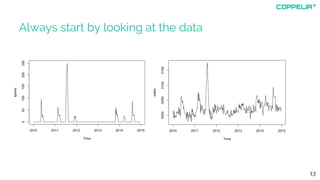
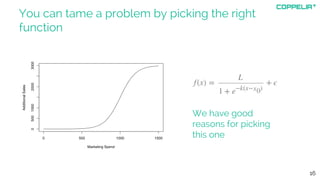
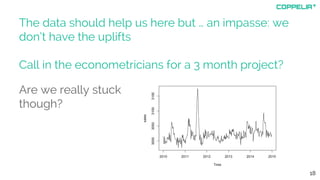
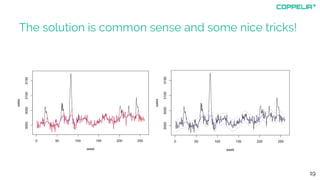
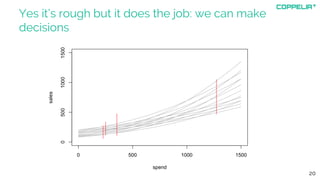
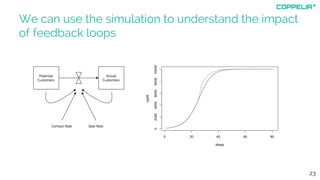
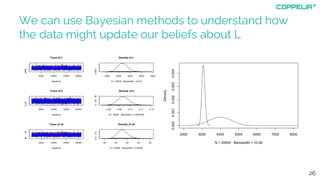
The document discusses modeling techniques for business decision making. It introduces Simon Raper and his expertise in areas like statistics, simulation, machine learning and coding. The document then uses an example of determining a marketing budget to illustrate how to build a simple model quickly using available data and common sense assumptions. It discusses exploring the model dynamics through simulation, uncertainty through Monte Carlo simulation, and updating assumptions based on new data using Bayesian inference. The key is building a useful model that directly informs the decision, without unnecessary complexity or assumptions.