Recommended
PPTX
PDF
PDF
JavaでCPUを使い倒す! ~Java 9 以降の CPU 最適化を覗いてみる~(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019...
PPT
PDF
知っておくべきCephのIOアクセラレーション技術とその活用方法 - OpenStack最新情報セミナー 2015年9月
PDF
知っているようで知らないNeutron -仮想ルータの冗長と分散- - OpenStack最新情報セミナー 2016年3月
PPTX
PDF
Yahoo!ニュースにおけるBFFパフォーマンスチューニング事例
PDF
PPTX
PDF
PDF
スケールアップファーストのNoSQL、ScyllaDB(スキュラDB)
PDF
Wireshark だけに頼らない! パケット解析ツールの紹介
PPTX
Apache BigtopによるHadoopエコシステムのパッケージング(Open Source Conference 2021 Online/Osaka...
ODP
tcpdumpとtcpreplayとtcprewriteと他。
PDF
Pythonはどうやってlen関数で長さを手にいれているの?
PDF
CyberAgentのインフラについて メディア事業編 #catechchallenge
PDF
Serf / Consul 入門 ~仕事を楽しくしよう~
PDF
OPcacheの新機能ファイルベースキャッシュの内部実装を読んでみた
PPT
PDF
20111015 勉強会 (PCIe / SR-IOV)
PPTX
トランザクションをSerializableにする4つの方法
PPTX
PDF
データインターフェースとしてのHadoop ~HDFSとクラウドストレージと私~ (NTTデータ テクノロジーカンファレンス 2019 講演資料、2019...
PDF
深層学習フレームワークにおけるIntel CPU/富岳向け最適化法
PDF
10分でわかる Cilium と XDP / BPF
PDF
PDF
エンジニアから都庁へ~中の人が語る街のDX、都庁のDX~
PDF
PDF
More Related Content
PPTX
PDF
PDF
JavaでCPUを使い倒す! ~Java 9 以降の CPU 最適化を覗いてみる~(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019...
PPT
PDF
知っておくべきCephのIOアクセラレーション技術とその活用方法 - OpenStack最新情報セミナー 2015年9月
PDF
知っているようで知らないNeutron -仮想ルータの冗長と分散- - OpenStack最新情報セミナー 2016年3月
PPTX
PDF
Yahoo!ニュースにおけるBFFパフォーマンスチューニング事例
What's hot
PDF
PPTX
PDF
PDF
スケールアップファーストのNoSQL、ScyllaDB(スキュラDB)
PDF
Wireshark だけに頼らない! パケット解析ツールの紹介
PPTX
Apache BigtopによるHadoopエコシステムのパッケージング(Open Source Conference 2021 Online/Osaka...
ODP
tcpdumpとtcpreplayとtcprewriteと他。
PDF
Pythonはどうやってlen関数で長さを手にいれているの?
PDF
