Downloaded 13 times






![Postgres 17
Postgres 16
-[ RECORD 1 ]------+---------------
pid | 21830
datid | 16384
datname | pg16
relid | 16389
phase | vacuuming heap
heap_blks_total | 88496
heap_blks_scanned | 88496
heap_blks_vacuumed| 7478
index_vacuum_count | 1
max_dead_tuples | 11184809
num_dead_tuples | 10000000
-[ RECORD 1 ]--------+---------------
pid | 21971
datid | 16389
datname | pg17
relid | 16468
phase | vacuuming heap
heap_blks_total | 88496
heap_blks_scanned | 88496
heap_blks_vacuumed | 27040
index_vacuum_count | 0
max_dead_tuple_byte | 67108864
dead_tuple_bytes | 2556928
num_dead_item_ids | 10000000
indexes_total | 0
indexes_processed | 0](https://image.slidesharecdn.com/whatsnewinpostgresql17-240826042706-f72fe239/75/What-s-New-in-PostgreSQL-17-Mydbops-MyWebinar-Edition-35-8-2048.jpg)
![Postgres 16 Postgres 17
2024-08-19 10:49:17.351 UTC [21830] LOG: automatic vacuum of table
"pg16.public.test_16": index scans: 1
pages: 0 removed, 88496 remain, 88496 scanned (100.00% of total)
tuples: 3180676 removed, 10000000 remain, 0 are dead but not
yet removable
removable cutoff: 747, which was 0 XIDs old when operation ended
new relfrozenxid: 745, which is 2 XIDs ahead of previous value
