Downloaded 18 times

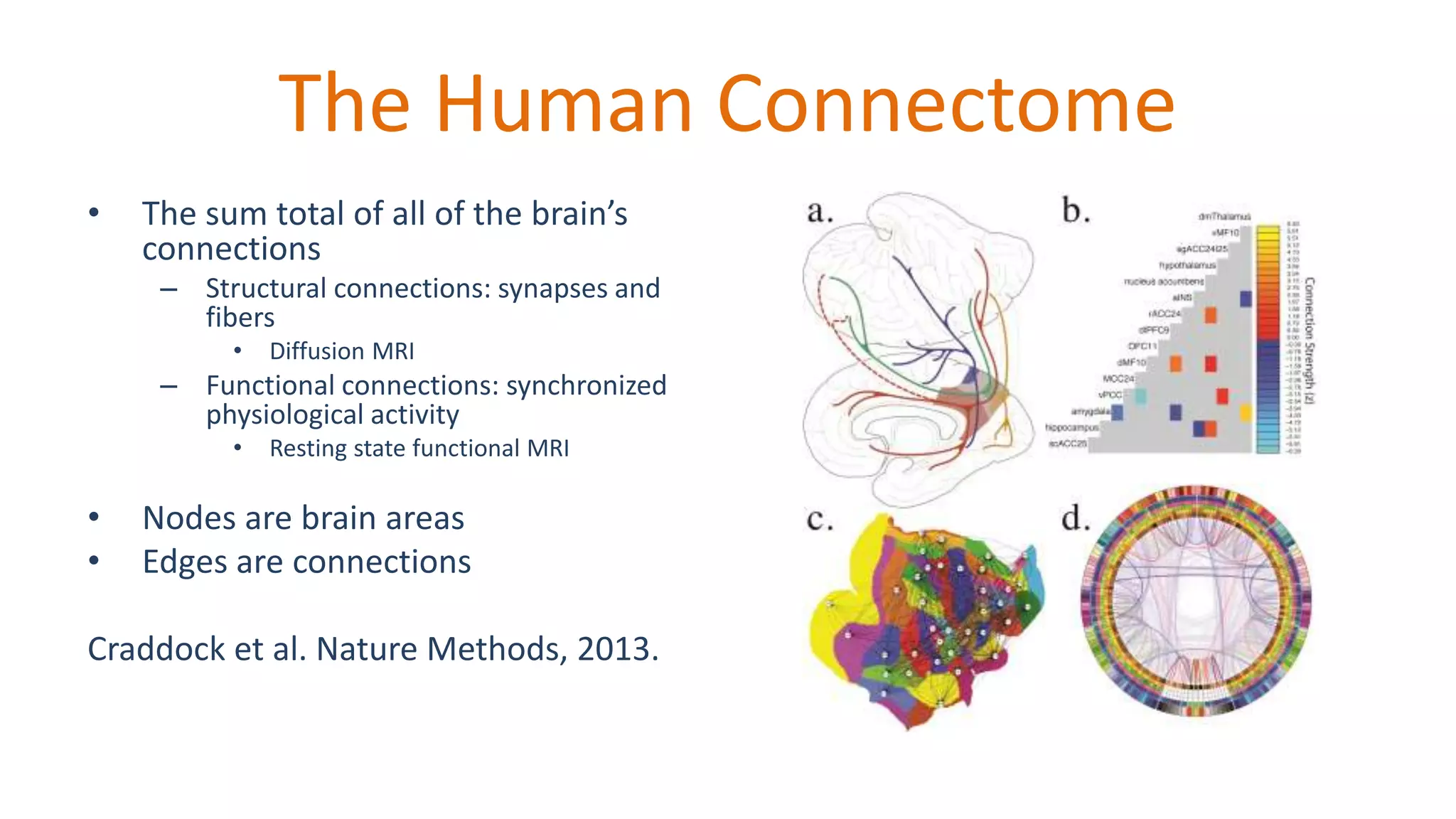


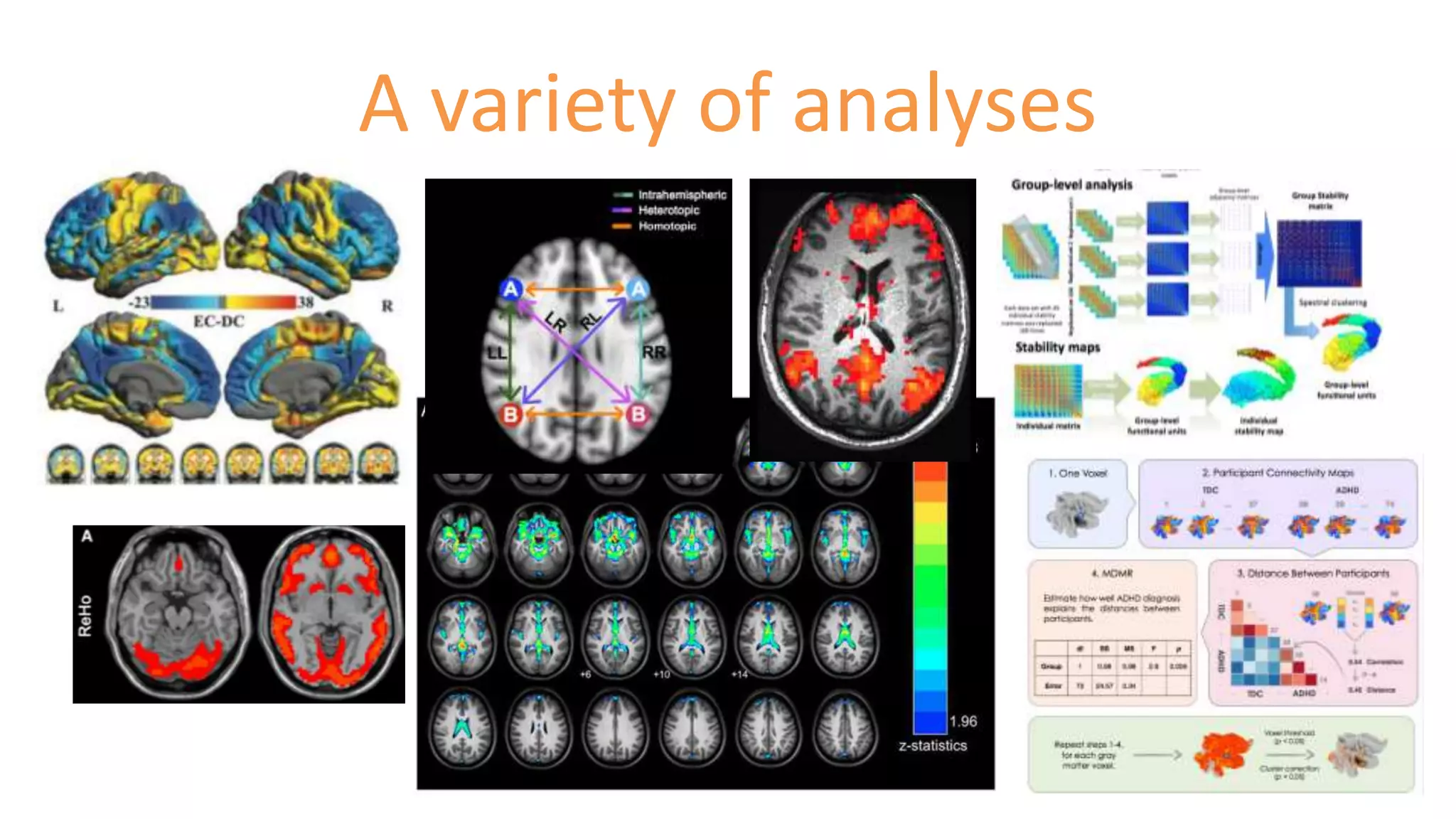

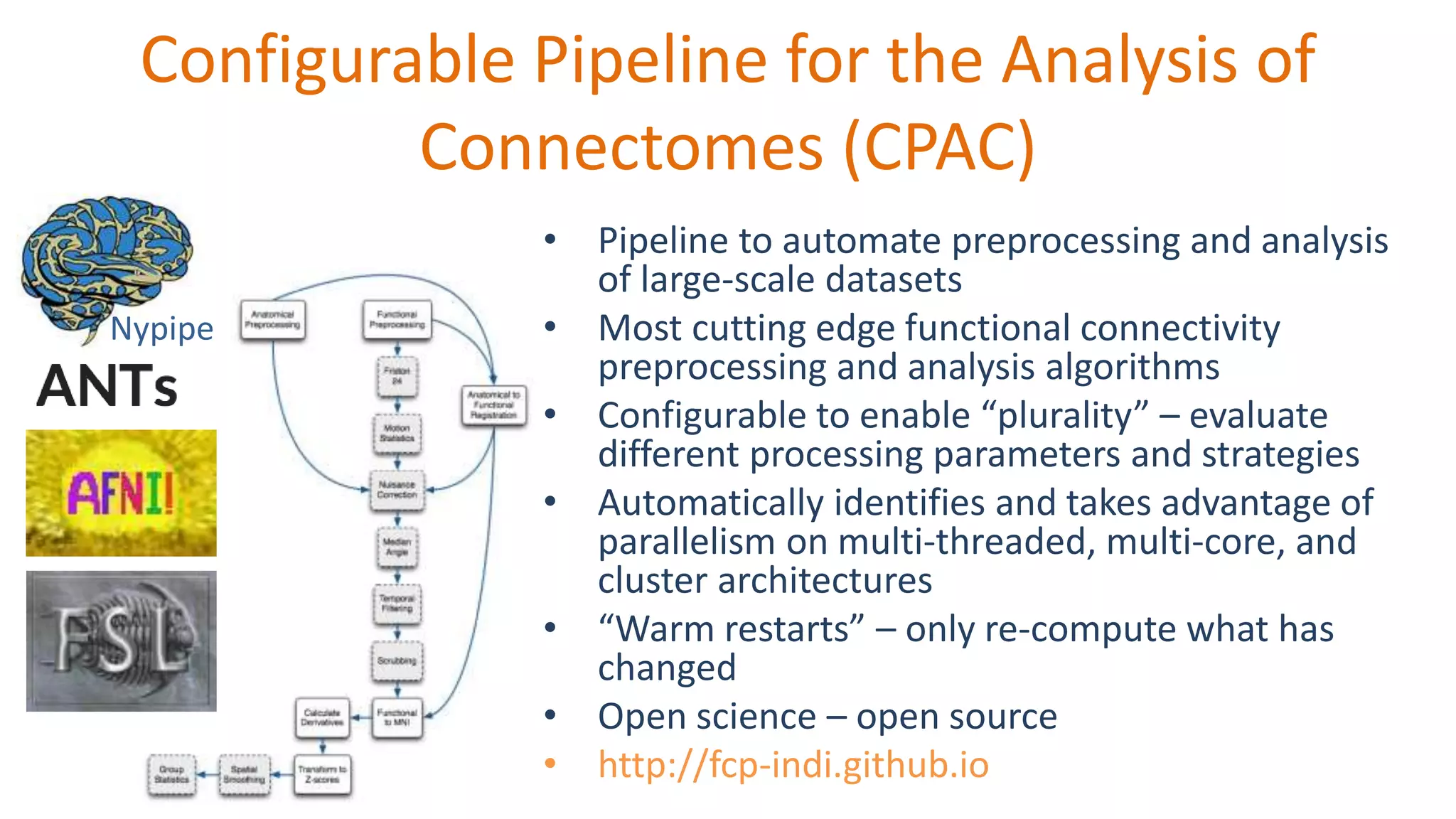












The document discusses open science resources aimed at enhancing the analysis of human connectome data through big data methodologies, specifically focusing on the challenges of noise in functional MRI data. It highlights various preprocessing techniques such as nuisance variable regression and component-based methods for reducing noise, and emphasizes the importance of sharing preprocessed data for reproducibility and collaboration in research. Additionally, it outlines the efforts and tools developed for large-scale datasets and quality assessment protocols to improve data preprocessing and analysis in neuroimaging.








































































