Download to read offline



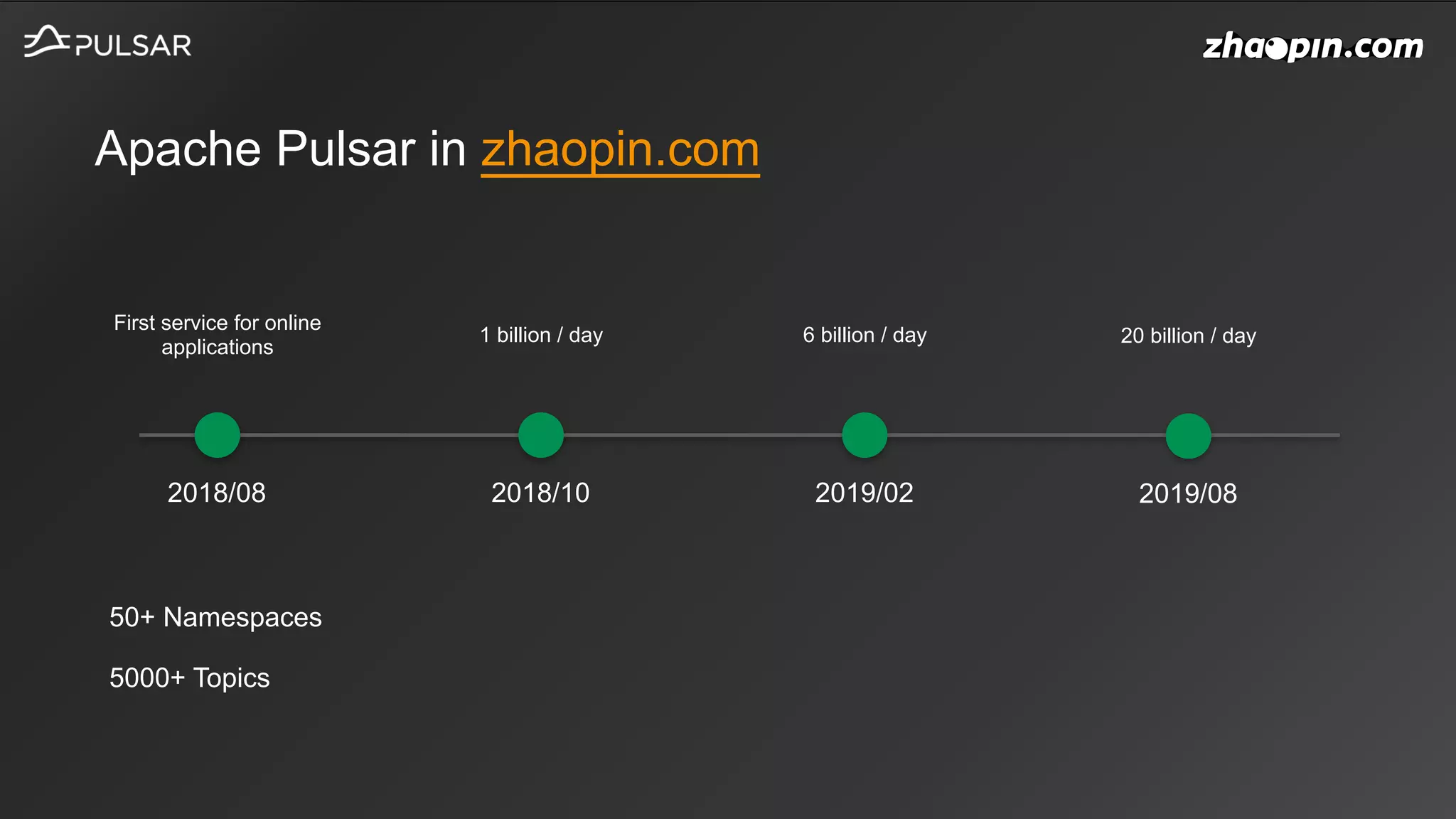


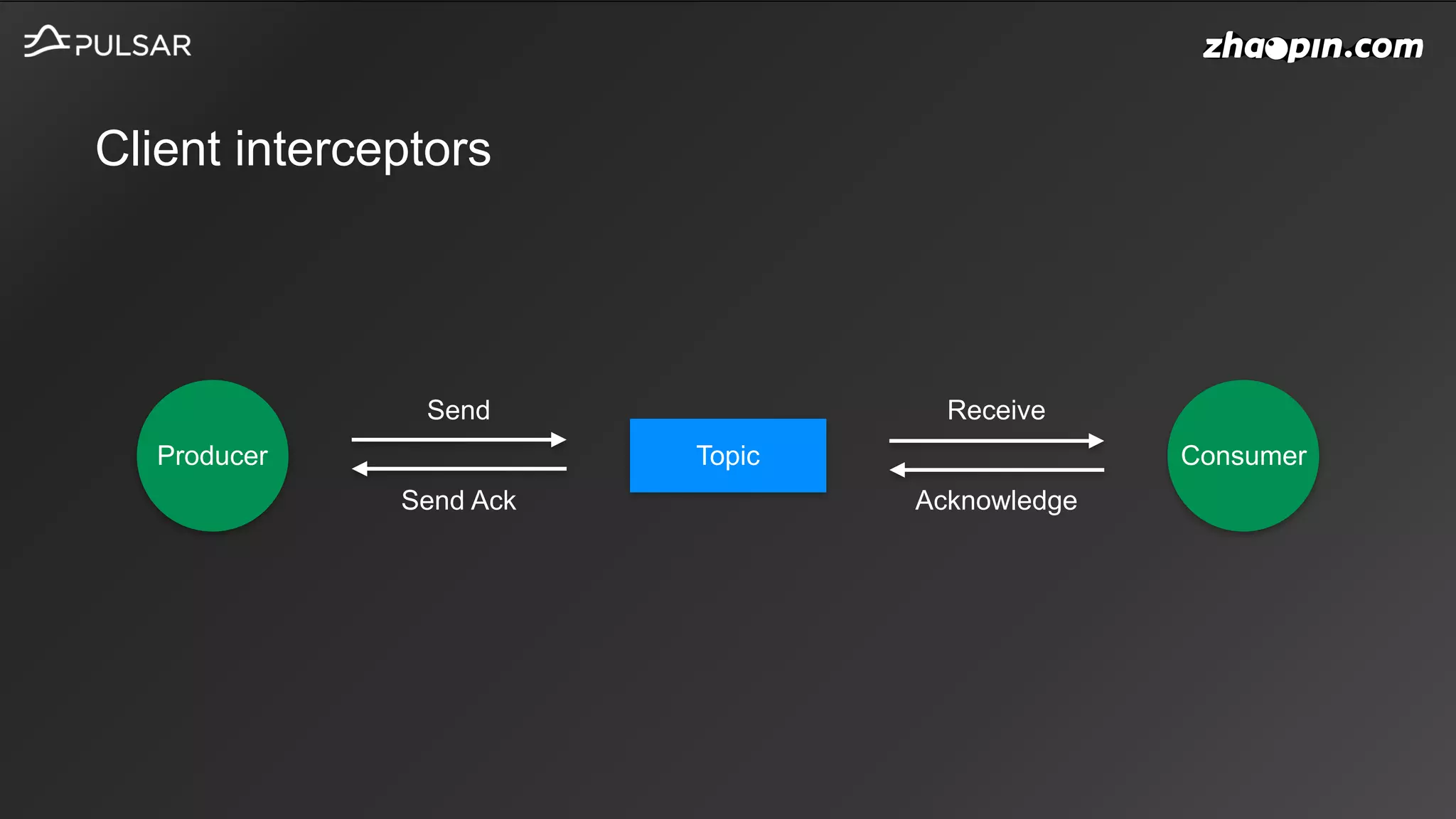
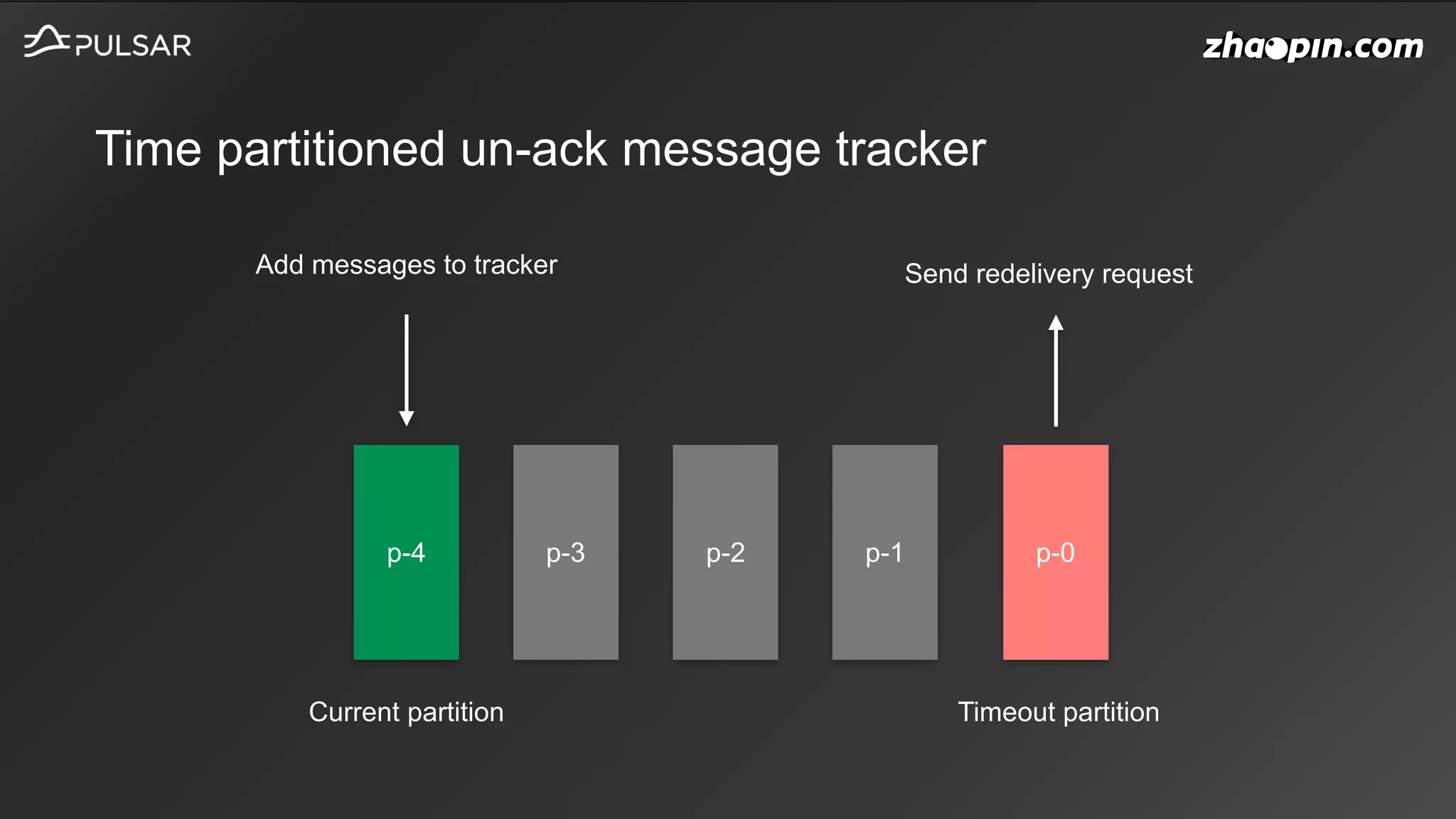

