






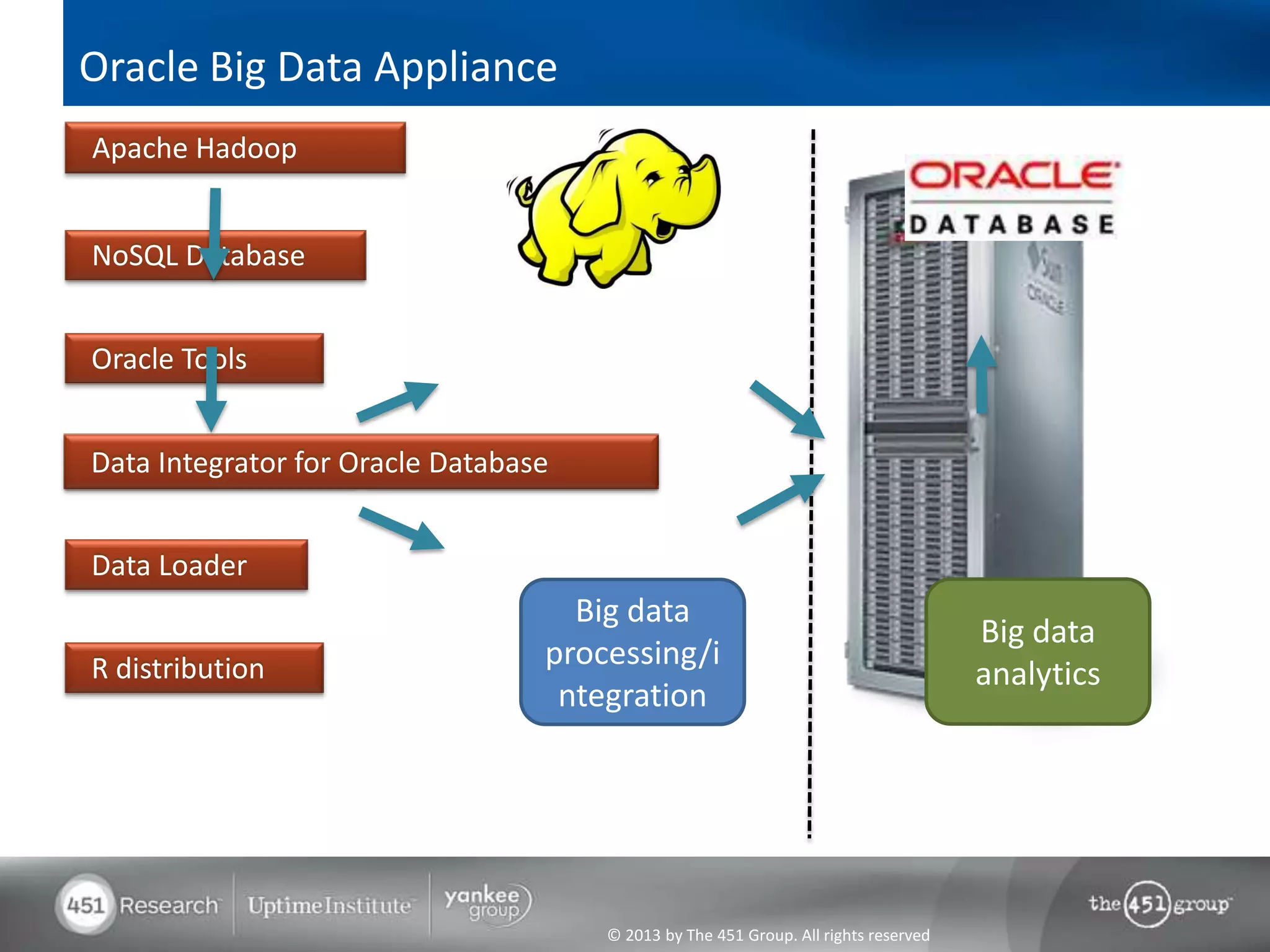
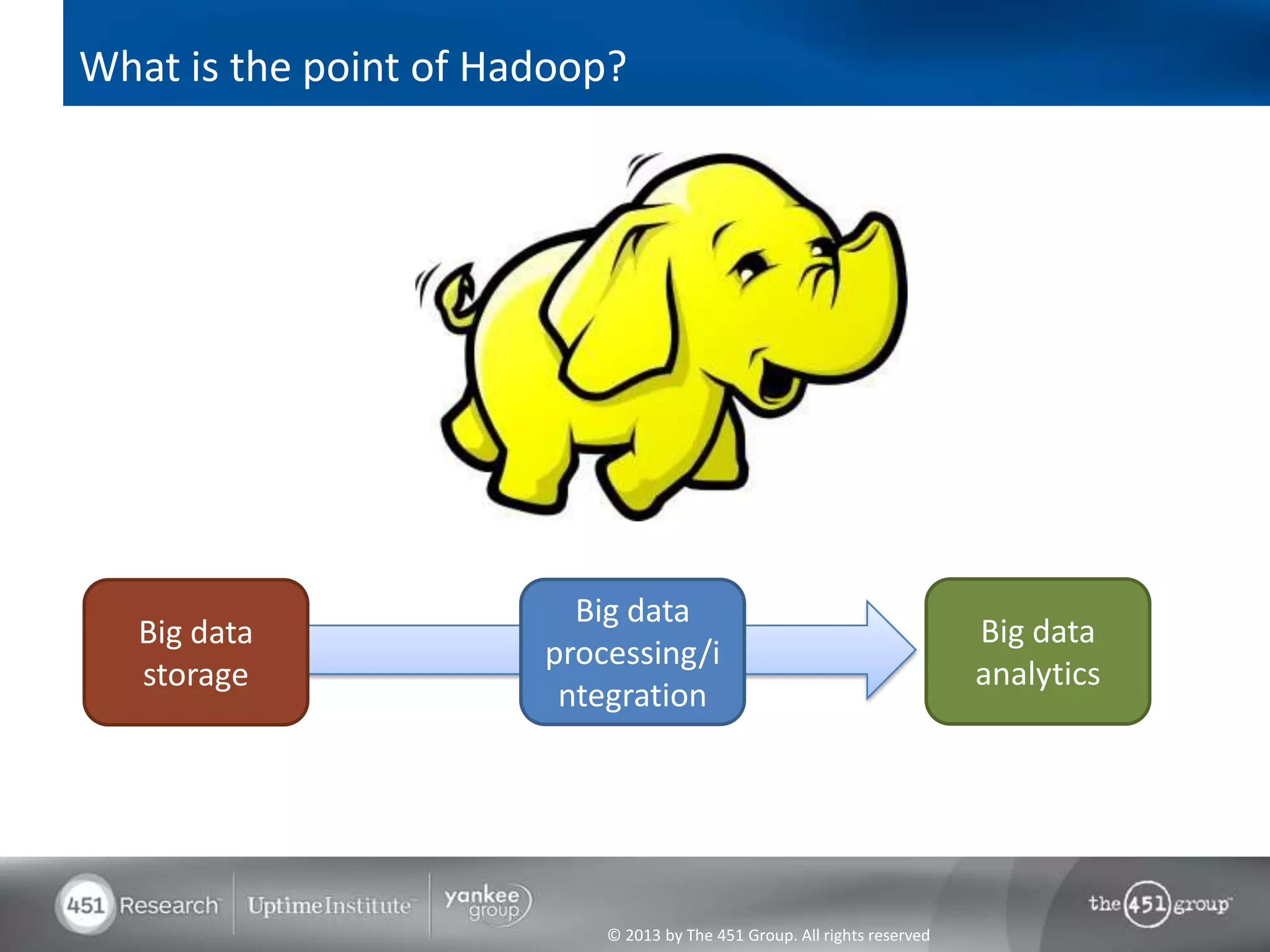


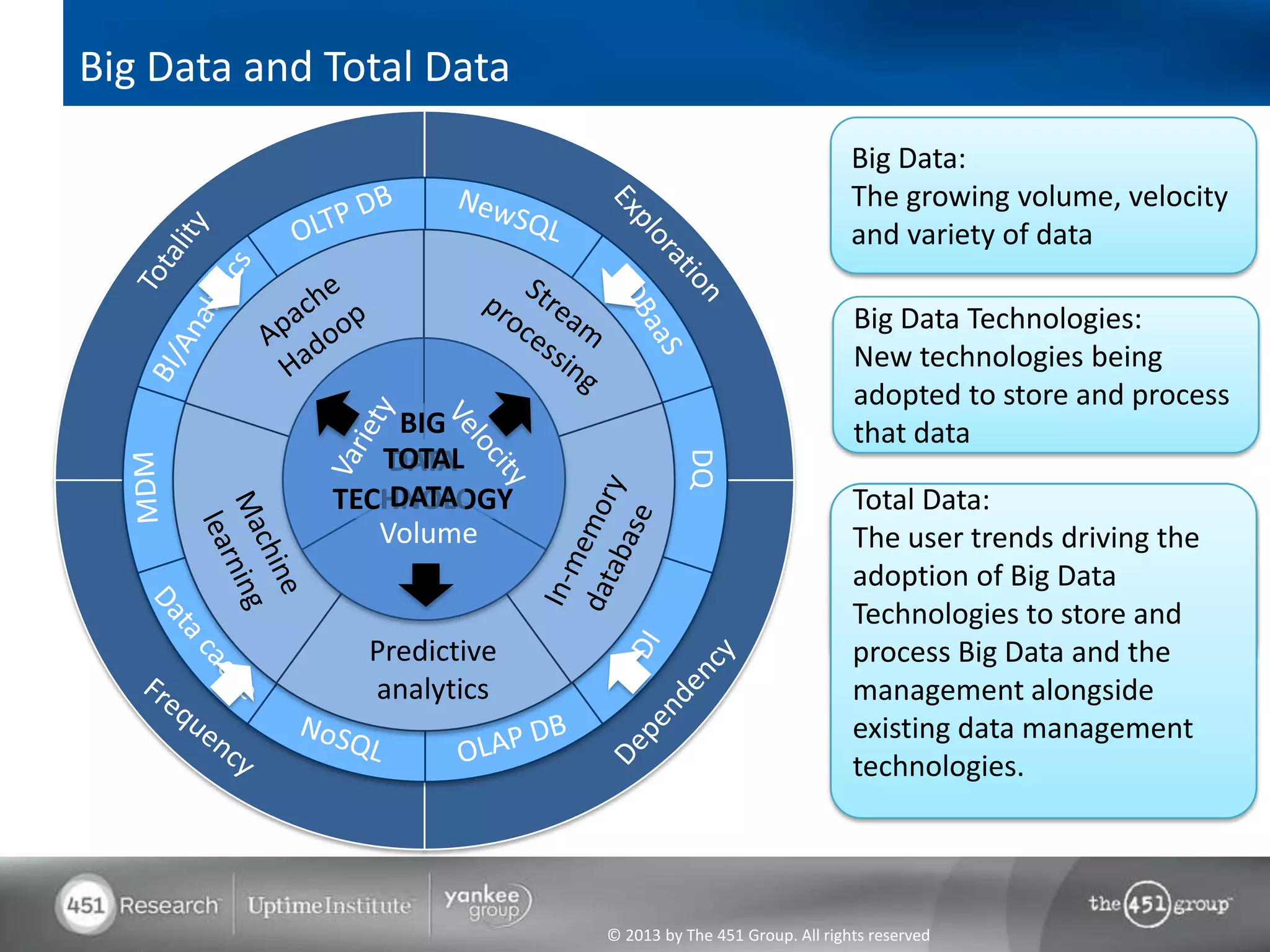

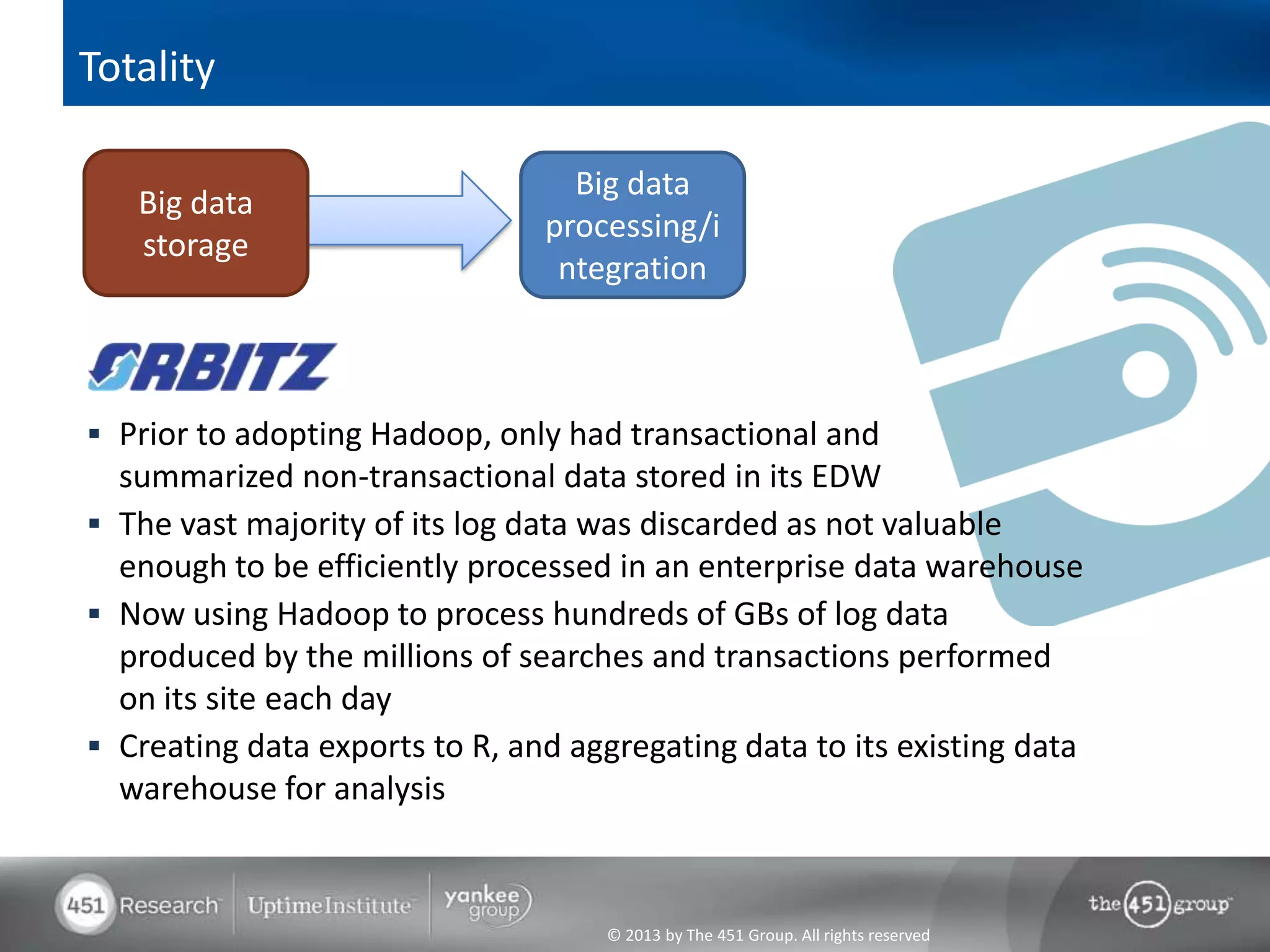

