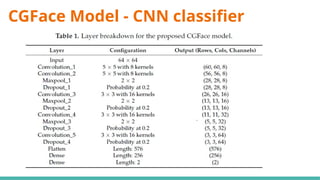
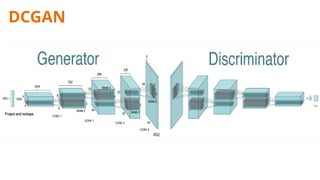
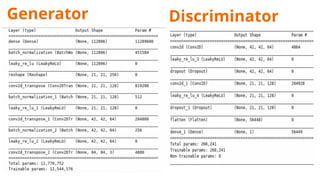
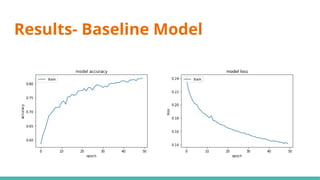
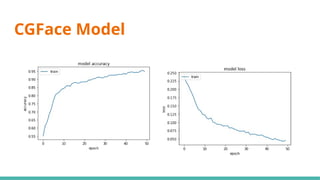
The document discusses deepfake detection, highlighting the need for improved accuracy in identifying real versus fake videos due to the negative implications on privacy and democracy. It details the methodology used in developing a model for classification, including dataset preparation, feature extraction, and the implementation of various deep learning techniques such as CNN and GAN. The findings indicate challenges faced in training models effectively, particularly with meta learning and resource requirements for processing video data.





























![DeepFake_Using_StyleGAN2[1].pptx,jknhbgkjhgf](https://cdn.slidesharecdn.com/ss_thumbnails/deepfakeusingstylegan21-260125032816-54a58d62-thumbnail.jpg?width=640&height=640&fit=bounds)


![DeepFake_Using_StyleGAN2[1][1].pptx,mjnhbgvfcxd](https://cdn.slidesharecdn.com/ss_thumbnails/deepfakeusingstylegan211-260125032907-a9e1a209-thumbnail.jpg?width=640&height=640&fit=bounds)











![[AI07] Revolutionizing Image Processing with Cognitive Toolkit](https://cdn.slidesharecdn.com/ss_thumbnails/ai07-170602095346-thumbnail.jpg?width=640&height=640&fit=bounds)























