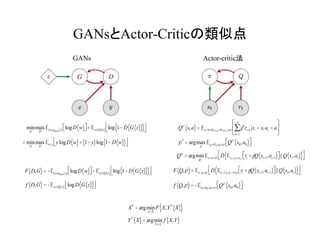
GANsとActor-Criticの類似点
min
G
max
D
Ew»pdata x( )logD w( )éë ùû+ Ez»N 0,1( ) log 1- D G z( )( )( )é
ë
ù
û
= min
G
max
D
Ew,y ylogD w( )+ 1- y( )log 1- D w( )( )é
ë
ù
û
F D,G( )= -Ew»pdata x( ) logD w( )éë ùû- Ez»N 0,1( ) log 1- D G z( )( )( )é
ë
ù
û
f D,G( )= -Ez»N 0,1( ) logD G z( )( )é
ë
ù
û
X*
= argmin
xÎÀ
F X,Y*
X( )( )
Y*
X( )= argmin
YΡ
f X,Y( )
F Q,p( )= Est ,at »p D Est+1,rt,at+1»p rt +gQ st+1,at+1( )éë ùû||Q st,at( )( )é
ë
ù
û
f Q,p( )= -Es0»p0,a0»p Qp
s0,a0( )éë ùû
Qp
s,a( )= Est+k»R,rt+k »R,at+k »p gk
rt+k
k=1
¥
å st = s,at = a
é
ë
ê
ù
û
ú
p*
= argmax
p
Es0 »R0,a0»p Qp
s0,a0( )éë ùû
Qp
= argmin
Q
Est,at »p D Est+1,rt,at+1
rt +gQ st+1,at+1( )éë ùû||Q st,at( )( )é
ë
ù
û
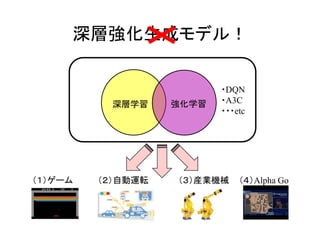
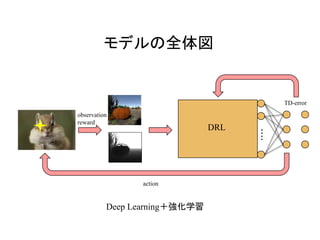
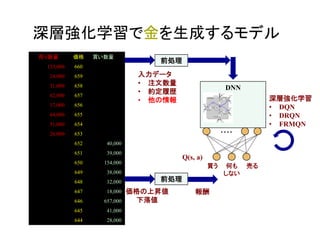
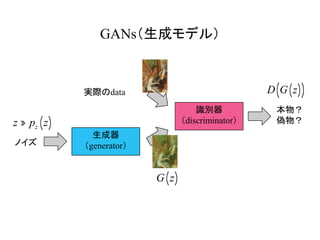
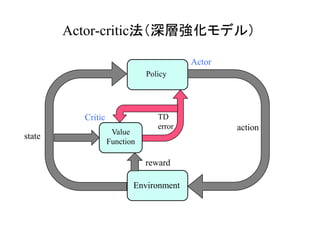
GANs Actor-critic法
26.
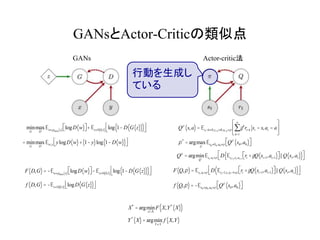
GANsとActor-Criticの類似点
min
G
max
D
Ew»pdata x( )logD w( )éë ùû+ Ez»N 0,1( ) log 1- D G z( )( )( )é
ë
ù
û
= min
G
max
D
Ew,y ylogD w( )+ 1- y( )log 1- D w( )( )é
ë
ù
û
F D,G( )= -Ew»pdata x( ) logD w( )éë ùû- Ez»N 0,1( ) log 1- D G z( )( )( )é
ë
ù
û
f D,G( )= -Ez»N 0,1( ) logD G z( )( )é
ë
ù
û
X*
= argmin
xÎÀ
F X,Y*
X( )( )
Y*
X( )= argmin
YΡ
f X,Y( )
F Q,p( )= Est ,at »p D Est+1,rt,at+1»p rt +gQ st+1,at+1( )éë ùû||Q st,at( )( )é
ë
ù
û
f Q,p( )= -Es0»p0,a0»p Qp
s0,a0( )éë ùû
Qp
s,a( )= Est+k»R,rt+k »R,at+k »p gk
rt+k
k=1
¥
å st = s,at = a
é
ë
ê
ù
û
ú
p*
= argmax
p
Es0 »R0,a0»p Qp
s0,a0( )éë ùû
Qp
= argmin
Q
Est,at »p D Est+1,rt,at+1
rt +gQ st+1,at+1( )éë ùû||Q st,at( )( )é
ë
ù
û
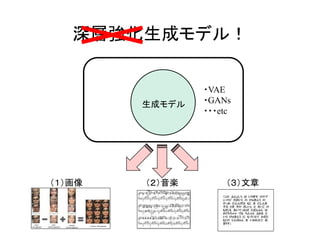
GANs Actor-critic法
行動を生成し
ている























![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
