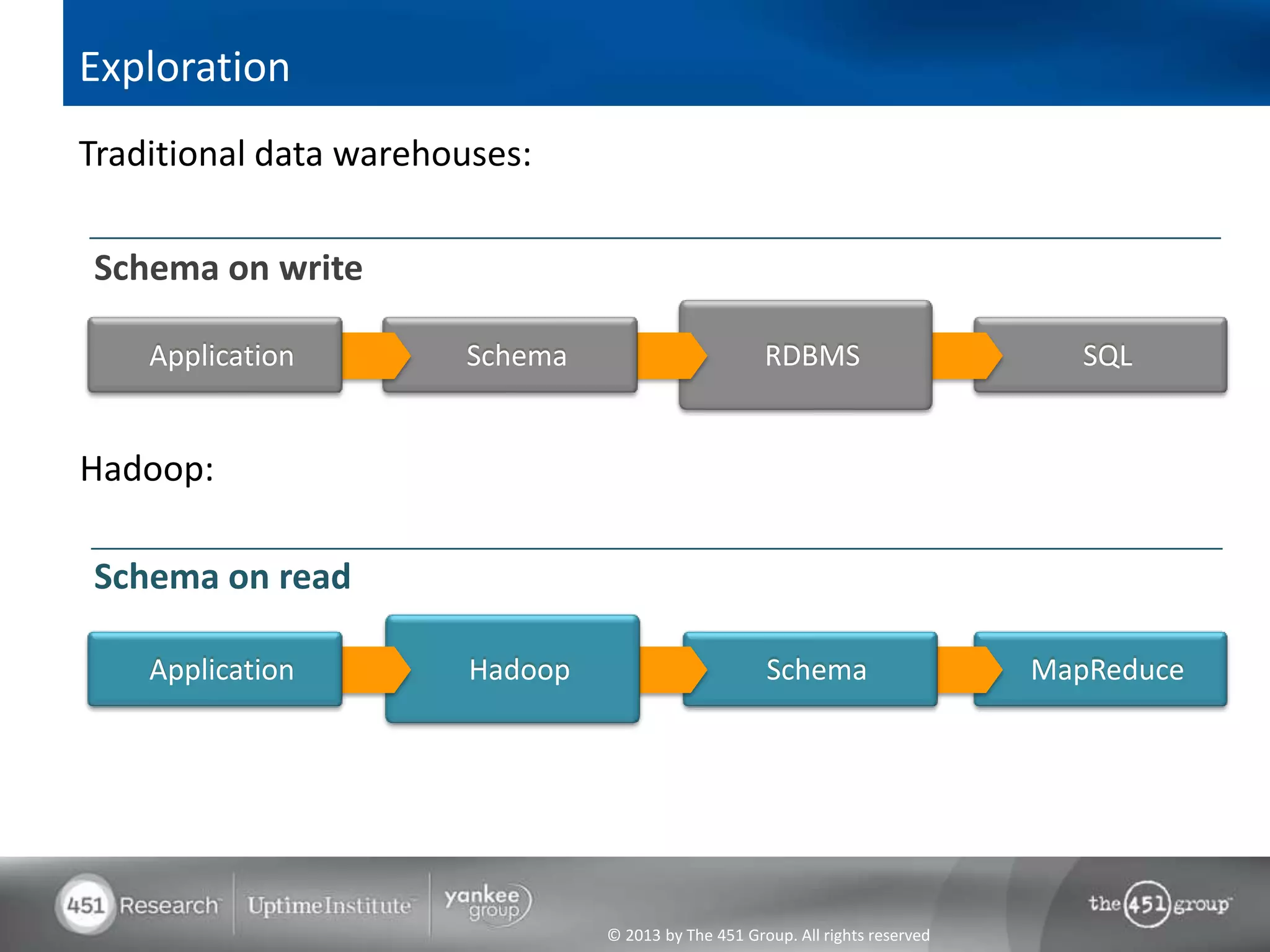
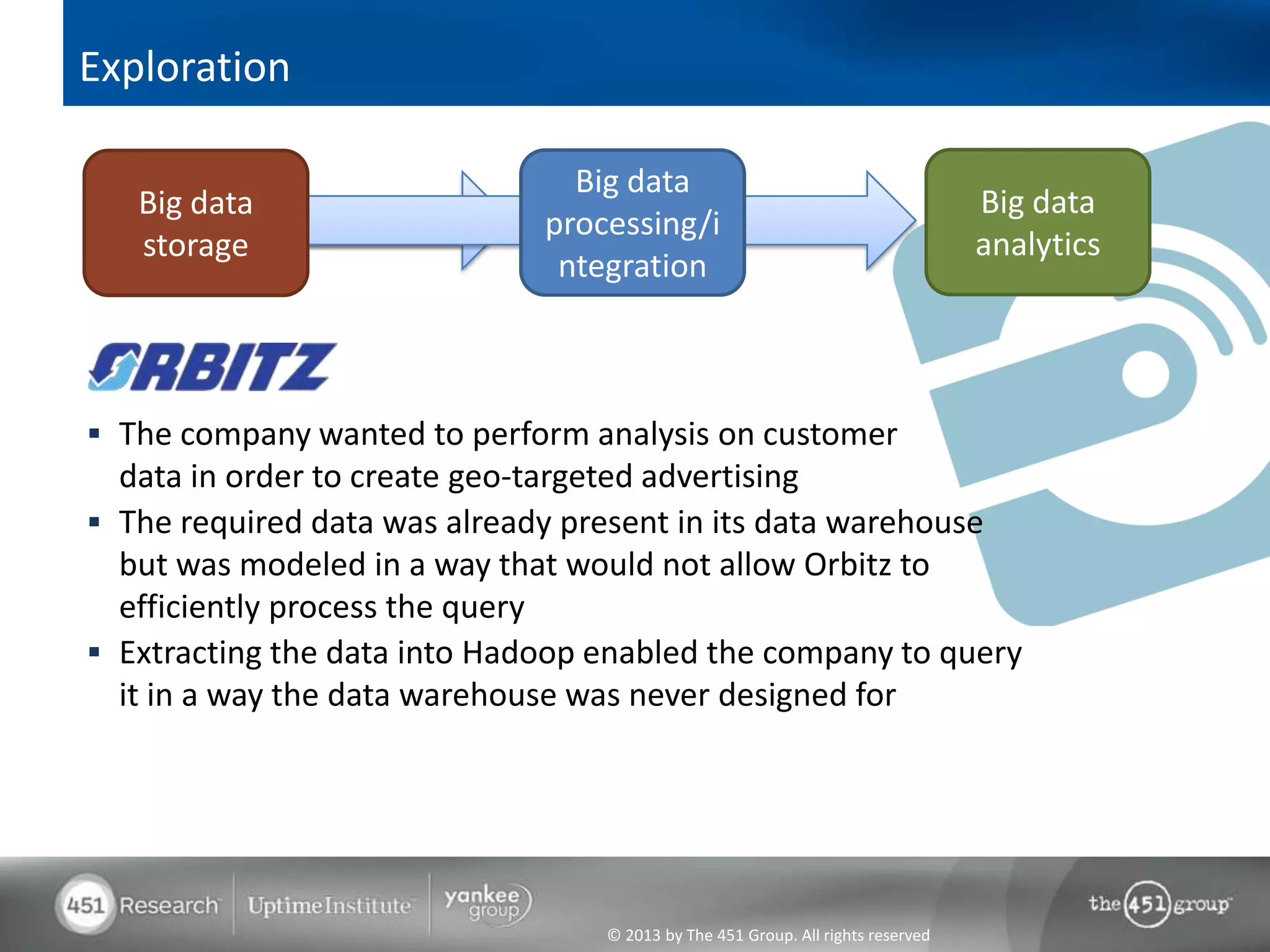
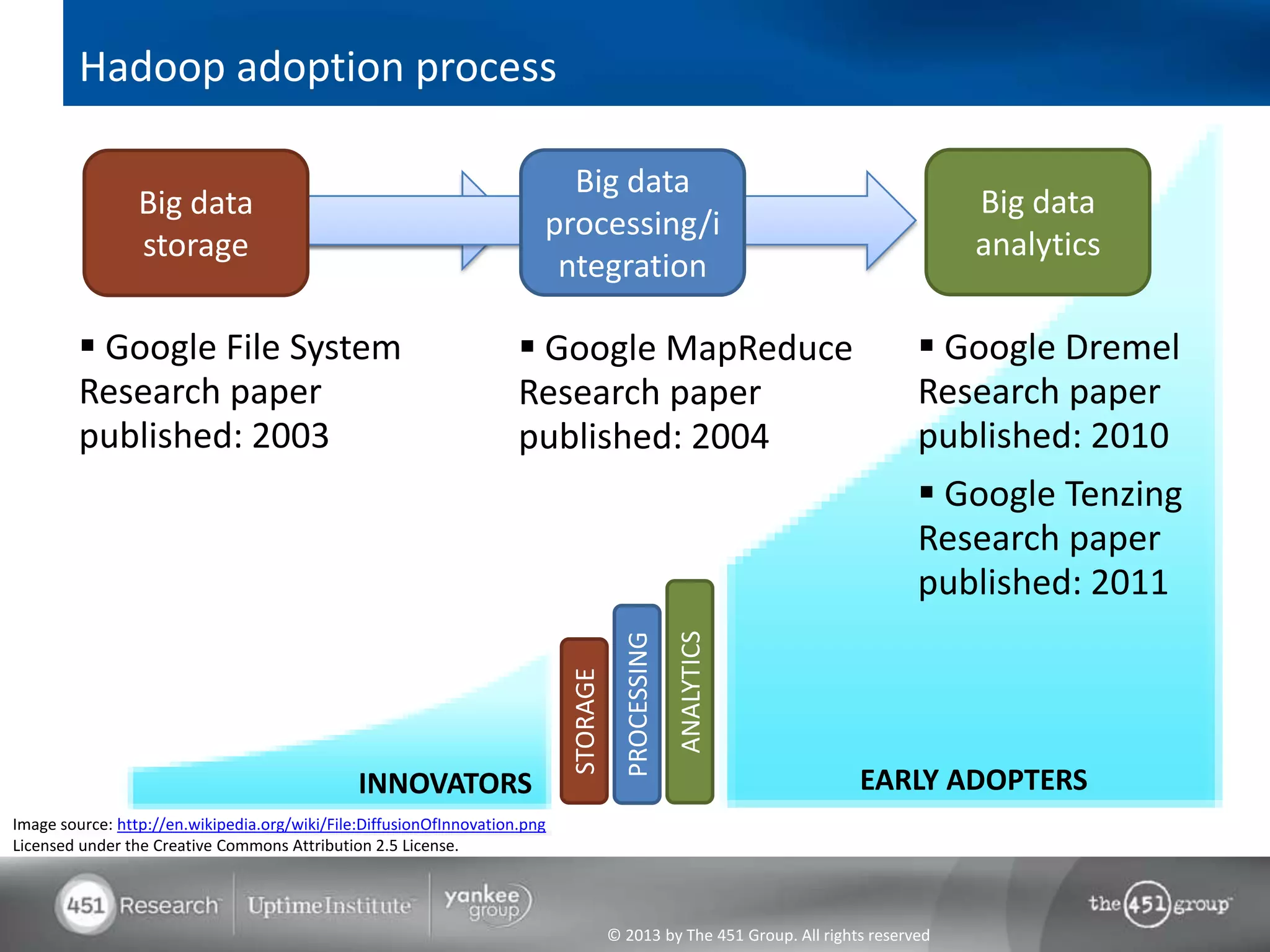
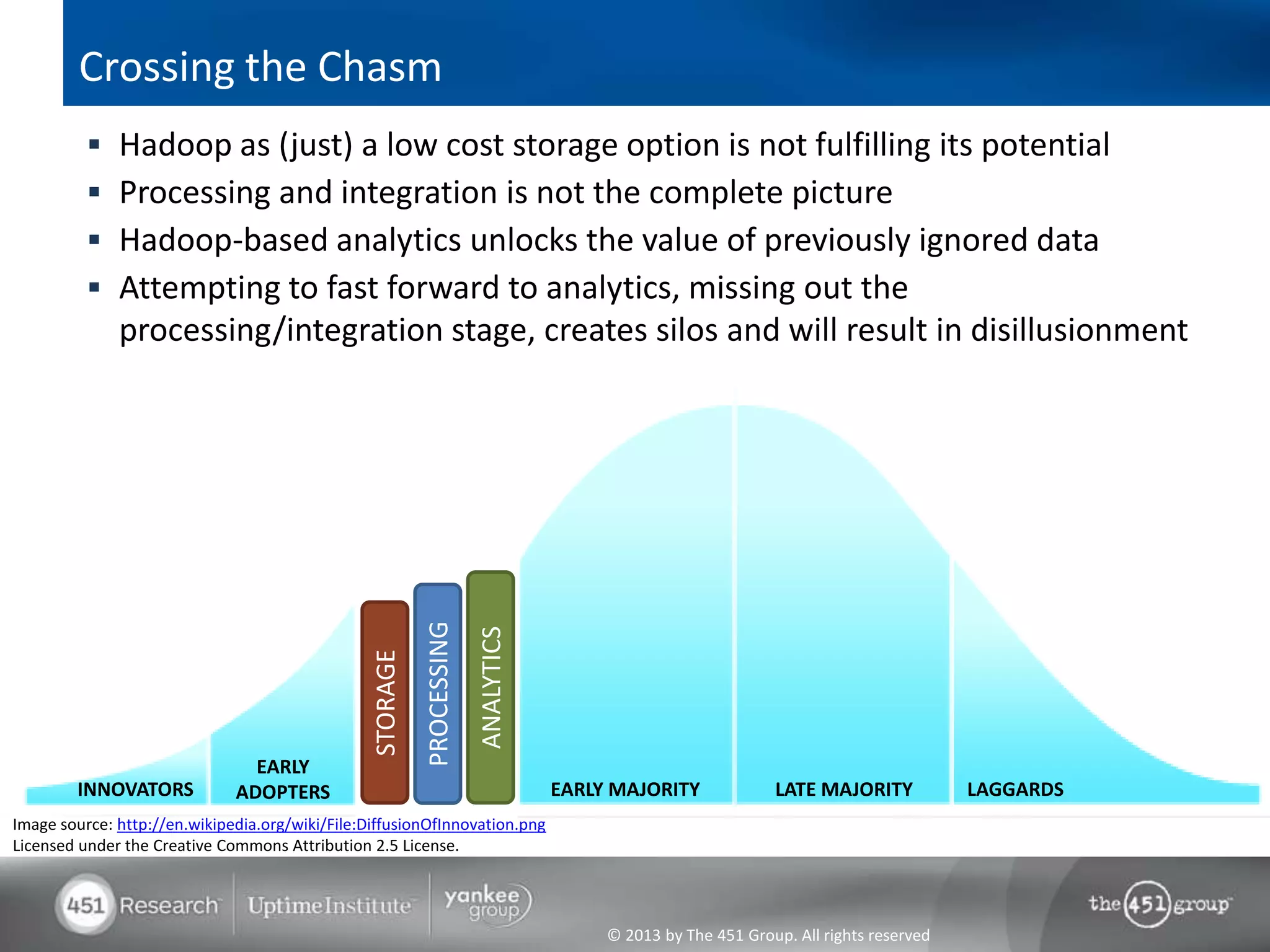


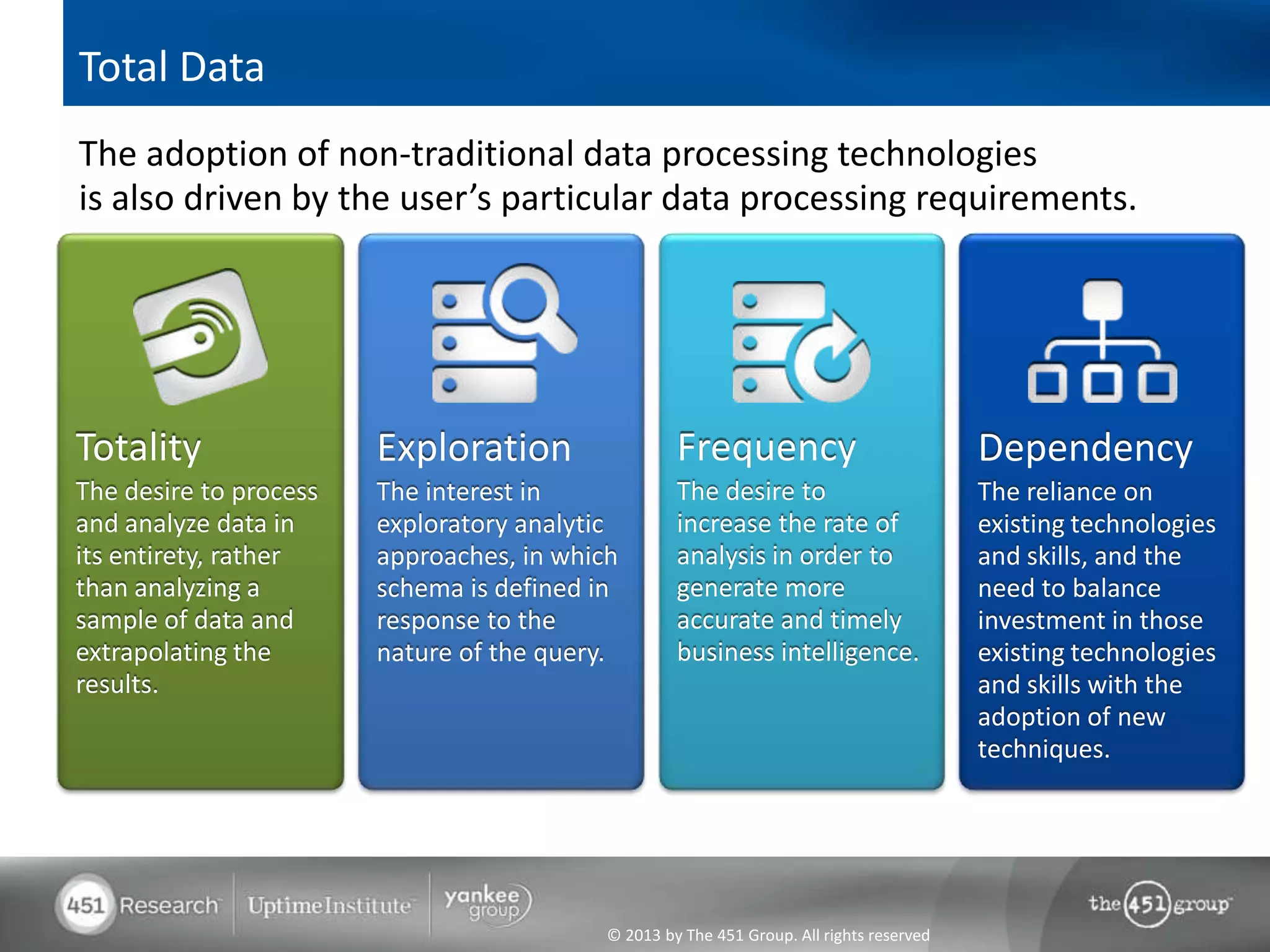

