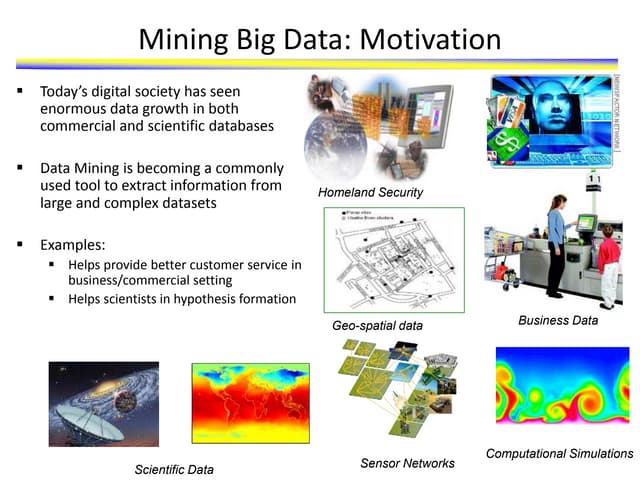
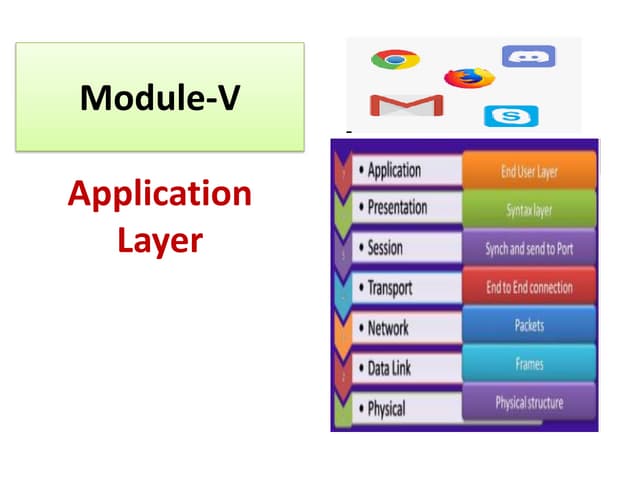
The document outlines the processes of feature generation, feature selection, and the development of recommendation systems in data analysis and machine learning. It covers techniques such as dimensionality reduction, various feature engineering methods, and different types of recommendation systems alongside their algorithms. The ultimate goal is to extract actionable insights from data to inform decision-making and improve model performance.






















![23
References …cont.
[26] Yan, J., & Chen, F. (2016, April). An improved AES key expansion algorithm. In 2016
International Conference on Electrical, Mechanical and Industrial Engineering. Atlantis Press.
[27] Kim, J. M., Lee, H. S., Yi, J., & Park, M. (2016). Power adaptive data encryption for energy-
efficient and secure communication in solar-powered wireless sensor networks. Journal of
Sensors, 2016.
[28] Li, J. (2017). A symmetric cryptography algorithm in wireless sensor network
security. International Journal of Online and Biomedical Engineering, 13(11), 102-110.
[29] Saravanan, P., & Kalpana, P. (2018). Novel reversible design of advanced encryption standard
cryptographic algorithm for wireless sensor networks. Wireless Personal Communications, 100(4),
1427-1458.
[30] Farooq, S., Prashar, D., & Jyoti, K. (2018). Hybrid encryption algorithm in wireless body area
networks (WBAN). In Intelligent Communication, Control and Devices (pp. 401-410). Springer,
Singapore.
[31] Wang, J., Xu, H., & Yao, M. (2012). Improvement of the Round Key Generation of
AES. International Journal of Communications, Network and System Sciences, 5(12), 850-853.
[32] Liu, B., & Baas, B. M. (2011). Parallel AES encryption engines for many-core processor
arrays. IEEE transactions on computers, 62(3), 536-547.
[33] Mullai, A., & Mani, K. (2020). Enhancing the security in RSA and elliptic curve cryptography
based on addition chain using simplified Swarm Optimization and Particle Swarm Optimization for
mobile devices. International Journal of Information Technology, 1-14.](https://image.slidesharecdn.com/module-3-240819093619-d3085b43/85/data-science-module-3-power-point-presentation-23-320.jpg)