Download as PDF, PPTX





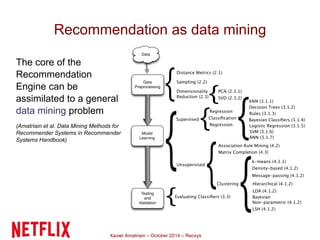


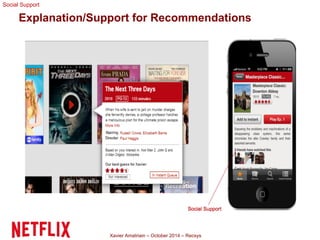

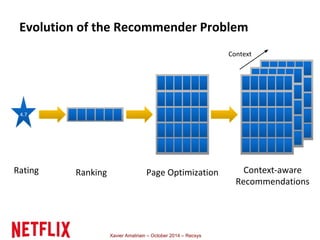
























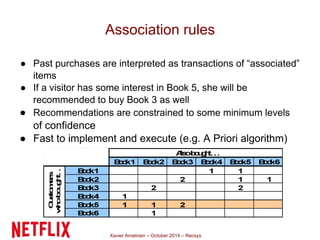












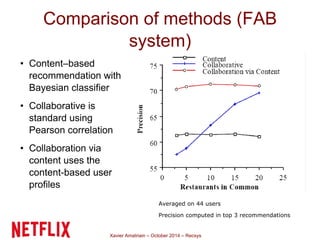






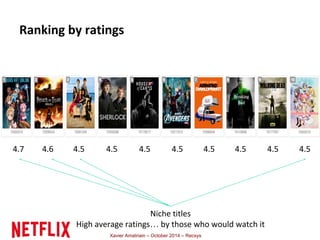

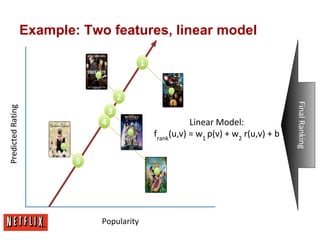
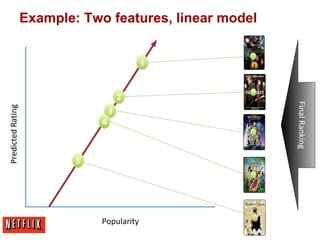







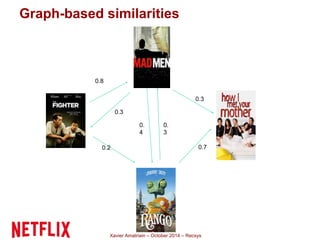




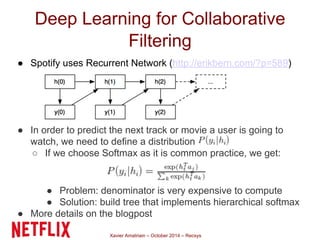











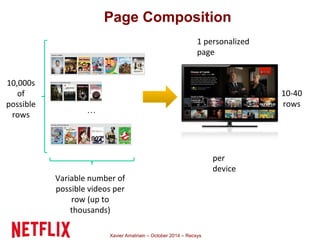
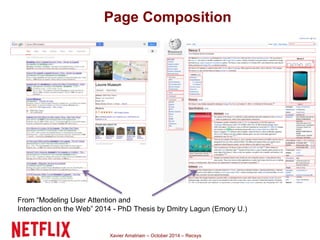

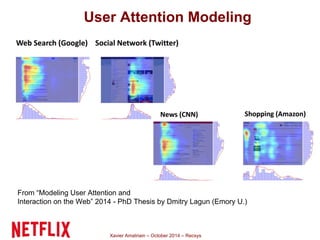



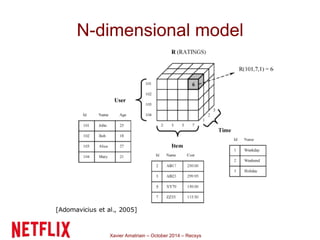
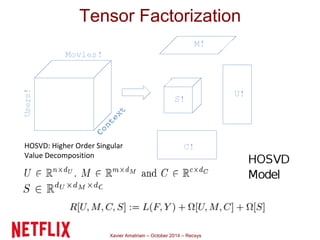





















This document summarizes Xavier Amatriain's presentation on recommender systems. It discusses traditional recommendation methods like collaborative filtering, content-based recommendations, and hybrid approaches. It also covers newer methods that go beyond traditional techniques, such as learning to rank, deep learning, social recommendations, and context-aware recommendations. Throughout the presentation, Amatriain discusses challenges like cold starts, popularity bias, and limitations of different recommendation approaches. He also shares lessons learned from the Netflix Prize competition, including how SVD and RBM models were used.









![[Phd Thesis Defense] CHAMELEON: A Deep Learning Meta-Architecture for News Re...](https://cdn.slidesharecdn.com/ss_thumbnails/chameleondefesadoutorado1-191209202516-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]Monaural Audio Source Separationusing Variational Autoencoders](https://cdn.slidesharecdn.com/ss_thumbnails/20190717dlmonauralaudiosourceseparationusingvariationalautoencodersver2-190719035345-thumbnail.jpg?width=640&height=640&fit=bounds)























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)