CyberAgentのインフラについて メディア事業編 #catechchallenge
PDF
Serf / Consul 入門 ~仕事を楽しくしよう~
PDF
OPcacheの新機能ファイルベースキャッシュの内部実装を読んでみた
PPT
PDF
20111015 勉強会 (PCIe / SR-IOV)
PPTX
トランザクションをSerializableにする4つの方法
PPTX
PDF
データインターフェースとしてのHadoop ~HDFSとクラウドストレージと私~ (NTTデータ テクノロジーカンファレンス 2019 講演資料、2019...
PDF
深層学習フレームワークにおけるIntel CPU/富岳向け最適化法
PDF
10分でわかる Cilium と XDP / BPF
PDF
PDF
エンジニアから都庁へ~中の人が語る街のDX、都庁のDX~
Viewers also liked
PDF
PDF
PDF
cassandra 100 node cluster �admin operation
PDF
OpenVZ - Linux Containers:第2回 コンテナ型仮想化の情報交換会@東京
PPTX
Inside Sqale's Backend at Sapporo Ruby Kaigi 2012
PDF
Intel DPDK Step by Step instructions
PDF
PPTX
Similar to Seastar:高スループットなサーバアプリケーションの為の新しいフレームワーク
PPTX
Seastar in 歌舞伎座.tech#8「C++初心者会」
PDF
高スループットなサーバアプリケーションの為の新しいフレームワーク
「Seastar」
PDF
PDF
PDF
[DDBJing31] 軽量仮想環境を用いてNGSデータの解析再現性を担保する
PPT
PDF
20121119.dodai projectの紹介
PDF
Open stack reference architecture v1 2
PPT
PDF
PDF
OSvのご紹介 in
Java 8 HotSpot meeting
PDF
OSvのご紹介 in OSC2014 Tokyo/Fall
PPTX
Benchmark during different architecture cloud IBM z Systems vs Intel Xeon
PDF
PDF
PEZY-SC programming overview
PDF
PDF
Kernel vm study_2_xv6_scheduler_part1_revised
PDF
Data Center As A Computer 2章前半
PDF
PDF
More from Takuya ASADA
PDF
PDF
PDF
PDF
PDF
PDF
PDF
Presentation on your terminal
PDF
PDF
PDF
PDF
BHyVeでOSvを起動したい
〜BIOSがなくてもこの先生きのこるには〜
PDF
PDF
PDF
PDF
Implements BIOS emulation support for BHyVe: A BSD Hypervisor
PDF
PDF
PDF
PDF
PDF
Implements BIOS emulation support for BHyVe
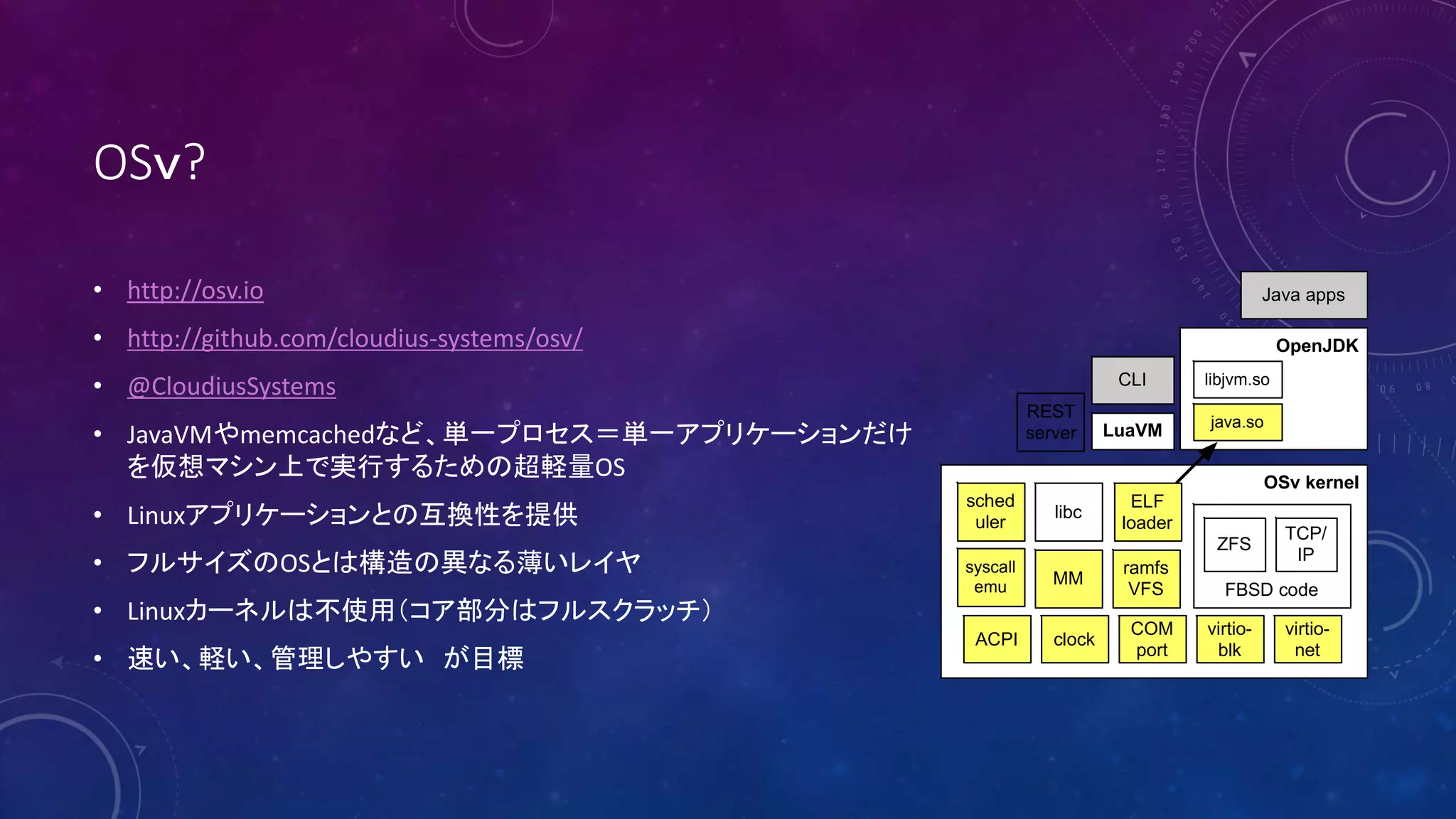
Seastar:高スループットなサーバアプリケーションの為の新しいフレームワーク 1. 2. 3. OSv?
