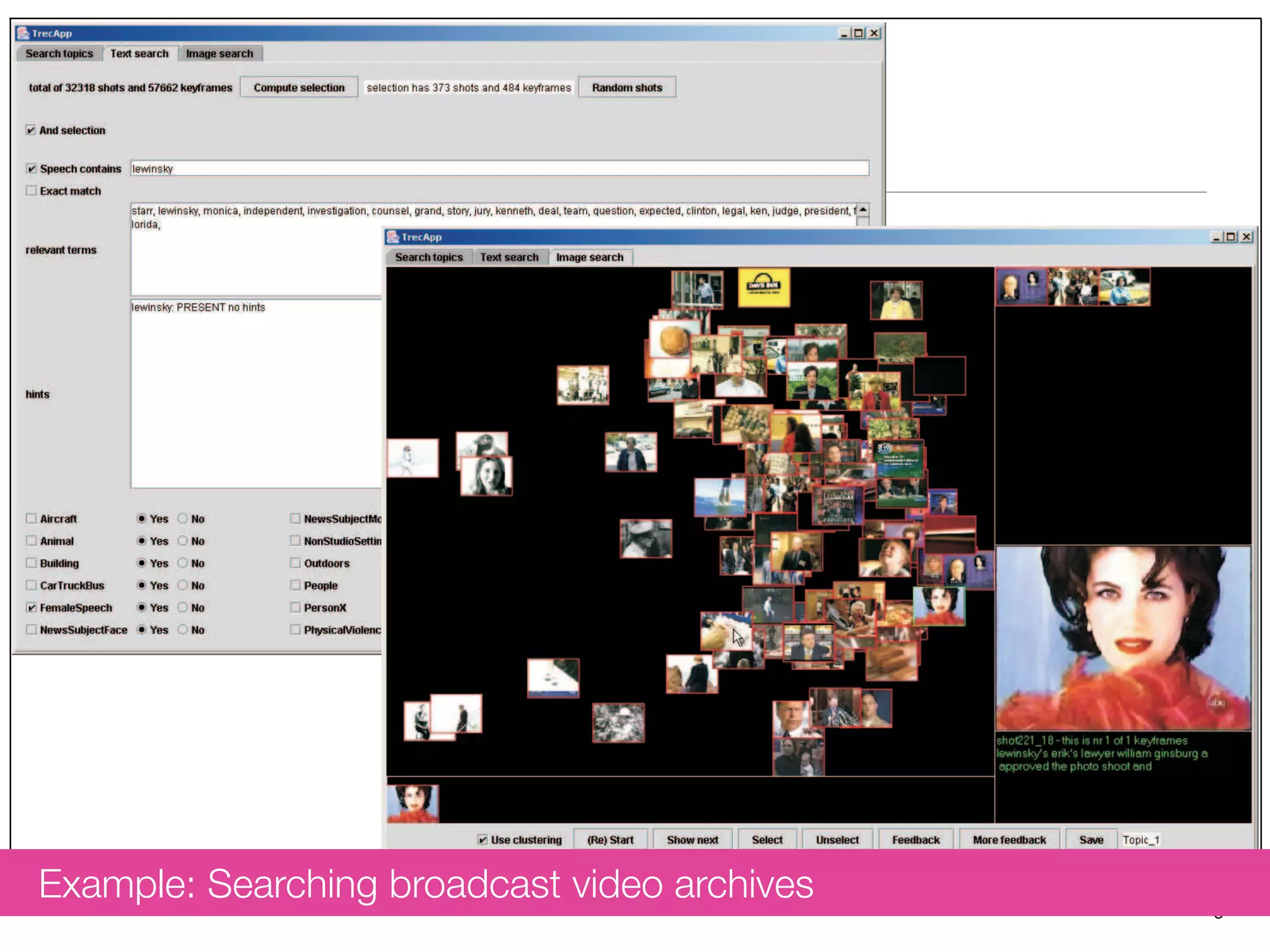
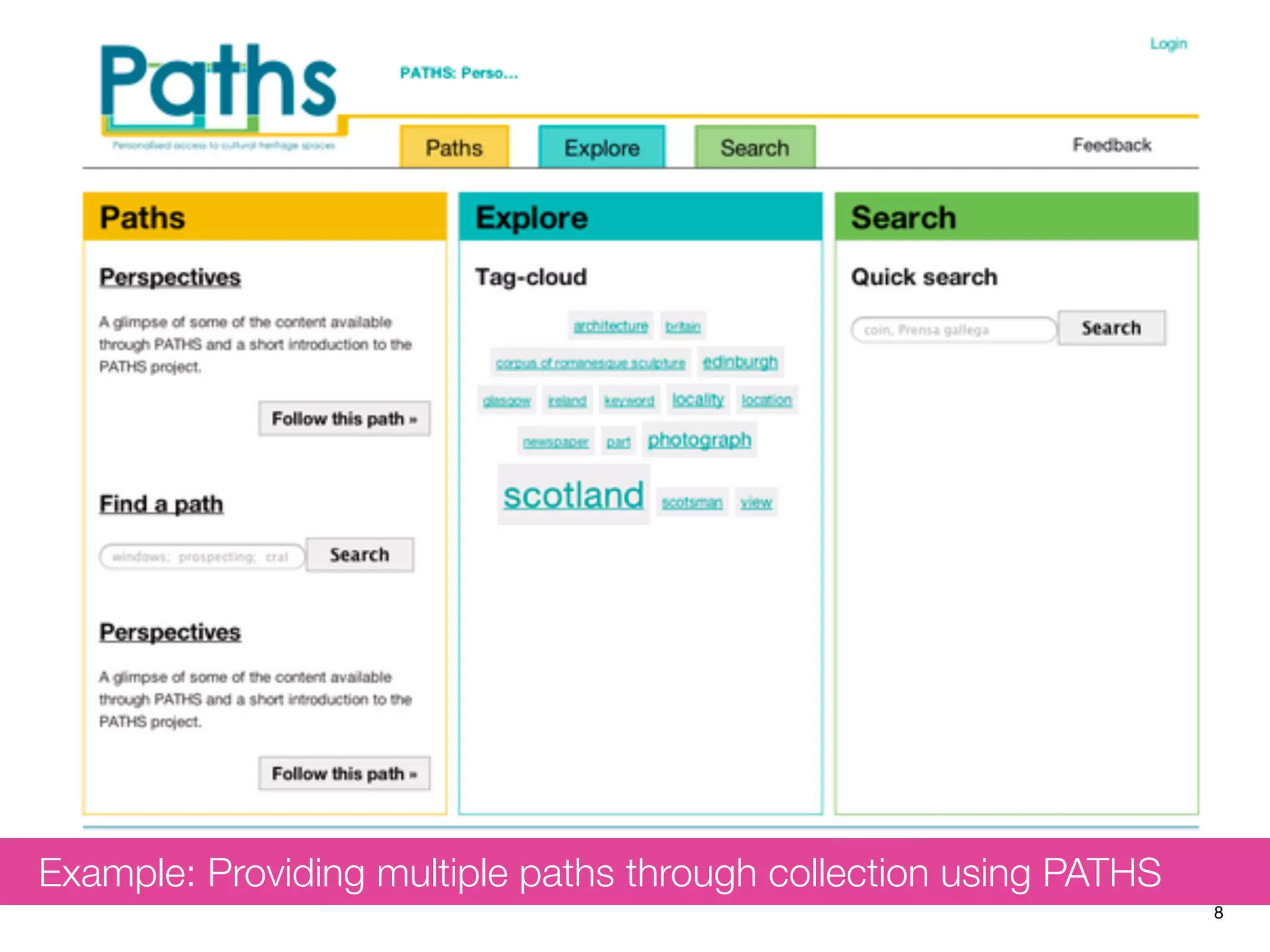
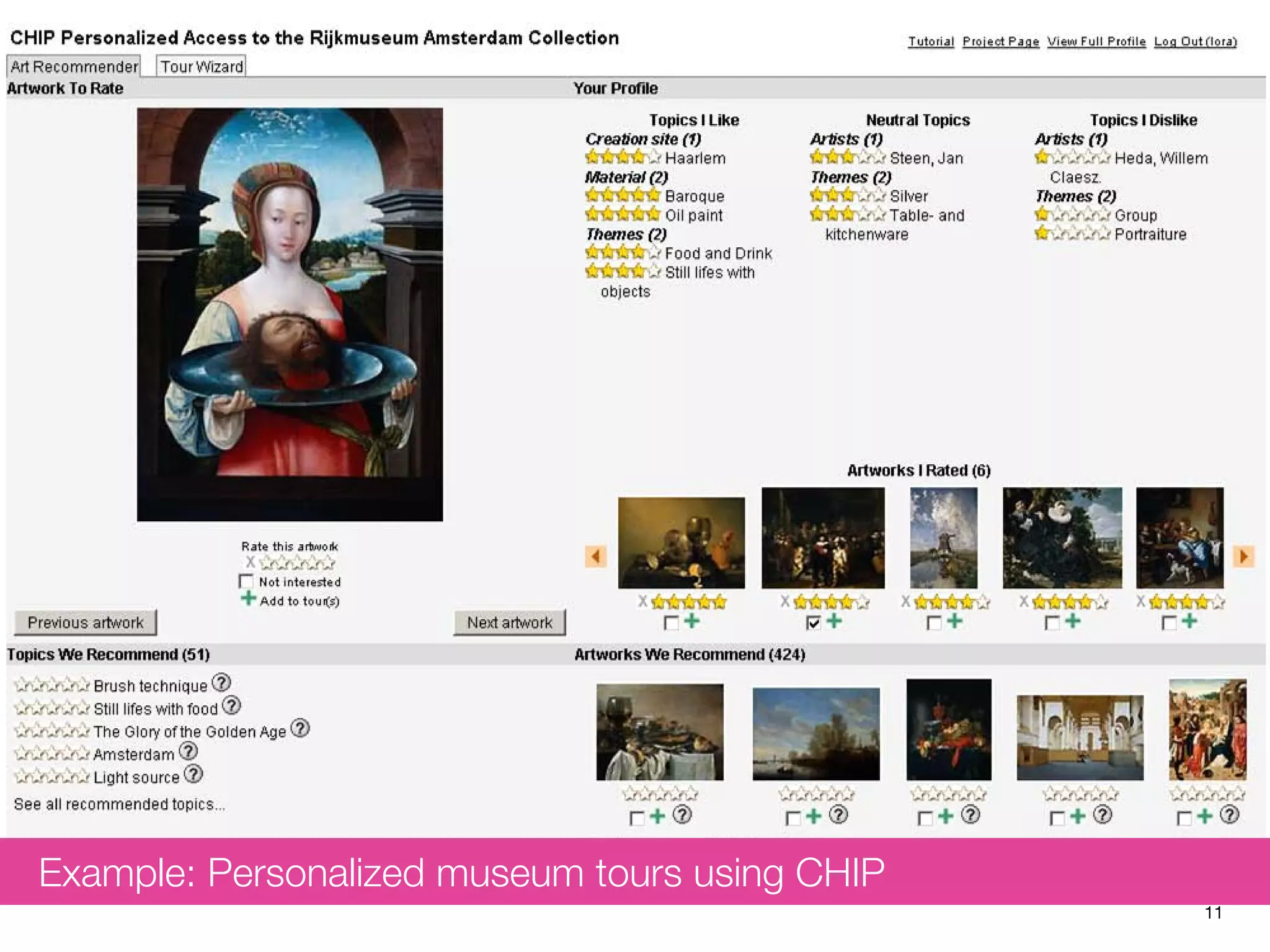