frozen: 0 pages from table (0.00% of total) had 0 tuples frozen
index scan needed: 44248 pages from table (50.00% of total) had
10000000 dead item identifiers removed
index "test_16_id_idx": pages: 54840 in total, 0 newly deleted, 0
currently deleted, 0 reusable
avg read rate: 24.183 MB/s, avg write rate: 22.317 MB/s
buffer usage: 119566 hits, 156585 misses, 144501 dirtied
WAL usage: 201465 records, 60976 full page images, 233670948
bytes
system usage: CPU: user: 9.04 s, system: 3.56 s, elapsed: 50.58 s
2024-08-19 10:51:54.081 UTC [21959] LOG: automatic vacuum of table
"pg17.public.test_17": index scans: 0
pages: 0 removed, 76831 remain, 76831 scanned (100.00% of total)
tuples: 0 removed, 10000000 remain, 0 are dead but not yet
removable
removable cutoff: 827, which was 1 XIDs old when operation ended
new relfrozenxid: 825, which is 1 XIDs ahead of previous value
frozen: 0 pages from table (0.00% of total) had 0 tuples frozen
index scan not needed: 0 pages from table (0.00% of total) had 0
dead item identifiers removed
avg read rate: 34.779 MB/s, avg write rate: 19.580 MB/s
buffer usage: 79090 hits, 74631 misses, 42016 dirtied
WAL usage: 4969 records, 2 full page images, 309554 bytes