• http://osv.io
• http://github.com/cloudius-systems/osv/
• @CloudiusSystems
• JavaVMやmemcachedなど、単一プロセス=単一アプリケーションだけ
を仮想マシン上で実行するための超軽量OS
• Linuxアプリケーションとの互換性を提供
• フルサイズのOSとは構造の異なる薄いレイヤ
• Linuxカーネルは不使用(コア部分はフルスクラッチ)
• 速い、軽い、管理しやすい が目標
OpenJDK
OSv kernel
FBSD code
ZFS
TCP/
IP
COM
port
virtio-
blk
virtio-
net
clockACPI
sched
uler
ramfs
VFS
MM
libc
ELF
loader
syscall
emu
libjvm.so
java.so
Java apps
LuaVM
CLI
REST
server
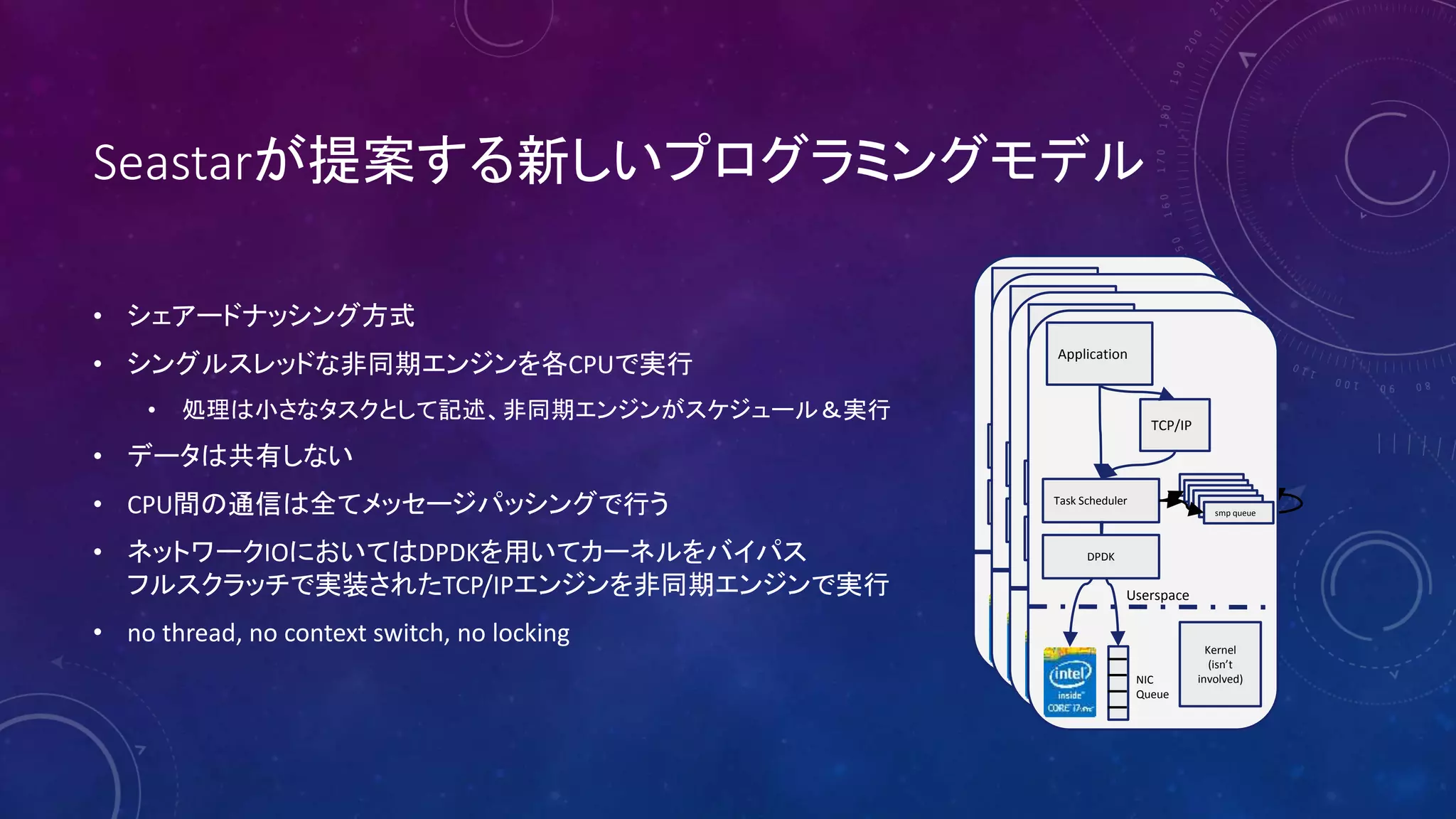
4. 5. 6. 7. 8. Seastarが提案する新しいプログラミングモデル
• シェアードナッシング方式
• シングルスレッドな非同期エンジンを各CPUで実行
• 処理は小さなタスクとして記述、非同期エンジンがスケジュール&実行
• データは共有しない
• CPU間の通信は全てメッセージパッシングで行う
• ネットワークIOにおいてはDPDKを用いてカーネルをバイパス
フルスクラッチで実装されたTCP/IPエンジンを非同期エンジンで実行
• no thread, no context switch, no locking
Application
TCP/IP
Task Scheduler
queuequeuequeuequeuequeuesmp queue
NIC
Queue
DPDK
Kernel
(isn’t
involved)
Userspace
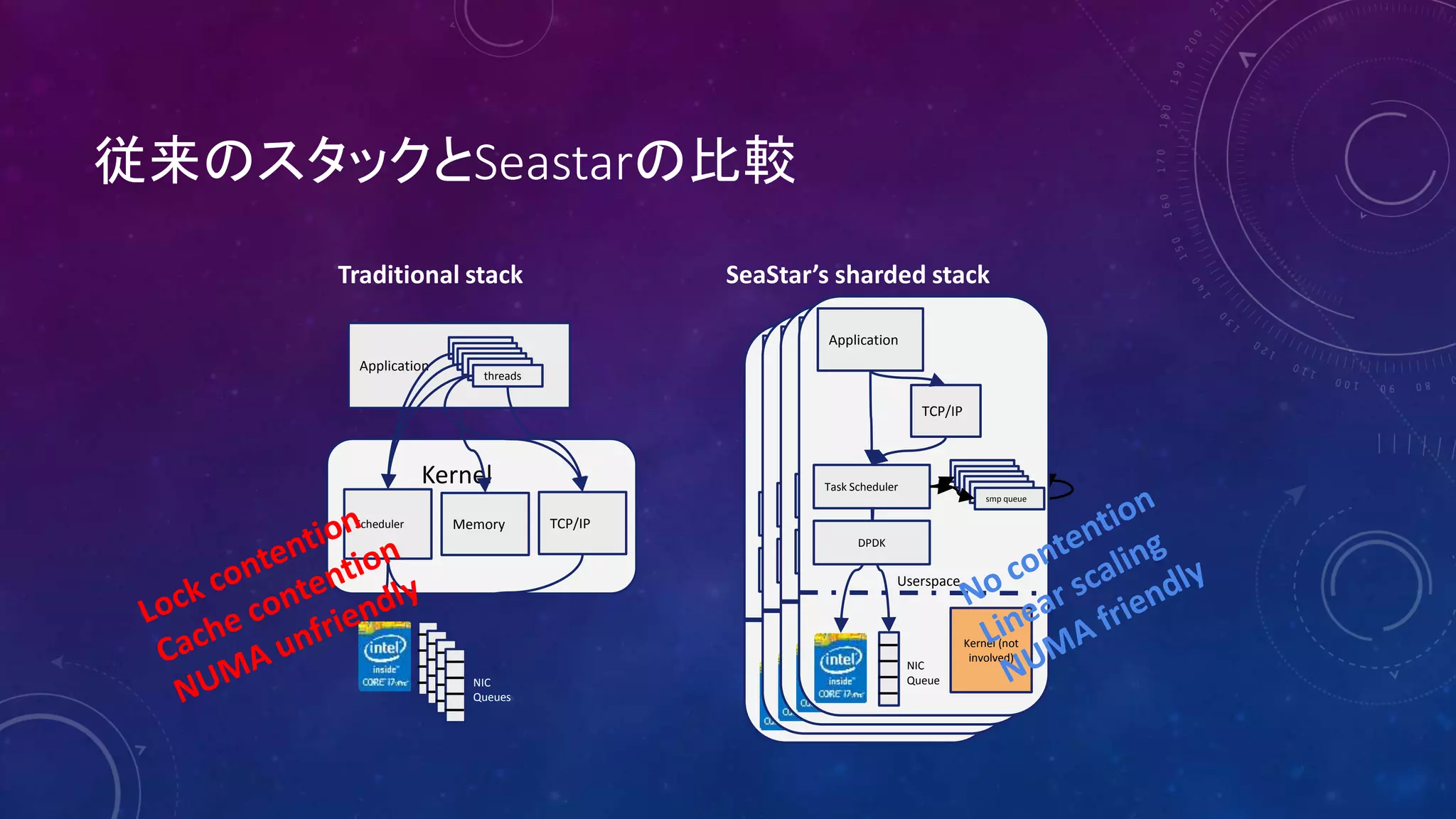
Application
TCP/IP
Task Scheduler
queuequeuequeuequeuequeuesmp queue