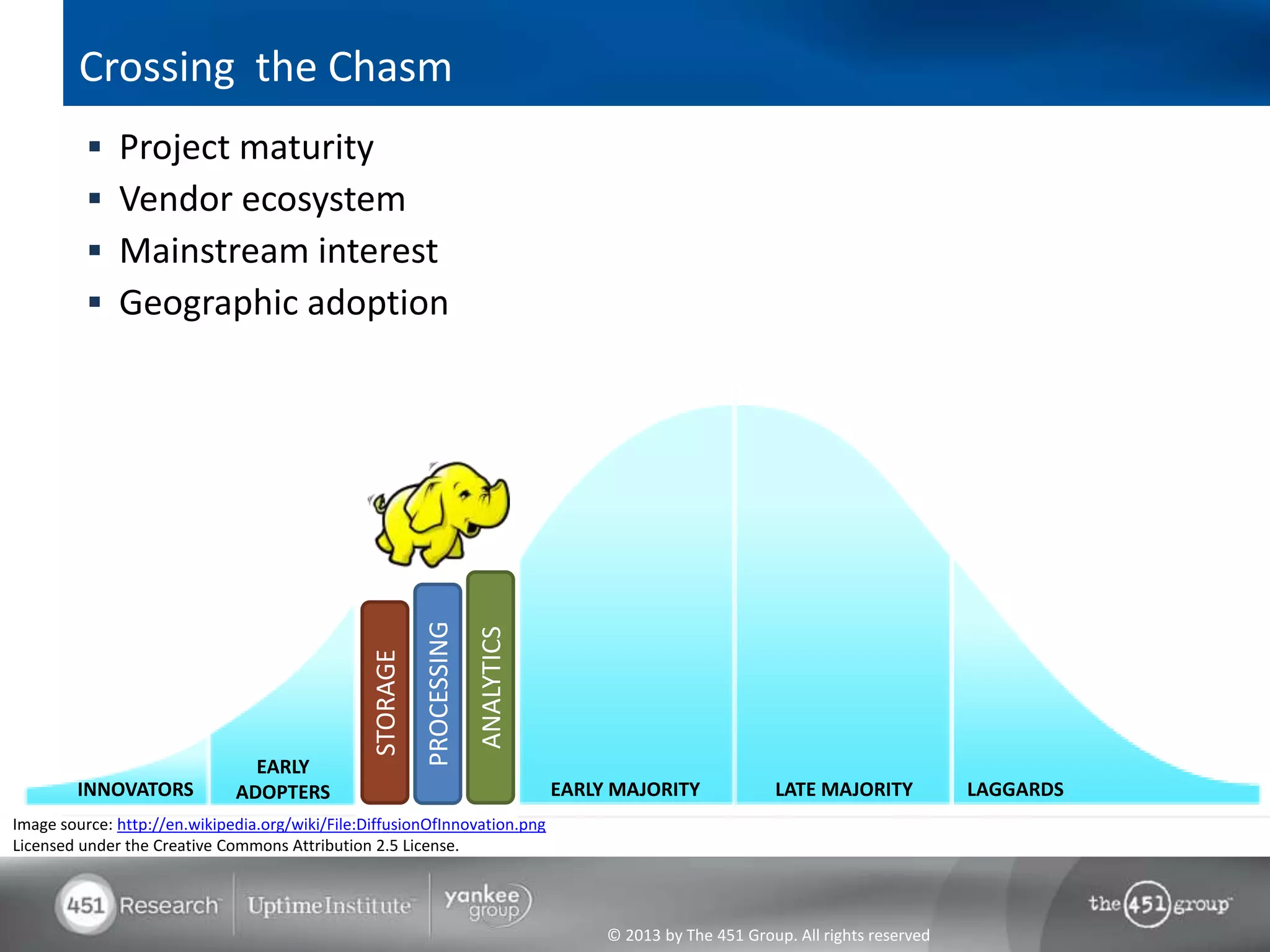
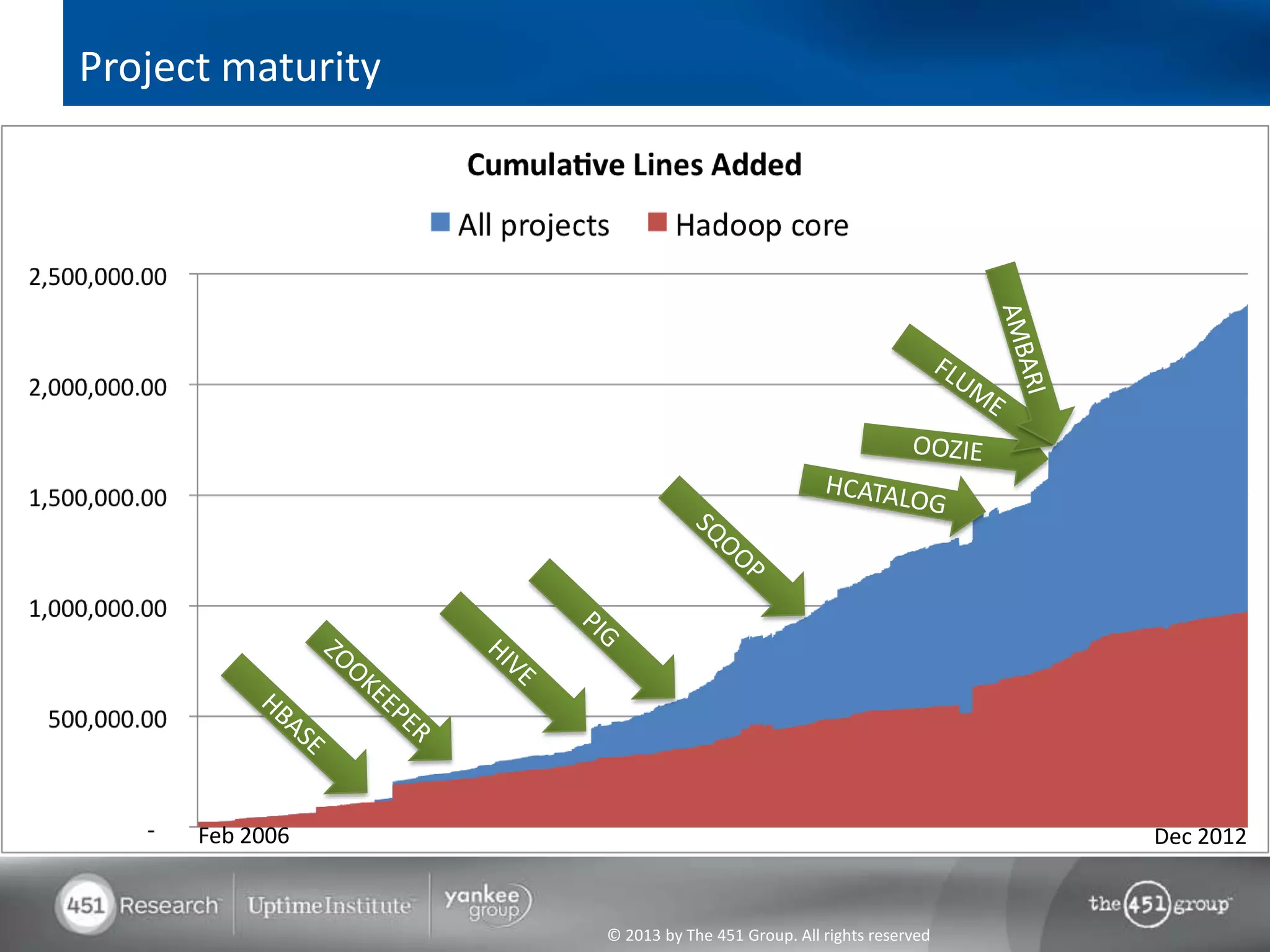
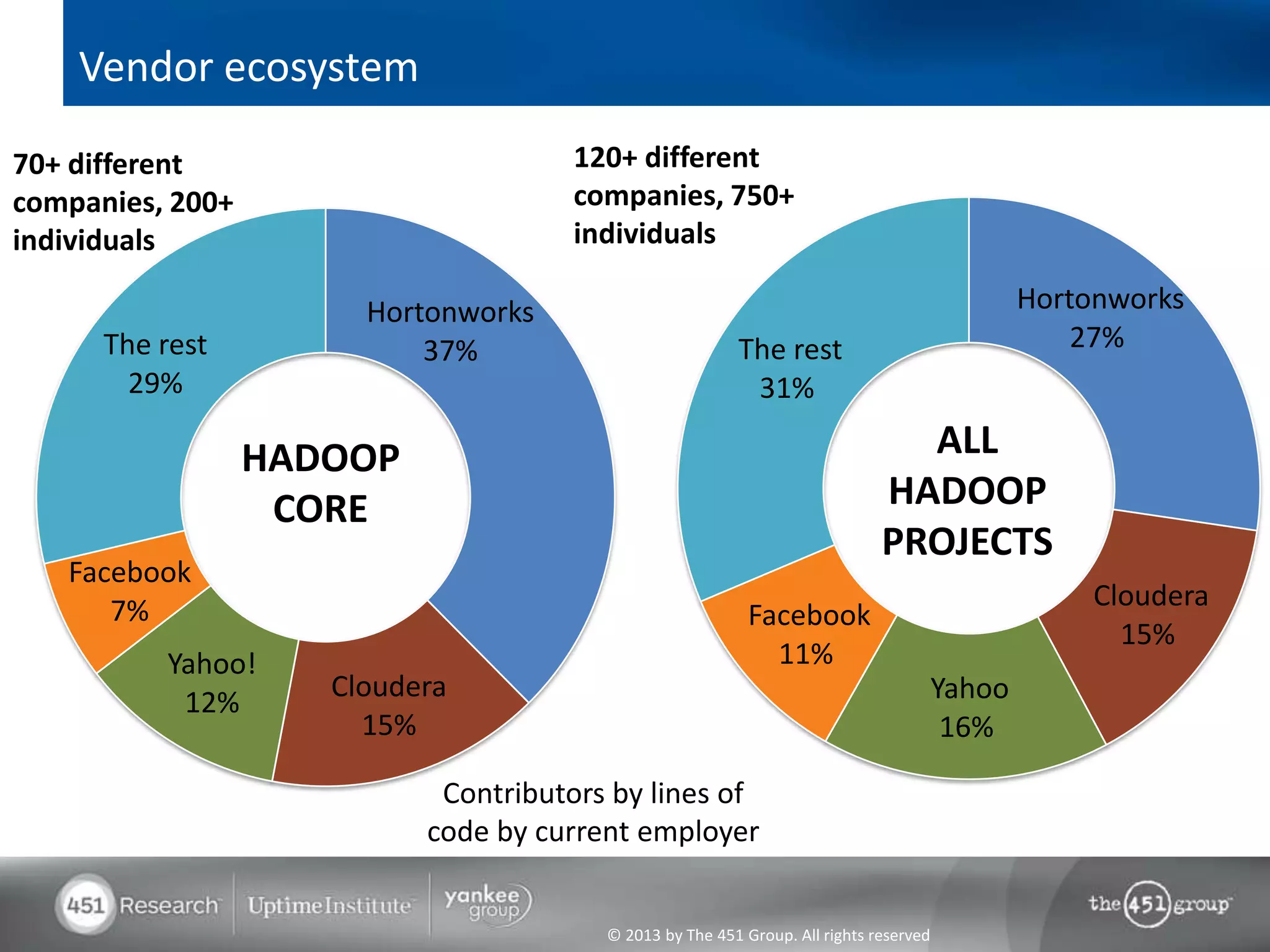
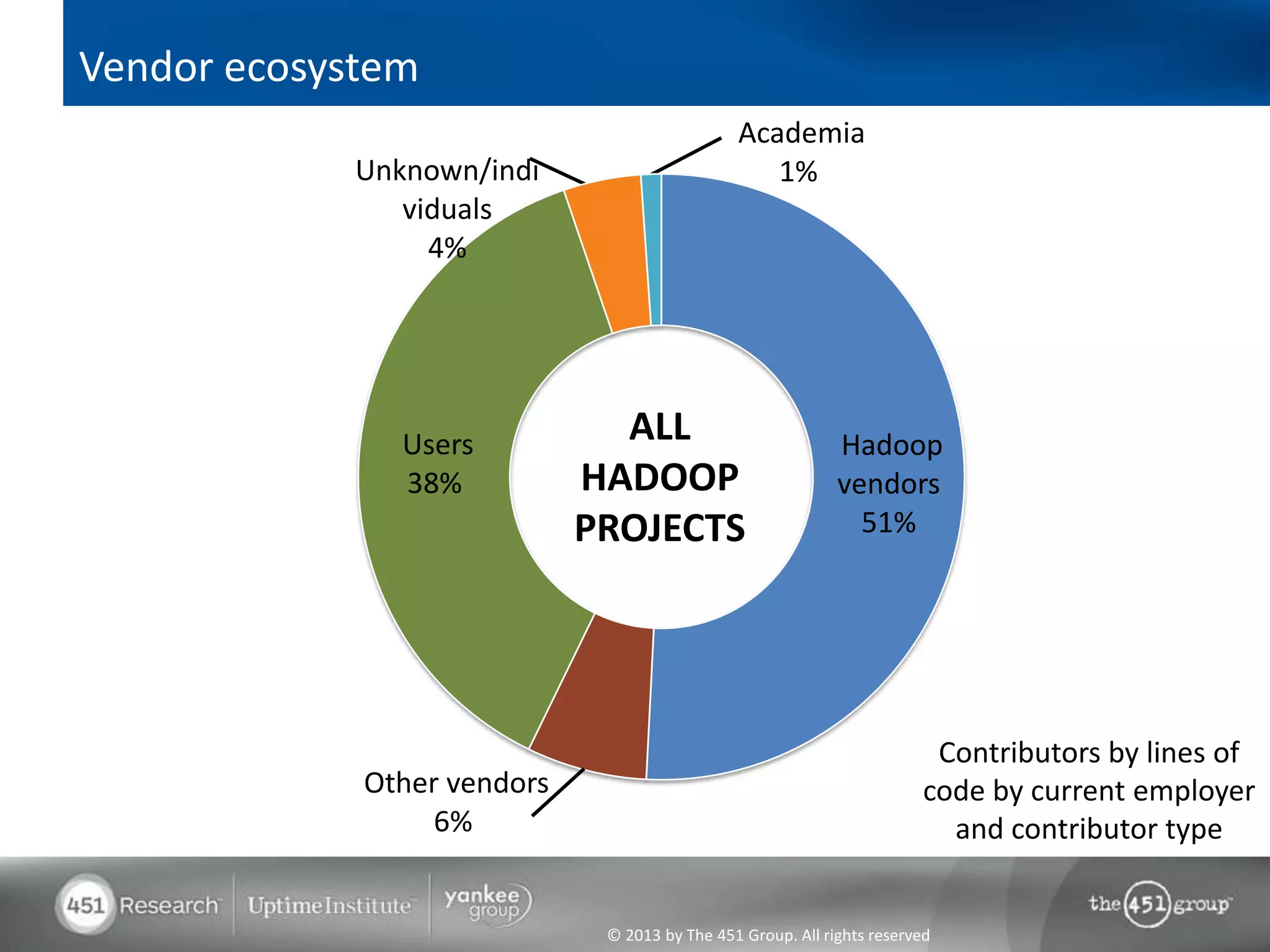