system usage: CPU: user: 2.71 s, system: 1.14 s, elapsed: 16.76 s](https://image.slidesharecdn.com/whatsnewinpostgresql17-240826042706-f72fe239/75/What-s-New-in-PostgreSQL-17-Mydbops-MyWebinar-Edition-35-9-2048.jpg)


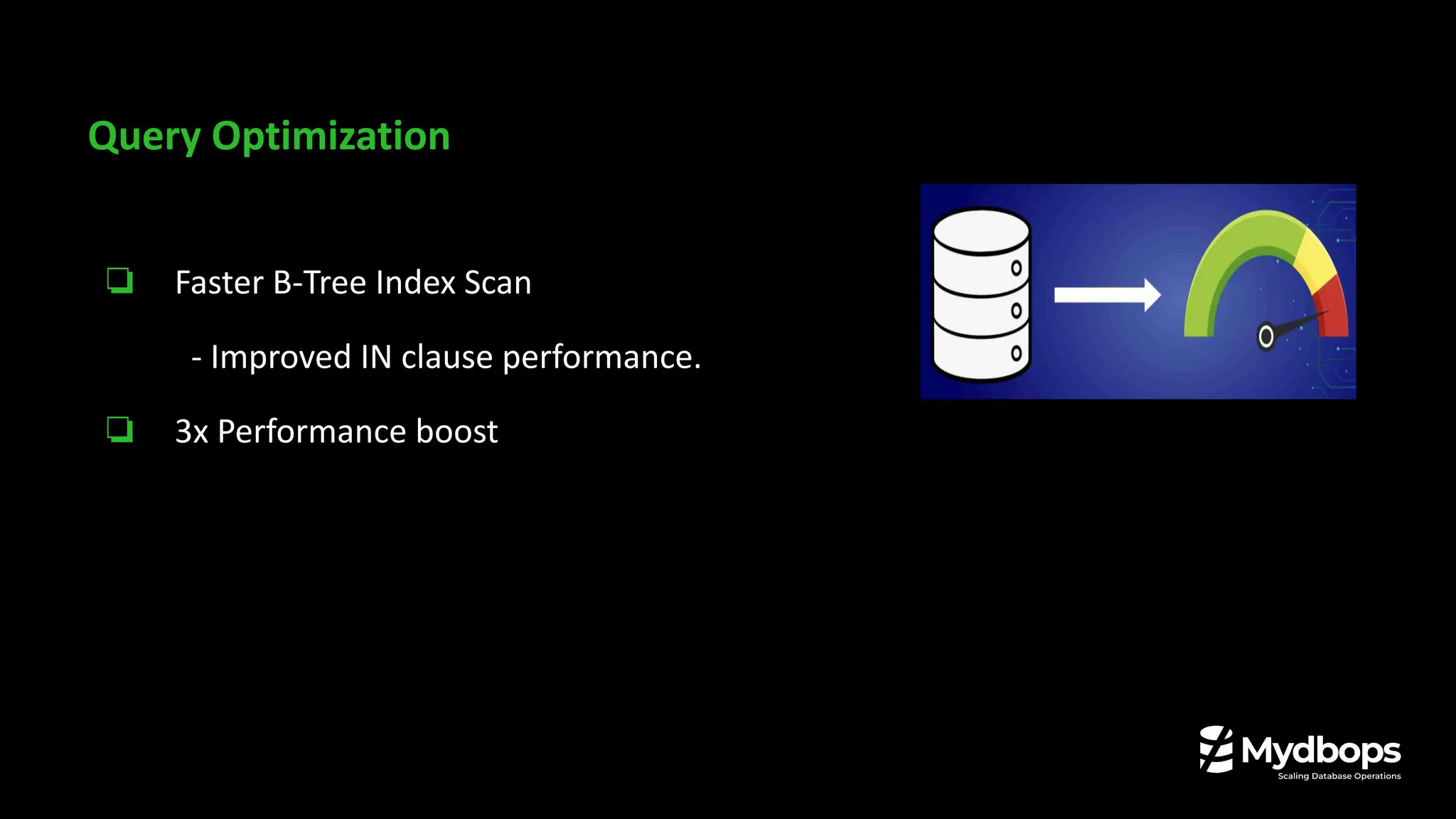
![Postgres 16
Postgres 17
pg16=# EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM test_16 WHERE id IN (1, 2, 3, 4, 45, 6, 10007);
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using test_16_id_idx on test_16 (cost=0.43..31.17 rows=7 width=4) (actual time=0.052..1.277 rows=7 loops=1)
Index Cond: (id = ANY ('{1,2,3,4,45,6,10007}'::integer[]))
Heap Fetches: 0
Buffers: shared hit=24 read=1
Planning:
Buffers: shared hit=61
Planning Time: 0.401 ms
Execution Time: 1.293 ms
(8 rows)
pg17=# EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM test_17 WHERE id IN (1, 2, 3, 4, 45, 6, 10007);
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using test_17_id_idx on test_17 (cost=0.43..31.17 rows=7 width=4) (actual time=0.056..0.542 rows=7 loops=1)
Index Cond: (id = ANY ('{1,2,3,4,45,6,10007}'::integer[]))
Heap Fetches: 0
Buffers: shared hit=6 read=1
Planning:
Buffers: shared hit=70
Planning Time: 0.452 ms
Execution Time: 0.564 ms