NIC
Queue
DPDK
Kernel
(isn’t
involved)
Userspace
Application
TCP/IP
Task Scheduler
queuequeuequeuequeuequeuesmp queue
NIC
Queue
DPDK
Kernel
(isn’t
involved)
Userspace
Application
TCP/IP
Task Scheduler
queuequeuequeuequeuequeuesmp queue
NIC
Queue
DPDK
Kernel
(isn’t
involved)
Userspace
9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 簡単なfuture/promiseの例
future<int> get(); // 最終的にintが生成される事をpromiseする
future<> put(int) // intを入力する事をpromiseする
void f() {
get().then([] (int value) { // .then()でget()が実行完了した時の処理をラムダ式で定義
put(value + 1).then([] { // .then()でput(int)が完了した時の処理をラムダ式で定義
std::cout << “value stored successfullyn”; // put(value+1)が完了したらstdoutにメッセージ出力
});
});
}
19. Continuation
future<int> get(); // 最終的にintが生成される事をpromiseする
future<> put(int) // intを入力する事をpromiseする
void f() {
get().then([] (int value) {// .then()でget()が実行完了した時の処理をラムダ式で定義
return put(value + 1); // put()はfutureなのでputが実行完了するまでこのラムダ式は終了しない
}).then([] {// .then()でget().then()が実行完了した時の処理をラムダ式で定義
