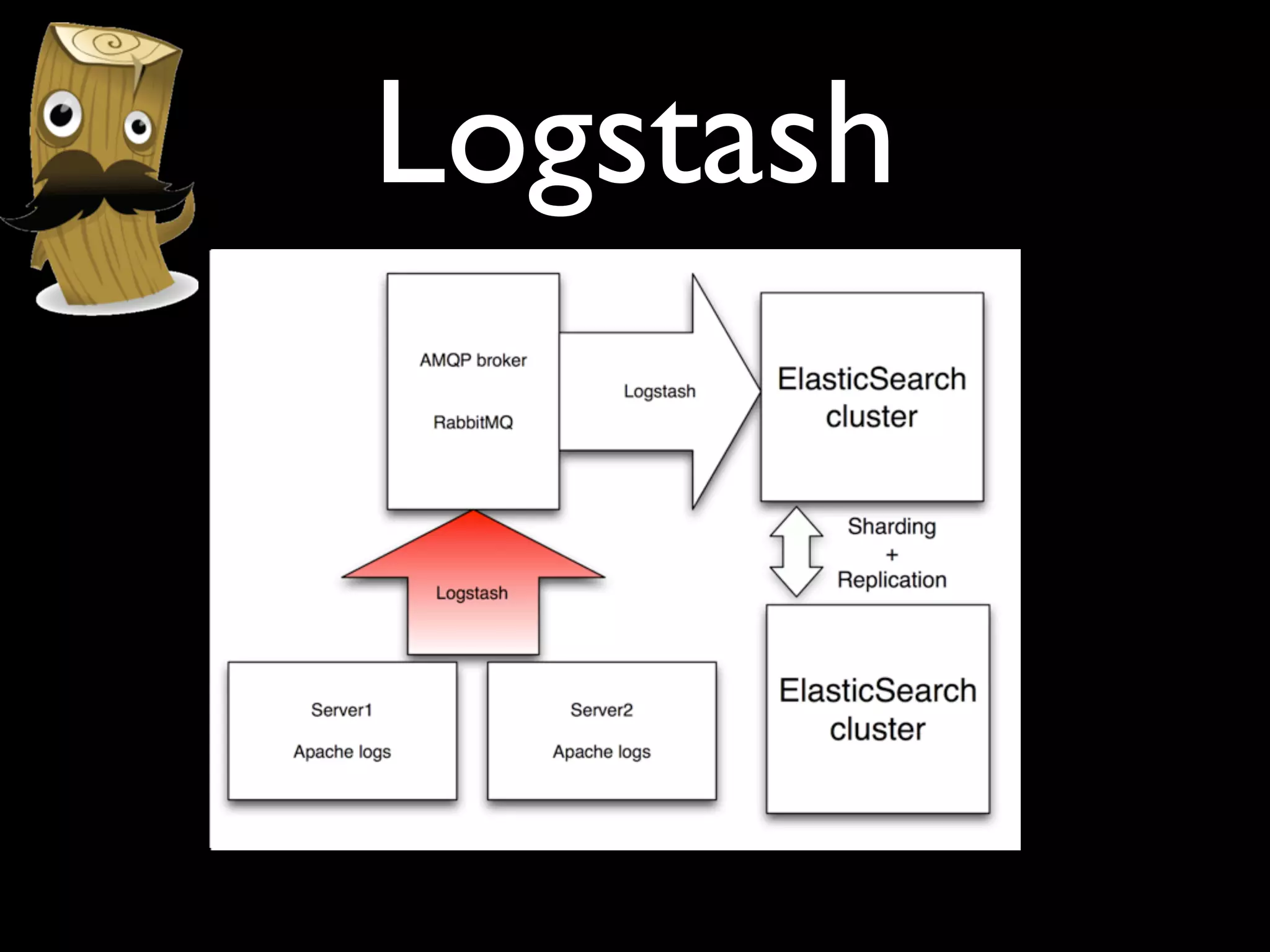












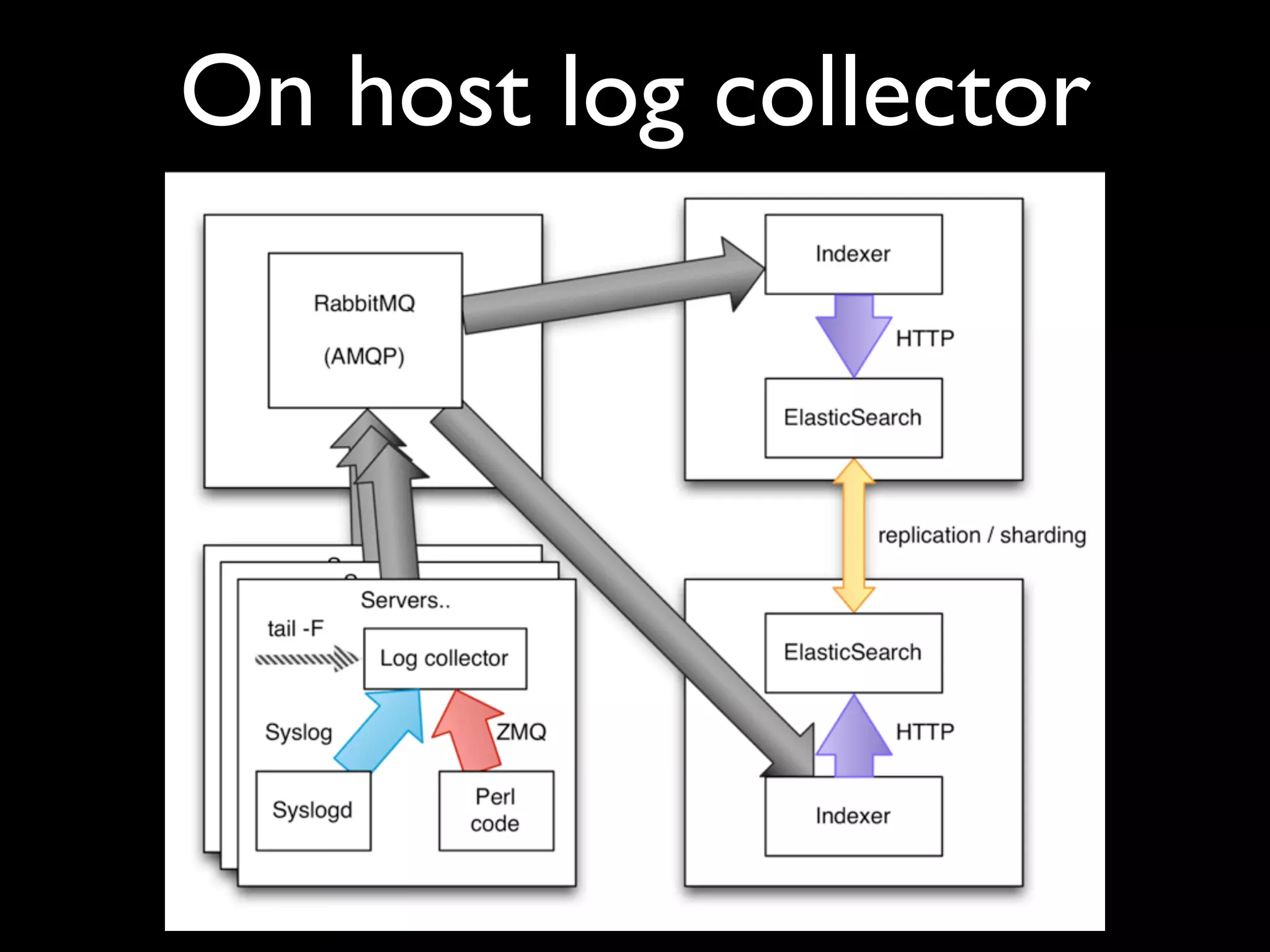



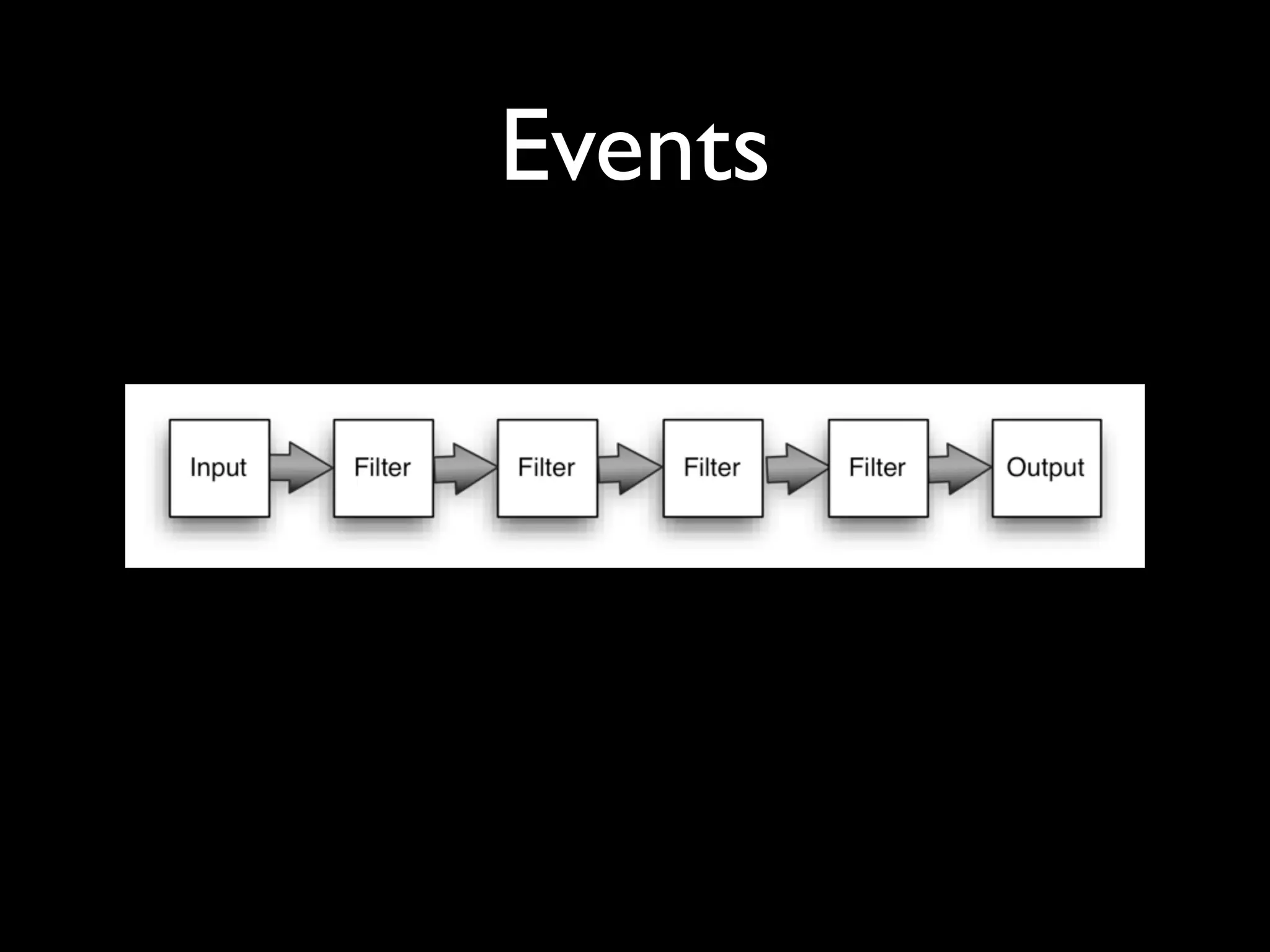