(8 rows)](https://image.slidesharecdn.com/whatsnewinpostgresql17-240826042706-f72fe239/75/What-s-New-in-PostgreSQL-17-Mydbops-MyWebinar-Edition-35-15-2048.jpg)

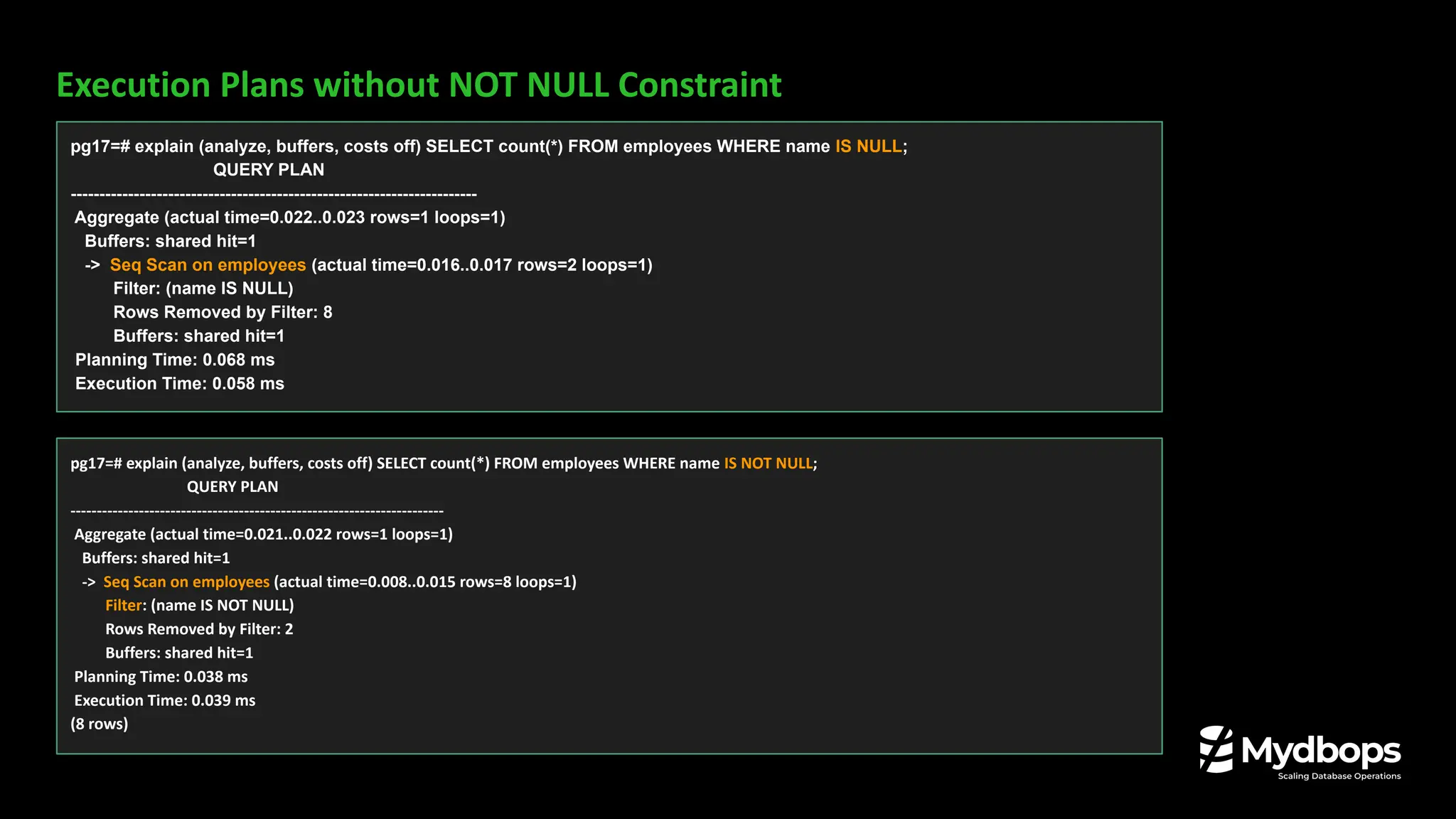








![Postgres 16 Postgres 17
pg16=# SELECT * FROM pg_replication_slots WHERE
slot_name = 'mydbops_testing_slot';
-[ RECORD 1 ]----------+---------------------
slot_name | mydbops_testing_slot
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | f
active_pid |
xmin |
catalog_xmin |
restart_lsn |
confirmed_flush_lsn |
wal_status |
safe_wal_size |
two_phase | f
conflicting |
pg17=# SELECT * FROM pg_replication_slots WHERE
slot_name = 'mydbops_testing_slot';
-[ RECORD 1 ]-------+------------------------------
slot_name | mydbops_testing_slot
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | f
active_pid |
xmin |
catalog_xmin |
restart_lsn |
confirmed_flush_lsn |
wal_status |
safe_wal_size |
two_phase | f
inactive_since | 2024-08-20 04:29:36.446812+00
conflicting |
invalidation_reason |
failover | f
synced | f](https://image.slidesharecdn.com/whatsnewinpostgresql17-240826042706-f72fe239/75/What-s-New-in-PostgreSQL-17-Mydbops-MyWebinar-Edition-35-26-2048.jpg)



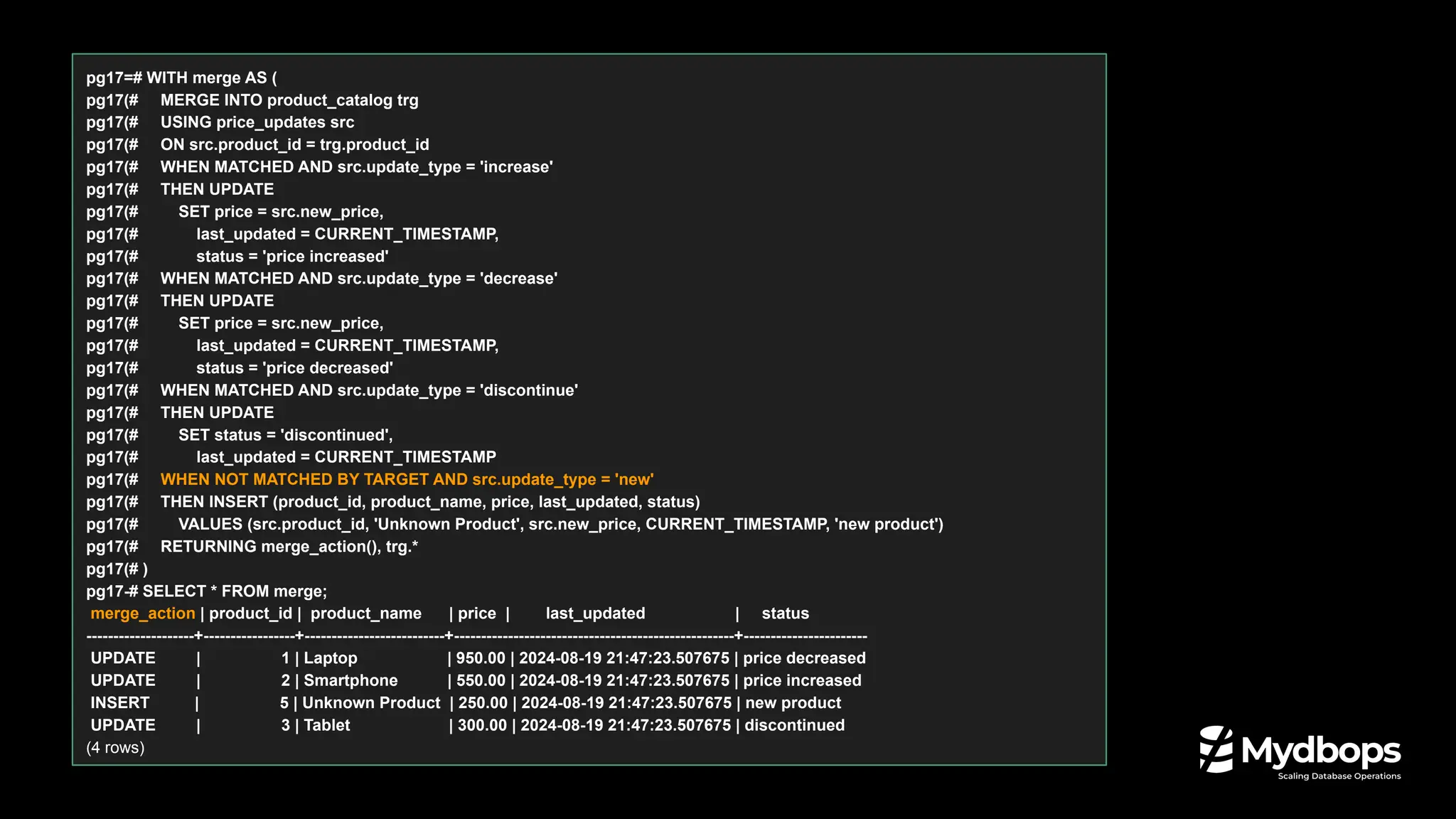

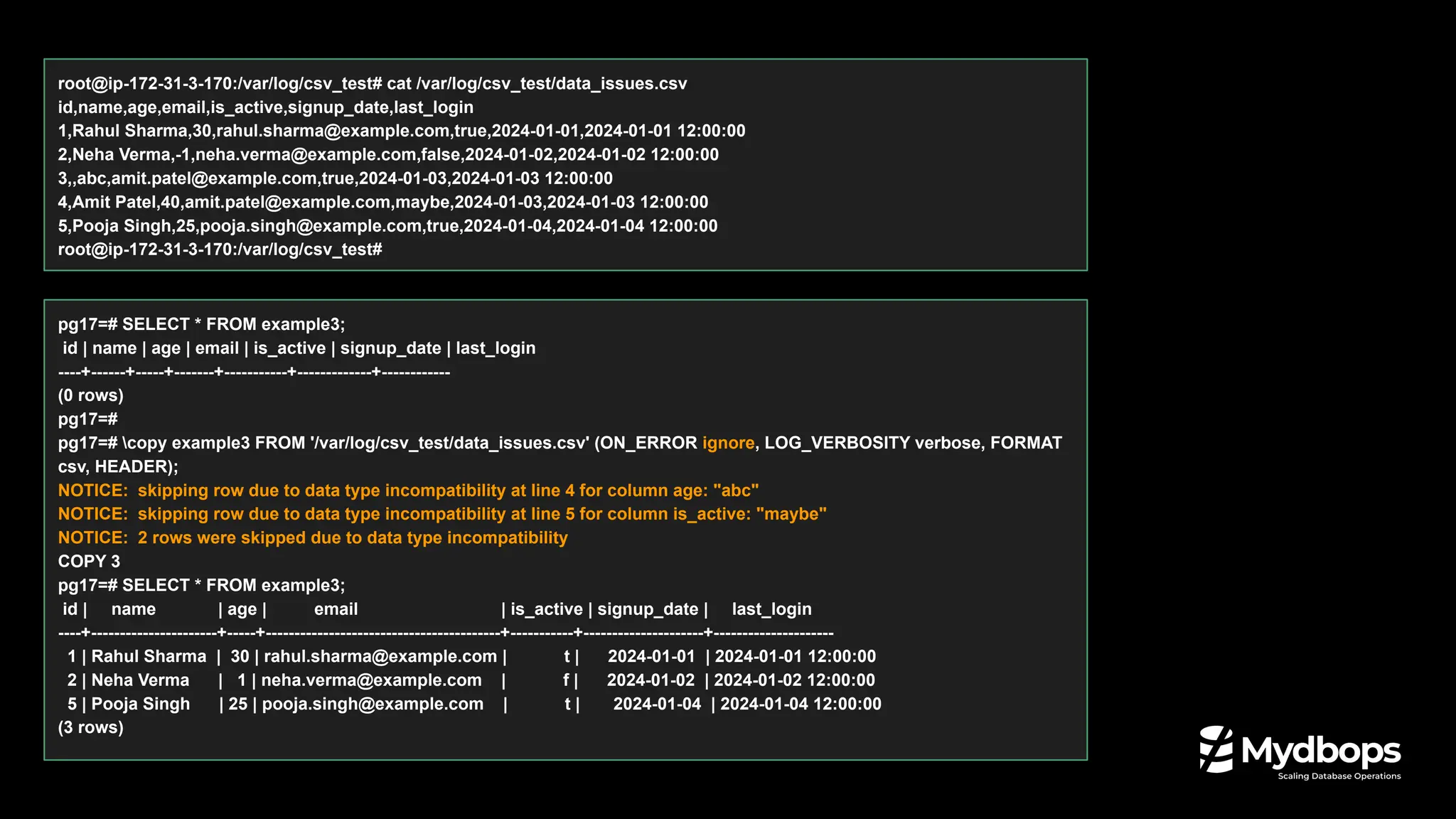
![JSON_TABLE: Convert JSON to table.
