Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Koichi Fujikawa
1,080 views
Cloud computing competition by Hapyrus
Presentation for cloud competition in INTEROP 2010
Technology
◦
News & Politics
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 11 times
1
/ 9
2
/ 9
3
/ 9
4
/ 9
5
/ 9
6
/ 9
7
/ 9
8
/ 9
9
/ 9
More Related Content
PPTX
20071030
by
小野 修司
PPTX
SQLチューニング入門 入門編
by
Miki Shimogai
PDF
[東京] JapanSharePointGroup 勉強会 #2
by
Atsuo Yamasaki
PDF
[TL06] 日本の第一人者が C# の現状と今後を徹底解説! 「この素晴らしい C# に祝福を!」
by
de:code 2017
PPT
20090107 Postgre Sqlチューニング(Sql編)
by
Hiromu Shioya
PPTX
BPStudy32 CouchDB 再入門
by
Yohei Sasaki
KEY
はじめてのCouch db
by
Eiji Kuroda
PPTX
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~
by
Miki Shimogai
20071030
by
小野 修司
SQLチューニング入門 入門編
by
Miki Shimogai
[東京] JapanSharePointGroup 勉強会 #2
by
Atsuo Yamasaki
[TL06] 日本の第一人者が C# の現状と今後を徹底解説! 「この素晴らしい C# に祝福を!」
by
de:code 2017
20090107 Postgre Sqlチューニング(Sql編)
by
Hiromu Shioya
BPStudy32 CouchDB 再入門
by
Yohei Sasaki
はじめてのCouch db
by
Eiji Kuroda
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~
by
Miki Shimogai
What's hot
PDF
「Grails-1.1を斬る!〜Grails-1.1からのチーム開発〜」
by
Tsuyoshi Yamamoto
PDF
PostgreSQL 10 新機能 @オープンセミナー香川 2017
by
Shigeru Hanada
PDF
Sqoopコネクタを書いてみた (Hadoopソースコードリーディング第12回 発表資料)
by
NTT DATA OSS Professional Services
PPT
クラウド時代の並列分散処理技術
by
Koichi Fujikawa
PDF
Elasticsearch入門 pyfes 201207
by
Jun Ohtani
PDF
PostgreSQLの実行計画を読み解こう(OSC2015 Spring/Tokyo)
by
Satoshi Yamada
PDF
Pg14_sql_standard_function_body
by
kasaharatt
PDF
Teclab3
by
Eikichi Yamaguchi
PDF
20140531 JPUGしくみ+アプリケーション分科会 勉強会資料
by
kasaharatt
PDF
ふぉとぶらり+LODAC -iPhoneアプリでのSPARQLでの活用事例-
by
uedayou
PPTX
JEP280: Java 9 で文字列結合の処理が変わるぞ!準備はいいか!? #jjug_ccc
by
YujiSoftware
PDF
PostgreSQLの関数属性を知ろう
by
kasaharatt
PDF
PostgreSQLとPythonとSQL
by
Satoshi Yamada
PPTX
Project lambda
by
Appresso Engineering Team
PDF
RailsエンジニアのためのSQLチューニング速習会
by
Nao Minami
PDF
PythonでテキストをJSONにした話(PyCon mini sapporo 2015)
by
Satoshi Yamada
PDF
「plyrパッケージで君も前処理スタ☆」改め「plyrパッケージ徹底入門」
by
Nagi Teramo
PDF
PostgreSQL:行数推定を読み解く
by
Hiroya Kabata
PDF
PostgreSQL SQLチューニング入門 実践編(pgcon14j)
by
Satoshi Yamada
「Grails-1.1を斬る!〜Grails-1.1からのチーム開発〜」
by
Tsuyoshi Yamamoto
PostgreSQL 10 新機能 @オープンセミナー香川 2017
by
Shigeru Hanada
Sqoopコネクタを書いてみた (Hadoopソースコードリーディング第12回 発表資料)
