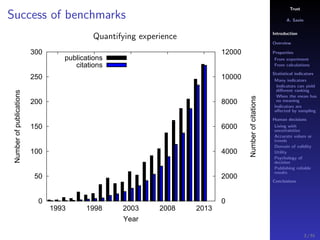
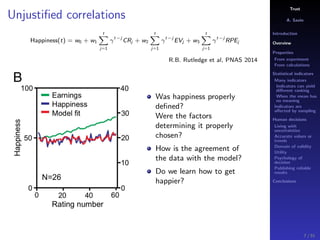
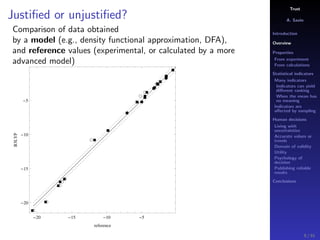
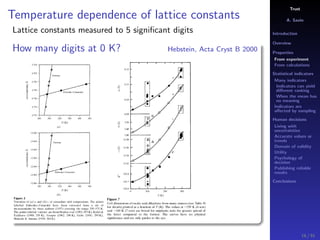
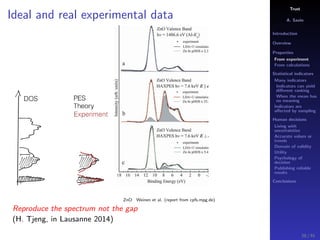
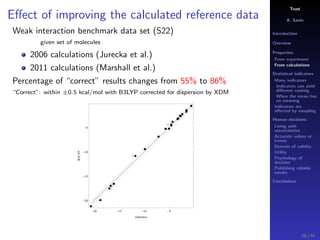
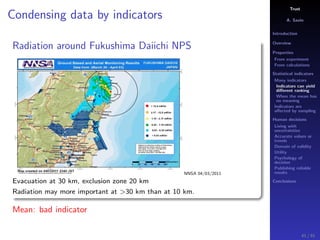
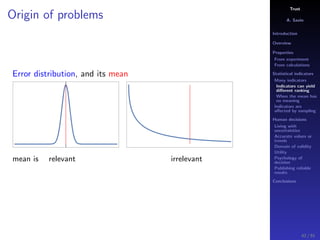
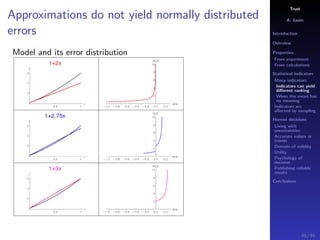
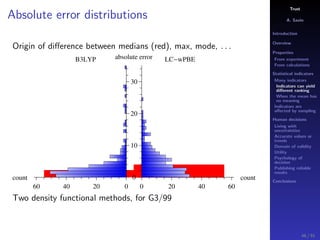
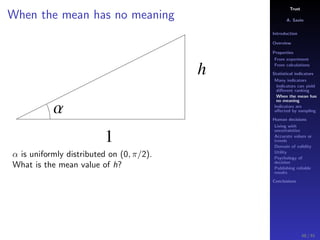
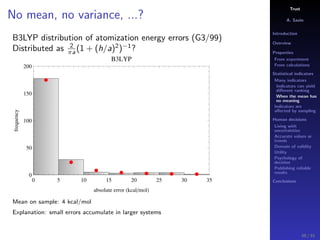
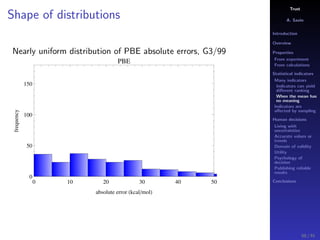
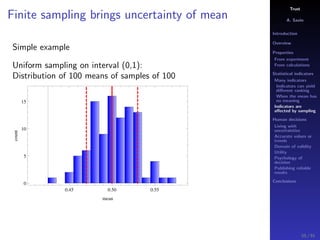
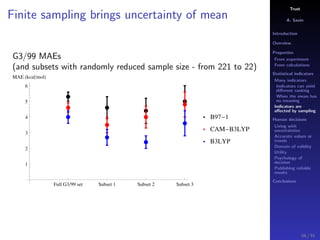
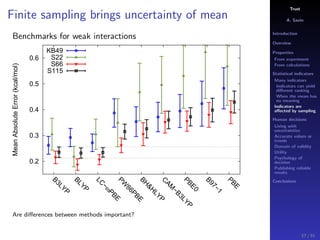
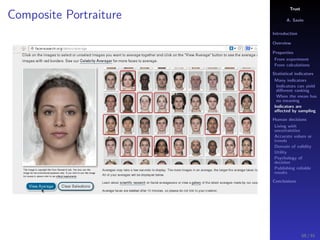
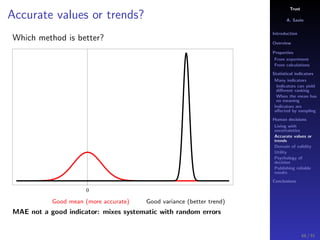
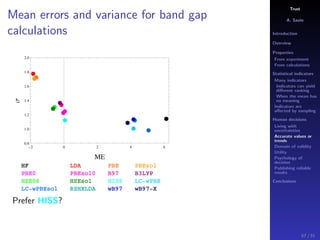
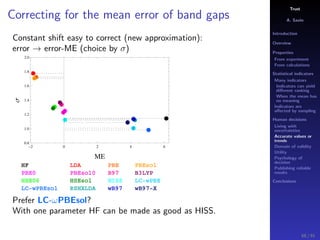
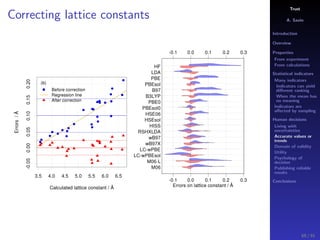
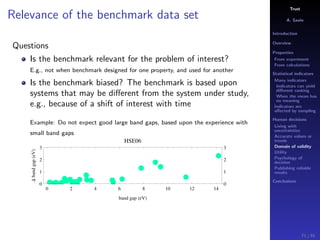