Converting JSON data into a table format
pg17=# CREATE TABLE customer_orders (order_data jsonb);
CREATE TABLE
pg17=# INSERT INTO customer_orders VALUES ( '{ "orders": [ { "product": "Laptop", "quantity": 2 }, { "product": "Mouse",
"quantity": 5 } ] }' );
INSERT 0 1
pg17=# SELECT jt.* FROM customer_orders, JSON_TABLE(order_data, '$.orders[*]'
pg17(# COLUMNS ( id FOR ORDINALITY, product text PATH '$.product', quantity int PATH '$.quantity' )) AS jt;
id | product | quantity
----+---------+----------
1 | Laptop | 2
2 | Mouse | 5
(2 rows)
pg17=#
SQL/JSON Enhancements](https://image.slidesharecdn.com/whatsnewinpostgresql17-240826042706-f72fe239/75/What-s-New-in-PostgreSQL-17-Mydbops-MyWebinar-Edition-35-33-2048.jpg)

![JSON Query Functions
- JSON_EXISTS(): Checks if a specific path exists in JSON
- JSON_QUERY(): Extracts a part of the JSON data.
- JSON_VALUE(): Extracts a single value from JSON.
SELECT JSON_EXISTS(jsonb '{"user": "Alice", "roles": ["admin", "user"]}', '$.roles[?(@ == "admin")]');
t(true)
SELECT JSON_QUERY(jsonb '{"user": "Bob", "roles": ["user", "editor"]}', '$.roles');
["user", "editor"]
SELECT JSON_VALUE(jsonb '{"user": "Charlie", "age": 25}', '$.user');
“Charlie”](https://image.slidesharecdn.com/whatsnewinpostgresql17-240826042706-f72fe239/75/What-s-New-in-PostgreSQL-17-Mydbops-MyWebinar-Edition-35-35-2048.jpg)







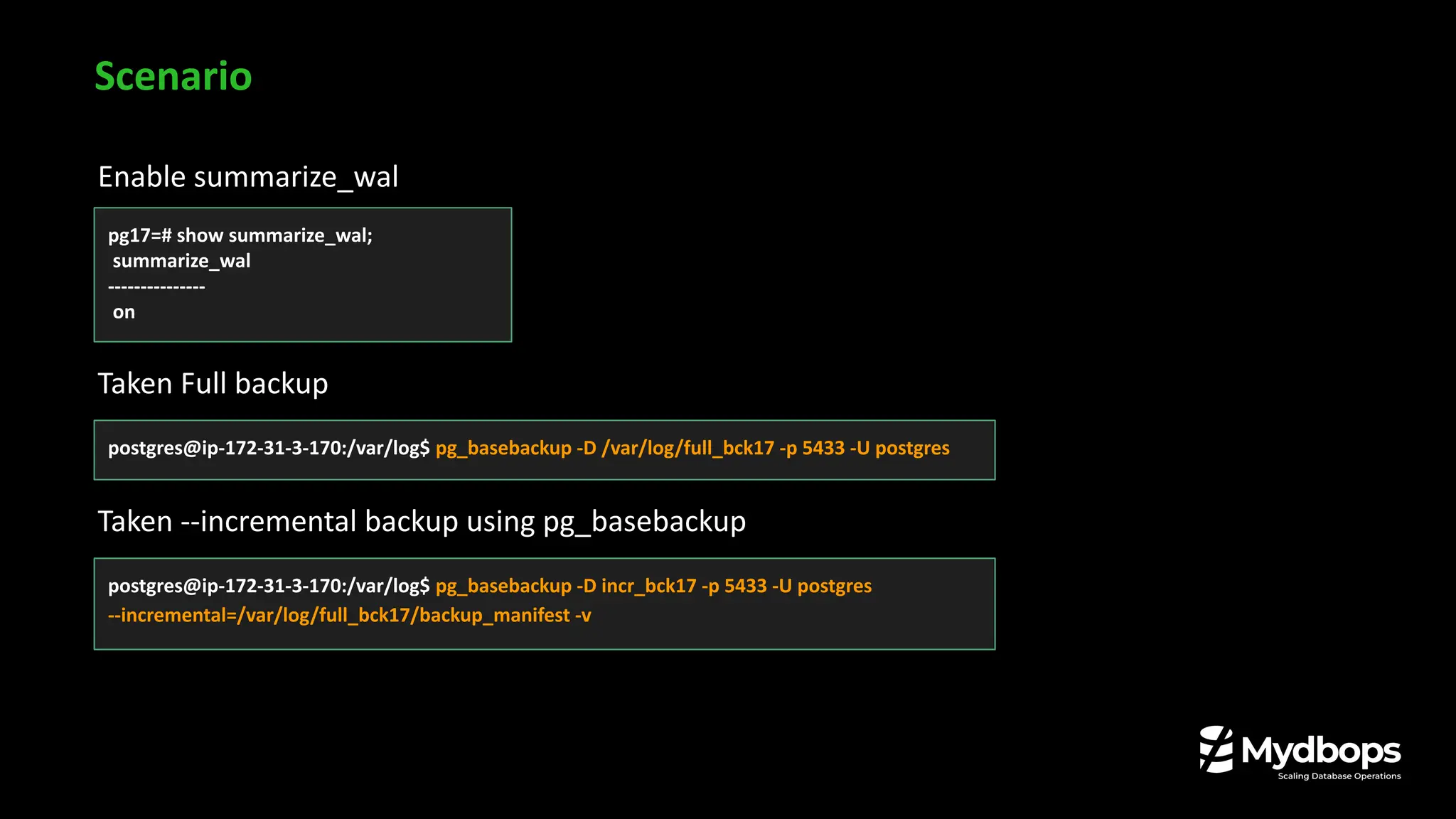
![Taken full backup including incremental backup using pg_combinebackup
postgres@ip-172-31-3-170:/var/log$ /usr/lib/postgresql/17/bin/pg_combinebackup --output=combine_incr_full_bck
full_bck17 incr_bck17
