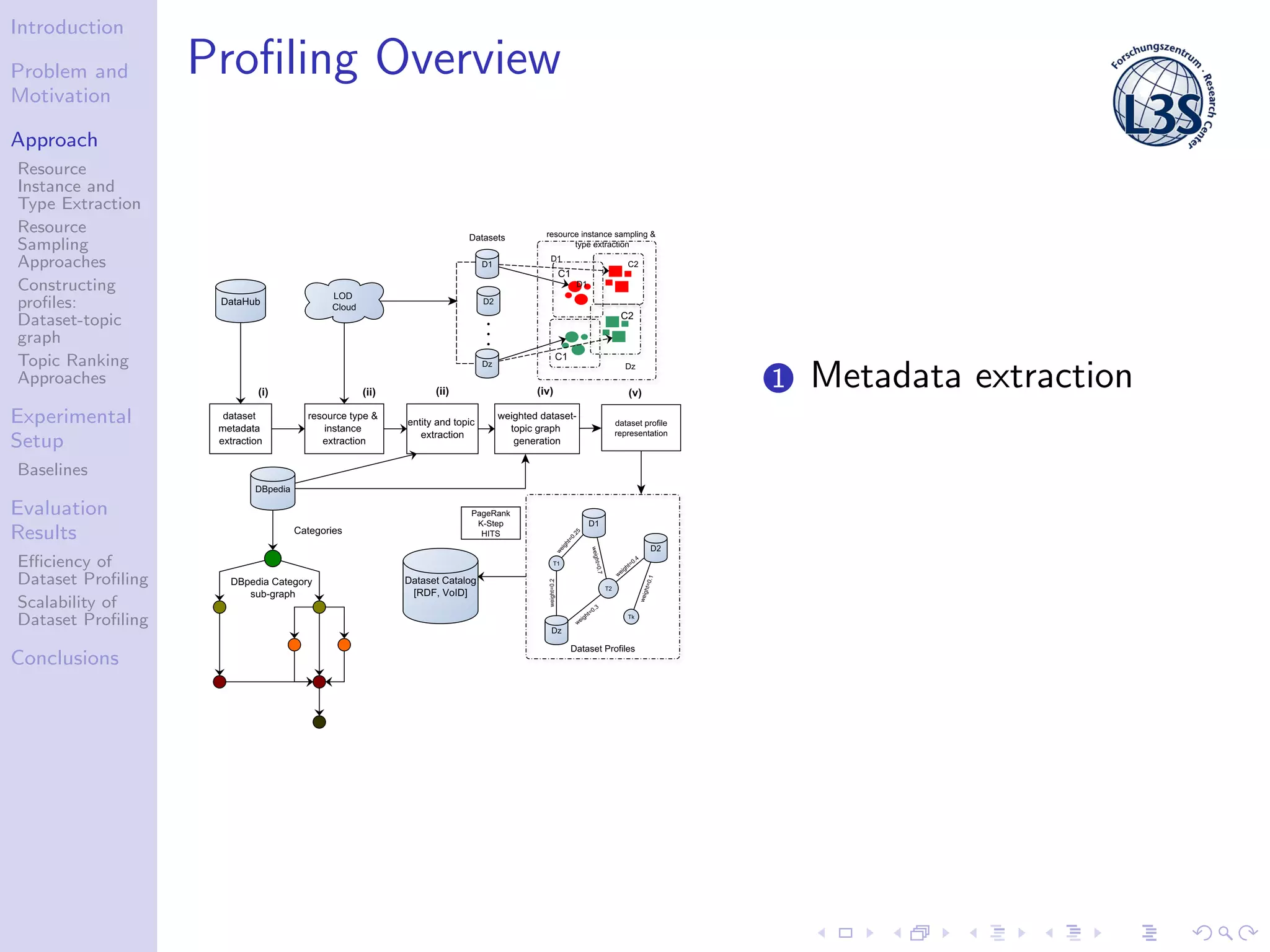
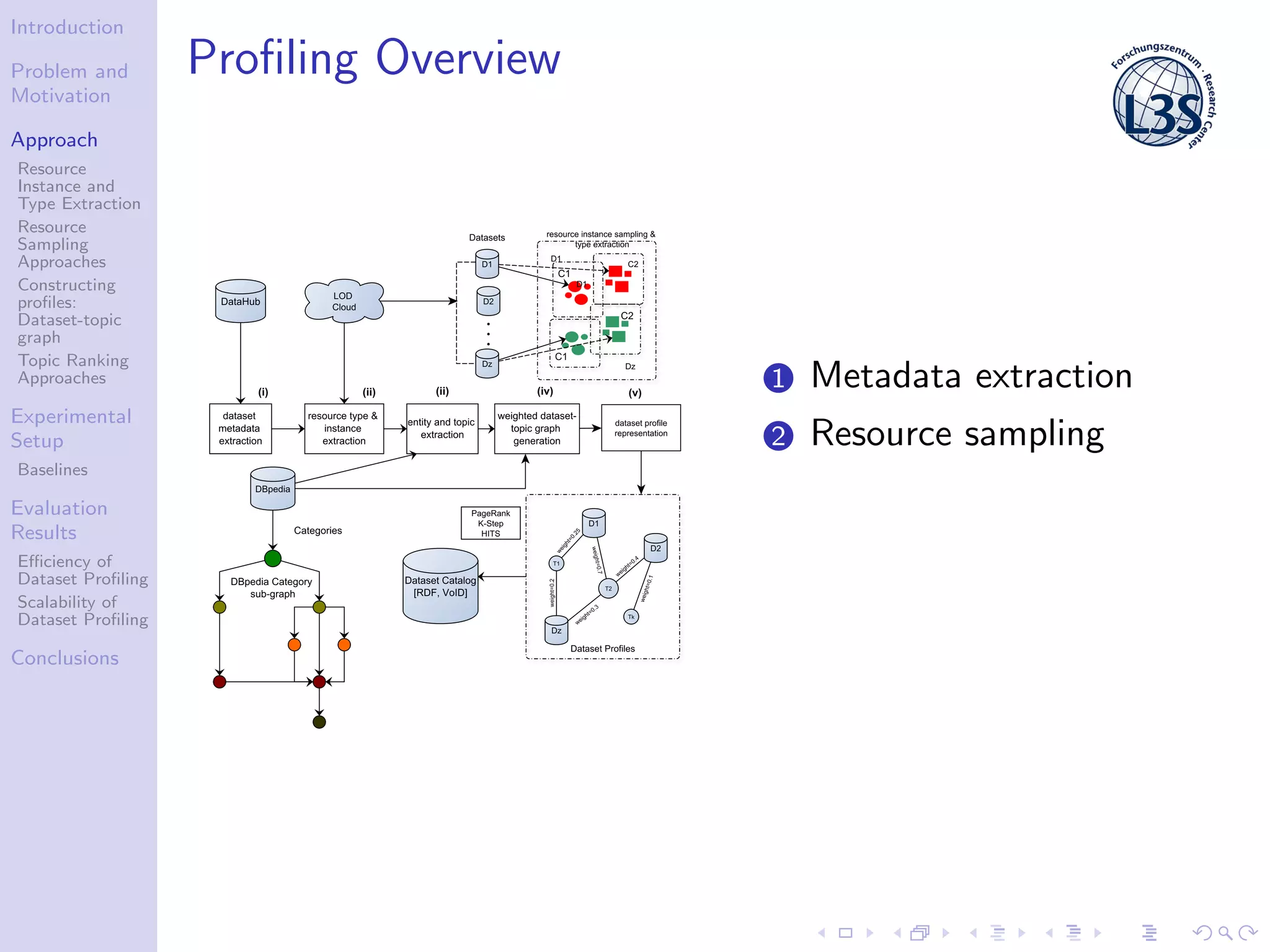
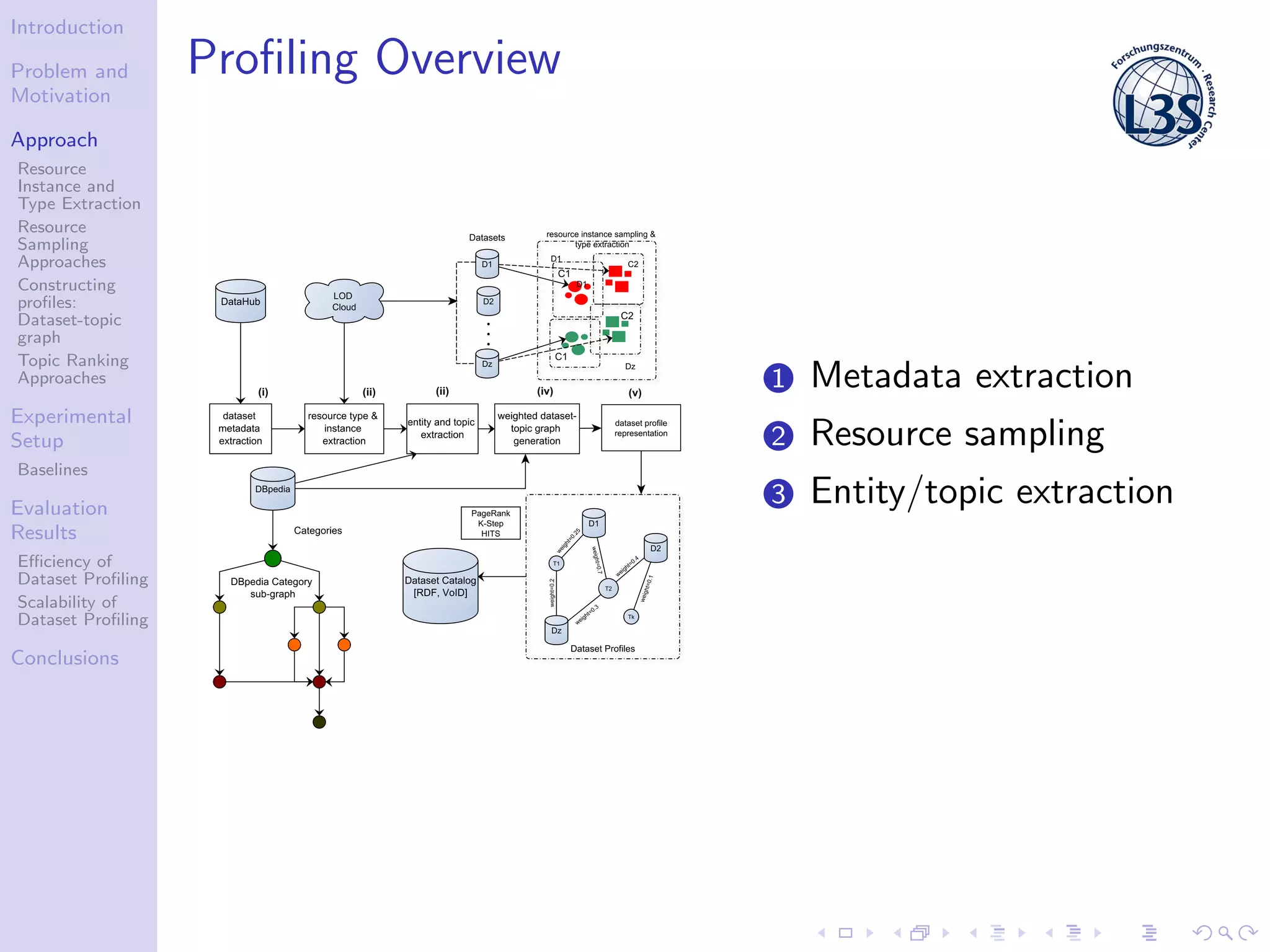
