
















![Solr Performance Issue: Query Time Sorting
q=sortfield["666" TO *]&rows=10
Will sort ALL of the sortfield values at Query Time
Response time abysmal for sortfields
with huge numbers of values
Try this: Terms Component
Lucid Imagination, Inc. – http://www.lucidimagination.com
21](https://image.slidesharecdn.com/li-webinar-practical-search-with-solr-100518013159-phpapp02/75/Practical-Search-with-Solr-Beyond-just-Looking-it-Up-21-2048.jpg)





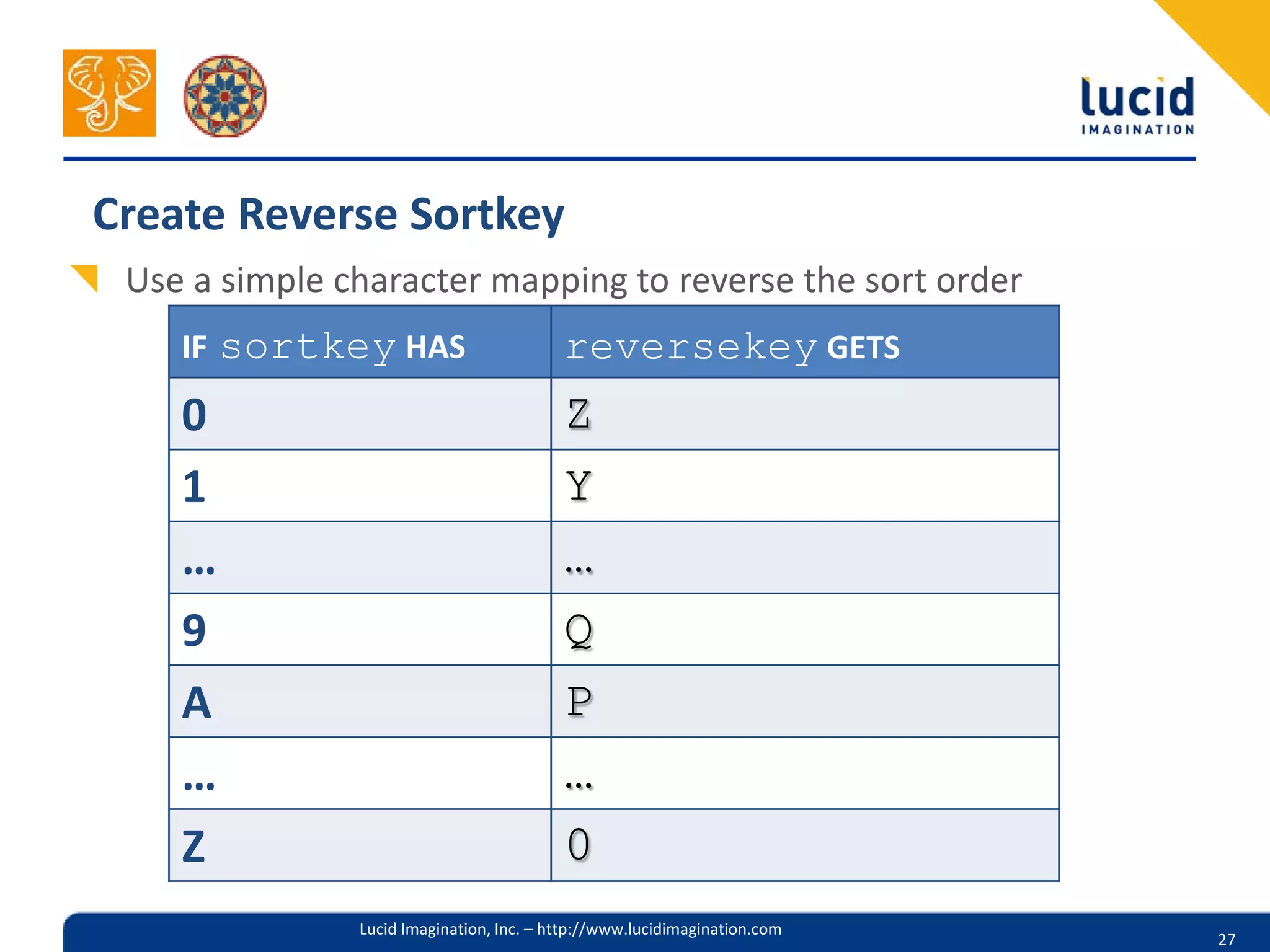



















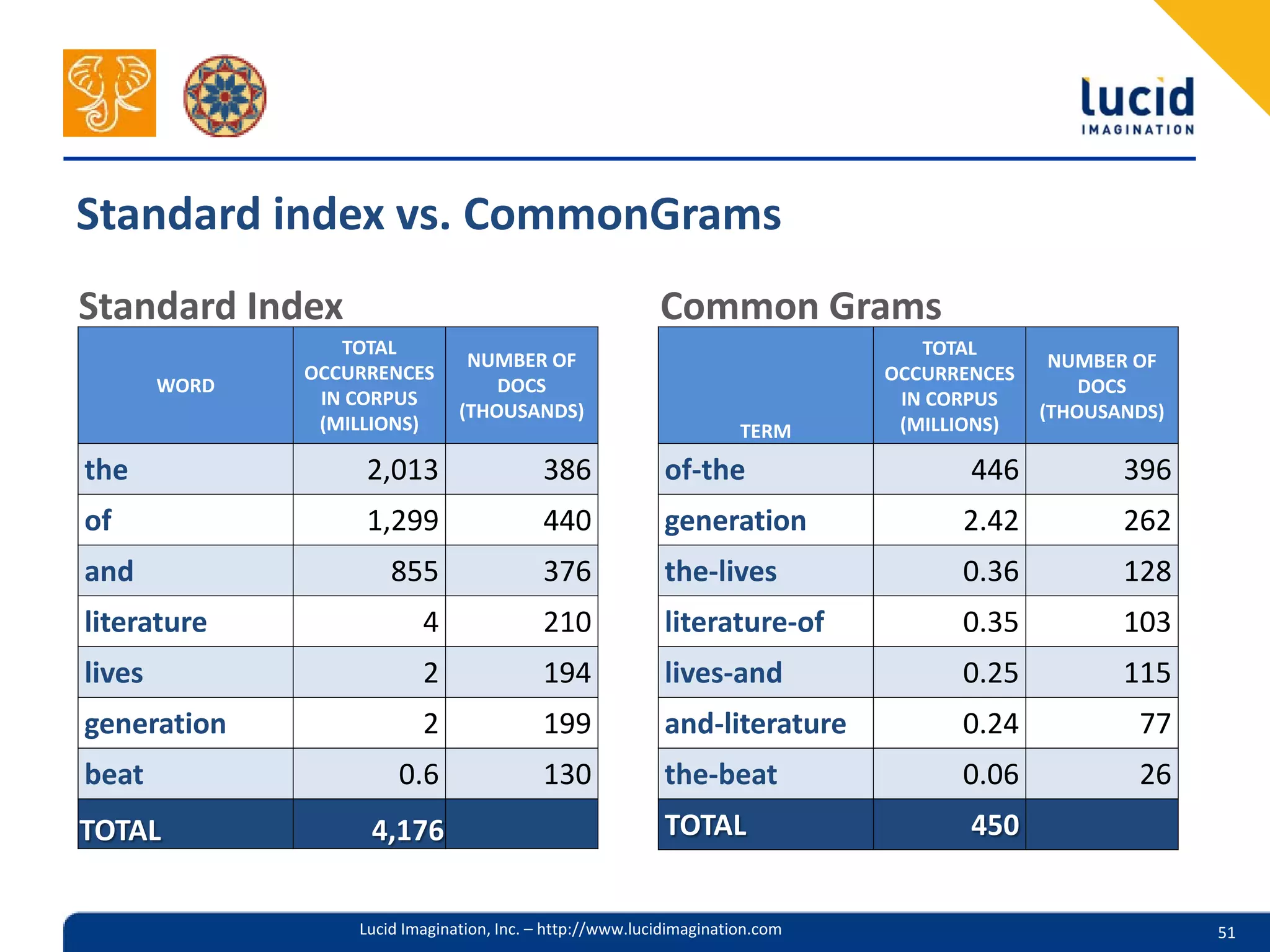
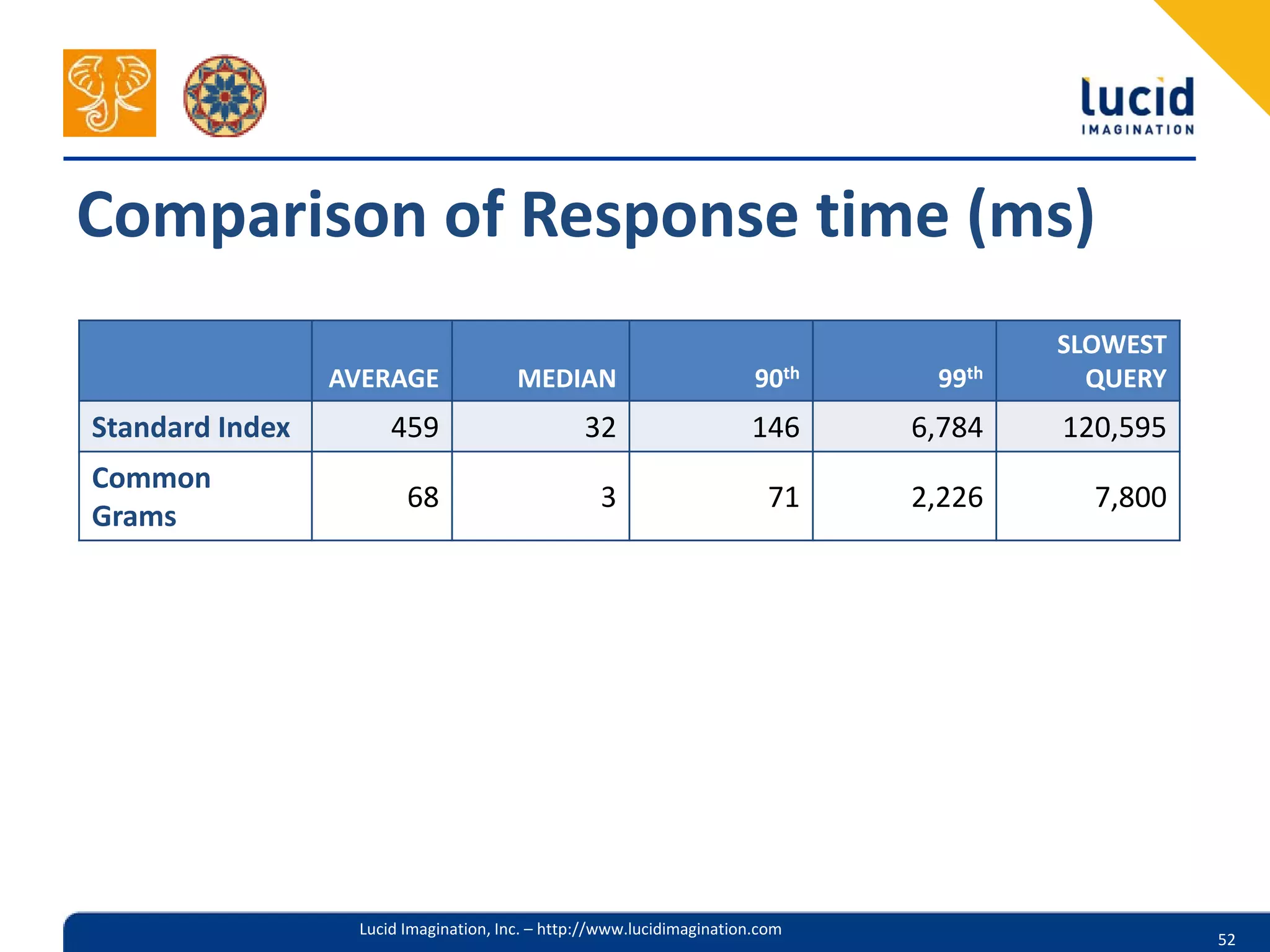




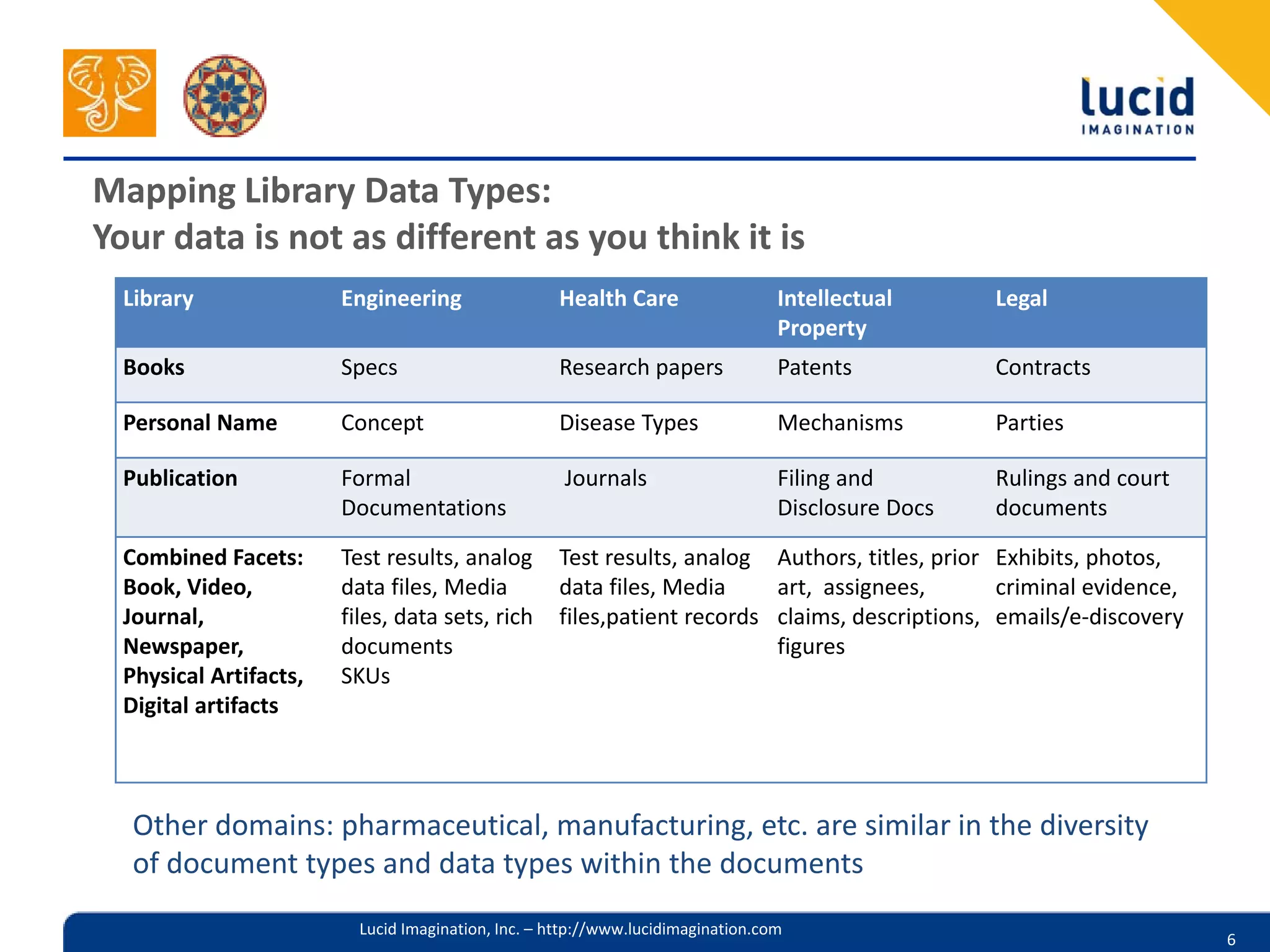
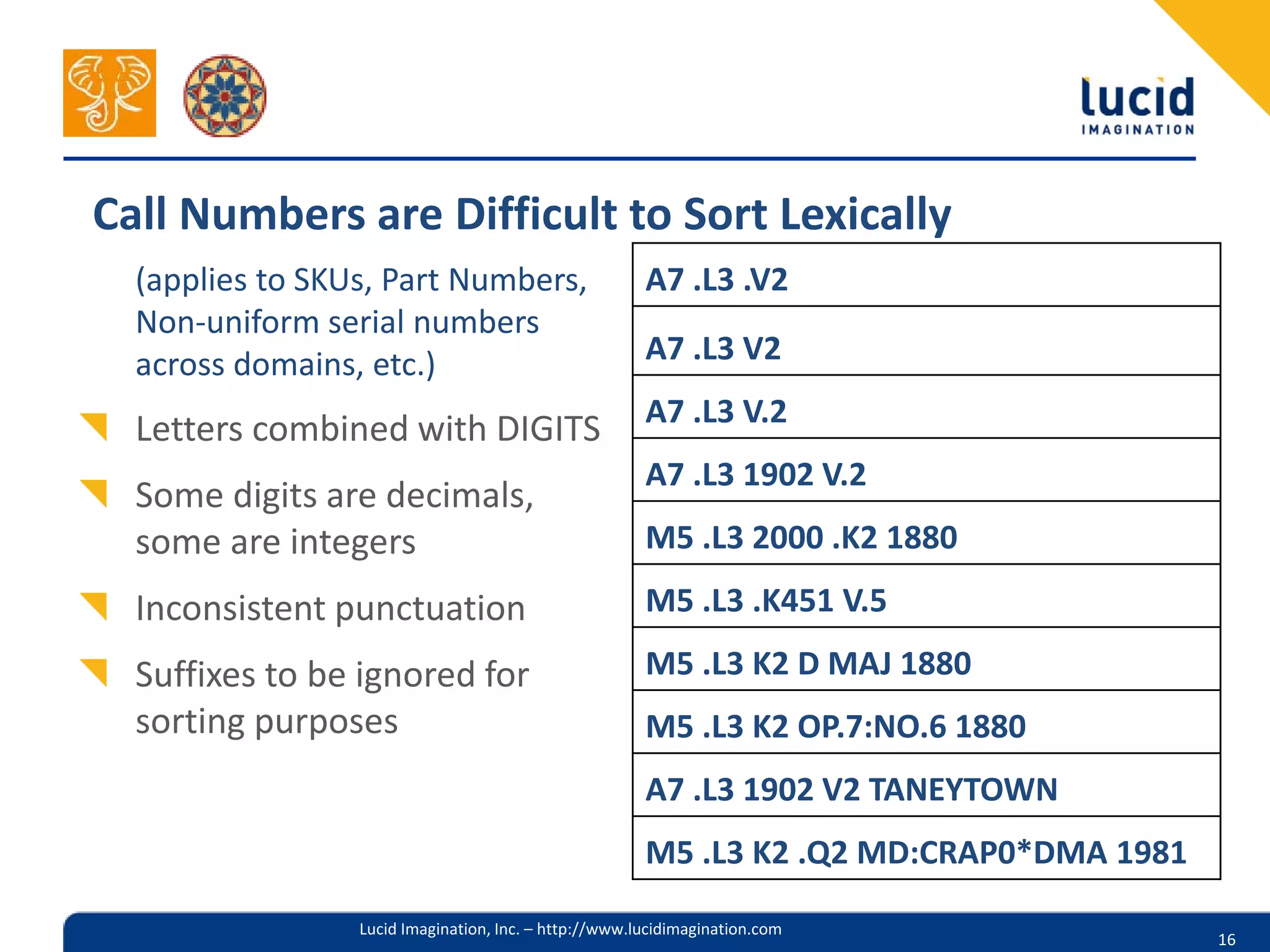
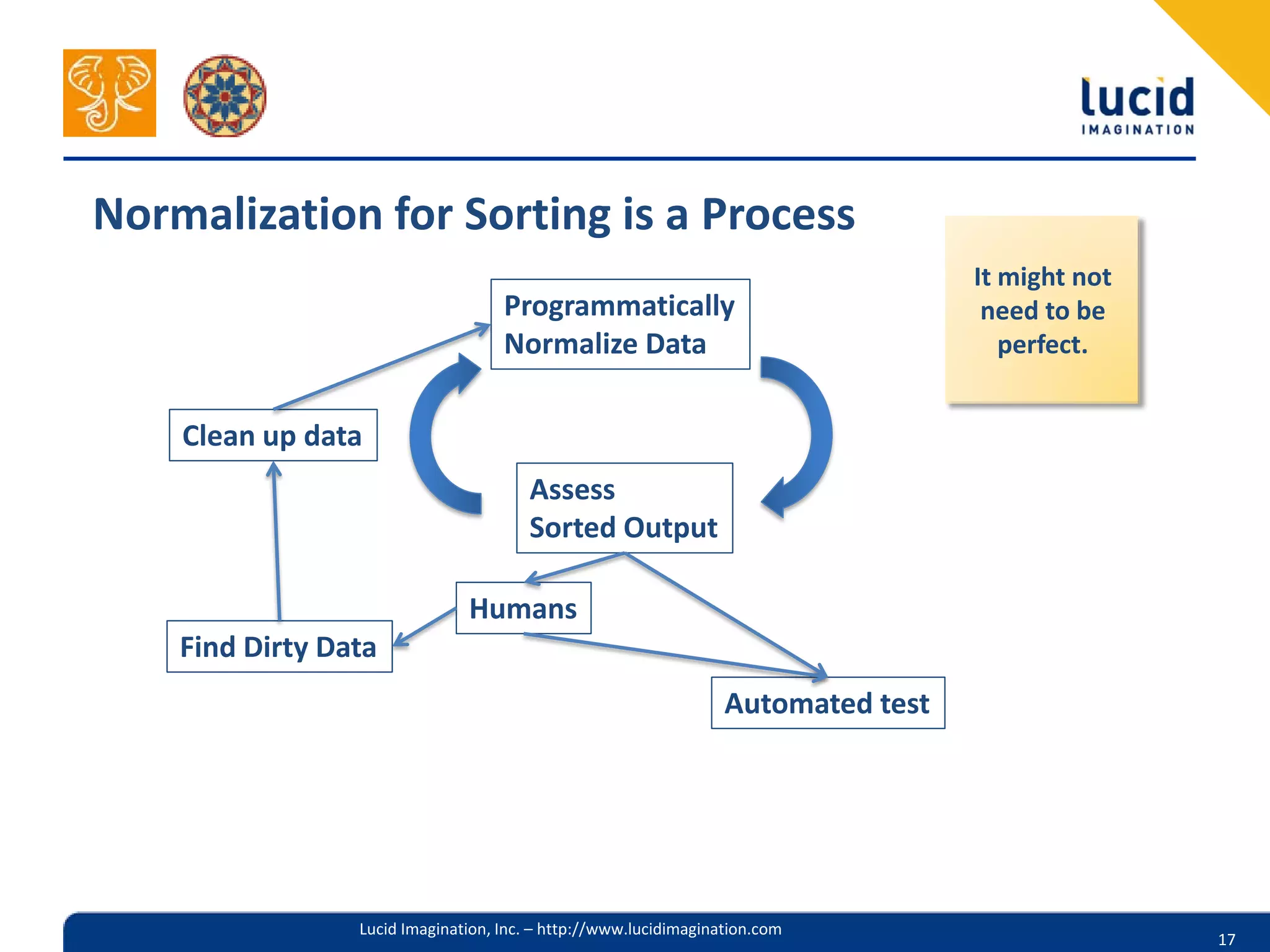
The document discusses the complexities of utilizing Solr for practical search applications, highlighting the challenges posed by dirty data, search versus browse functionalities, and query structuring. It emphasizes the importance of data normalization, addressing varied document types, and implementing effective search strategies at large scale, particularly for projects like HathiTrust. Additionally, the presenters share insights on leveraging Solr features, including dismax query parsing and performance enhancement techniques.













































































![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)




![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)