postgres@ip-172-31-3-170:/var/log/combine_incr_full_bck$ tail -10 backup_manifest
{ "Path": "global/6303", "Size": 16384, "Last-Modified": "2024-08-18 13:26:43 GMT", "Checksum-Algorithm": "CRC32C", "Checksum":
"e8d85722" },
{ "Path": "global/6245", "Size": 8192, "Last-Modified": "2024-08-18 13:26:43 GMT", "Checksum-Algorithm": "CRC32C", "Checksum":
"21597da0" },
{ "Path": "global/6115", "Size": 8192, "Last-Modified": "2024-08-18 13:26:43 GMT", "Checksum-Algorithm": "CRC32C", "Checksum":
"b5a46221" },
{ "Path": "global/6246", "Size": 8192, "Last-Modified": "2024-08-18 13:26:43 GMT", "Checksum-Algorithm": "CRC32C", "Checksum":
"865872e0" },
{ "Path": "global/6243", "Size": 0, "Last-Modified": "2024-08-18 13:26:43 GMT", "Checksum-Algorithm": "CRC32C", "Checksum":
"00000000" }
],
"WAL-Ranges": [
{ "Timeline": 1, "Start-LSN": "2/B000028", "End-LSN": "2/B000120" }
],
"Manifest-Checksum": "0f16e87ab7bd400434c2725cf468d77bbcb702a49d38d749cd0e5af47f8f5fac"}
postgres@ip-172-31-3-170:/var/log/combine_incr_full_bck$](https://image.slidesharecdn.com/whatsnewinpostgresql17-240826042706-f72fe239/75/What-s-New-in-PostgreSQL-17-Mydbops-MyWebinar-Edition-35-45-2048.jpg)
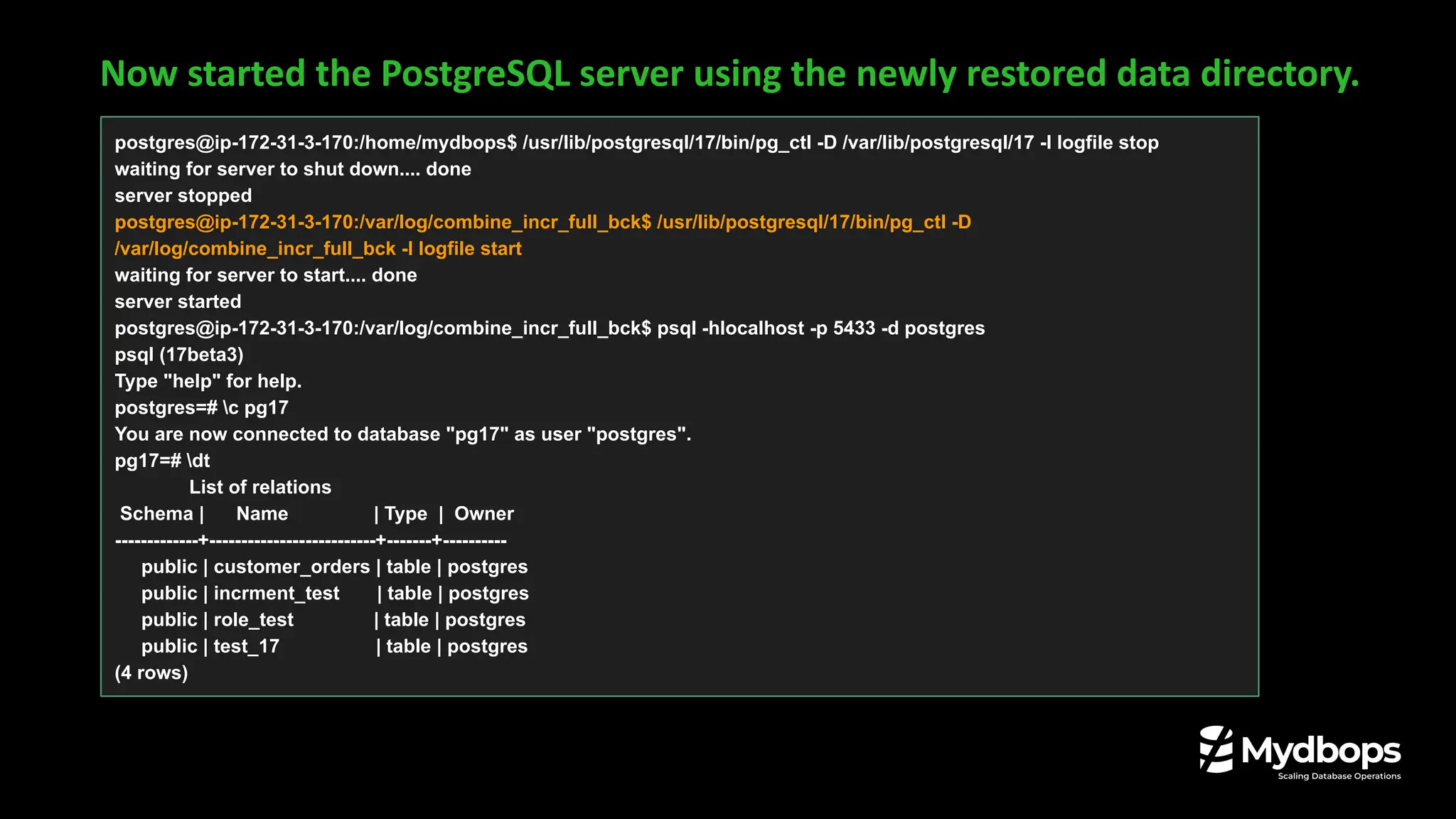

![VACUUM Progress Reporting
❏ Indexes_total: Total indexes on the table being vacuumed
❏ Indexes_processed: Shows how many indexes have been already vacuumed
select * from pg_stat_progress_vacuum;
-[ RECORD 1 ]--------+------------------
pid | 7454
datid | 16389
datname | pg17
relid | 16394
phase | vacuuming indexes
heap_blks_total | 88496
heap_blks_scanned | 88496
heap_blks_vacuumed | 0
index_vacuum_count | 0
max_dead_tuple_bytes| 67108864