by
NTT DATA OSS Professional Services
クラウド時代の並列分散処理技術
by
Koichi Fujikawa
Elasticsearch入門 pyfes 201207
by
Jun Ohtani
PostgreSQLの実行計画を読み解こう(OSC2015 Spring/Tokyo)
by
Satoshi Yamada
Pg14_sql_standard_function_body
by
kasaharatt
Teclab3
by
Eikichi Yamaguchi
20140531 JPUGしくみ+アプリケーション分科会 勉強会資料
by
kasaharatt
ふぉとぶらり+LODAC -iPhoneアプリでのSPARQLでの活用事例-
by
uedayou
JEP280: Java 9 で文字列結合の処理が変わるぞ!準備はいいか!? #jjug_ccc
by
YujiSoftware
PostgreSQLの関数属性を知ろう
by
kasaharatt
PostgreSQLとPythonとSQL
by
Satoshi Yamada
Project lambda
by
Appresso Engineering Team
RailsエンジニアのためのSQLチューニング速習会
by
Nao Minami
PythonでテキストをJSONにした話(PyCon mini sapporo 2015)
by
Satoshi Yamada
「plyrパッケージで君も前処理スタ☆」改め「plyrパッケージ徹底入門」
by
Nagi Teramo
PostgreSQL:行数推定を読み解く
by
Hiroya Kabata
PostgreSQL SQLチューニング入門 実践編(pgcon14j)
by
Satoshi Yamada
Viewers also liked
PDF
Rakuten tech conf
by
Koichi Fujikawa
DOC
Technology Plan For Stevenson Ms Table
by
Dana Luterman
PPT
GUIAS DE NADAL
by
boello
PPT
Trends WCM 2010
by
Martijn Hoeijmans
PDF
Hadoop Conf Japan 2009 After Party LT - Hadoop Ruby DSL
by
Koichi Fujikawa
PDF
Design of a_dsl_by_ruby_for_heavy_computations
by
Koichi Fujikawa
Rakuten tech conf
by
Koichi Fujikawa
Technology Plan For Stevenson Ms Table
by
Dana Luterman
GUIAS DE NADAL
by
boello
Trends WCM 2010
by
Martijn Hoeijmans
Hadoop Conf Japan 2009 After Party LT - Hadoop Ruby DSL
by
Koichi Fujikawa
Design of a_dsl_by_ruby_for_heavy_computations
by
Koichi Fujikawa
Similar to Cloud computing competition by Hapyrus
PDF
ただいまHadoop勉強中
by
Satoshi Noto
PDF
MapReduce入門
by
Satoshi Noto
PDF
Hadoop jobbuilder
by
Taku Miyakawa
PDF
Oedo Ruby Conference 04: Ruby会議でSQLの話をするのは間違っているだろうか
by
Minero Aoki
PPT
Scala on Hadoop
by
Shinji Tanaka
PDF
OSC2011 Tokyo/Spring Hadoop入門
by
Shinichi YAMASHITA
PDF
Hadoop - OSC2010 Tokyo/Spring
by
Shinichi YAMASHITA
PDF
Hadoop事始め
by
You&I
PDF
OSC2012 OSC.DB Hadoop
by
Shinichi YAMASHITA
PDF
Java x Groovy: improve your java development life
by
Uehara Junji
PPTX
今さら聞けないHadoop勉強会第3回 セントラルソフト株式会社(20120327)
by
YoheiOkuyama
PDF
OSC2012 Tokyo/Spring - Hadoop入門
by
Shinichi YAMASHITA
PPT
Googleの基盤クローン Hadoopについて
by
Kazuki Ohta
PPT
Hadoopの紹介
by
bigt23
PPTX
今さら聞けないHadoop セントラルソフト株式会社(20120119)
by
Toru Takizawa
PDF
AspectJを用いた大規模分散システムHadoopの監視とプロファイリング
by
Yusuke Shimizu
