More Related Content

PDF
Fluentdでログを集めてGlusterFSに保存してMapReduceで集計 
KEY

PDF
Apache Drill で見る Twitter の世界 
ODP
高トラフィックサイトをRailsで構築するためのTips基礎編 
PPTX
Seastar in 歌舞伎座.tech#8「C++初心者会」 
PDF
高スループットなサーバアプリケーションの為の新しいフレームワーク
「Seastar」 
PDF

PPTX
What's hot

PPTX
Persistence on Azure� - Microsoft Azure の永続化 
PDF
机上の Kubernetes - 形式手法で見るコンテナオーケストレーション #NGK2016B 
PDF

PDF

PPT
Ruby on rails on hudsonの活用事例 
PDF
BOSHで始めるImmutable Infrastructure ![[社内勉強会]ELBとALBと数万スパイク負荷テスト](https://cdn.slidesharecdn.com/ss_thumbnails/elbalb-160822022623-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[社内勉強会]ELBとALBと数万スパイク負荷テスト 
PDF

PDF
Docker, Kubernetes and OpenShift v3 
PDF

PDF

PPTX
クラウドデザイン パターンに見る�クラウドファーストな�アプリケーション設計 Data Management編 
PDF

PDF
OpenStack ComputingはHyper-Convergedの夢を見るのか? 
PPTX

PDF
kubernetes(GKE)環境におけるdatadog利用 
PDF
OpenStack Object Storage; Usage 
PDF

PDF
OSC2012 Nagoya - OpenStack - Storage System; Overview 
PDF
OpenStack Object Storage; Overview Similar to Rubyによるお手軽分散処理

PDF

PDF

PDF

PDF
夏サミ2013 Hadoopを使わない独自の分散処理環境の構築とその運用 
PPTX
Jenkinsとhadoopを利用した継続的データ解析環境の構築 
PDF
Jenkinsとhadoopを利用した継続的データ解析環境の構築 
PPT
Hadoop ~Yahoo! JAPANの活用について~ 
PDF

PDF

PDF
Hadoop - OSC2010 Tokyo/Spring 
PDF

PDF

PDF
私がMuninに恋する理由 - インフラエンジニアでも監視がしたい! - 
PDF
Muninではじめる実践★リソース監視 -俺のサーバがこんなに重いはずがない、を乗り切るために- 
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~ 
PDF