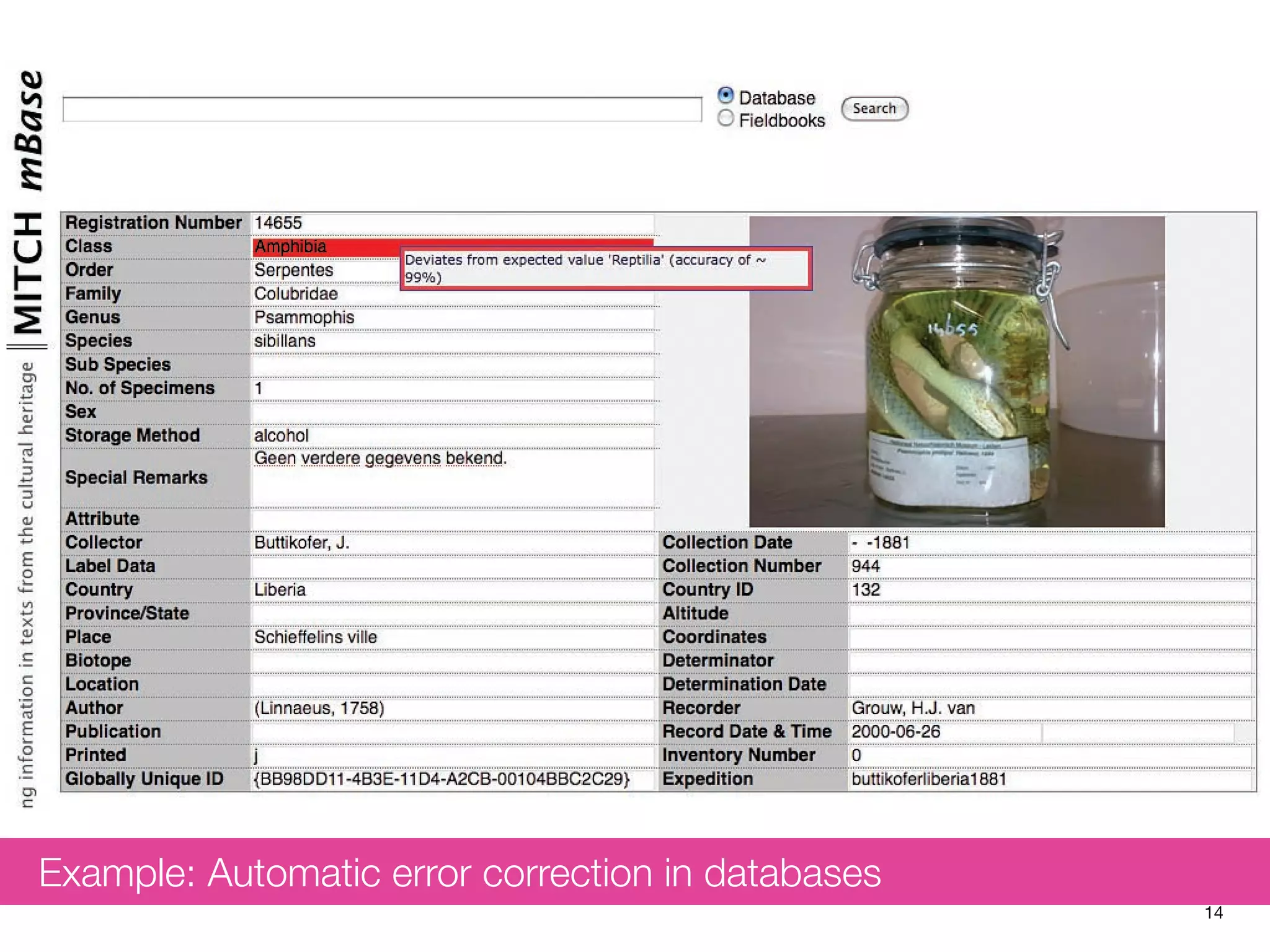
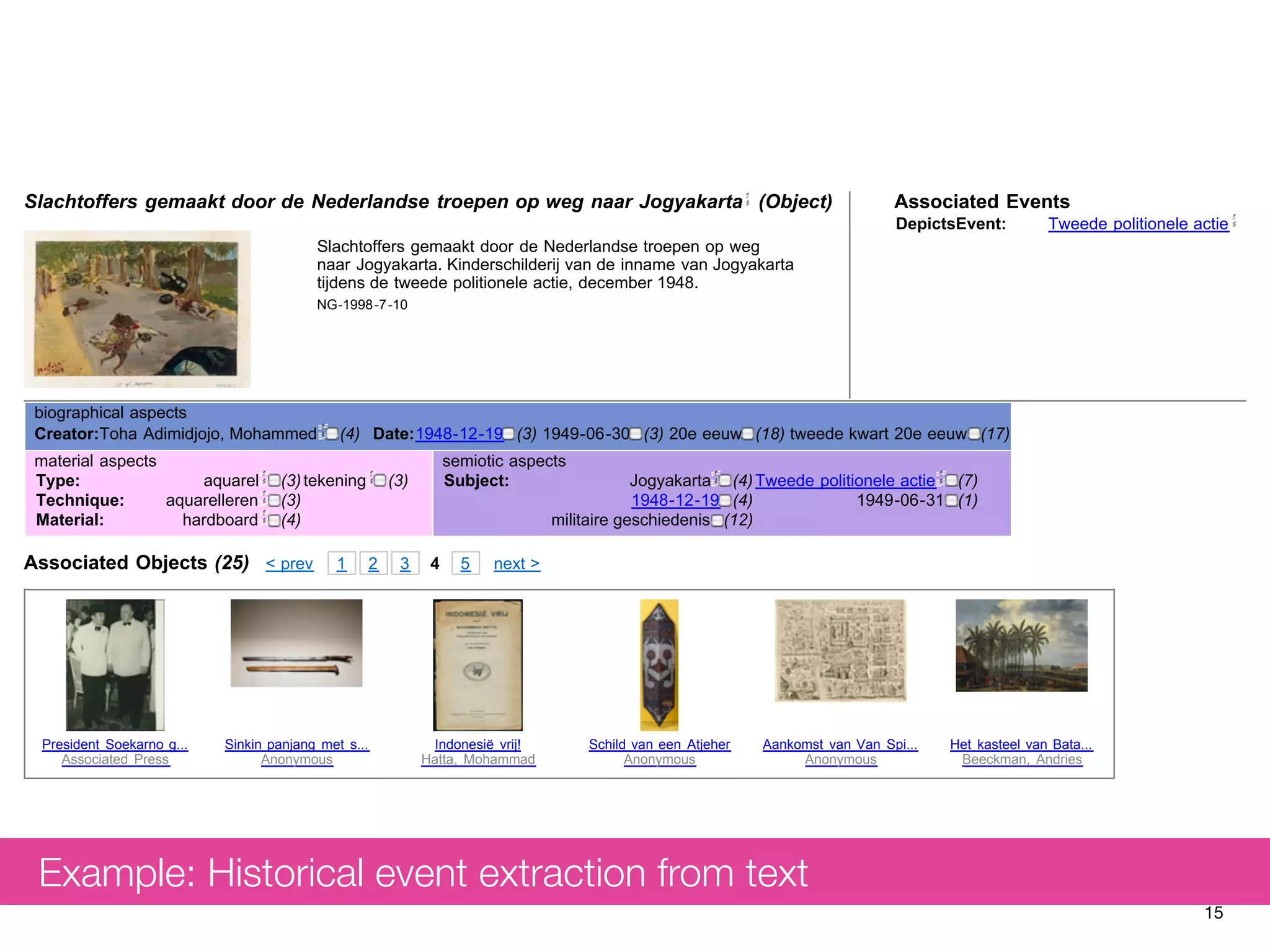