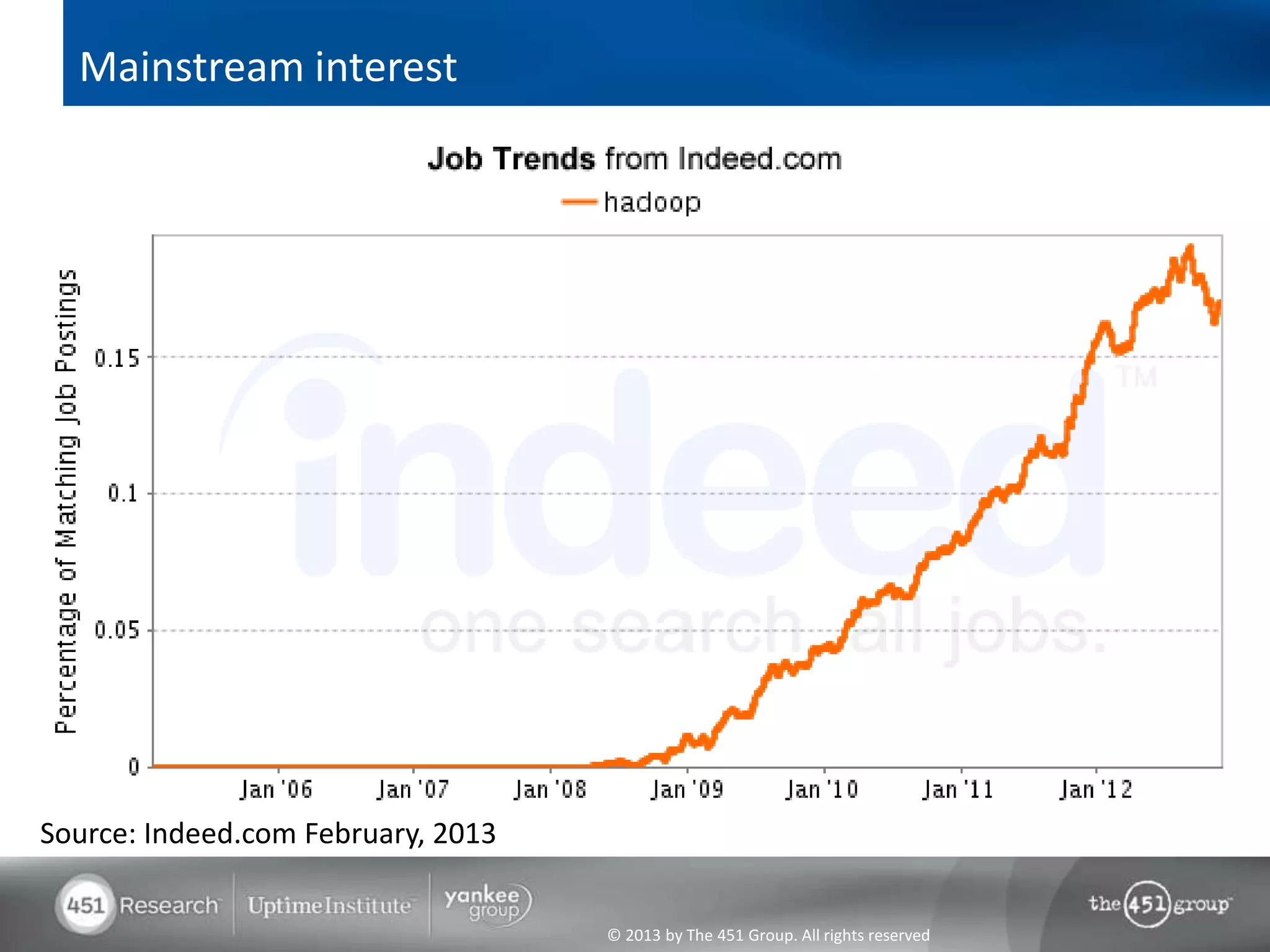
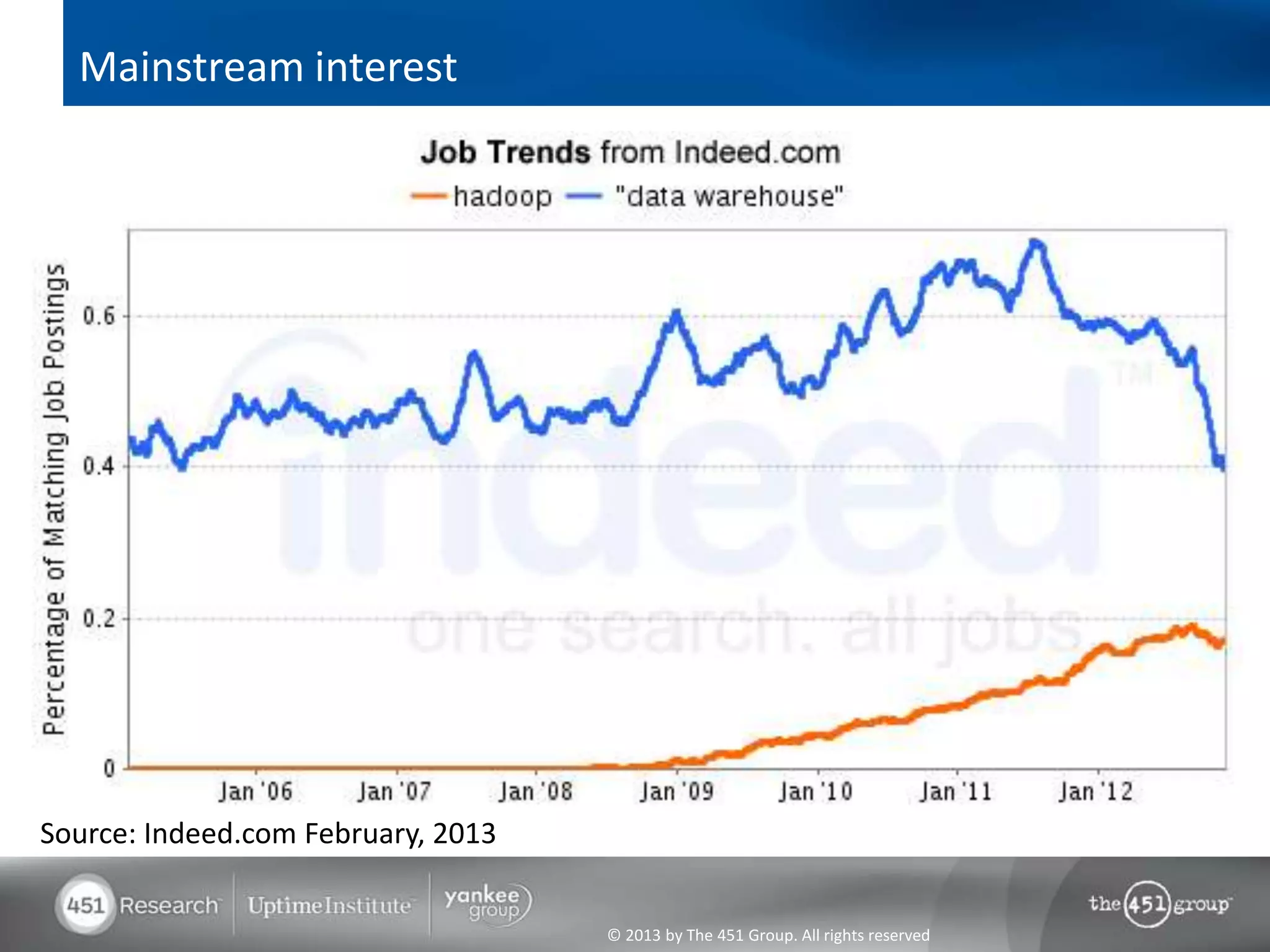
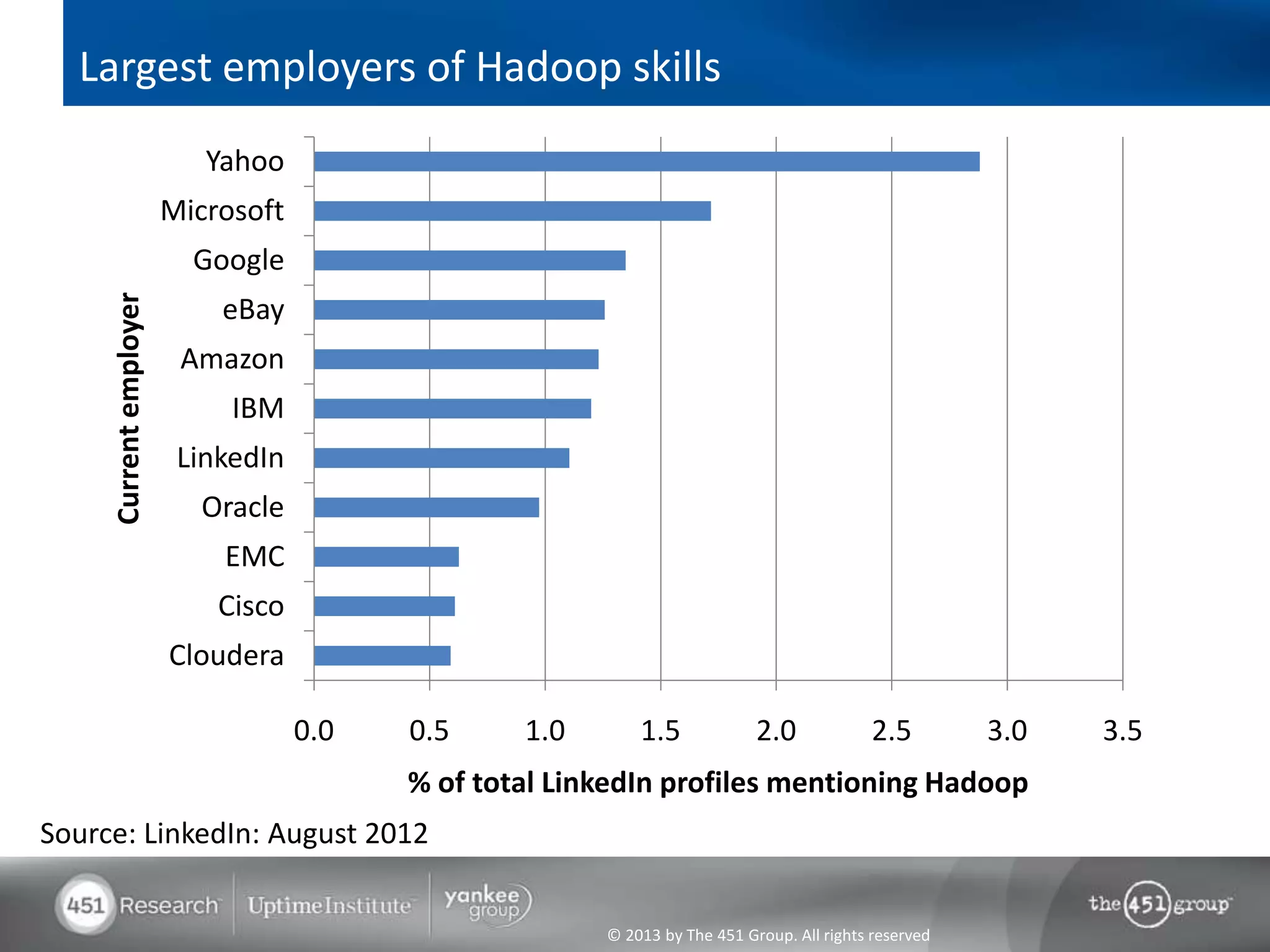
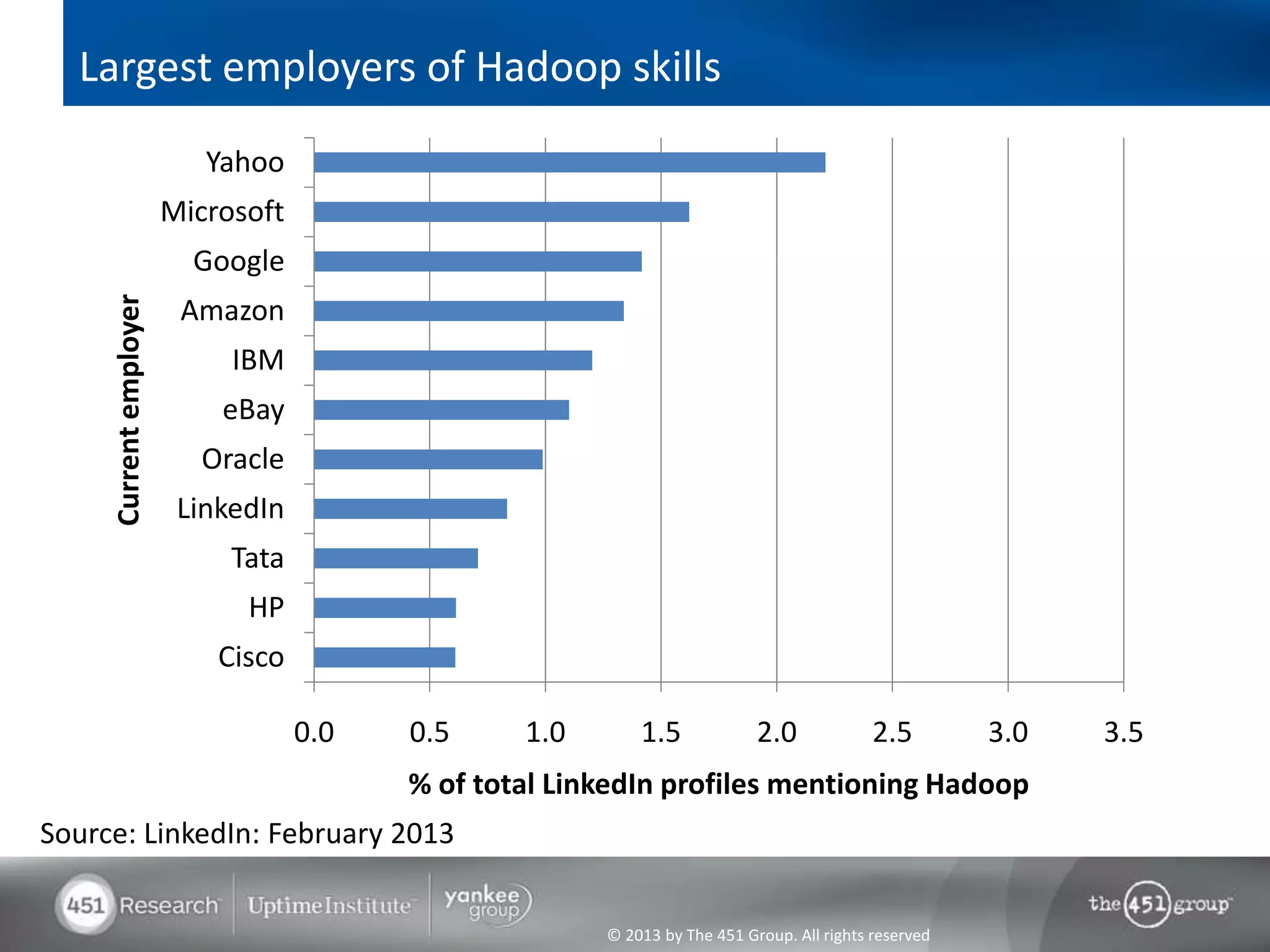
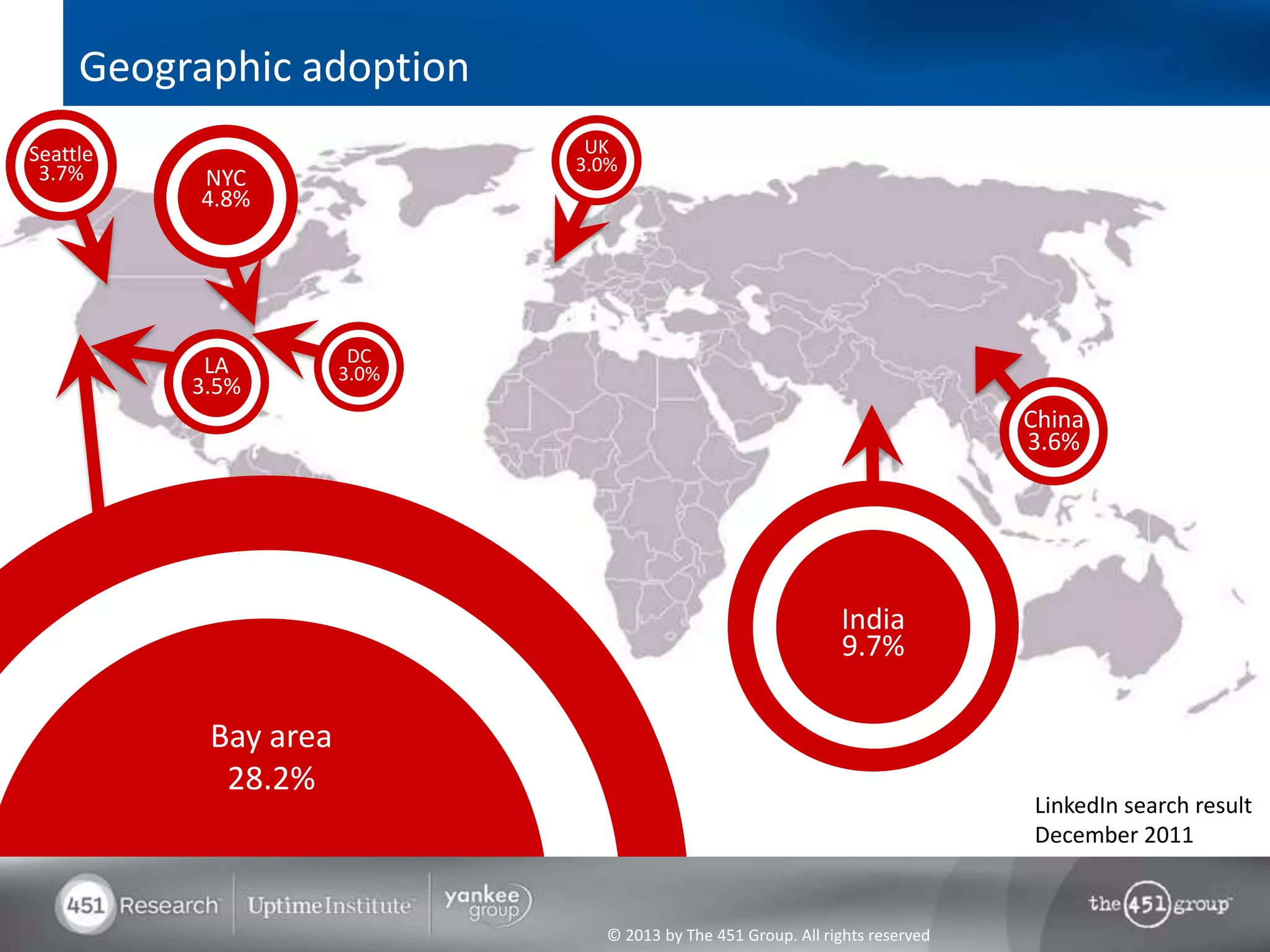
