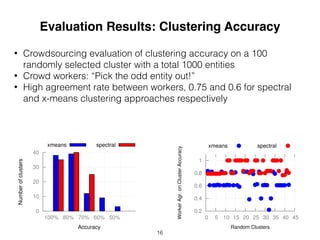
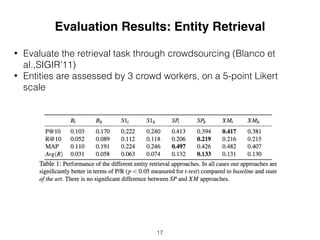
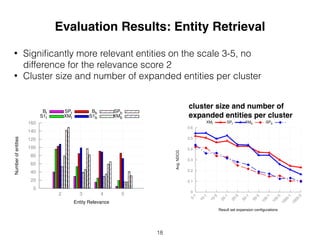
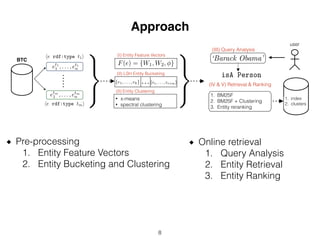
This document proposes an approach to improve entity retrieval on structured data by leveraging entity clustering and type information. It introduces (I) representing entities as feature vectors, (II) clustering entities using techniques like x-means, and (III) analyzing queries to determine relevant entity types. For retrieval, it first uses BM25F and then expands results by retrieving additional entities from the same clusters. Evaluation shows the clustering approaches significantly increase the number of relevant entities retrieved compared to baselines.






![Motivation
10
0
10
1
10
2
103
10
4
10
5
10
6
107
10
8
100
101
102
103
104
105
106
107
Frequencyofobjectproperties
Frequency of explicit similarity statements
• Explicit entity linking statements
improve retrieval[1]
[1] Alberto Tonon, Gianluca Demartini, Philippe Cudré-Mauroux. Combining inverted indices and structured search for ad-hoc object retrieval, SIGIR 2012
equivalence
dbp:Bethlehem,_Pennsylvania
owl:sameAs
fb:Bethlehem (Pennsylvania)
relatedness
dbp:Bethlehem,_Pennsylvania
rdfs:seeAlso
dbp:The_Lehigh_Valley
redirects
dbp:Bethlehem,_Pennsylvania
dbo:WikiPageRedirects
dbr:Bethlehem,_PA
• Sparsity of explicit linking
statements
• Majority of links have no
properly defined semantics
6](https://image.slidesharecdn.com/iswc2015-151014201604-lva1-app6892/85/Improving-Entity-Retrieval-on-Structured-Data-6-320.jpg)
![Motivation (I)
• Most queries are entity-
centric[2]
• Relevant entities in the
result set are usually from
related entity types
• Few entity types (e.g.
‘Person’) are affiliated with
many entity types
Artist
Organization
Famous People
Film
Bird
People
Product
City
Activists
Computer Software
Musical Artist
ArchitecturalStructure
NAACP Image Awards
People with Occupation
Saints
Work
Computer
Educational Organization
Broadcaster
Murdered People
Musical Work
Stadium
Organization
University
CreativeWork
Broadcaster
City
Person
Place
Weapon
0
0.2
0.4
0.6
0.8
1
Query type affinity: Given an entity-
centric query, entities of a specific type
are more likely to be relevant than the
others
q = {’Barack Obama’}
hasType Person
7 Query type affinity](https://image.slidesharecdn.com/iswc2015-151014201604-lva1-app6892/85/Improving-Entity-Retrieval-on-Structured-Data-7-320.jpg)
![Pre-Processing: Feature Vectors
Wn — n-gram dictionary scored
through tf-idf
φ — {0,1} if a property for
type t is present in entity e
F(e) = {W1(e), W2(e), }
W1 = [hu1; tfidf(u1)i, . . . , hun; tfidf(un)i]
W2 = [hb1; tfidf(b1)i, . . . , hbn; tfidf(bn)i]
= [ (o1, e), . . . , (on, e)]
(oi, e) ! [0, 1], i 2 {1, . . . , n}
rdfs:label Barack Obama
rdfs:comment Barack Hussein Obama II (/bəˈrɑːk huːˈseɪn ɵˈbɑːmə/; born August 4,
1961) is the 44th and current President of the United States, and the first African American to
hold the office. Born in Honolulu, Hawaii, Obama is a graduate of Columbia University and
Harvard Law School, where he served as president of the Harvard Law Review. He was a
community organizer in Chicago before earning his law degree.
foaf:name Barack Obama
dc:description American politician, 44th President of the United States
foaf:isPrimaryTopicOf http://en.wikipedia.org/wiki/Barack_Obama
dcterms:subject http://dbpedia.org/resource/Category:Nobel_Peace_Prize_laureates
dcterms:subject http://dbpedia.org/resource/Category:Presidents_of_the_United_States
dcterms:subject http://dbpedia.org/resource/Category:Obama_family
dcterms:subject http://dbpedia.org/resource/Category:American_civil_rights_lawyers
rdfs:seeAlso http://dbpedia.org/resource/United_States_Senate
• n-grams from literals
• object properties
• entity type level statistics
9](https://image.slidesharecdn.com/iswc2015-151014201604-lva1-app6892/85/Improving-Entity-Retrieval-on-Structured-Data-9-320.jpg)



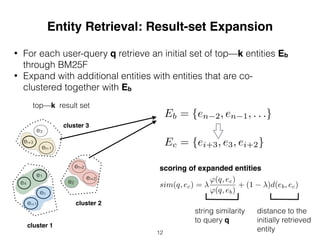

![Experimental Setup
Dataset: BTC’12
• 1.4 billion triples
• 107,967 data graphs
• 3,321 entity types
• 454 million entity instances
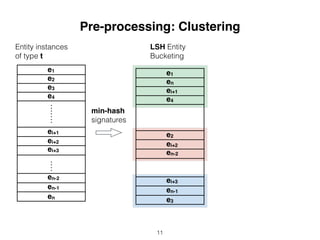
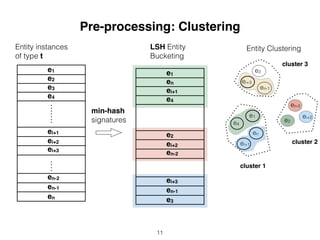
Entity Bucketing and Clustering
• ~77,485 entities fed into LSH
bucketing algorithm
• ~400 entities on average for the
clustering approaches
• ~13–38 clusters
• ~10–20 entities per cluster
Queries: SemSearch[1]
• 92 queries
[1] http://km.aifb.kit.edu/ws/semsearch10/
[2] T. Neumann and G. Weikum. Rdf-3x: A risc-style engine for rdf. Proc. VLDB Endow.,1(1):647–659, Aug. 2008.
Data Indexes
• RDF3X[2] and Lucene Index
• title + body fields
• body (consists of all literals of an
entity
14](https://image.slidesharecdn.com/iswc2015-151014201604-lva1-app6892/85/Improving-Entity-Retrieval-on-Structured-Data-17-320.jpg)