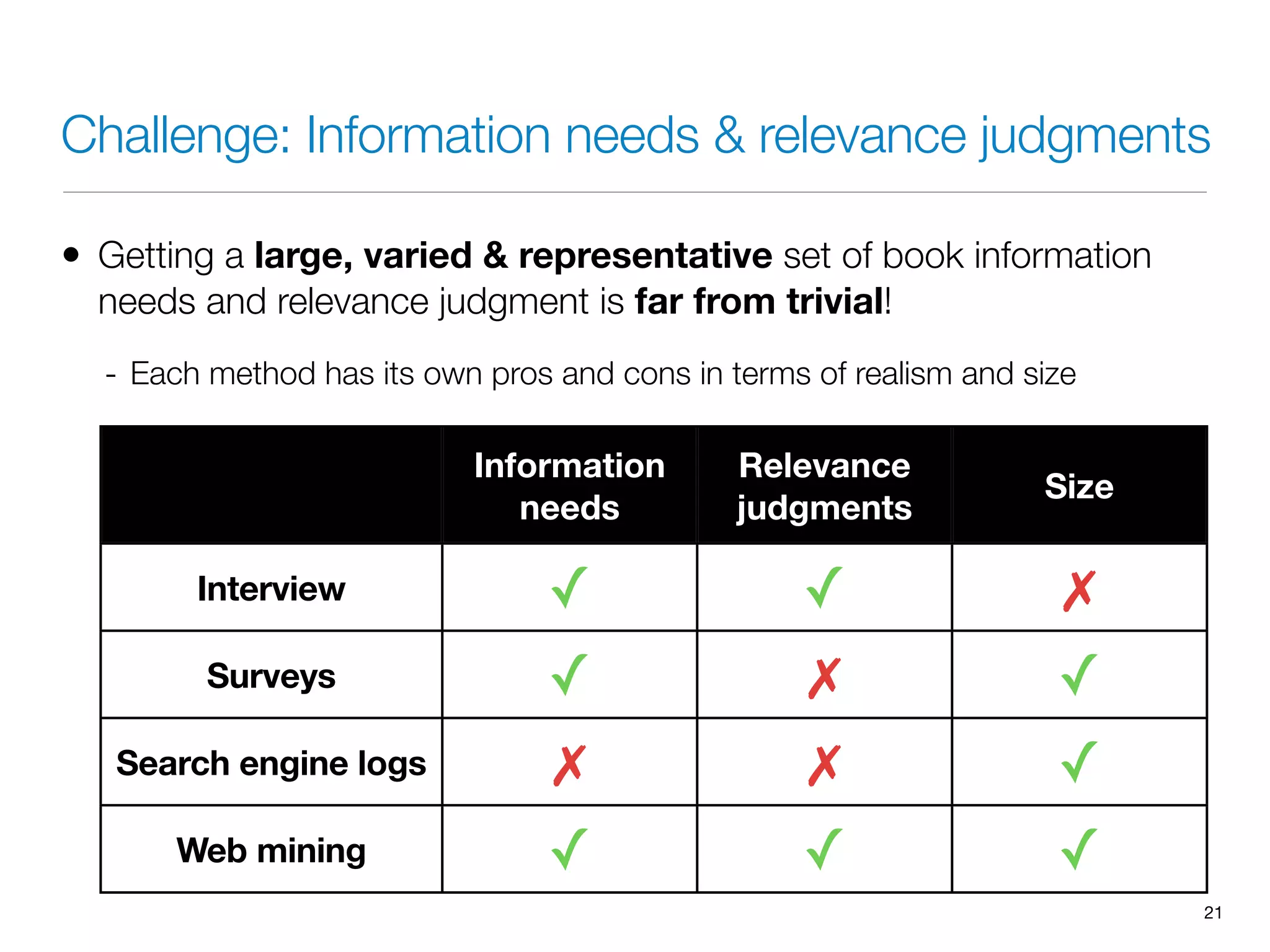
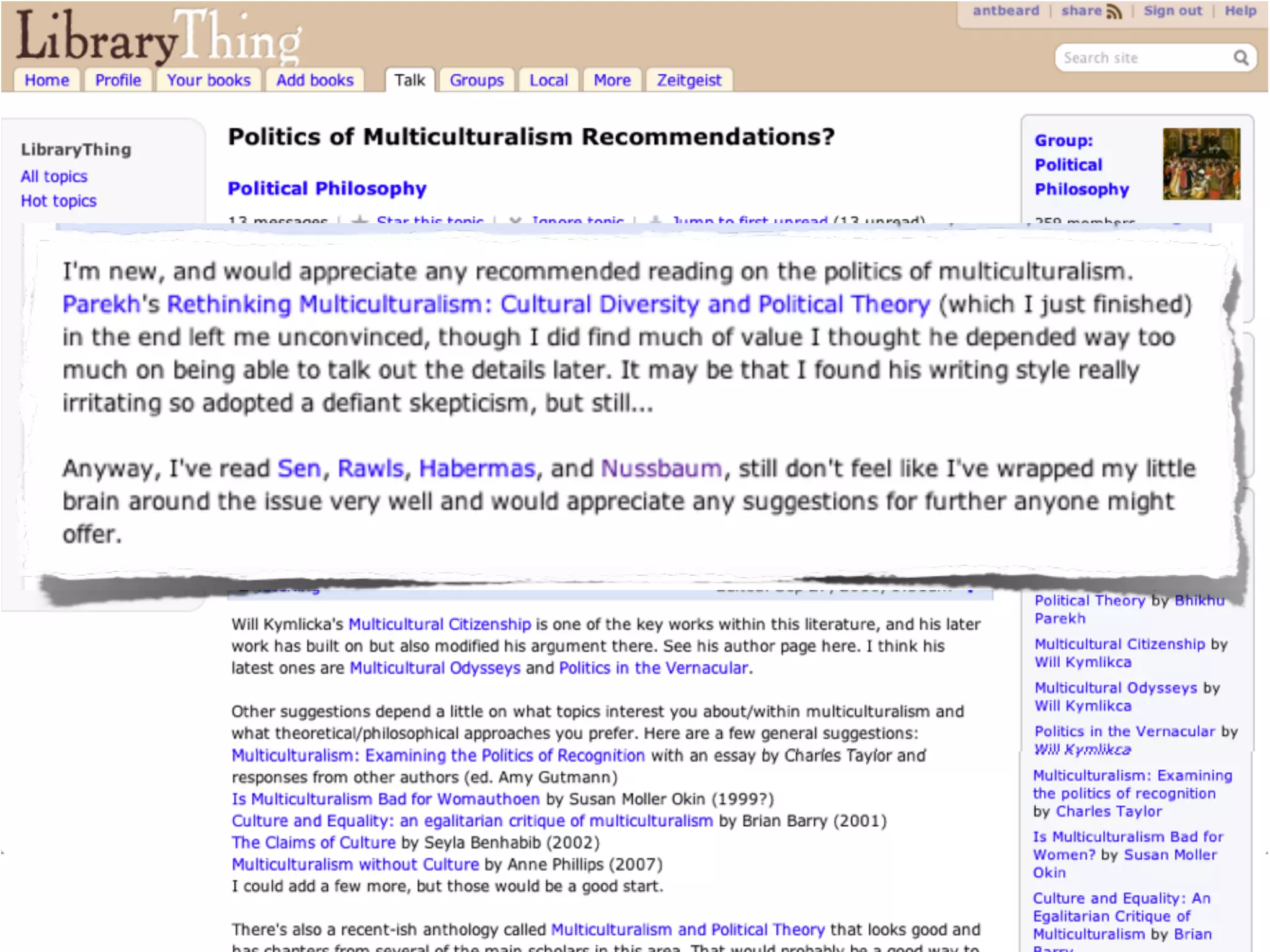
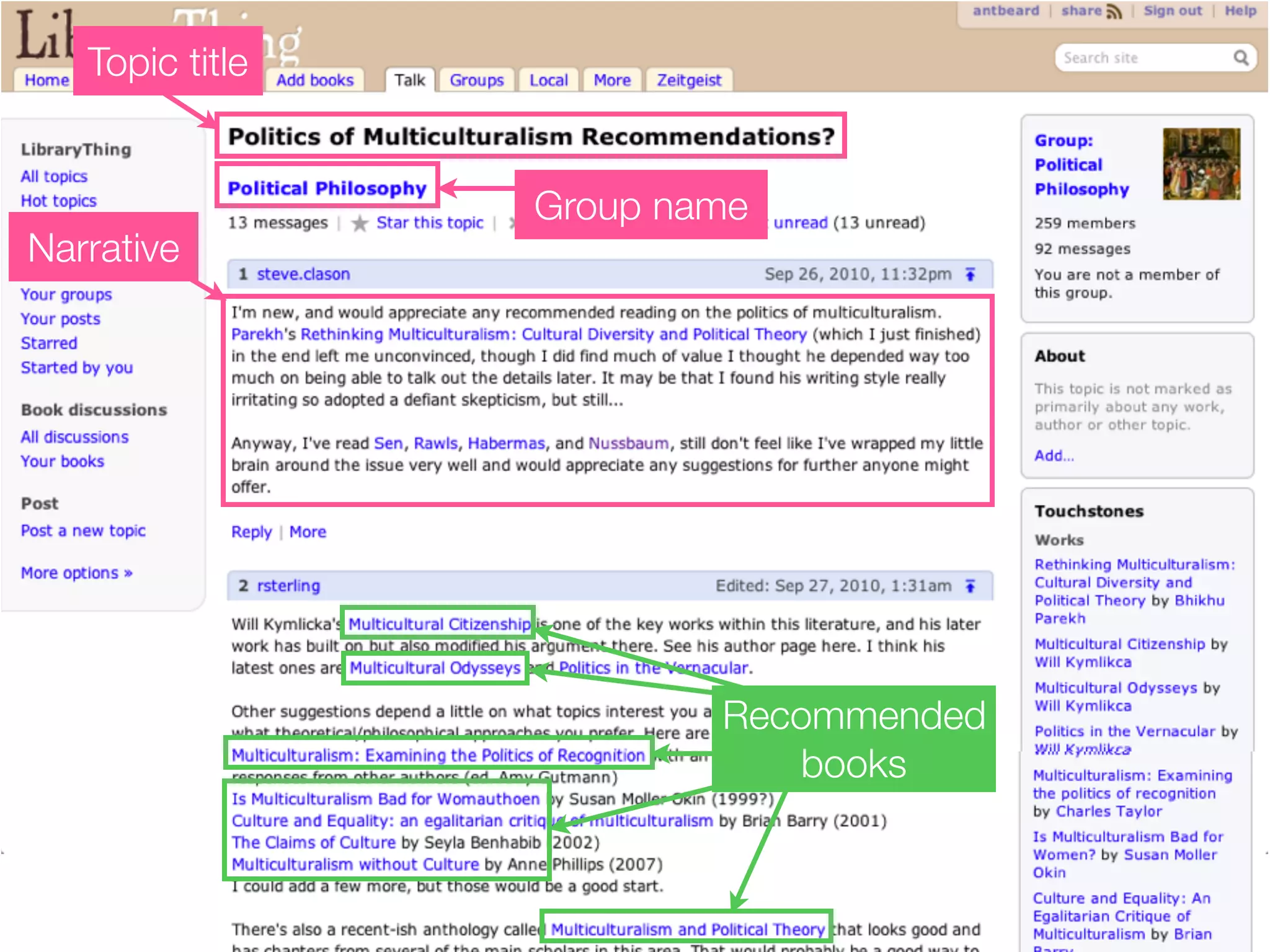
