Downloaded 18 times

















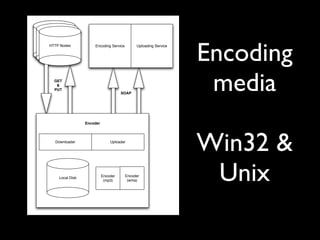







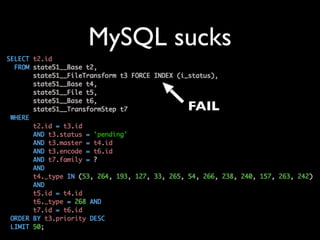
























This talk provides an overview of the large platform architecture used at State51 to deliver independent music and media content. It discusses using technologies like Varnish, Nginx, MogileFS, and Memcached to serve content efficiently from cheap hardware. Jobs and queues are used to process workflows like encoding files. The architecture is designed to be redundant and handle failures across the web, application, storage, and processing layers. Logging and monitoring are important for debugging in these complex systems.















