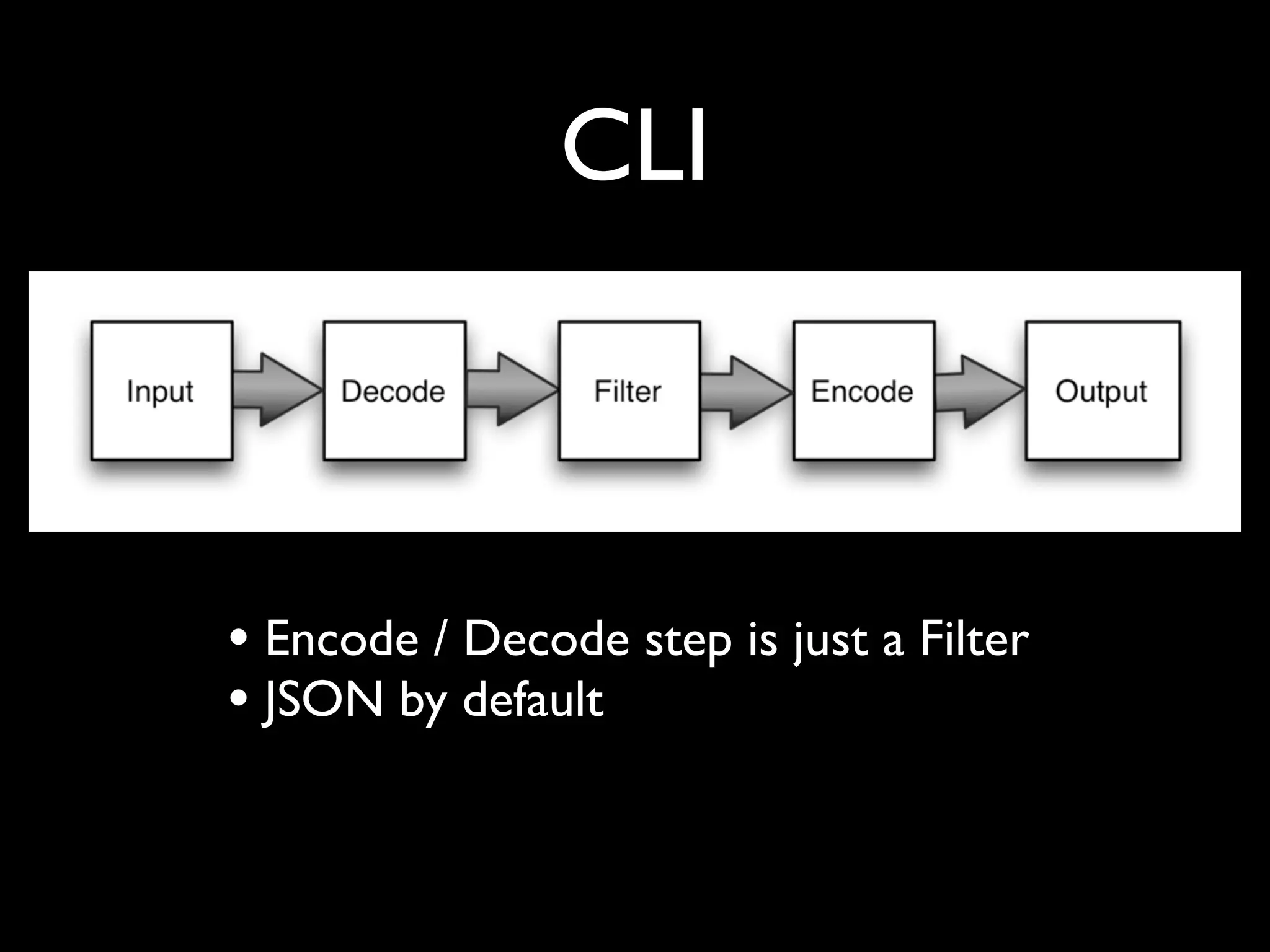





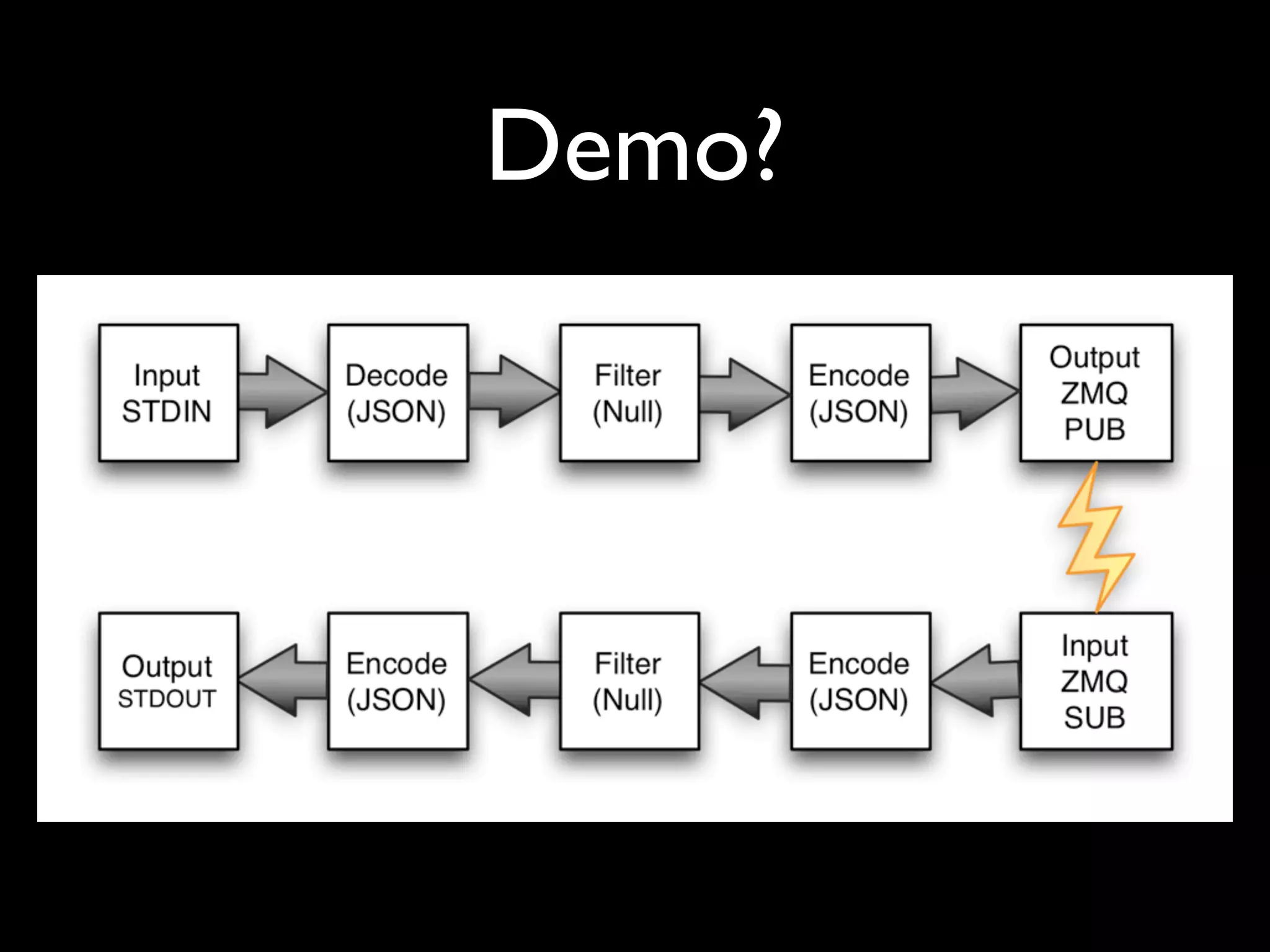












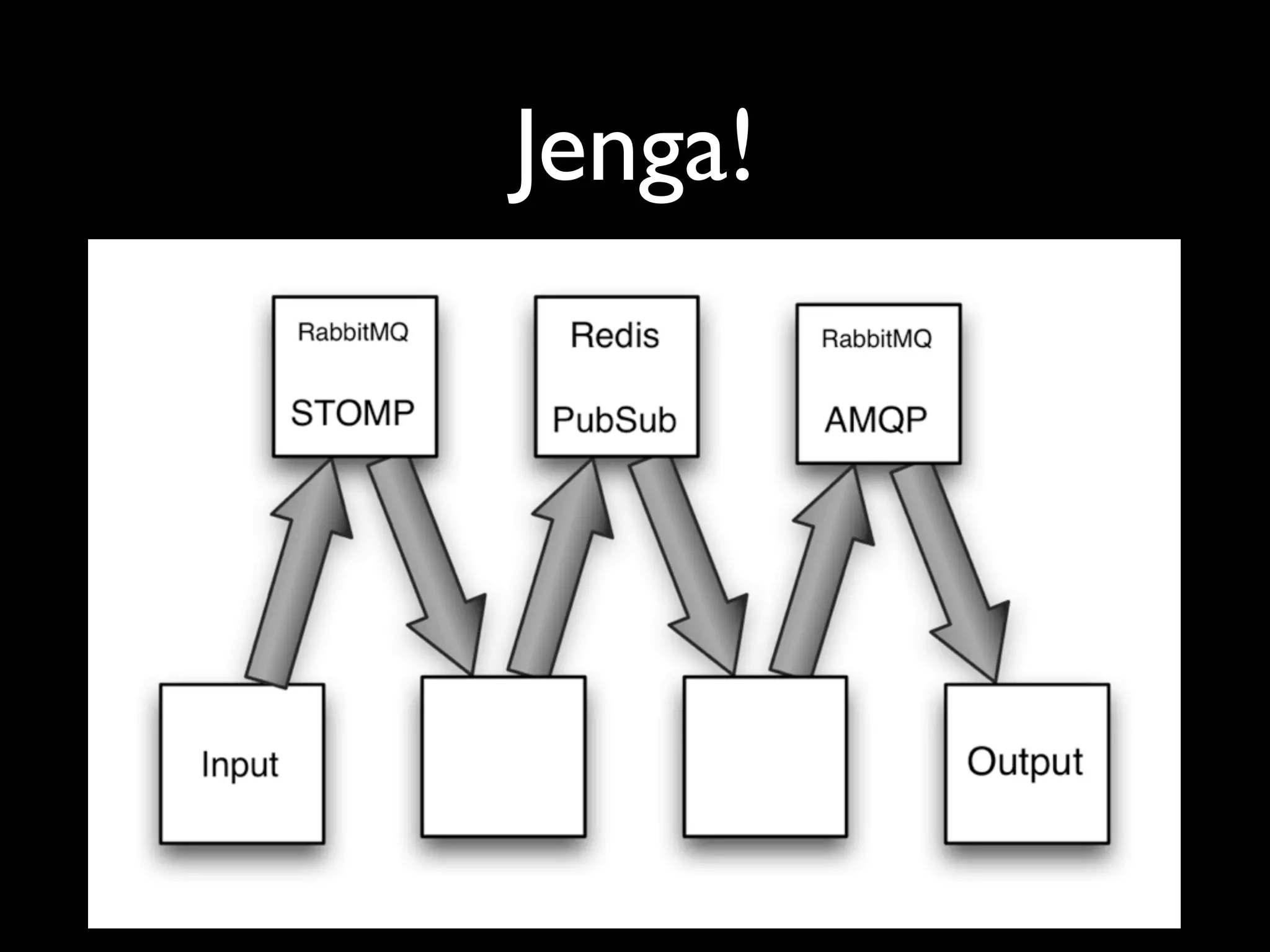