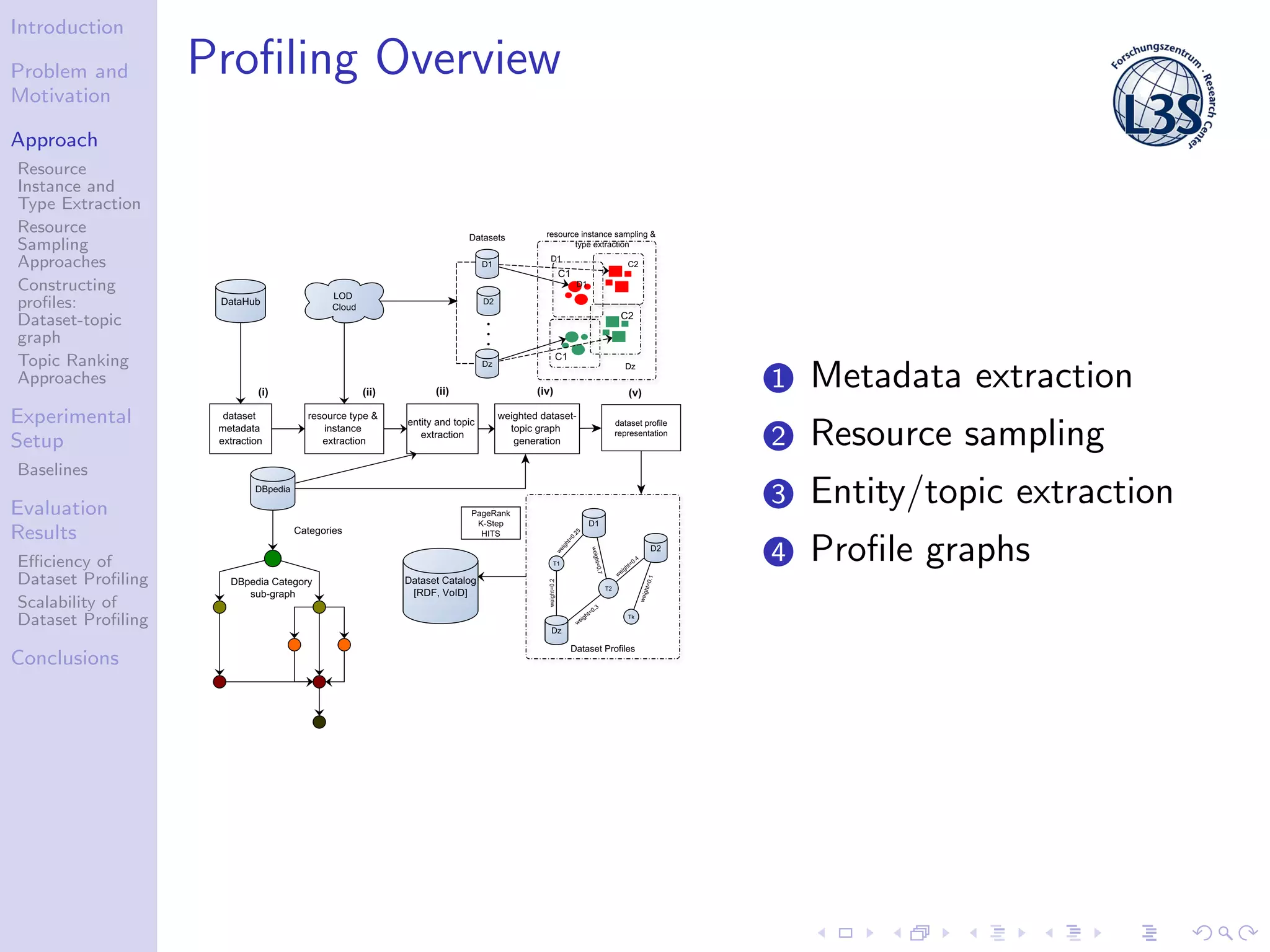
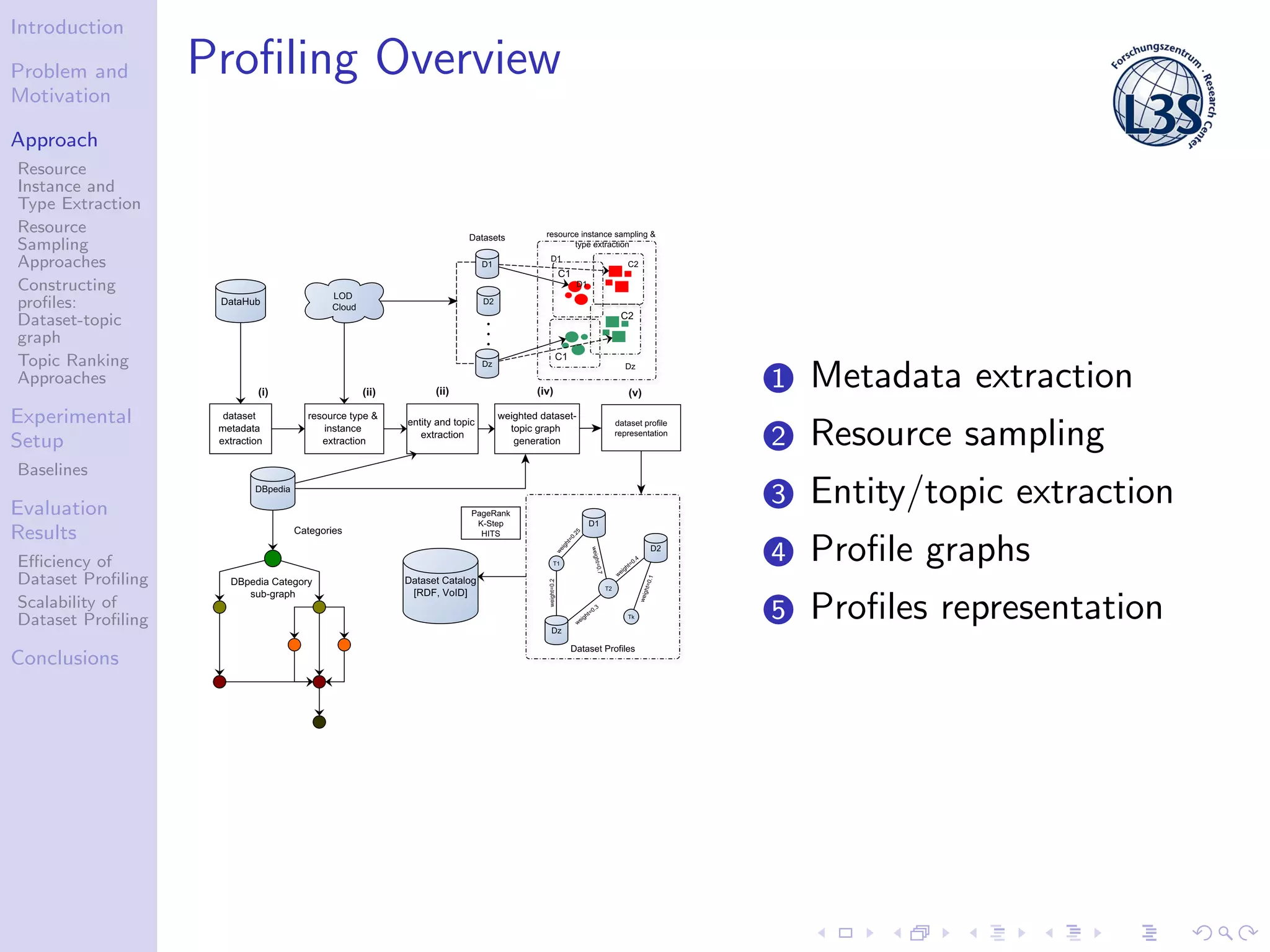
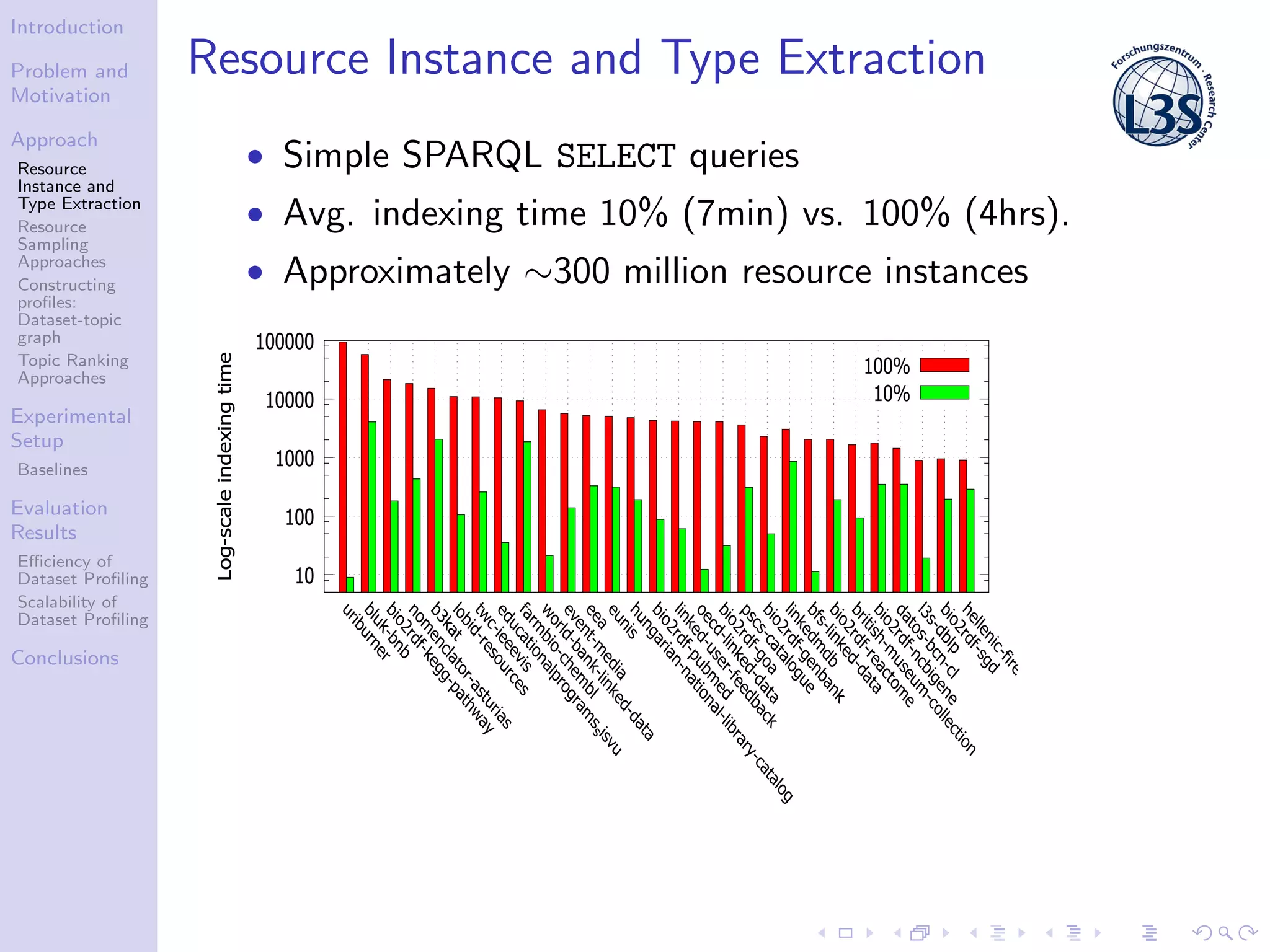
