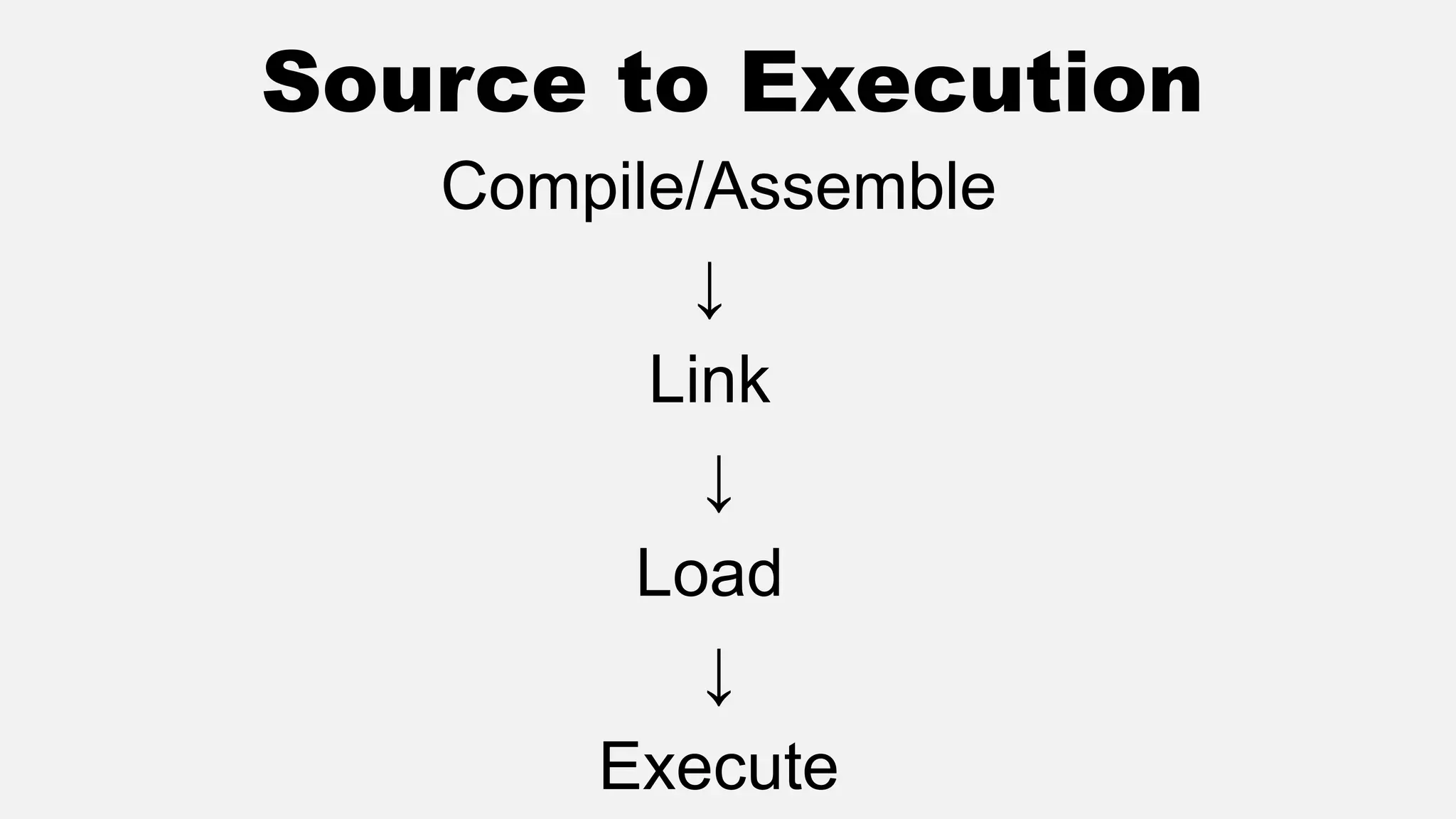
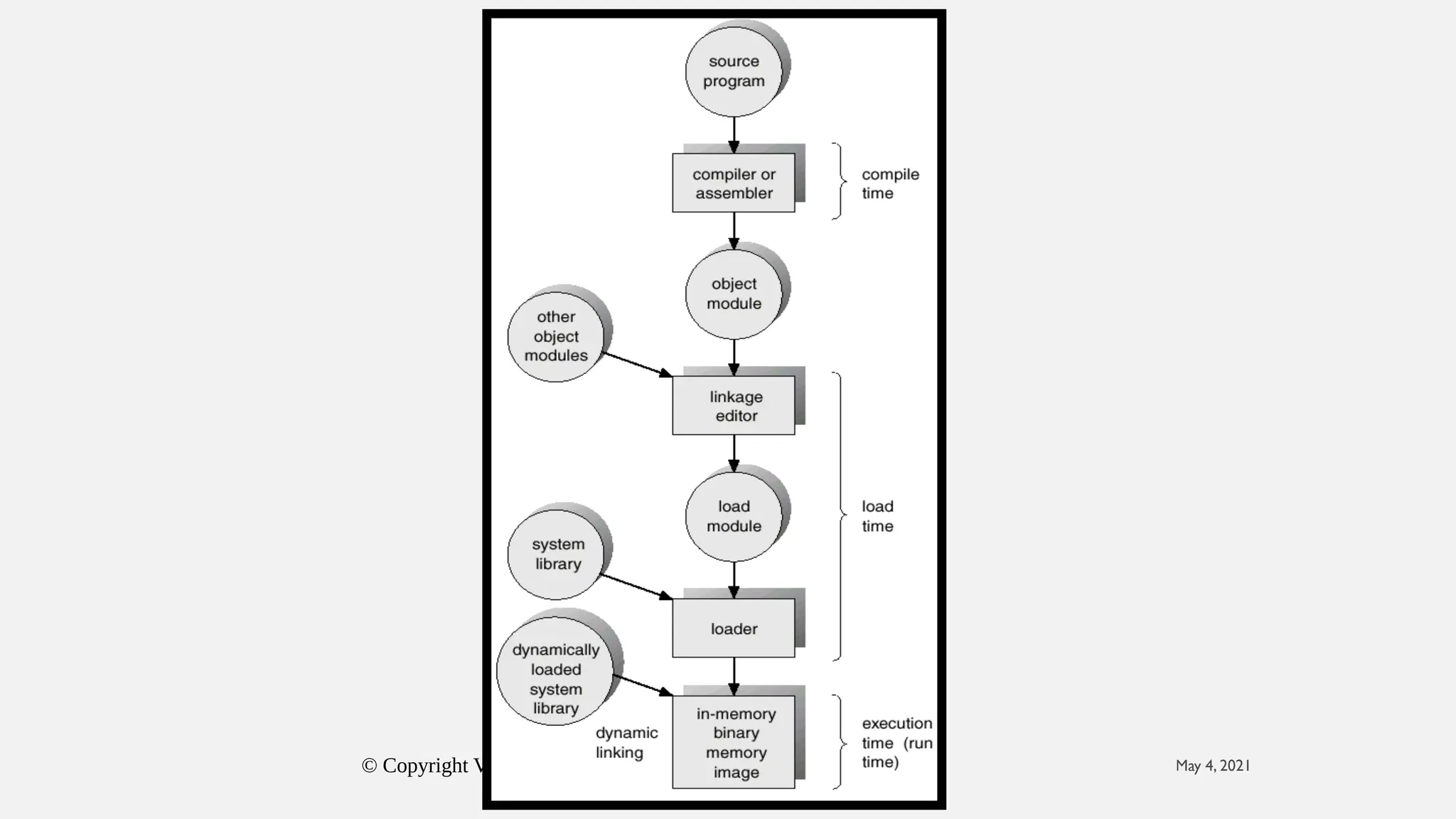
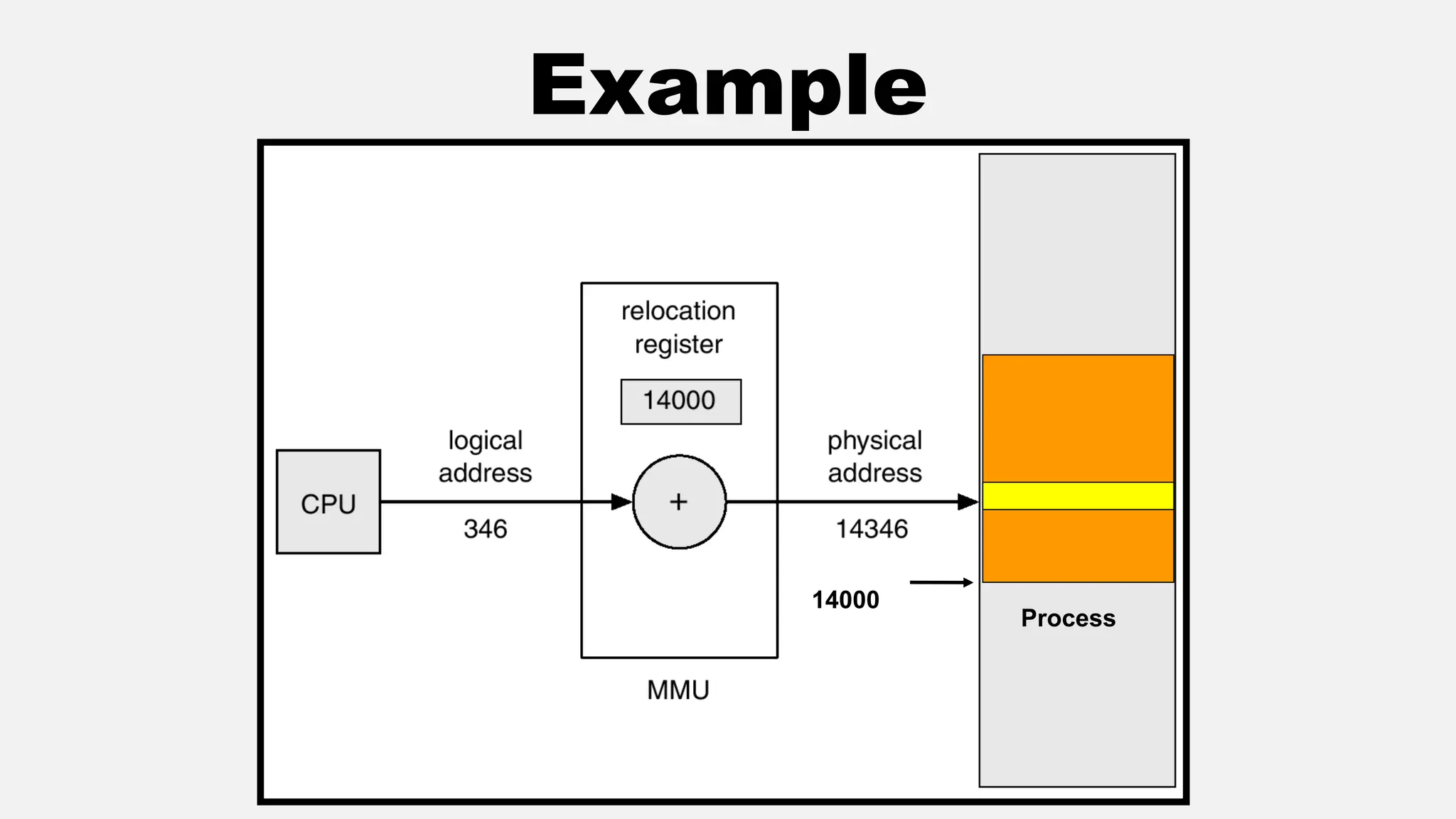
