Download as PDF, PPTX






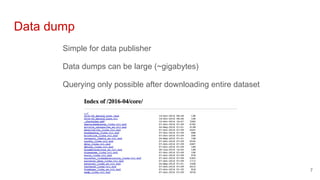




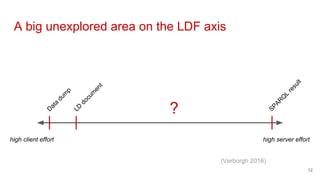
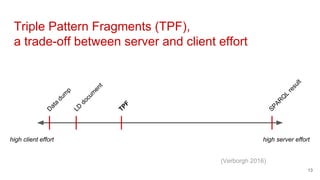















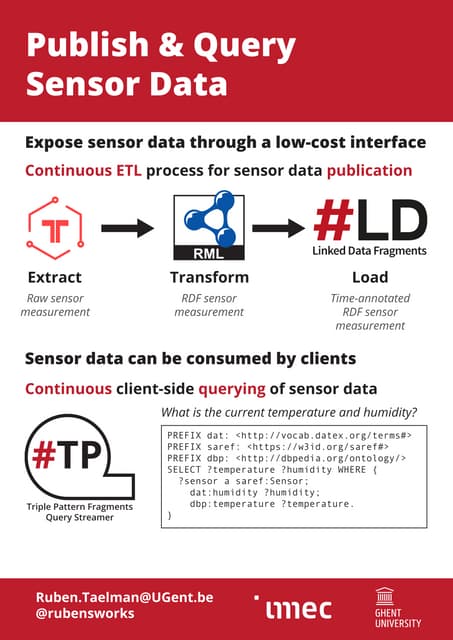
The document discusses the various methods and considerations for publishing linked data, highlighting the balance between server and client efforts in interface selection. It emphasizes the importance of URI policies, data licensing, and continuous maintenance in the linked data publishing process. Additionally, it identifies different interfaces and storage solutions that can impact data accessibility and usability.