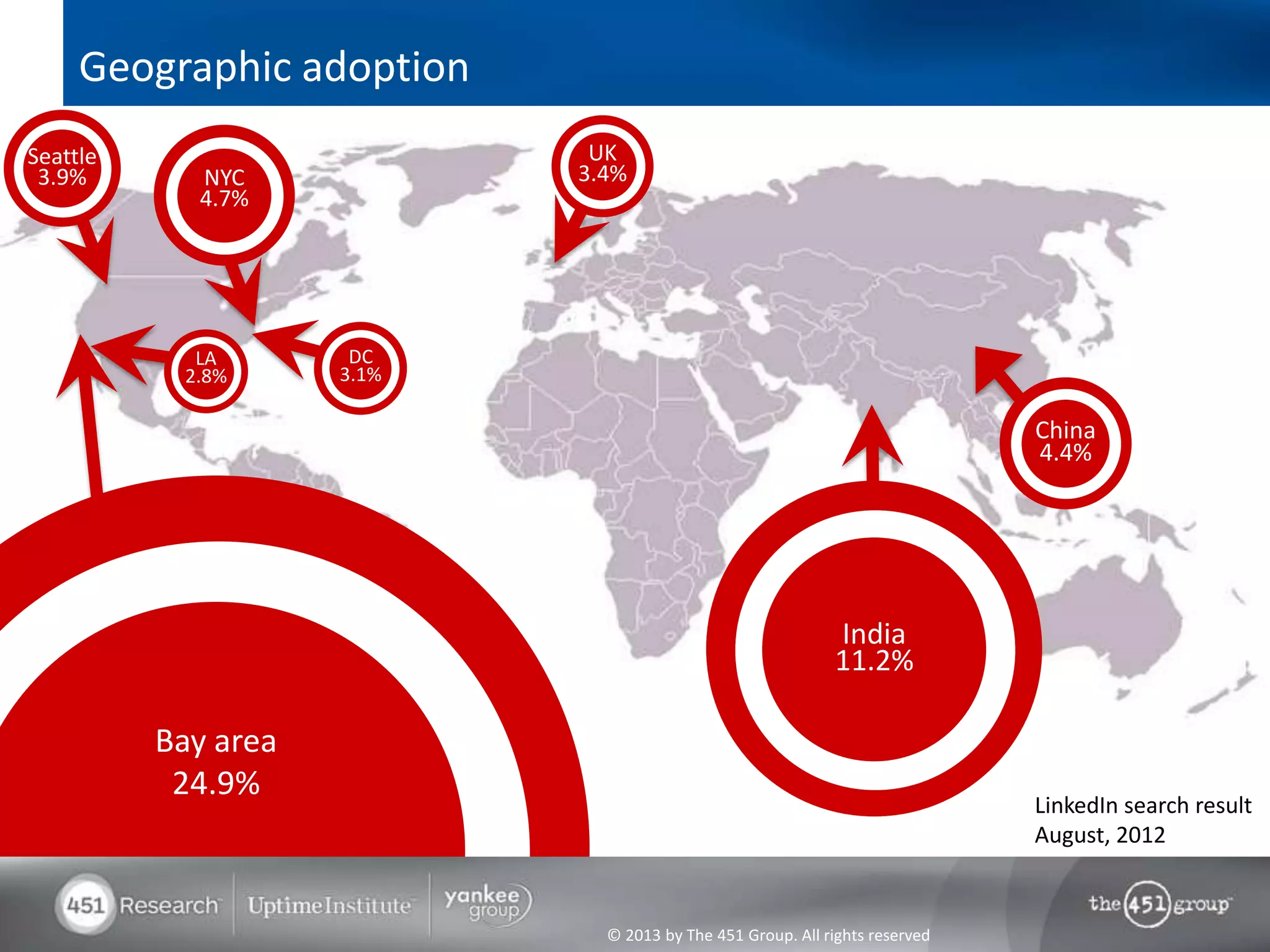
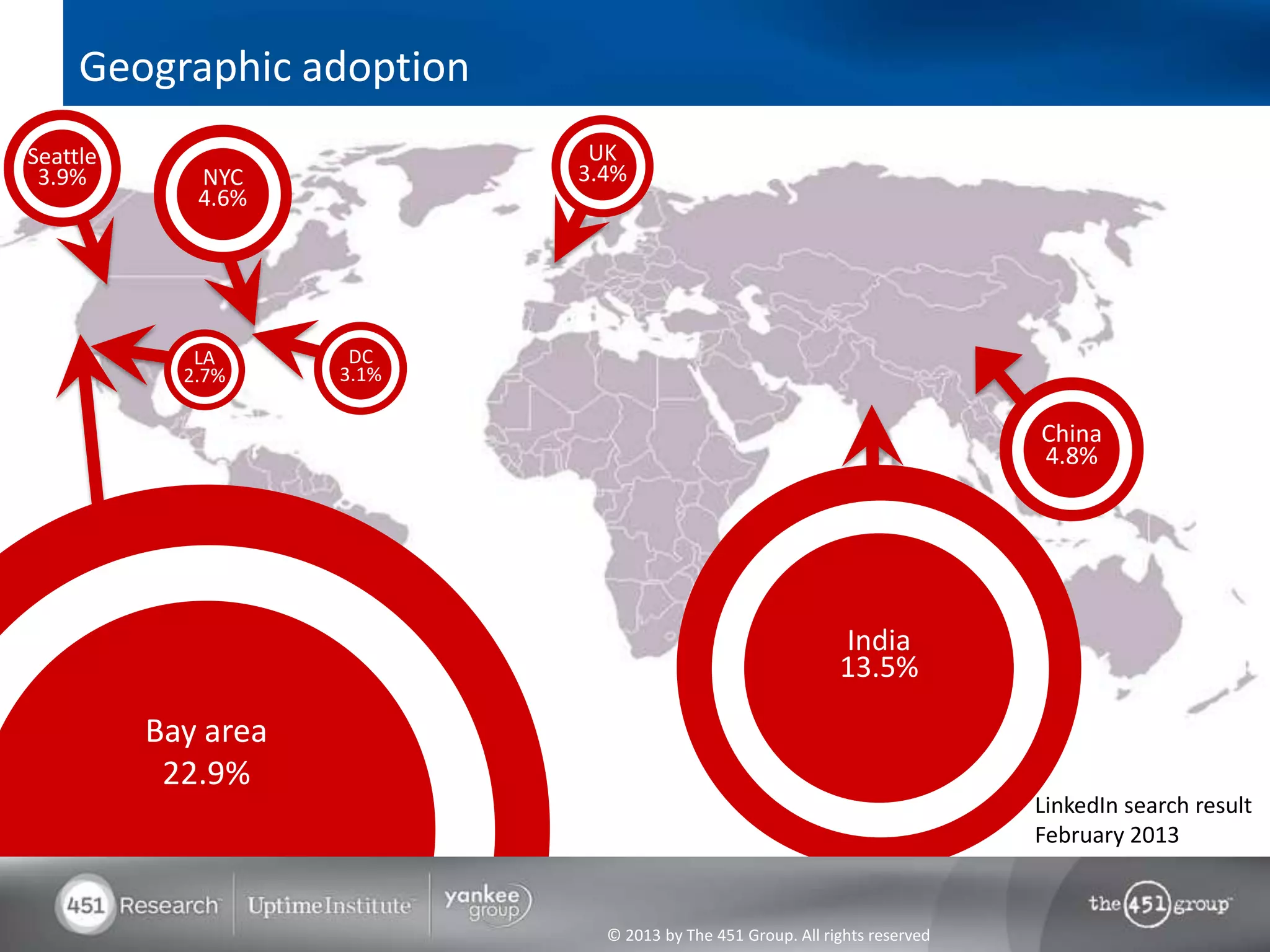
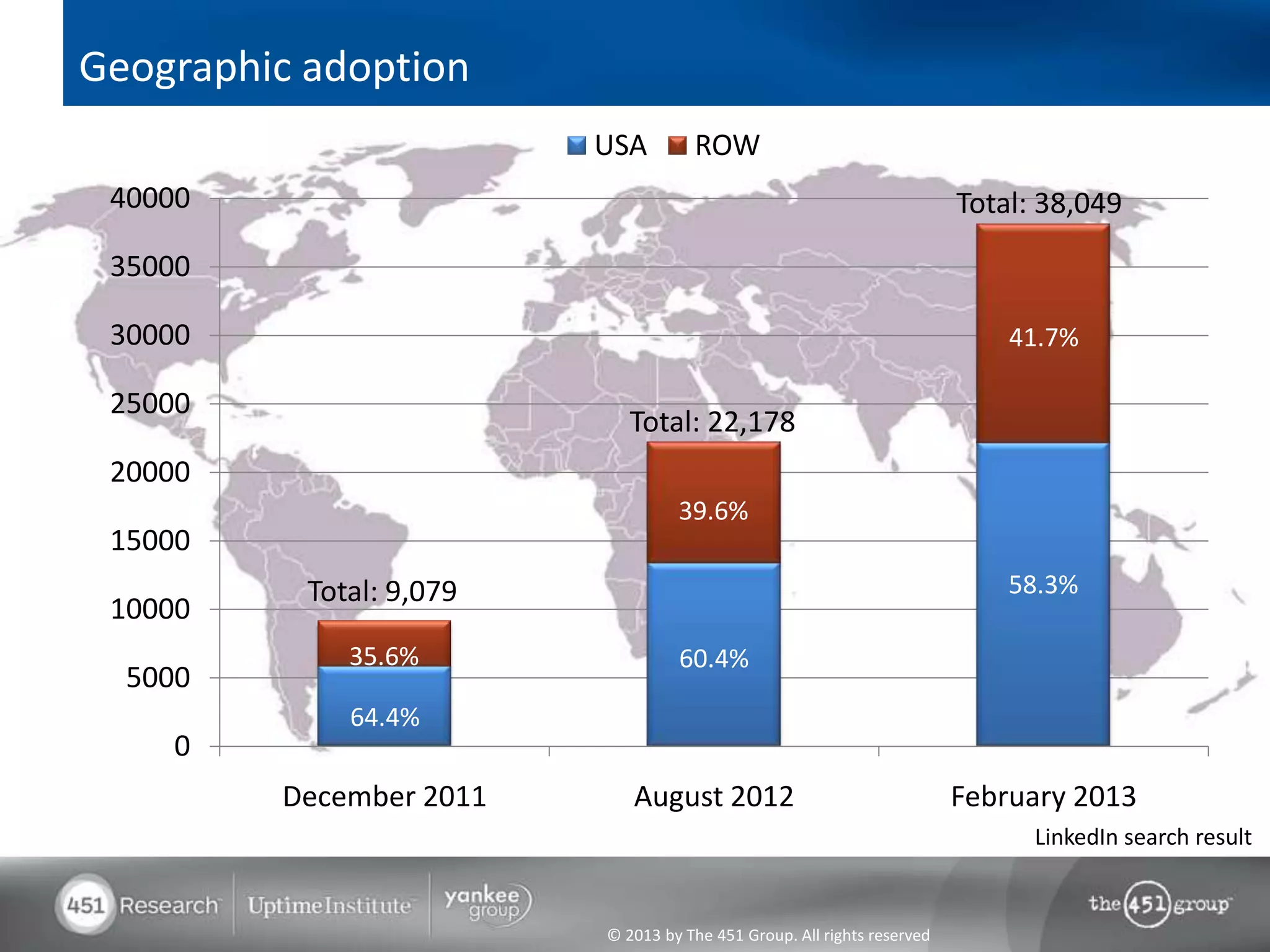



Hadoop's flexibility is its greatest strength, allowing it to serve multiple roles in data processing but also leading to confusion among users. It facilitates advanced business intelligence by enabling the storage, processing, and analysis of previously ignored data due to the constraints of traditional data management technologies. The document underscores the importance of fully leveraging Hadoop in all stages of data management to avoid silos and disillusionment, highlighting its growing mainstream adoption.






















































