PDF
OSC2011 Tokyo/Spring Hadoop入門 
PDF
Guide to Cassandra for Production Deployments 
PDF
第12回CloudStackユーザ会_ApacheCloudStack最新情報 
PDF
TokyoWebminig カジュアルなHadoop Rubyによるお手軽分散処理
- 1.
Ruby
によるお手軽分散処理
maebashi
@
IIJ
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
1
- 2.
- 3.
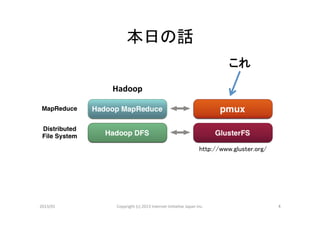
本日の話
• Ruby
でHadoop
MapReduce
みたいなものを
つくりました
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
3
- 4.
本日の話
これ
Hadoop
http://www.gluster.org/
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
4
- 5.
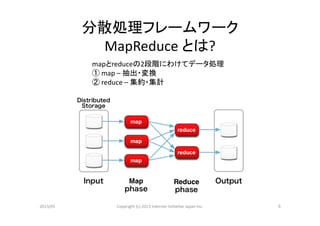
分散処理フレームワーク
MapReduce
とは?
mapとreduceの2段階にわけてデータ処理
①
map
–
抽出・変換
②
reduce
–
集約・集計
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
5
- 6.
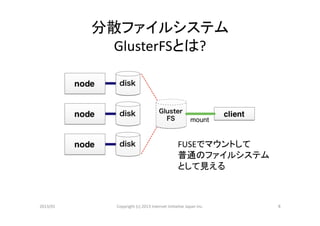
分散ファイルシステム
GlusterFSとは?
FUSEでマウントして
普通のファイルシステム
として見える
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
6
- 7.
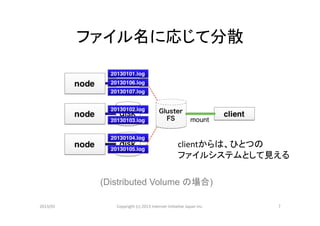
ファイル名に応じて分散
clientからは、ひとつの
ファイルシステムとして見える
(Distributed Volume の場合)
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
7
- 8.
pmux
とは?
(1)
• pipeline
mul>plexer
に由来
• hMps://github.com/iij/pmux
• hMps://github.com/iij/pmux/wiki
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
8
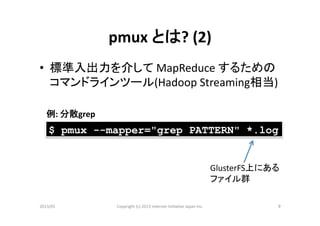
- 9.
pmux
とは?
(2)
• 標準入出力を介して
MapReduce
するための
コマンドラインツール(Hadoop
Streaming相当)
例:
分散grep
$ pmux --mapper="grep PATTERN" *.log
GlusterFS上にある
ファイル群
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
9
- 10.
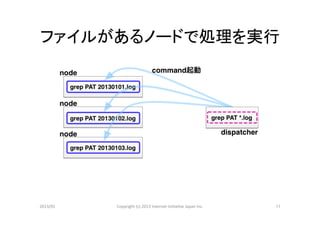
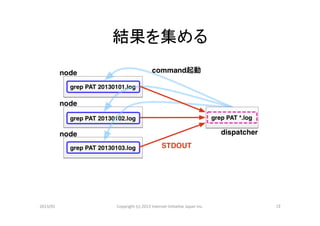
動作原理
• 例えば次のようなコマンド
$ grep PATTERN *.log
• *.log が複数ノードに分散して配置されて
いれば、各ノードで並列に処理できる
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
10
- 11.
- 12.
- 13.
- 14.
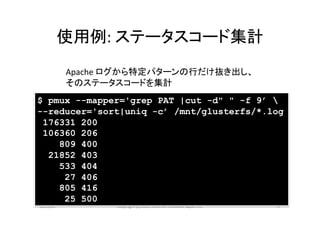
使用例:
ステータスコード集計
Apache
ログから特定パターンの行だけ抜き出し、
そのステータスコードを集計
$ pmux --mapper='grep PAT |cut -d" " -f 9’
--reducer='sort|uniq -c’ /mnt/glusterfs/*.log
176331 200
106360 206
809 400
21852 403
533 404
27 406
805 416
25 500
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
14
- 15.
使用例:
word
count
map.rb
#! /usr/bin/ruby -an
$F.each {|f| print "#{f}t1n"}
reduce.rb
#! /usr/bin/ruby -an
BEGIN {$c = Hash.new 0}
$c[$F[0]] += $F[1].to_i
END {$c.each {|k, v| print "#{k} #{v}n"}}
コマンドライン
$ pmux --mapper=map.rb --reducer=reduce.rb
--file=map.rb –-file=reduce.rb
/mnt/glusterfs/*.txt
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
15
- 16.
コンセプト
• なるべく既にある概念を用いて分散処理
– 普通のファイルシステムに見える GlusterFS
– Unix
のパイプの思想とフィルタコマンド群
– ssh によるリモートコマンド実行
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
16
- 17.
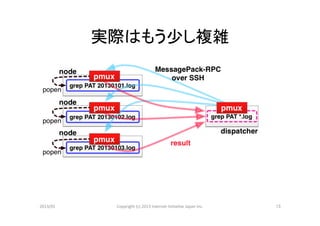
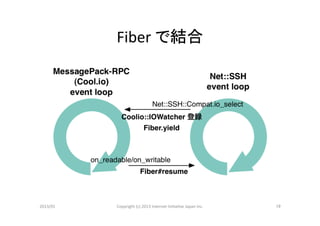
内部構造
• シングルスレッド
• イベントドリブン方式
• Net::SSH
で ssh
セッションを同時に複数張り、
その上に MessagePack-‐RPC
を通す
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
17
- 18.
- 19.
- 20.
ベンチマークテスト
こんなかんじのtcpdumpのlogの
14:00:00.416011
IP
21.44.60.29.hMp
>
170.73.162.175.58546:
.
3523999974:3524001422(1448)
ack
3401170238
win
1716
<nop,nop,>mestamp
1070614671
1955062367>
各ファイルで一番出現数の多かった
IPアドレスを抽出
8344ファイル、1ファイルあたり約50万行、計約40億行
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
20
- 21.
- 22.
結果
pmuxを使わずに1台で実行
8時間49分6秒
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
22
- 23.
結果
pmuxを使わずに1台で実行
8時間49分6秒
pmuxを使ってノード60台で実行
1分45秒
約300倍
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
23
- 24.
- 25.
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
25






![使用例:
word
count
map.rb
#! /usr/bin/ruby -an
$F.each {|f| print "#{f}t1n"}
reduce.rb
#! /usr/bin/ruby -an
BEGIN {$c = Hash.new 0}
$c[$F[0]] += $F[1].to_i
END {$c.each {|k, v| print "#{k} #{v}n"}}
コマンドライン
$ pmux --mapper=map.rb --reducer=reduce.rb
--file=map.rb –-file=reduce.rb
/mnt/glusterfs/*.txt
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
15](https://image.slidesharecdn.com/tkrk10-pmux-130114040205-phpapp01/85/Ruby-15-320.jpg)




![実行するmapコマンド
--mapper='egrep –o "[0-9]+.[0-9]+.[0-9]+.[0-9]+"|
sort|uniq -c|sort -nr|head -1'
2013/01
Copyright
(c)
2013
Internet
Ini>a>ve
Japan
Inc.
21](https://image.slidesharecdn.com/tkrk10-pmux-130114040205-phpapp01/85/Ruby-21-320.jpg)