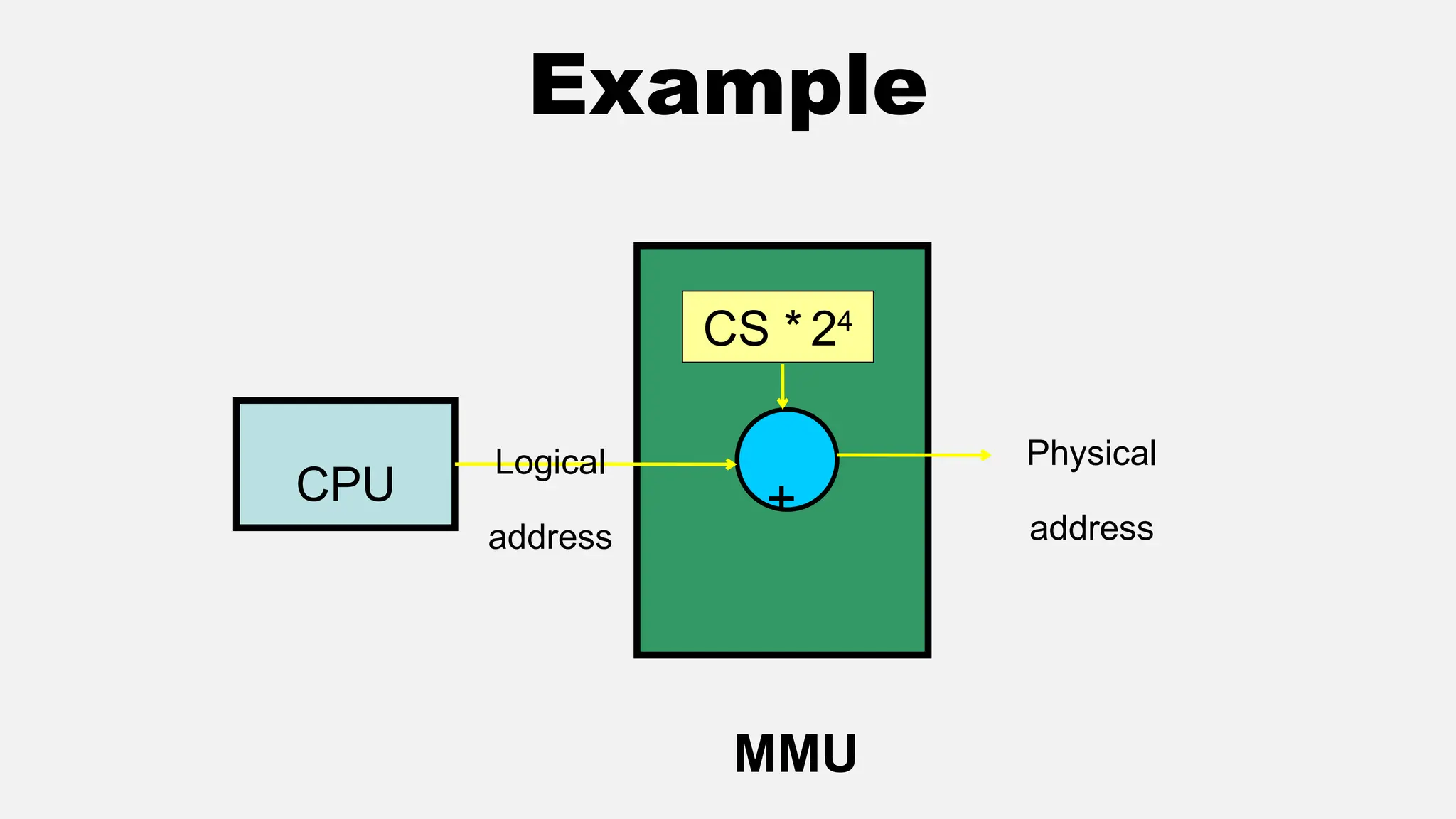
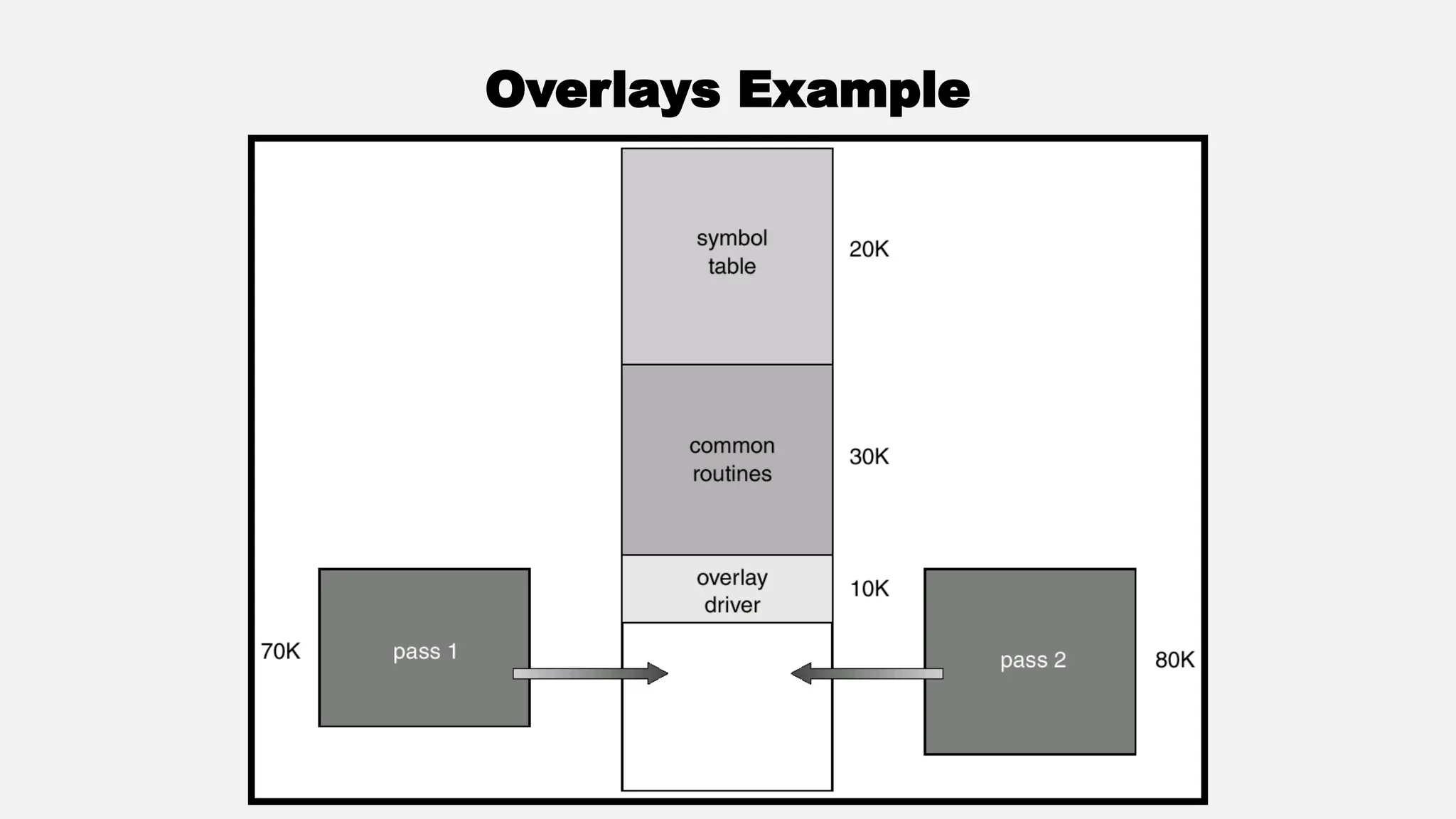
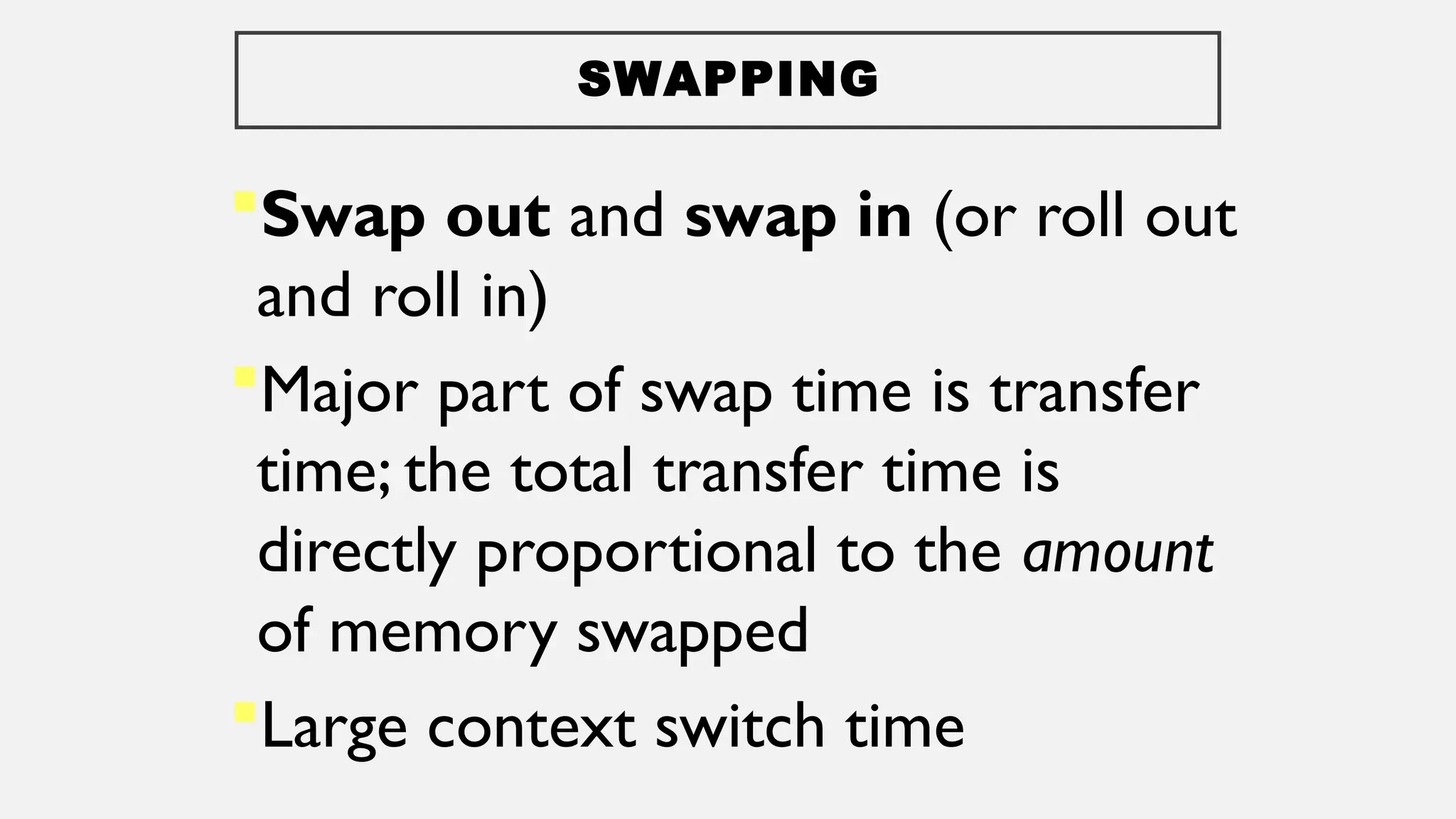