std::cout << "value stored successfullyn";
});
}
20. UDP Server
ipv4_addr listen_addr{port};
chan = engine().net().make_udp_channel(listen_addr);
keep_doing([this] {
return chan.receive().then([this] (udp_datagram dgram) {
return chan.send(dgram.get_src(), std::move(dgram.get_data())).then([this] {
n_sent++;
});
});
});
21. TCP Server
engine().listen(make_ipv4_address(addr), lo).accept().then([this, which] (connected_socket fd, socket_address addr) mutable {
input_stream<char> read_buf(fd.input());
output_stream<char> write_buf(fd.output());
return read_buf.read_exactly(4).then([this] (temporary_buffer<char> buf) {
auto cmd = std::string(buf.get(), buf.size());
if (cmd == str_a) {
return do_something_a();
}else if(cmd == str_b) {
return do_something_b();
}
});
});
22. Exception handling
void f() {
receive().then([] (buffer buf) {
return process(parse(std::move(buf));
}).rescue([] (auto get_ex) {
try {
get_ex();
} (catch std::exception& e) {
// your handler goes here
}
});
}
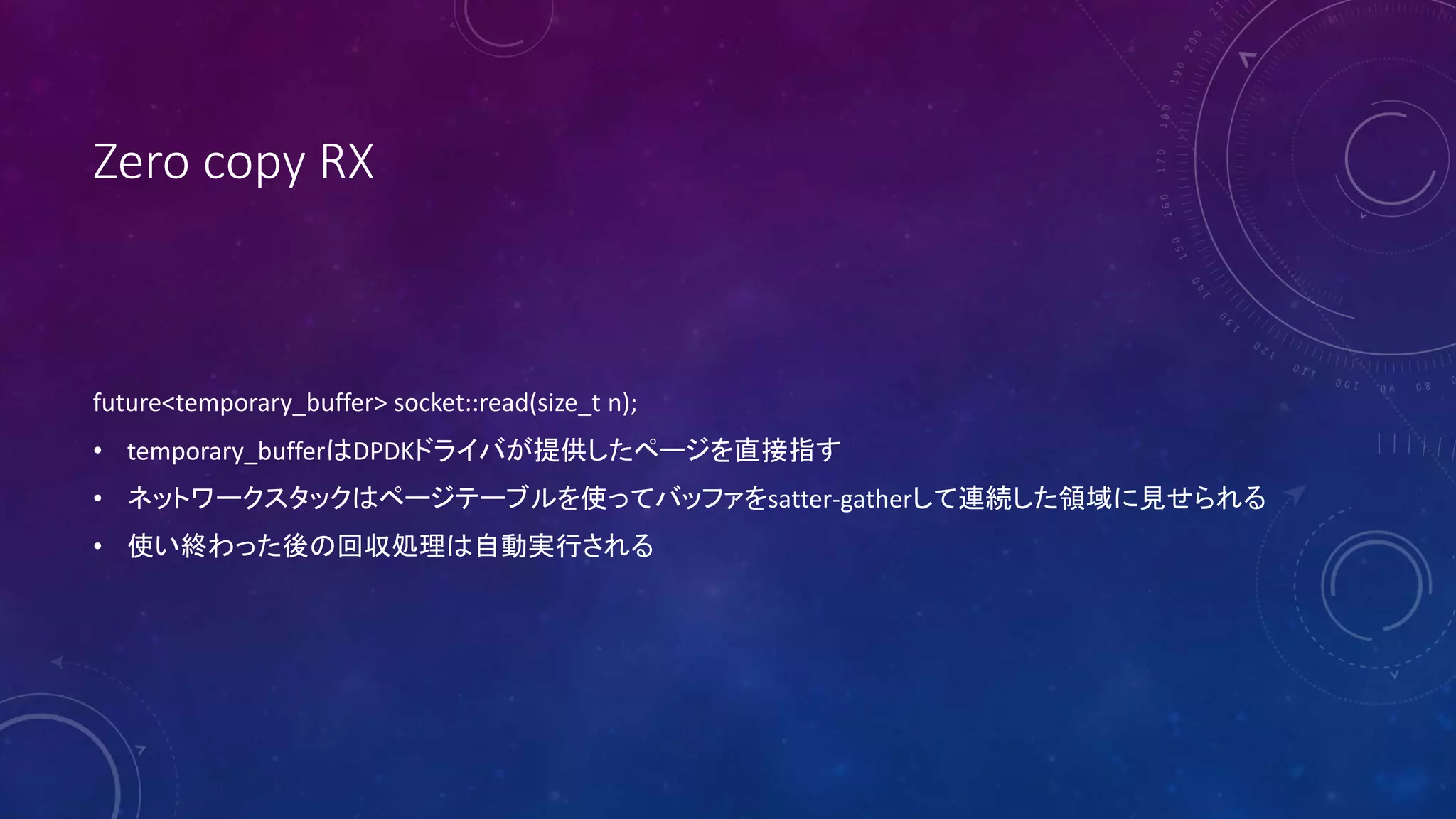
23. 24. Zero copy TX
pair<future<size_t>, future<temporary_buffer>> socket::write(temporary_buffer);
• 最初のfutureはTCPウインドウがデータ送信可能な状態になったらreadyになる
• 次のfutureはバッファが解放可能になったらreadyになる
• どの順序でcompleteしても問題無い
25. 複数CPUで実行
auto server = new distributed<udp_server>;
server->start().then([server = std::move(server), port] () mutable {
server->invoke_on_all(&udp_server::start, port);
}).then([port] {
std::cout << "Seastar UDP server listening on port " << port << " ...n";
});
26. 27. 28. 29. 30. どこがタスクになるのか
engine().listen(make_ipv4_address(addr), lo).accept().then([this, which] (connected_socket fd, socket_address addr) mutable {
input_stream<char> read_buf(fd.input());
output_stream<char> write_buf(fd.output());
return read_buf.read_exactly(4).then([this] (temporary_buffer<char> buf) {
auto cmd = std::string(buf.get(), buf.size());
if (cmd == str_a) {
return do_something_a();