PDF
Hadoop入門
by
Preferred Networks
PDF
MapReduce/YARNの仕組みを知る
by
日本ヒューレット・パッカード株式会社
PDF
日々進化するHadoopの 「いま」
by
NTT DATA OSS Professional Services
PDF
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演)
by
Hadoop / Spark Conference Japan
ただいまHadoop勉強中
by
Satoshi Noto
MapReduce入門
by
Satoshi Noto
Hadoop jobbuilder
by
Taku Miyakawa
Oedo Ruby Conference 04: Ruby会議でSQLの話をするのは間違っているだろうか
by
Minero Aoki
Scala on Hadoop
by
Shinji Tanaka
OSC2011 Tokyo/Spring Hadoop入門
by
Shinichi YAMASHITA
Hadoop - OSC2010 Tokyo/Spring
by
Shinichi YAMASHITA
Hadoop事始め
by
You&I
OSC2012 OSC.DB Hadoop
by
Shinichi YAMASHITA
Java x Groovy: improve your java development life
by
Uehara Junji
今さら聞けないHadoop勉強会第3回 セントラルソフト株式会社(20120327)
by
YoheiOkuyama
OSC2012 Tokyo/Spring - Hadoop入門
by
Shinichi YAMASHITA
Googleの基盤クローン Hadoopについて
by
Kazuki Ohta
Hadoopの紹介
by
bigt23
今さら聞けないHadoop セントラルソフト株式会社(20120119)
by
Toru Takizawa
AspectJを用いた大規模分散システムHadoopの監視とプロファイリング
by
Yusuke Shimizu
Hadoop入門
by
Preferred Networks
MapReduce/YARNの仕組みを知る
by
日本ヒューレット・パッカード株式会社
日々進化するHadoopの 「いま」
by
NTT DATA OSS Professional Services
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演)
by
Hadoop / Spark Conference Japan
Cloud computing competition by Hapyrus
1.
INTEROP
クラウドコンピューティング コンペティション2010 「HadoopクラスタをZERO-CONFで 100+台まで拡張チャレンジ」 チーム ハピルス 藤川幸一 @fujibee 平野智也 @tomoya55 株式会社シリウステクノロジーズ
2.
Hadoopとは? • 大規模データ並列分散処理フレームワーク • Google
MapReduceのオープンソースクローン • テラバイトレベルのデータ処理に必要 – 標準的なHDDがRead 50MB/sとして400TB(Webス ケール)のReadだけで2000時間 – 分散ファイルシステムと分散処理フレームワーク が必要
3.
Hadoopクラスタ拡張の現状 • マスタの設定ファイルにスレーブの場所を記
述 • すべてのスレーブにHadoopパッケージをイン ストール • それぞれのスレーブにタスク用の設定ファイ ルを配置 などなど ⇒ スレーブが大量にあると手間がかかる!
4.
HudsonでZERO-CONF Hadoopクラスタ拡張 • Hadoopスレーブ配布フレームワークとして
Hudsonを利用する • Hudsonはビルドツールとして知られているが実 は分散フレームワークとして利用できる – HudsonはZERO-CONFでスレーブを簡単にアタッチす ることが可能 – さらにHudsonのマスタとスレーブはそれぞれ、 Hadoopのマスタとスレーブを立ち上げることが可能 よってHudsonのスレーブ追加ツールを開発すれ ば、HadoopのZERO-CONFクラスタ拡張が可能!
5.
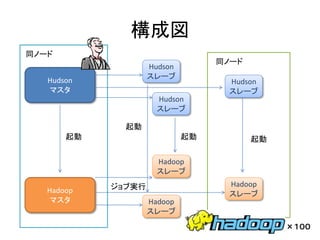
構成図 同ノード
同ノード Hudson Hudson スレーブ Hudson マスタ スレーブ Hudson スレーブ 起動 起動 起動 起動 Hadoop スレーブ ジョブ実行 Hadoop Hadoop スレーブ マスタ Hadoop スレーブ ×100
6.
Hadoop Papyrus • HadoopジョブをRubyのDSLで実行できるオー
プンソースフレームワーク – 本来HadoopジョブはJavaで記述する – Javaだと複雑な記述がほんの数行で書ける! • IPA未踏本体2009年上期のサポートを受け 藤川によって開発されている • Hudson上でジョブを記述/実行が可能
7.