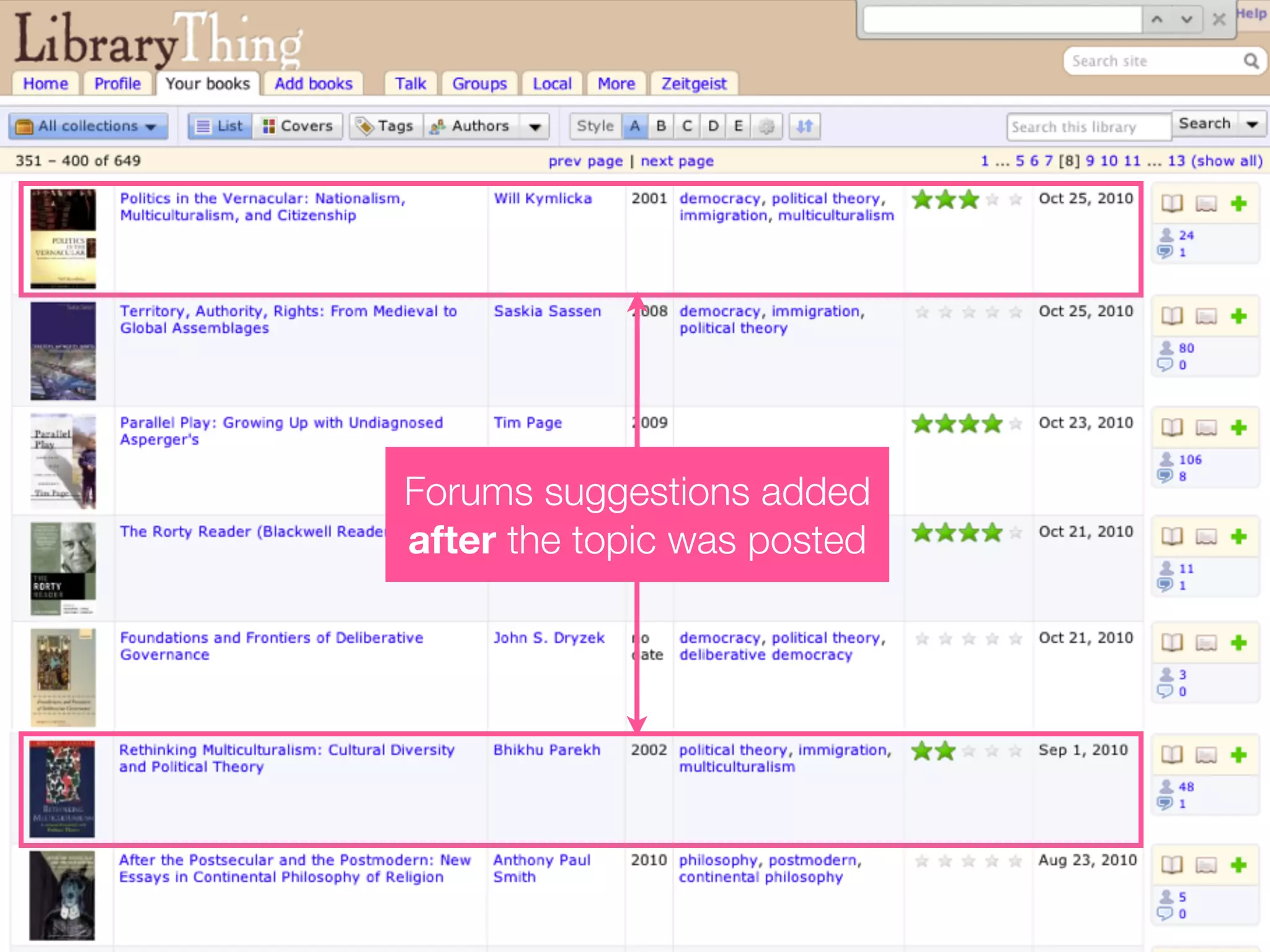
The document discusses measuring system performance in cultural heritage information systems, detailing four main types: search, browsing, recommendation, and enrichment. It outlines evaluation practices and challenges associated with each type, emphasizing the need for realistic data, user input, and tailored evaluation approaches. A case study on social book search illustrates the importance of gathering representative information needs and relevance judgments in the context of cultural heritage.