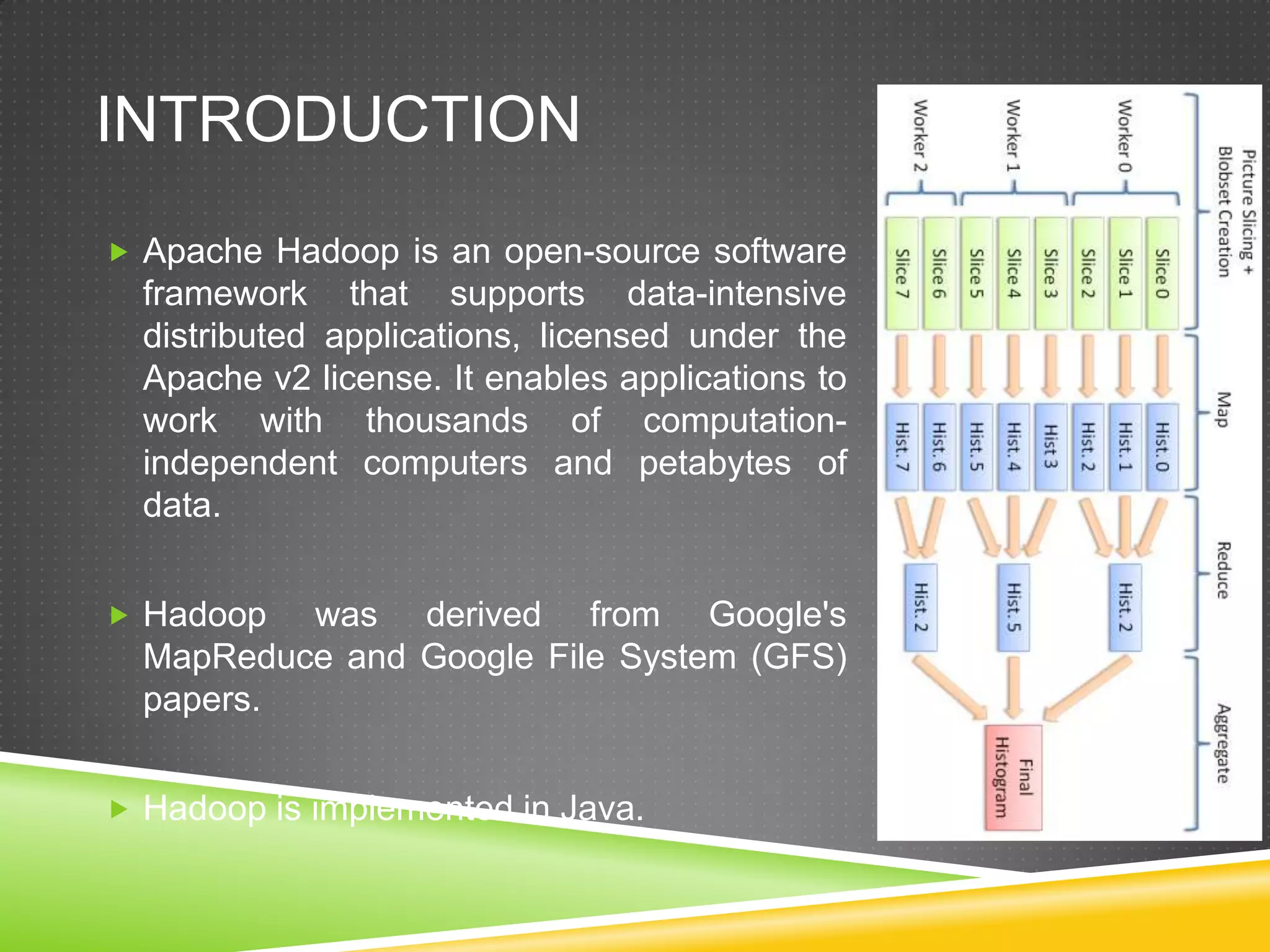
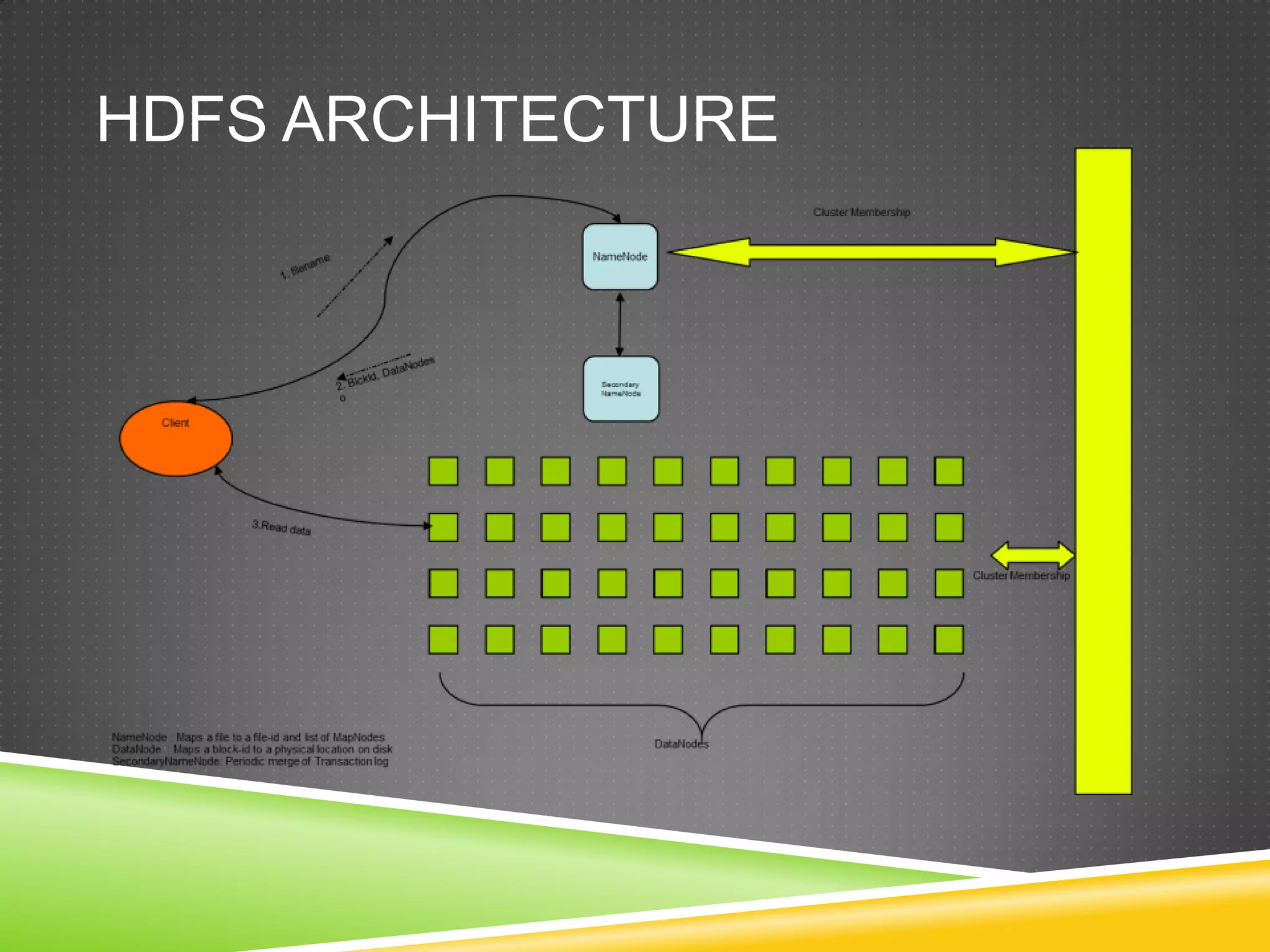
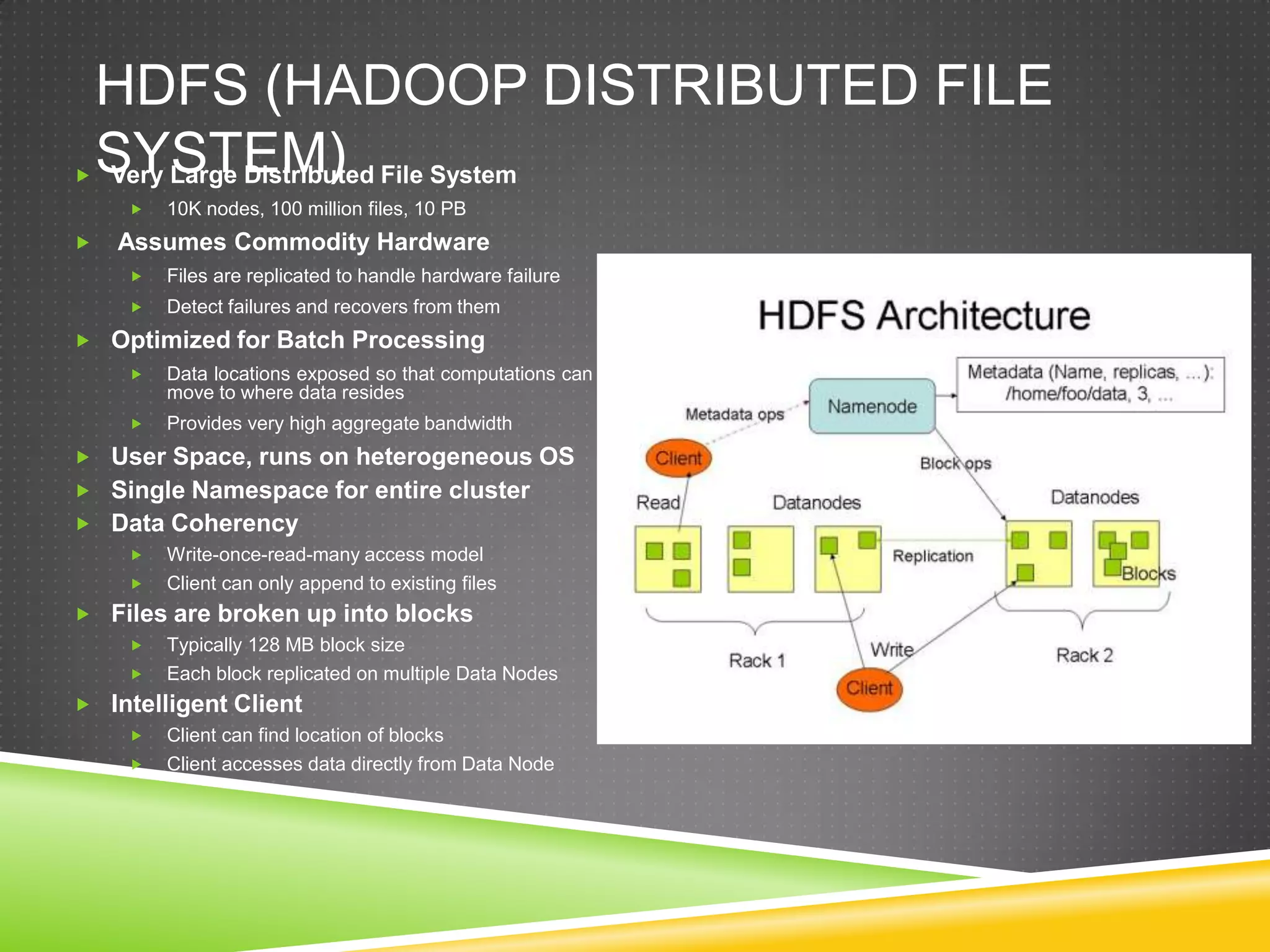
Apache Hadoop is an open-source software framework that supports large-scale distributed applications and processing of multi-petabyte datasets across thousands of commodity servers. It implements the MapReduce programming model for distributed processing and the Hadoop Distributed File System (HDFS) for reliable data storage. HDFS stores data across commodity servers, provides high aggregate bandwidth, and detects/recovers from failures automatically.