package org.apache.hadoop.examples;
Javaの場合 import java.io.IOException; import java.util.StringTokenizer; 同様な処理がJavaでは70行必要だが、 import org.apache.hadoop.conf.Configuration; Hadoop Papyrusだと10行に! import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; IntSumReducer extends public static class import org.apache.hadoop.mapreduce.Reducer; Reducer<Text, IntWritable, Text, IntWritable> { import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; private IntWritable result = new IntWritable(); import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { public class WordCount { int sum = 0; for (IntWritable val : values) { sum += val.get(); public static class TokenizerMapper extends } Mapper<Object, Text, Text, IntWritable> { result.set(sum); Hadoop Papyrus context.write(key, result); } dsl 'LogAnalysis‘ private final static IntWritable one = new IntWritable(1); } private Text word = new Text(); public static void main(String[] args) throws Exception { public void map(Object key, Text value, Context context) Configuration(); Configuration conf = new from ‘test/in‘ throws IOException, InterruptedException { String[] otherArgs = new GenericOptionsParser(conf, args) StringTokenizer itr = new StringTokenizer(value.toString()); .getRemainingArgs(); to ‘test/out’ while (itr.hasMoreTokens()) { if (otherArgs.length != 2) { word.set(itr.nextToken()); System.err.println("Usage: wordcount <in> <out>"); context.write(word, one); System.exit(2); } } } pattern /¥[¥[([^|¥]:]+)[^¥]:]*¥]¥]/ Job job = new Job(conf, "word count"); } job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); column_name :link job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); topic "link num", :label => 'n' do FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); count_uniq column[:link] System.exit(job.waitForCompletion(true) ? 0 : 1); } } end
8.
今回のチャレンジ 1. Hudsonのスレーブを自動起動するスクリプト
を準備 2. Hudsonのスレーブを起動するだけでHadoop クラスタに自動追加されるデモ 3. 100台Hadoopクラスタ ZERO-CONF起動! 4. そのクラスタでHadoop Papyrusにて Wikipedia全データのリンクをカウントする ジョブ実行 5. 100台以上何台いけるかチャレンジ!
9.
ありがとうございました Twitter ID: @fujibee
/ @tomoya55 / @hapyrus
Download






![package org.apache.hadoop.examples; Javaの場合
import java.io.IOException;
import java.util.StringTokenizer;
同様な処理がJavaでは70行必要だが、
import org.apache.hadoop.conf.Configuration;
Hadoop Papyrusだと10行に!
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper; IntSumReducer extends
public static class
import org.apache.hadoop.mapreduce.Reducer;
Reducer<Text, IntWritable, Text, IntWritable> {
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
private IntWritable result = new IntWritable();
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
public class WordCount { int sum = 0;
for (IntWritable val : values) {
sum += val.get();
public static class TokenizerMapper extends
}
Mapper<Object, Text, Text, IntWritable> {
result.set(sum);
Hadoop Papyrus
context.write(key, result);
} dsl 'LogAnalysis‘
private final static IntWritable one = new IntWritable(1);
}
private Text word = new Text();
public static void main(String[] args) throws Exception {
public void map(Object key, Text value, Context context) Configuration();
Configuration conf = new
from ‘test/in‘
throws IOException, InterruptedException {
String[] otherArgs = new GenericOptionsParser(conf, args)
StringTokenizer itr = new StringTokenizer(value.toString());
.getRemainingArgs();
to ‘test/out’
while (itr.hasMoreTokens()) { if (otherArgs.length != 2) {
word.set(itr.nextToken()); System.err.println("Usage: wordcount <in> <out>");
context.write(word, one); System.exit(2);
}
}
} pattern /¥[¥[([^|¥]:]+)[^¥]:]*¥]¥]/
Job job = new Job(conf, "word count");
} job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
column_name :link
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); topic "link num", :label => 'n' do
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); count_uniq column[:link]
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
end](https://image.slidesharecdn.com/hapyrus-100609014327-phpapp01/85/Cloud-computing-competition-by-Hapyrus-7-320.jpg)





![[東京] JapanSharePointGroup 勉強会 #2](https://cdn.slidesharecdn.com/ss_thumbnails/jpsps2powershell-120405100646-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TL06] 日本の第一人者が C# の現状と今後を徹底解説! 「この素晴らしい C# に祝福を!」](https://cdn.slidesharecdn.com/ss_thumbnails/tl06-170614050641-thumbnail.jpg?width=640&height=640&fit=bounds)
















