}else if(cmd == str_b) {
return do_something_b();
}
});
});
丸で囲った部分(then()に渡されるfutureの部分)がそれぞれランキューに登録される
31. 32. 33. 34. 35. 36. 37. 選べる実行環境
• OS
• Linux on baremetal
• Linux on VM
• OSv on VM
• ネットワークバックエンド
• DPDK + Seastarネットワークスタック
• vhost-net + Seastarネットワークスタック
• Xen + Seastarネットワークスタック
• OSのネットワークスタック(ソケットAPI)
• ブロックバックエンド
• OSのファイルシステム
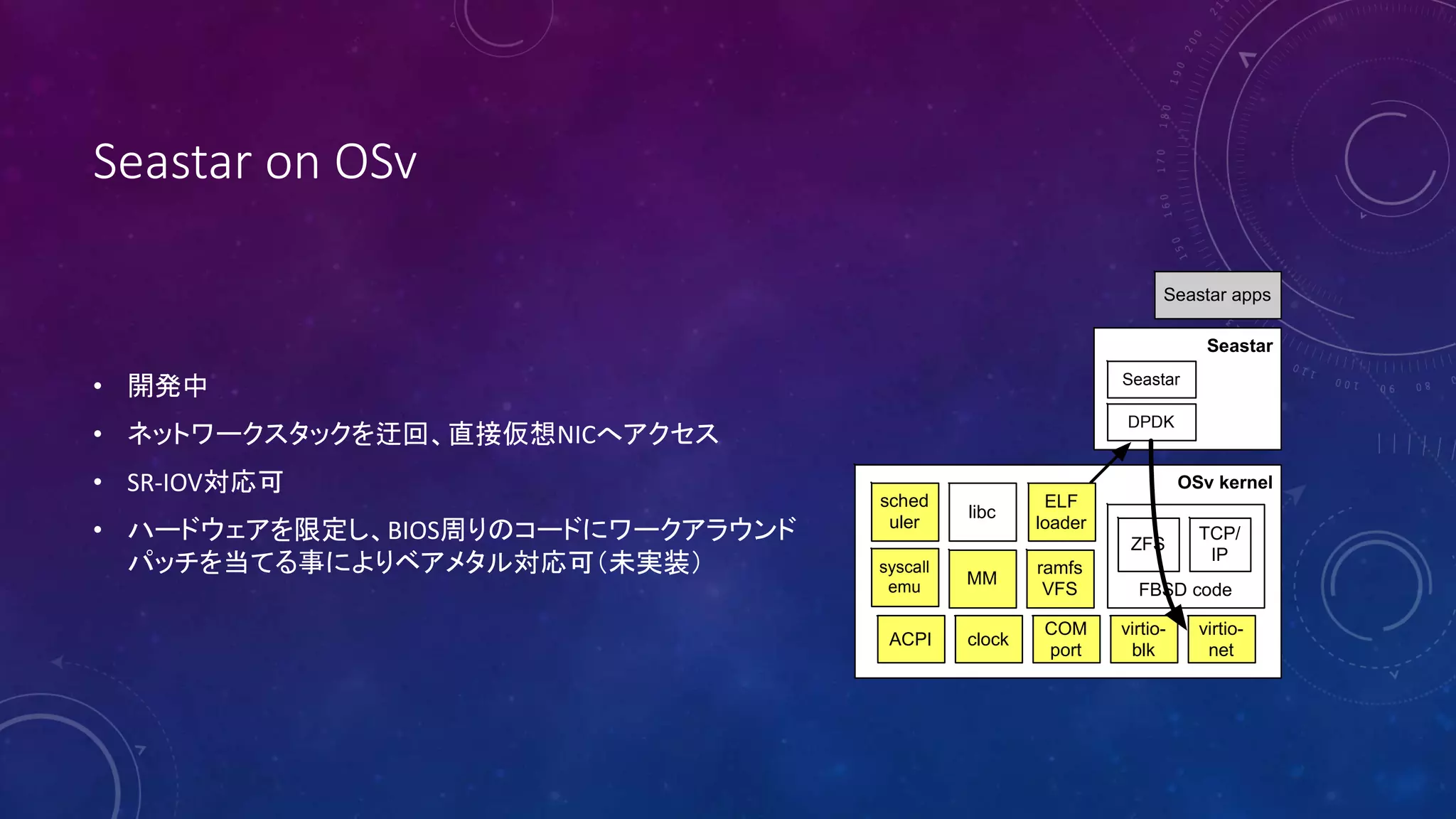
38. Seastar on OSv
• 開発中
• ネットワークスタックを迂回、直接仮想NICへアクセス
• SR-IOV対応可
• ハードウェアを限定し、BIOS周りのコードにワークアラウンド
パッチを当てる事によりベアメタル対応可(未実装)
Seastar
OSv kernel
FBSD code
ZFS
TCP/
IP
COM
port
virtio-
blk
virtio-
net
clockACPI
sched
uler
ramfs
VFS
MM
libc
ELF
loader
syscall
emu
Seastar
DPDK
Seastar apps
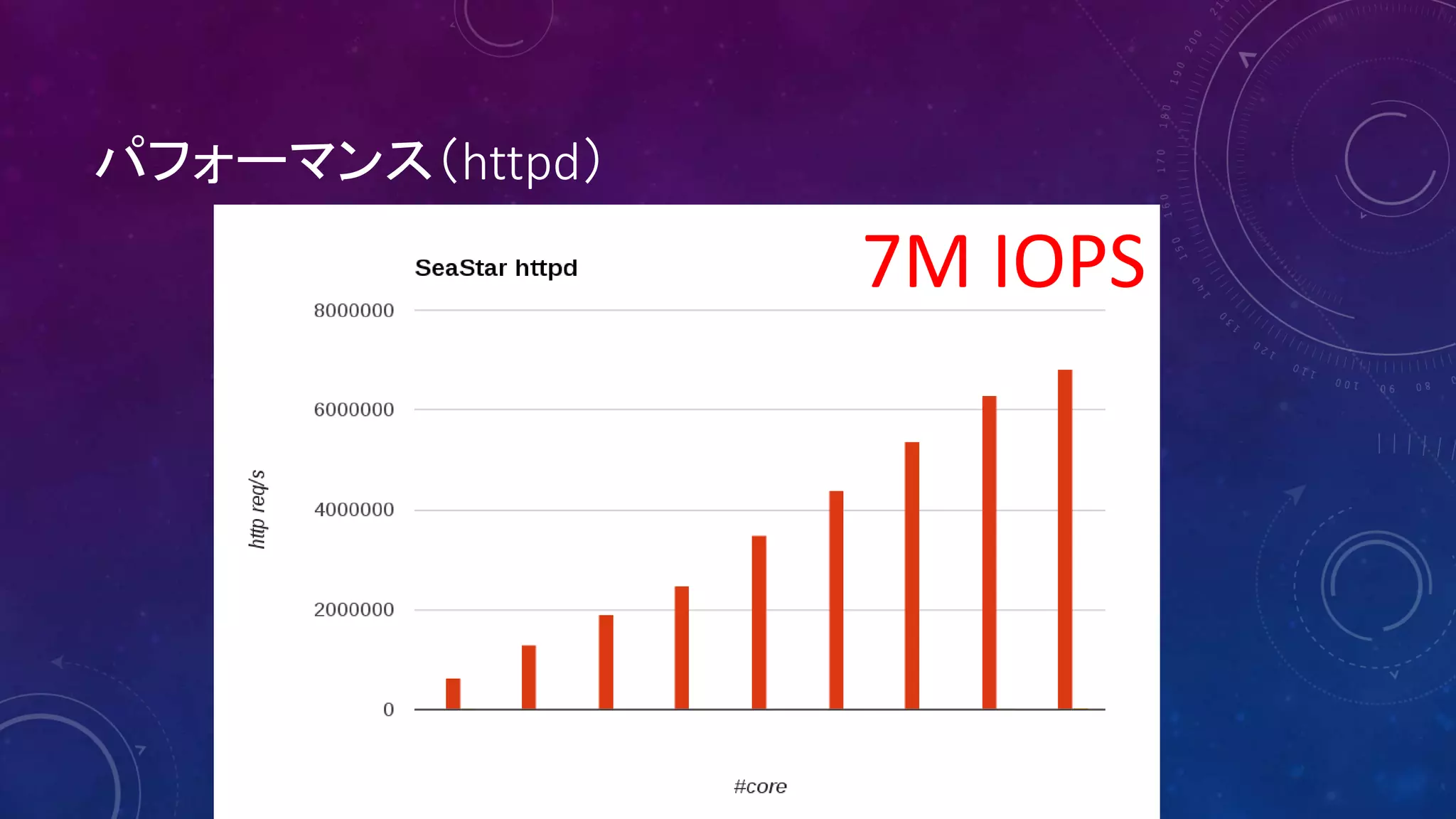
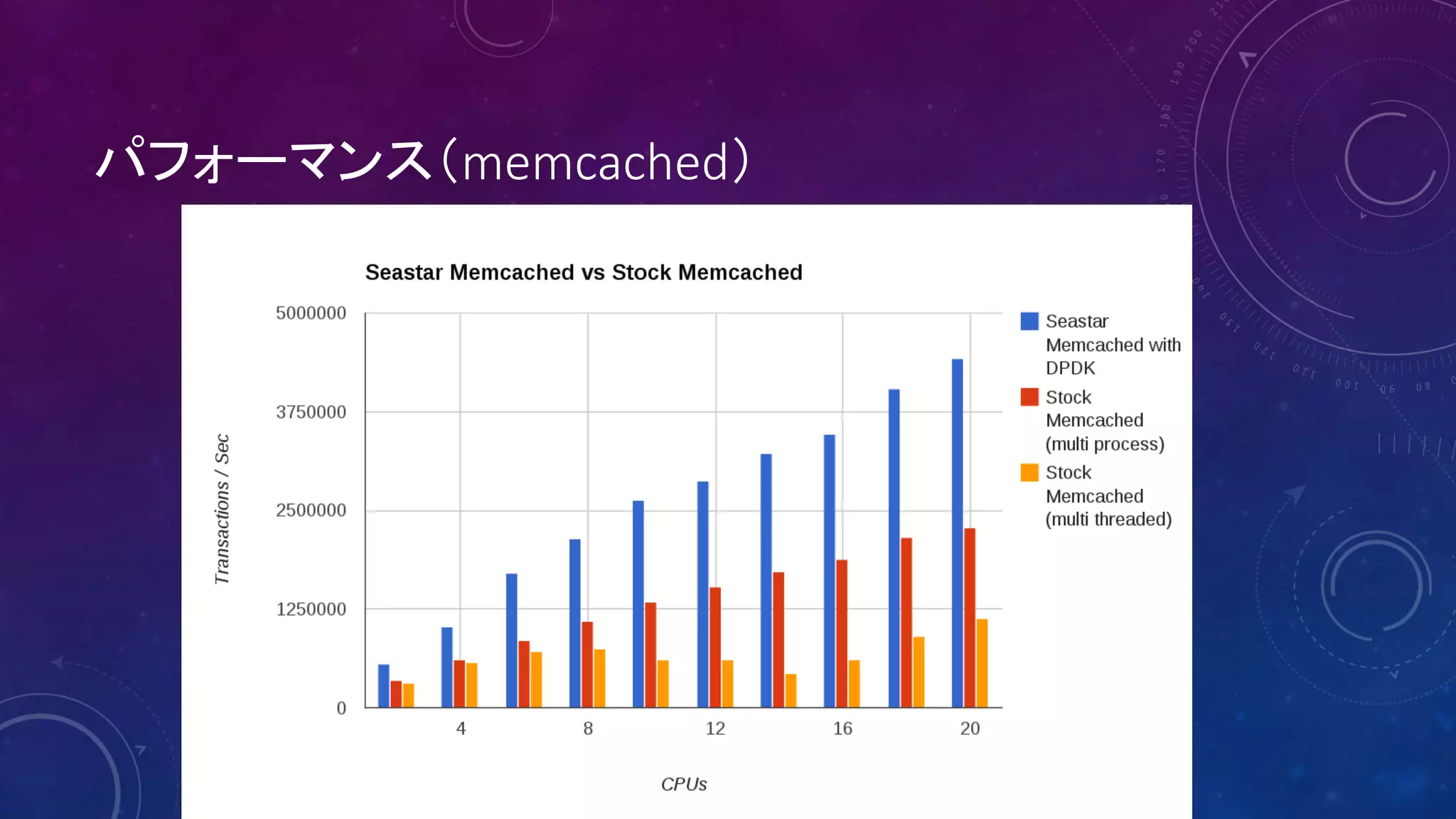
39. 40. 41. 42. ベンチマーク環境
■ 2x Xeon E5-2695v3, 2.3GHz
35M cache, 14 cores
(28 cores total, 56 HT)
■ 8x 8 = 64 GB DDR4 Micron memory
■ Intel Ethernet CNA XL710-QDA1(10GbE/40GbE)
43. 44. 45. 46.