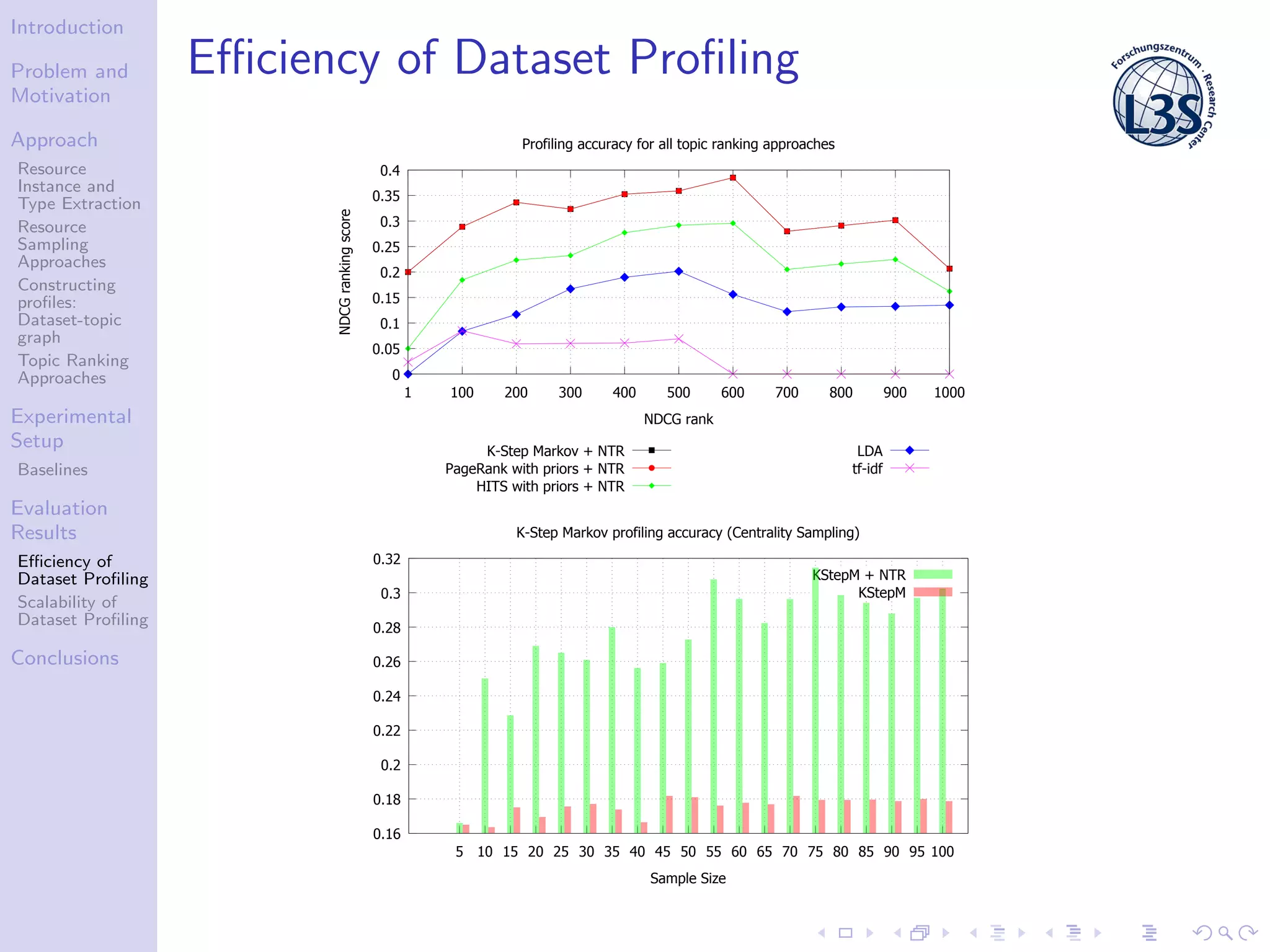
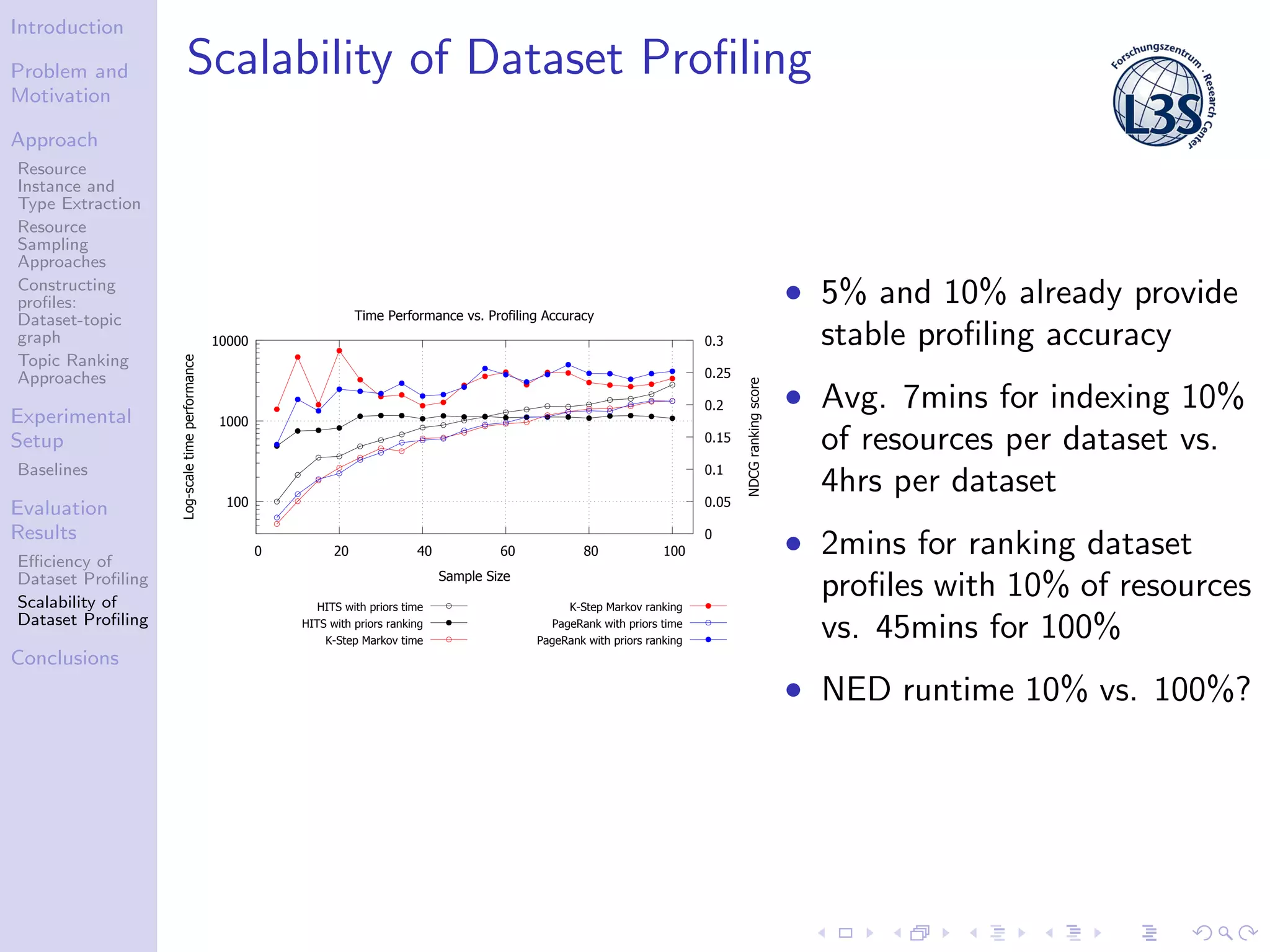