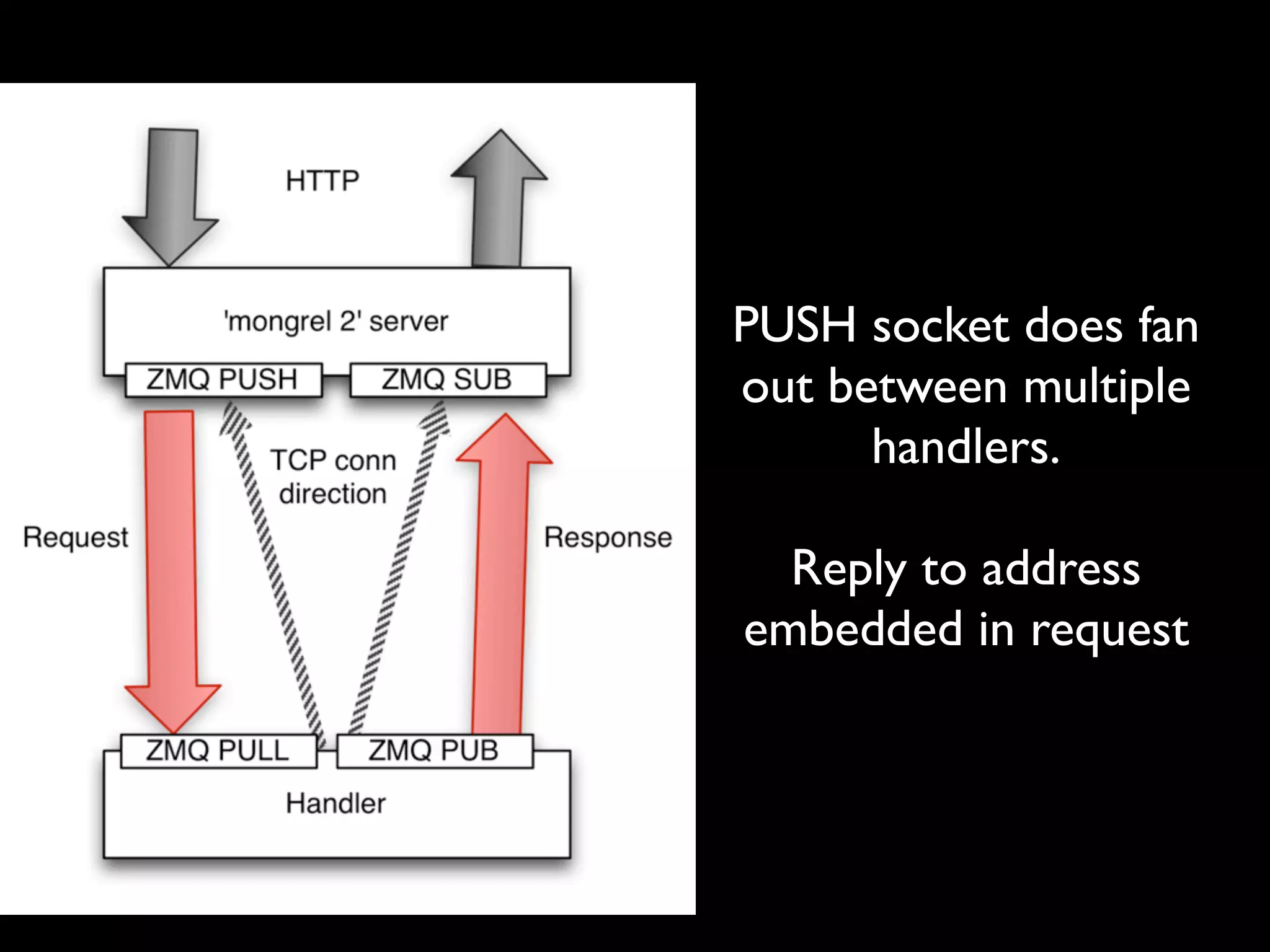


The document discusses a new Perl library, message::passing, designed to improve logging and messaging interoperability. It highlights the insufficiencies of traditional logging methods like syslog and logstash while proposing a simplified solution utilizing structured app logging and ZeroMQ for efficient message passing. The framework also supports various messaging patterns and is validated through production use by other developers.








































![[52nd KUG PP] Intro KUG](https://cdn.slidesharecdn.com/ss_thumbnails/introkug-100117080401-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


































