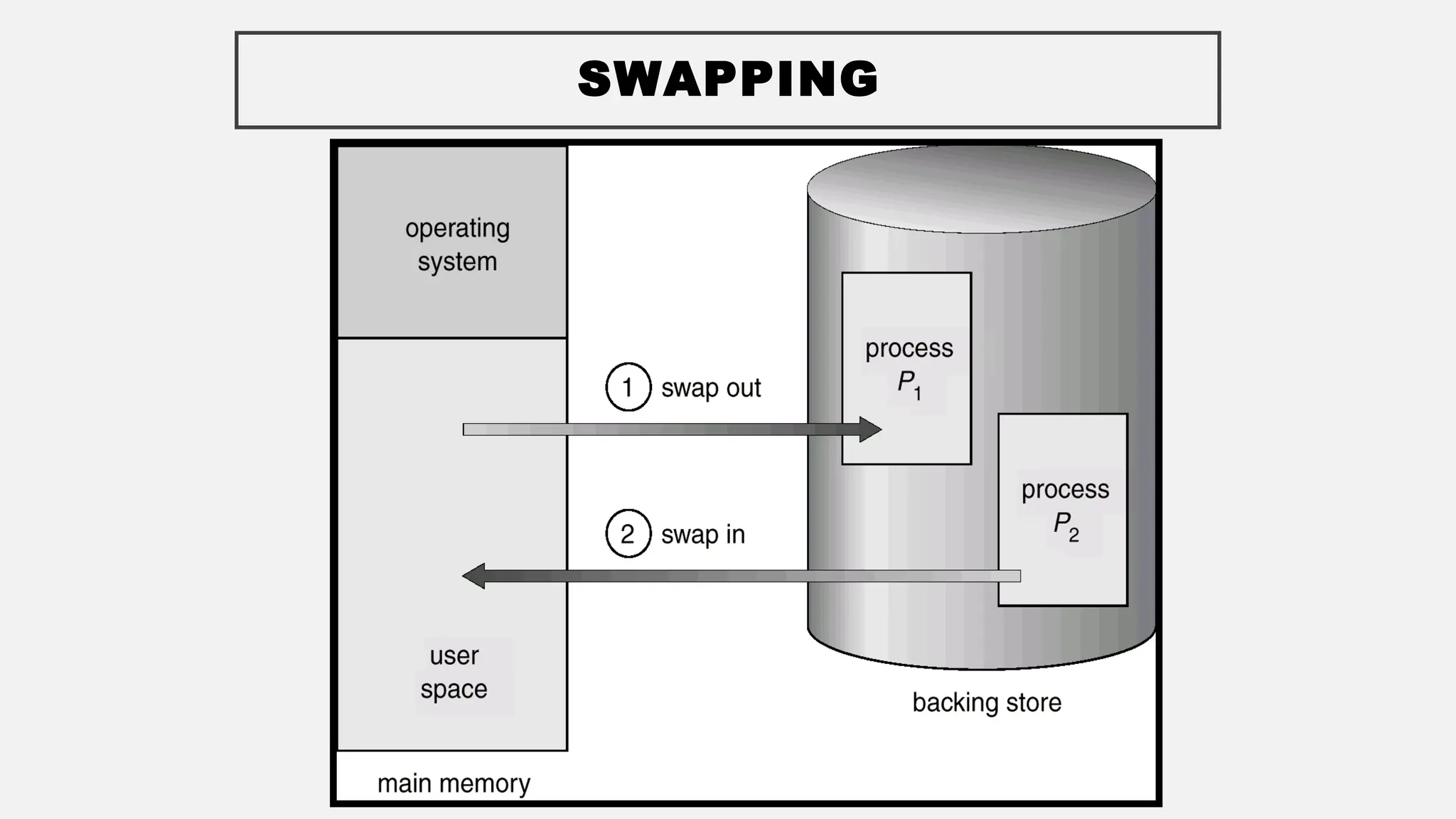
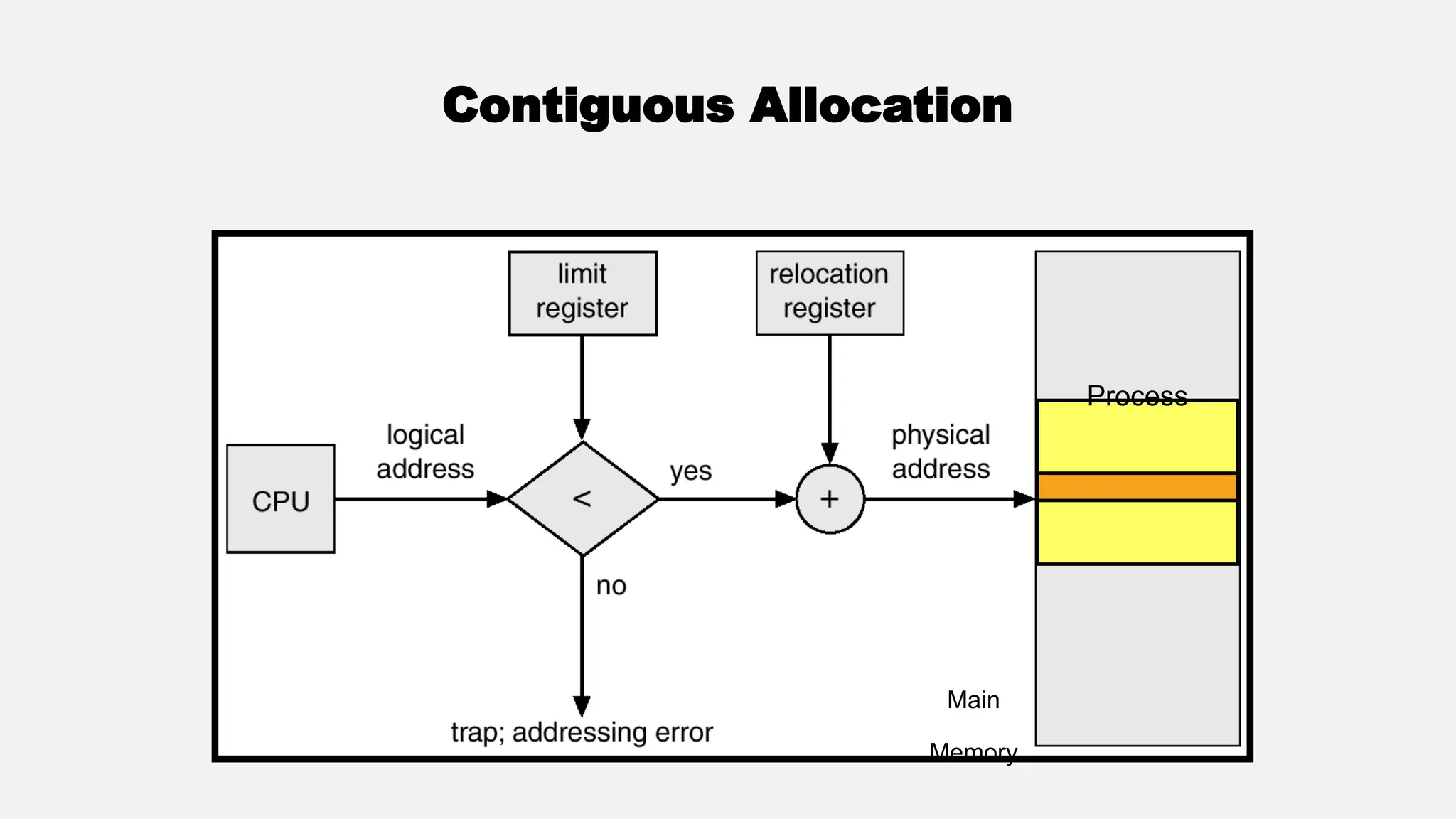
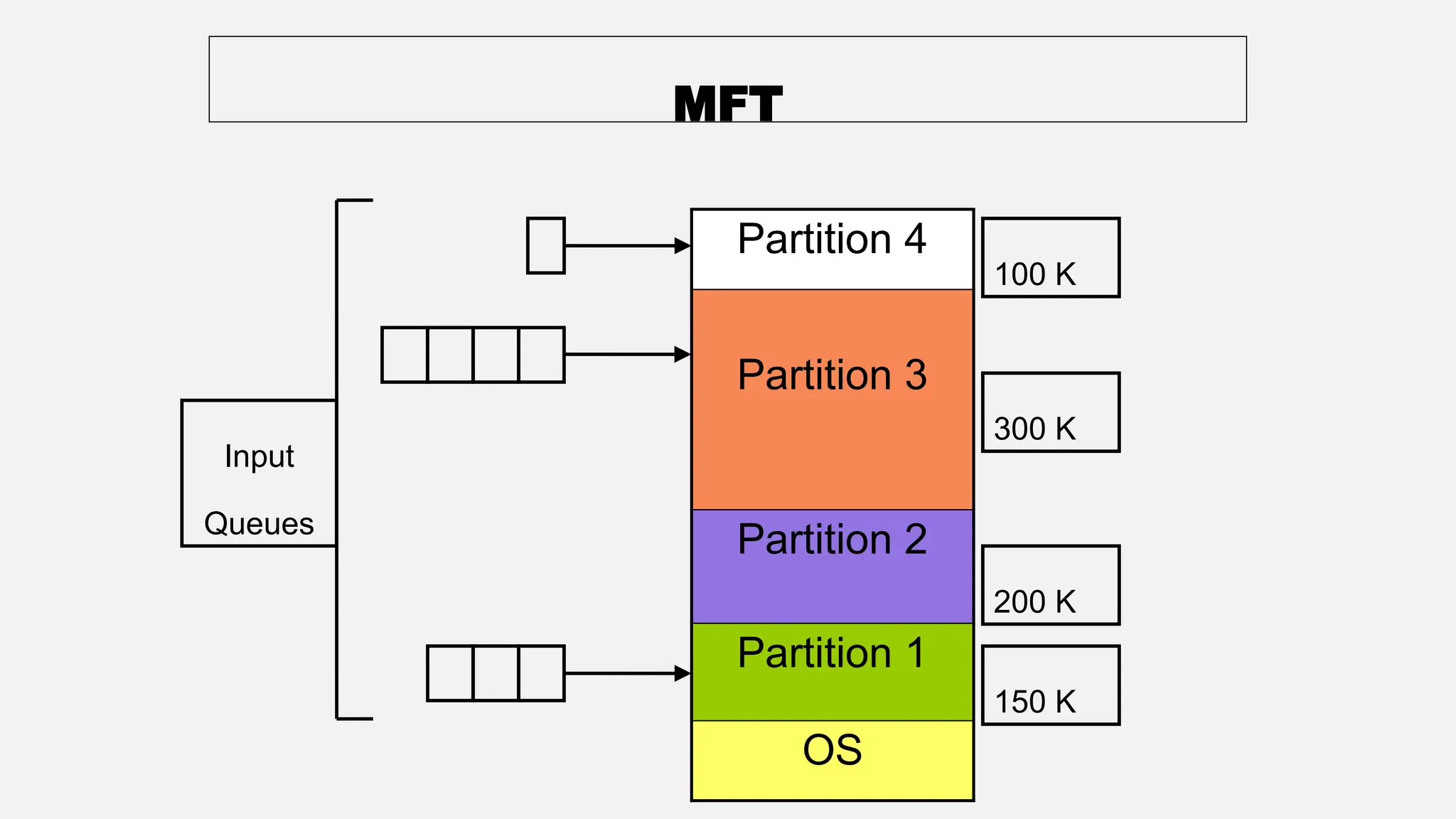
