Scala による Quicksort def qsort[T <% Ordered[T]](list: List[T]): List[T] = list match { case Nil => Nil case pivot::tail => qsort(tail.filter(_ < pivot)) ::: pivot :: qsort(tail.filter(_ >= pivot)) } scala> qsort(List(2,1,3)) res1: List[Int] = List(1, 2, 3)
17.
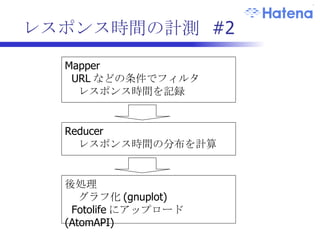
WordCount by Javapublic class WordCount { public static class Map extends MapReduceBase implements Mapper<LongWritable, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); } } } public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable> { …
18.
WordCount by Scalaobject WordCount { class MyMap extends Mapper[LongWritable, Text, Text, IntWritable] { val one = 1 override def map(ky: LongWritable, value: Text, output: Mapper[LongWritable, Text, Text, IntWritable]#Context) = { (value split " ") foreach (output write (_, one)) } } class MyReduce extends Reducer[Text, IntWritable, Text, IntWritable] { override def reduce(key: Text, values: java.lang.Iterable[IntWritable], output: Reducer[Text, IntWritable, Text, IntWritable]#Context) = { val iter: Iterator[IntWritable] = values.iterator() val sum = iter reduceLeft ((a: Int, b: Int) => a + b) output write (key, sum) } } def main(args: Array[String]) = { …
19.
Java vs ScalaJava Scala public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); } } override def map(ky: LongWritable, value: Text, output: Mapper[LongWritable, Text, Text, IntWritable]#Context) = { (value split " ") foreach (output write (_, one)) }
20.
Scala on HadoopJava と Scala を接続するライブラリが必要 SHadoop http://code.google.com/p/jweslley/source/browse/#svn/trunk/scala/shadoop 型変換を行うシンプルなライブラリ
reducer class MyReduceextends Reducer[Text, IntWritable, Text, IntWritable] { override def reduce(key: Text, values: java.lang.Iterable[IntWritable], output: Reducer[Text, IntWritable, Text, IntWritable]#Context) = { val iter: Iterator[IntWritable] = values.iterator() val sum = iter reduceLeft ((a: Int, b: Int) => a + b) output write (key, sum) } }
23.
main def main(args:Array[String]) = { val conf = new Configuration() val otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs() val job = new Job(conf, "word count") job setJarByClass(WordCount getClass()) job setMapperClass(classOf[WordCount.MyMap]) job setCombinerClass(classOf[WordCount.MyReduce]) job setReducerClass(classOf[WordCount.MyReduce]) job setMapOutputKeyClass(classOf[Text]) job setMapOutputValueClass(classOf[IntWritable]) job setOutputKeyClass(classOf[Text]) job setOutputValueClass(classOf[IntWritable]) FileInputFormat addInputPath(job, new Path(otherArgs(0))) FileOutputFormat setOutputPath(job, new Path(otherArgs(1))) System exit(job waitForCompletion(true) match { case true => 0 case false => 1}) }
24.
HDFS 操作 importjava.net.URI import org.apache.hadoop.fs._ import org.apache.hadoop.hdfs._ import org.apache.hadoop.conf.Configuration object Hdfs { def main(args: Array[String]) = { val conf = new Configuration() val uri = new URI("hdfs://hadoop01:9000/") val fs = new DistributedFileSystem fs.initialize(uri, conf) var status = fs.getFileStatus(new Path(args(0))) println(status.getModificationTime) } }









![map.pl #!/usr/bin/env perl use strict; use warnings; while (<>) { chomp; my @segments = split /\s+/; printf "%s\t%s\n", $segments[8], 1; }](https://image.slidesharecdn.com/091113hadoopconference2-091124223838-phpapp01/85/Scala-on-Hadoop-9-320.jpg)





![Scala 2003 年登場 関数型の特徴を備えた言語 普通のオブジェクト指向っぽくも書ける JavaVM 上で動作する object HelloWorld { def main(args: Array[String]) { println("Hello, world!") } }](https://image.slidesharecdn.com/091113hadoopconference2-091124223838-phpapp01/85/Scala-on-Hadoop-15-320.jpg)
![Scala による Quick sort def qsort[T <% Ordered[T]](list: List[T]): List[T] = list match { case Nil => Nil case pivot::tail => qsort(tail.filter(_ < pivot)) ::: pivot :: qsort(tail.filter(_ >= pivot)) } scala> qsort(List(2,1,3)) res1: List[Int] = List(1, 2, 3)](https://image.slidesharecdn.com/091113hadoopconference2-091124223838-phpapp01/85/Scala-on-Hadoop-16-320.jpg)

