Download as KEY, PPTX

















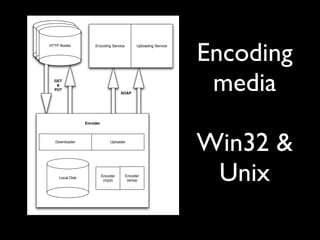







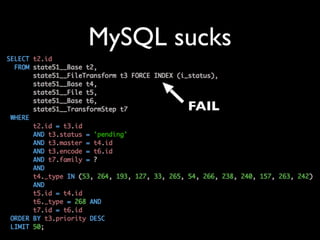
























This talk provides an overview of the large platform architecture used at State51 to deliver independent music and media content. It discusses using technologies like Varnish, Nginx, MogileFS, and Memcached to serve content efficiently from cheap hardware. It also describes using a job-based system with RabbitMQ to process workflows asynchronously instead of within web requests. The talk emphasizes designing for reliability through redundancy, monitoring with Splunk, and avoiding mutable states and relational database issues.


































