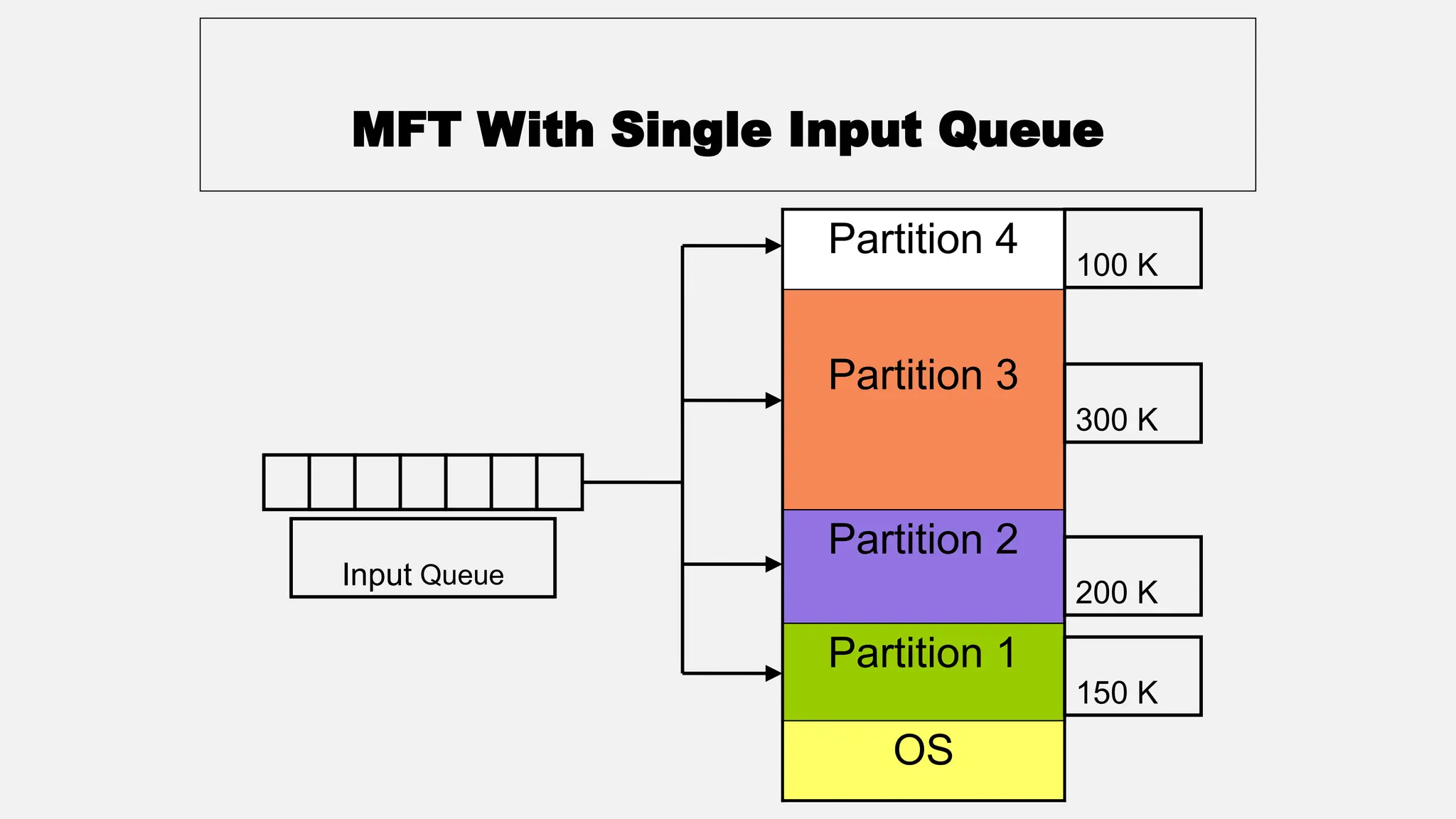
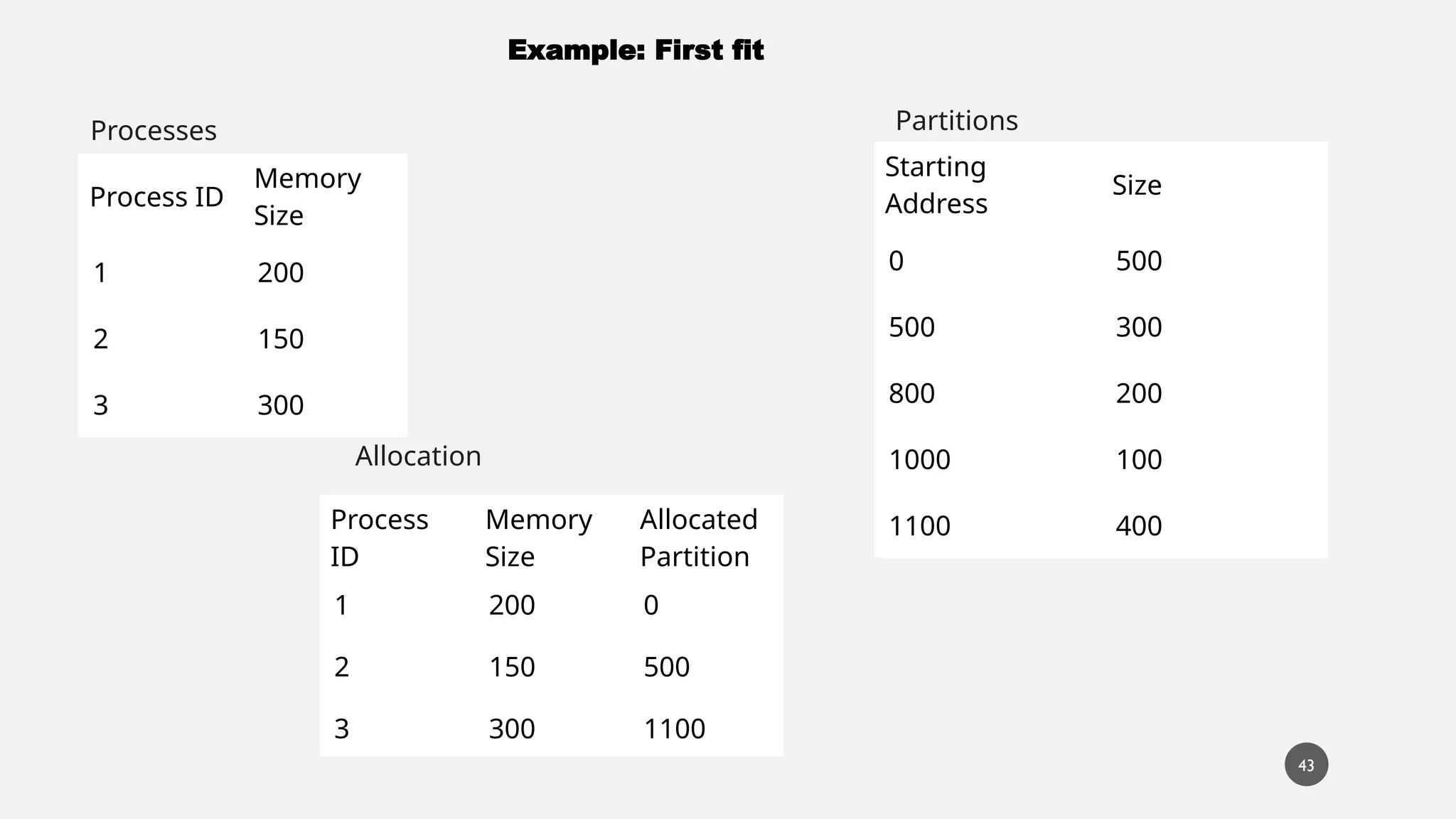