![WordCount by Scala object WordCount { class MyMap extends Mapper[LongWritable, Text, Text, IntWritable] { val one = 1 override def map(ky: LongWritable, value: Text, output: Mapper[LongWritable, Text, Text, IntWritable]#Context) = { (value split " ") foreach (output write (_, one)) } } class MyReduce extends Reducer[Text, IntWritable, Text, IntWritable] { override def reduce(key: Text, values: java.lang.Iterable[IntWritable], output: Reducer[Text, IntWritable, Text, IntWritable]#Context) = { val iter: Iterator[IntWritable] = values.iterator() val sum = iter reduceLeft ((a: Int, b: Int) => a + b) output write (key, sum) } } def main(args: Array[String]) = { …](https://image.slidesharecdn.com/091113hadoopconference2-091124223838-phpapp01/85/Scala-on-Hadoop-18-320.jpg)
![Java vs Scala Java Scala public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); } } override def map(ky: LongWritable, value: Text, output: Mapper[LongWritable, Text, Text, IntWritable]#Context) = { (value split " ") foreach (output write (_, one)) }](https://image.slidesharecdn.com/091113hadoopconference2-091124223838-phpapp01/85/Scala-on-Hadoop-19-320.jpg)

![mapper class MyMap extends Mapper[LongWritable, Text, Text, IntWritable] { val one = 1 override def map(ky: LongWritable, value: Text, output: Mapper[LongWritable, Text, Text, IntWritable]#Context) = { (value split " ") foreach (output write (_, one)) } }](https://image.slidesharecdn.com/091113hadoopconference2-091124223838-phpapp01/85/Scala-on-Hadoop-21-320.jpg)
![reducer class MyReduce extends Reducer[Text, IntWritable, Text, IntWritable] { override def reduce(key: Text, values: java.lang.Iterable[IntWritable], output: Reducer[Text, IntWritable, Text, IntWritable]#Context) = { val iter: Iterator[IntWritable] = values.iterator() val sum = iter reduceLeft ((a: Int, b: Int) => a + b) output write (key, sum) } }](https://image.slidesharecdn.com/091113hadoopconference2-091124223838-phpapp01/85/Scala-on-Hadoop-22-320.jpg)
![main def main(args: Array[String]) = { val conf = new Configuration() val otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs() val job = new Job(conf, "word count") job setJarByClass(WordCount getClass()) job setMapperClass(classOf[WordCount.MyMap]) job setCombinerClass(classOf[WordCount.MyReduce]) job setReducerClass(classOf[WordCount.MyReduce]) job setMapOutputKeyClass(classOf[Text]) job setMapOutputValueClass(classOf[IntWritable]) job setOutputKeyClass(classOf[Text]) job setOutputValueClass(classOf[IntWritable]) FileInputFormat addInputPath(job, new Path(otherArgs(0))) FileOutputFormat setOutputPath(job, new Path(otherArgs(1))) System exit(job waitForCompletion(true) match { case true => 0 case false => 1}) }](https://image.slidesharecdn.com/091113hadoopconference2-091124223838-phpapp01/85/Scala-on-Hadoop-23-320.jpg)
![HDFS 操作 import java.net.URI import org.apache.hadoop.fs._ import org.apache.hadoop.hdfs._ import org.apache.hadoop.conf.Configuration object Hdfs { def main(args: Array[String]) = { val conf = new Configuration() val uri = new URI("hdfs://hadoop01:9000/") val fs = new DistributedFileSystem fs.initialize(uri, conf) var status = fs.getFileStatus(new Path(args(0))) println(status.getModificationTime) } }](https://image.slidesharecdn.com/091113hadoopconference2-091124223838-phpapp01/85/Scala-on-Hadoop-24-320.jpg)






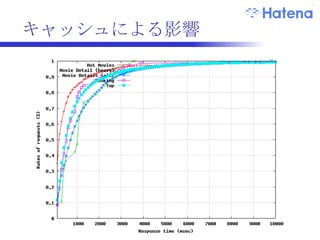

![Q & A [email_address]](https://image.slidesharecdn.com/091113hadoopconference2-091124223838-phpapp01/85/Scala-on-Hadoop-34-320.jpg)


































