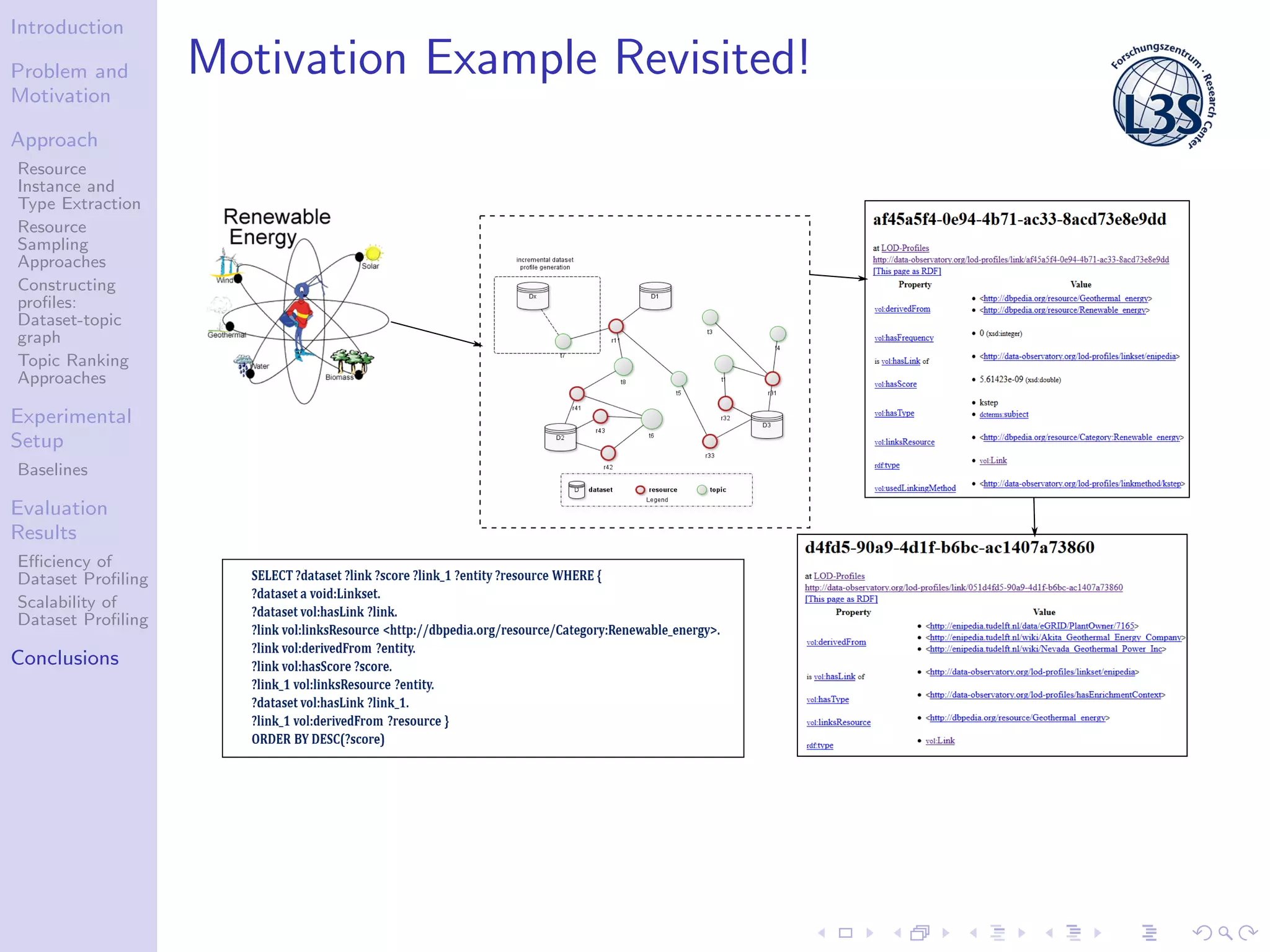
The document discusses a scalable approach for efficiently generating structured dataset topic profiles in the context of increasing web data. It outlines the challenges faced, such as data heterogeneity, sparsely connected datasets, and lack of descriptive metadata, while presenting methods for resource instance and type extraction, topic ranking, and evaluating profiling efficiency and scalability. The study evaluates various sampling approaches and algorithmic techniques through experiments, highlighting the effectiveness of the developed methods.