dead_tuple_bytes | 2556928
num_dead_item_ids | 10000000
indexes_total | 1
indexes_processed | 0](https://image.slidesharecdn.com/whatsnewinpostgresql17-240826042706-f72fe239/75/What-s-New-in-PostgreSQL-17-Mydbops-MyWebinar-Edition-35-49-2048.jpg)
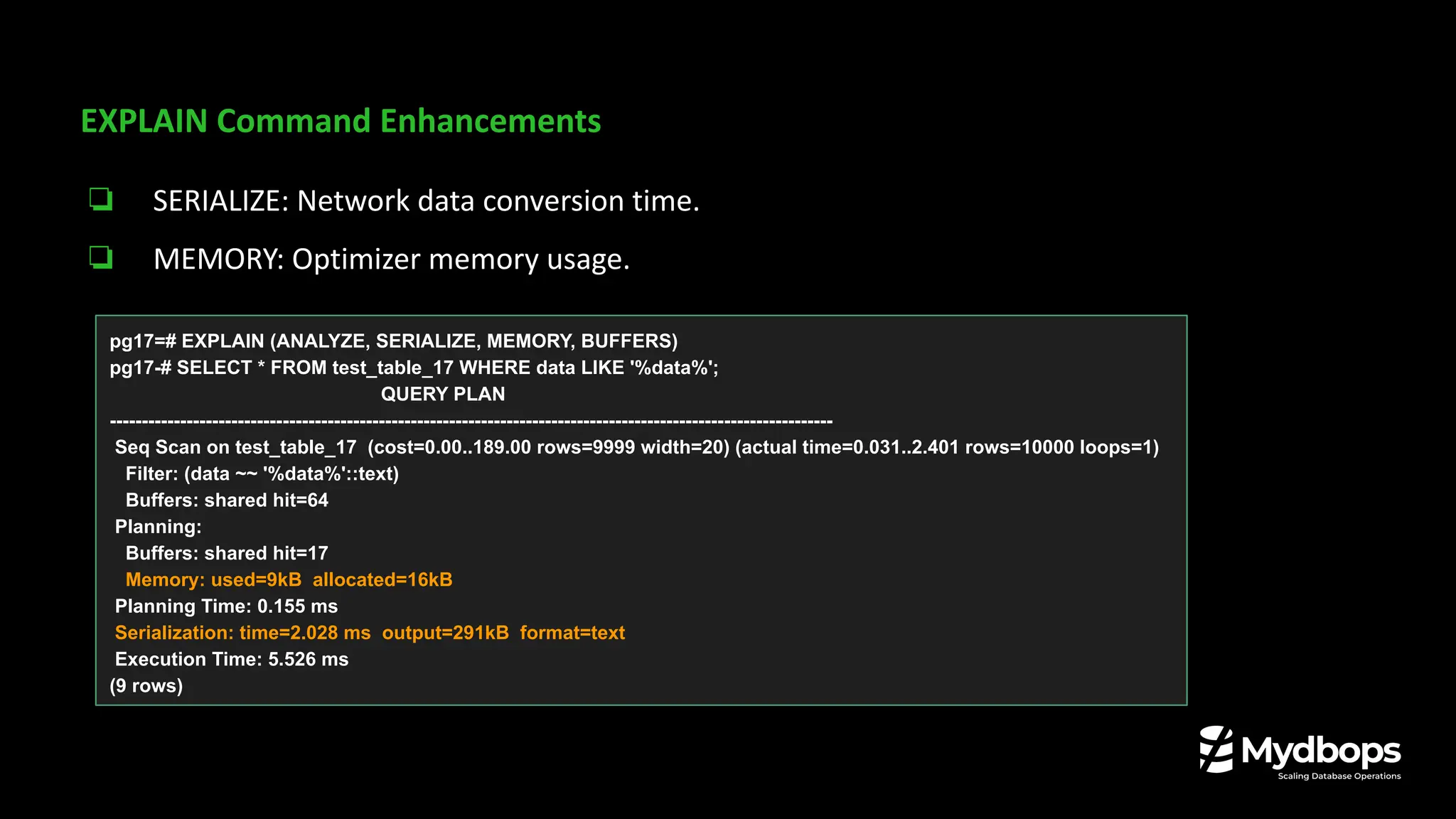
![pg_wait_events View
- Shows wait event details and description.
pg17=# SELECT * FROM pg_wait_events;
-[ RECORD 1
]-----------------------------------------------------------------------------------------------------------------------------
type | Activity
name | AutovacuumMain
description | Waiting in main loop of autovacuum launcher process](https://image.slidesharecdn.com/whatsnewinpostgresql17-240826042706-f72fe239/75/What-s-New-in-PostgreSQL-17-Mydbops-MyWebinar-Edition-35-50-2048.jpg)
![Pg_stat_checkpointer
❏ Displays statistics related to the checkpointer process.
❏ Replaced some of the old stats found in pg_stat_bgwriter.
pg17=# SELECT * FROM pg_stat_checkpointer;
-[ RECORD 1 ]-------+------------------------------
num_timed | 345
num_requested | 21
restartpoints_timed | 0
restartpoints_req | 0
restartpoints_done | 0
write_time | 1192795
sync_time | 1868
buffers_written | 56909
stats_reset | 2024-08-14 10:29:39.606191+00
pg17=#](https://image.slidesharecdn.com/whatsnewinpostgresql17-240826042706-f72fe239/75/What-s-New-in-PostgreSQL-17-Mydbops-MyWebinar-Edition-35-51-2048.jpg)
![Pg_stat_statements
CALL Normalization: Fewer entries for procedures.
pg16=# SELECT userid, dbid, toplevel, queryid, query,
total_exec_time, min_exec_time, max_exec_time,
mean_exec_time, stddev_exec_time FROM
pg_stat_statements WHERE query LIKE 'CALL