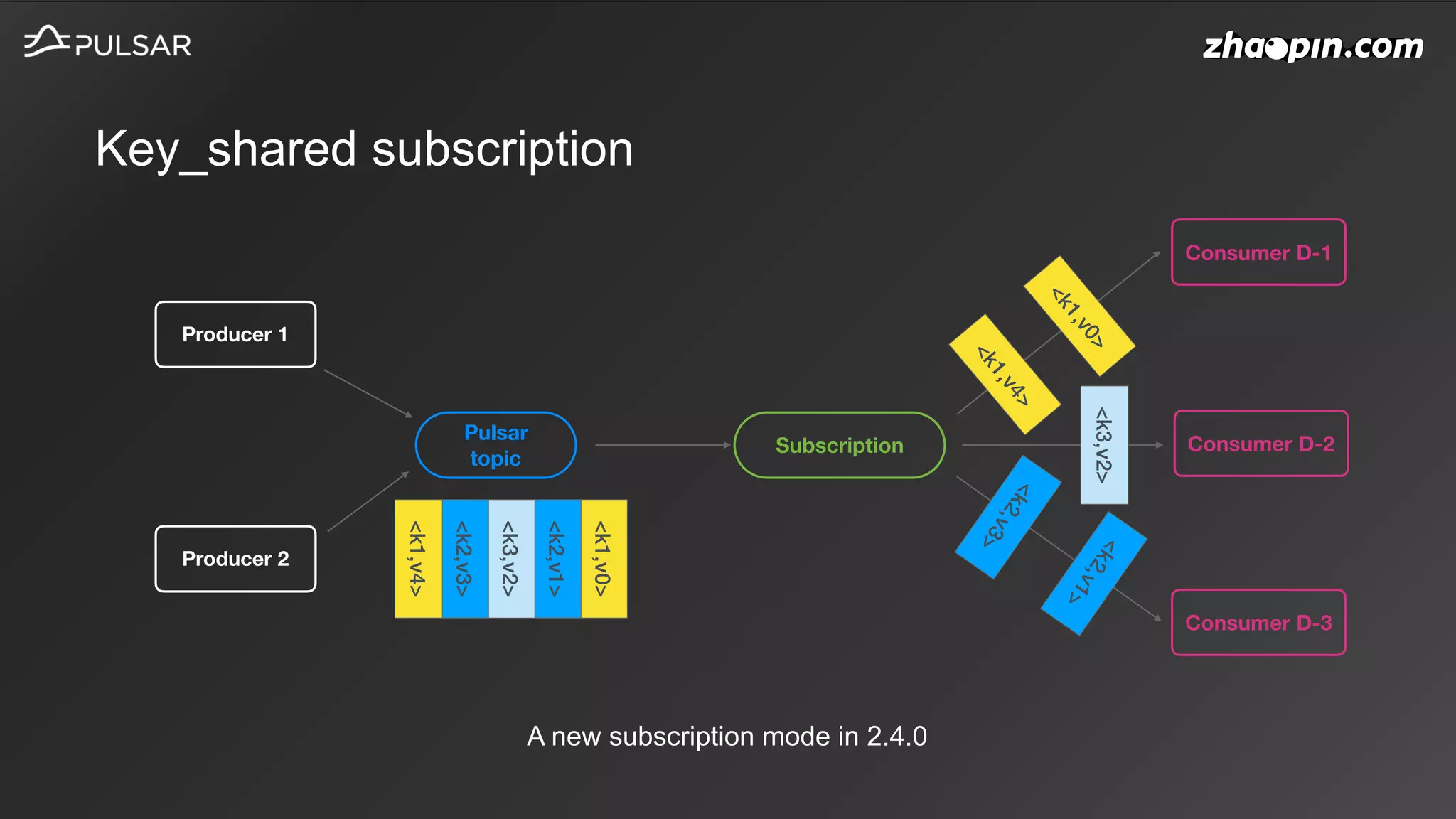




















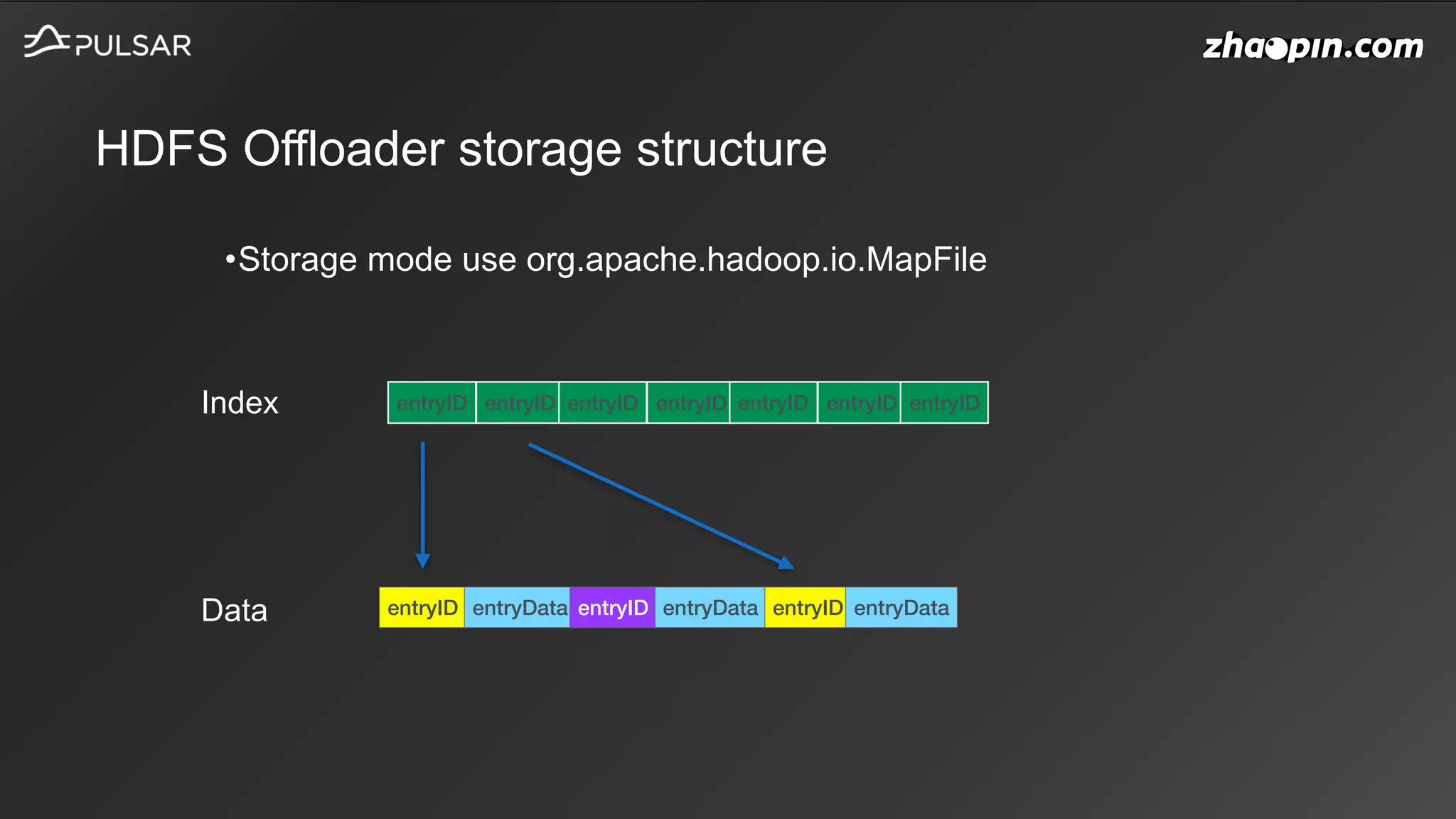



This document discusses Apache Pulsar usage in Zhaopin and some key features: 1. It provides an overview of how Pulsar is used in Zhaopin and the increasing message throughput over time. 2. It describes several Pulsar features in detail, including key-shared subscriptions, schema versioning, HDFS offloading, and upcoming topics like policies and sticky consumers. 3. It discusses the Pulsar community contributions from the Zhaopin team, including details on key-shared subscriptions, schema version handling, HDFS offloader storage, and other improvements.






















































































