Downloaded 16 times















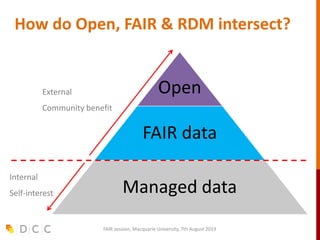
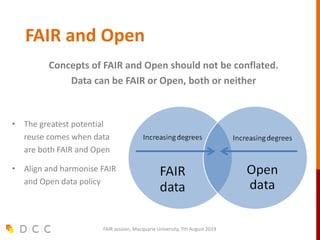






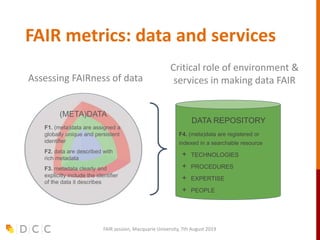






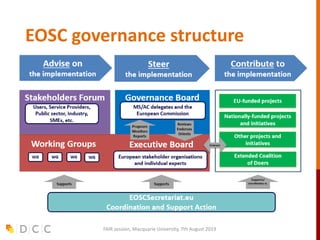

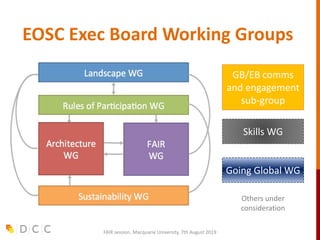










The document discusses the FAIR (Findable, Accessible, Interoperable, Reusable) data principles in the context of research data management and open science. It highlights the importance of creating a fair culture, developing a technical ecosystem, and building skills and capacity to ensure these principles are effectively implemented. Additionally, it outlines recommendations for various stakeholders and emphasizes the need for alignment between open and fair data policies.























































