update_salary%';
-[ RECORD 1 ]-----+-------------------------------
userid | 10
dbid | 16384
toplevel | t
queryid | -6663051425227154753
query | CALL update_salary('HR', 1200)
total_exec_time | 0.10497
min_exec_time | 0.10497
max_exec_time | 0.10497
mean_exec_time | 0.10497
stddev_exec_time | 0
-[ RECORD 2 ]----+-------------------------------
pg17=# SELECT userid, dbid, toplevel, queryid, query,
total_exec_time, min_exec_time, max_exec_time,
mean_exec_time, stddev_exec_time, minmax_stats_since,
stats_since FROM pg_stat_statements WHERE query LIKE
'CALL update_salary%';
-[ RECORD 1 ]------+------------------------------
userid | 10
dbid | 16389
toplevel | t
queryid | 3335012495428089609
query | CALL update_salary($1, $2)
total_exec_time | 1.957936
min_exec_time | 0.06843
max_exec_time | 1.694025
mean_exec_time | 0.489484
stddev_exec_time | 0.6955936256612045
minmax_stats_since | 2024-08-20 14:19:29.726603+00
stats_since | 2024-08-20 14:19:29.726603+00
pg17=#
Postgres 16 Postgres 17](https://image.slidesharecdn.com/whatsnewinpostgresql17-240826042706-f72fe239/75/What-s-New-in-PostgreSQL-17-Mydbops-MyWebinar-Edition-35-52-2048.jpg)






The document details the enhancements in PostgreSQL 17, highlighting performance optimizations, developer workflow improvements, and new security features. Key improvements include more efficient vacuum mechanisms, faster tuple ID lookups, and advancements in partition management and logical replication. Additionally, the document discusses new commands and features that facilitate data management and enhance replication processes in database environments.