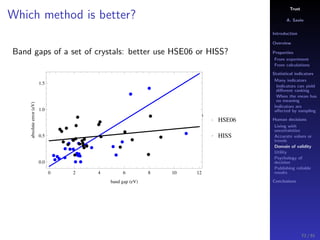
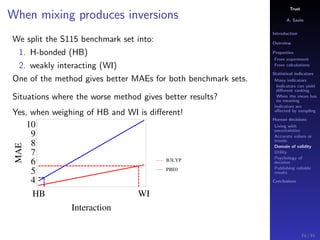
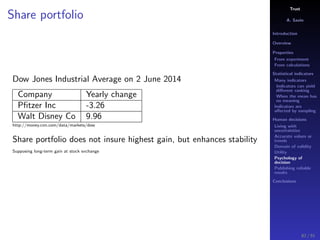
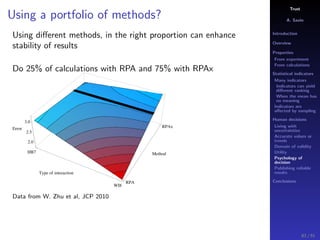
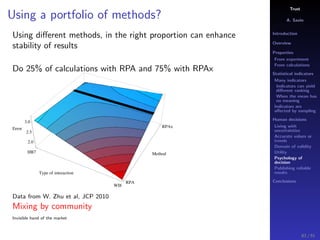
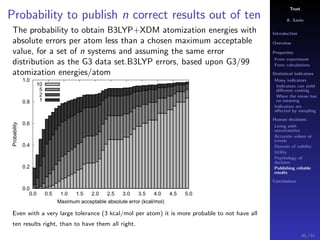
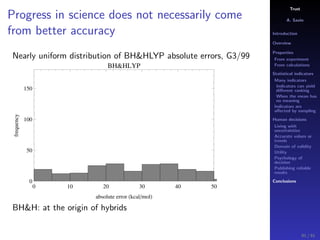
The document discusses the complexities of interpreting statistical indicators and experimental data within the context of decision-making and reliability. It emphasizes the influence of sampling, human judgment, and the inherent uncertainties in deriving accurate values or trends from various sources. The conclusions suggest a need for careful consideration of the methodologies used in statistical predictions and the validation of results against benchmark data.







































































































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)

