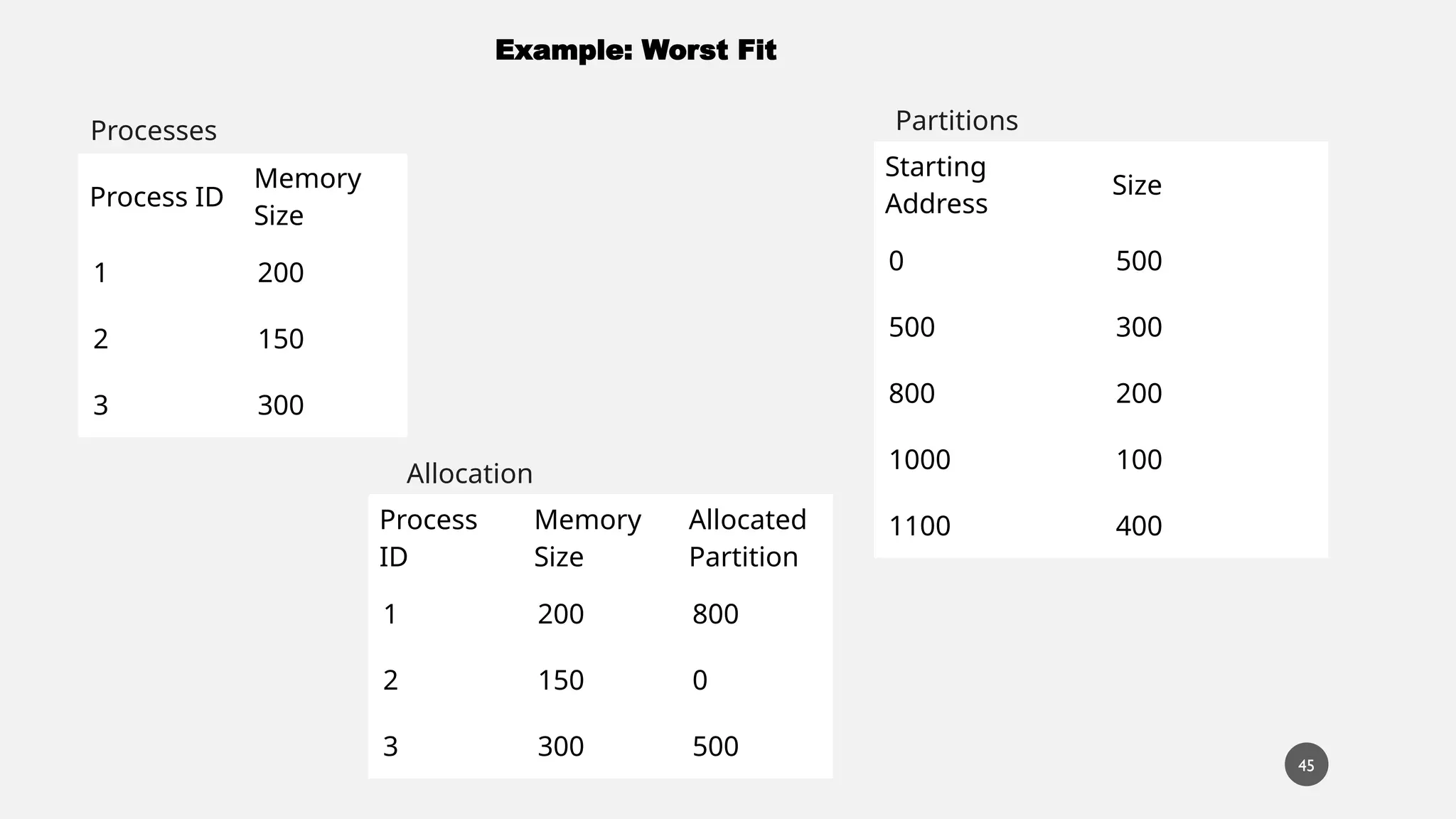
The document discusses memory management in operating systems, covering topics such as address binding, logical and physical address spaces, and memory hierarchy. It explains techniques like dynamic loading, dynamic linking, and overlays to optimize memory use during program execution. Additionally, concepts related to swapping processes and memory allocation strategies are explored, alongside practical examples of memory partitioning techniques.