![簡単なfuture/promiseの例
future<int> get(); // 最終的にintが生成される事をpromiseする
future<> put(int) // intを入力する事をpromiseする
void f() {
get().then([] (int value) { // .then()でget()が実行完了した時の処理をラムダ式で定義
put(value + 1).then([] { // .then()でput(int)が完了した時の処理をラムダ式で定義
std::cout << “value stored successfullyn”; // put(value+1)が完了したらstdoutにメッセージ出力
});
});
}](https://image.slidesharecdn.com/seastar-150409062602-conversion-gate01/75/Seastar-18-2048.jpg)
![Continuation
future<int> get(); // 最終的にintが生成される事をpromiseする
future<> put(int) // intを入力する事をpromiseする
void f() {
get().then([] (int value) {// .then()でget()が実行完了した時の処理をラムダ式で定義
return put(value + 1); // put()はfutureなのでputが実行完了するまでこのラムダ式は終了しない
}).then([] {// .then()でget().then()が実行完了した時の処理をラムダ式で定義
std::cout << "value stored successfullyn";
});
}](https://image.slidesharecdn.com/seastar-150409062602-conversion-gate01/75/Seastar-19-2048.jpg)
![UDP Server
ipv4_addr listen_addr{port};
chan = engine().net().make_udp_channel(listen_addr);
keep_doing([this] {
return chan.receive().then([this] (udp_datagram dgram) {
return chan.send(dgram.get_src(), std::move(dgram.get_data())).then([this] {
n_sent++;
});
});
});](https://image.slidesharecdn.com/seastar-150409062602-conversion-gate01/75/Seastar-20-2048.jpg)
![TCP Server
engine().listen(make_ipv4_address(addr), lo).accept().then([this, which] (connected_socket fd, socket_address addr) mutable {
input_stream<char> read_buf(fd.input());
output_stream<char> write_buf(fd.output());
return read_buf.read_exactly(4).then([this] (temporary_buffer<char> buf) {
auto cmd = std::string(buf.get(), buf.size());
if (cmd == str_a) {
return do_something_a();
}else if(cmd == str_b) {
return do_something_b();
}
});
});](https://image.slidesharecdn.com/seastar-150409062602-conversion-gate01/75/Seastar-21-2048.jpg)
![Exception handling
void f() {
receive().then([] (buffer buf) {
return process(parse(std::move(buf));
}).rescue([] (auto get_ex) {
try {
get_ex();
} (catch std::exception& e) {
// your handler goes here
}
});
}](https://image.slidesharecdn.com/seastar-150409062602-conversion-gate01/75/Seastar-22-2048.jpg)

![複数CPUで実行
auto server = new distributed<udp_server>;
server->start().then([server = std::move(server), port] () mutable {
server->invoke_on_all(&udp_server::start, port);
}).then([port] {
std::cout << "Seastar UDP server listening on port " << port << " ...n";
});](https://image.slidesharecdn.com/seastar-150409062602-conversion-gate01/75/Seastar-25-2048.jpg)
![CPU間通信
smp::submit_to(neighbor, [key] {
return local_database[key];
}).then([key, neighbor] (sstring value) {
print(“The value of key %s on shard %d is %sn”, key, neighbor, value);
});](https://image.slidesharecdn.com/seastar-150409062602-conversion-gate01/75/Seastar-26-2048.jpg)



![どこがタスクになるのか
engine().listen(make_ipv4_address(addr), lo).accept().then([this, which] (connected_socket fd, socket_address addr) mutable {
input_stream<char> read_buf(fd.input());
output_stream<char> write_buf(fd.output());
return read_buf.read_exactly(4).then([this] (temporary_buffer<char> buf) {
auto cmd = std::string(buf.get(), buf.size());
if (cmd == str_a) {
return do_something_a();
}else if(cmd == str_b) {
return do_something_b();
}
});
});
丸で囲った部分(then()に渡されるfutureの部分)がそれぞれランキューに登録される](https://image.slidesharecdn.com/seastar-150409062602-conversion-gate01/75/Seastar-30-2048.jpg)





















































![[DDBJing31] 軽量仮想環境を用いてNGSデータの解析再現性を担保する](https://cdn.slidesharecdn.com/ss_thumbnails/31ddbjingohta-150626022623-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


































