More Related Content

PDF

PPTX

PPTX

ZIP

PDF
CephとGluster次期バージョンでの新機能 
PDF

PDF
グラフデータベースNeo4Jでアセットダウンロードの構成管理と最適化 
PPTX
Amazon RDS for PostgreSQL ( JPUG 2014夏セミナー) #jpug What's hot

PPTX

PDF
Apache Drill で見る Twitter の世界 
PDF
OpenStack ComputingはHyper-Convergedの夢を見るのか? 
PDF
知っておくべきCephのIOアクセラレーション技術とその活用方法 - OpenStack最新情報セミナー 2015年9月 ![[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018optimizingdeeplearningwithpfnseiyatokui-181009073509-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也 
PDF
フルオープンソースでここまで出来る。OpenStackの構築と運用 
PDF
Kubernetes meetup-tokyo-13-customizing-kubernetes-for-ml-cluster ![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介 
PPT

PDF

PDF
まだCPUで消耗してるの?Jubatusによる近傍探索のGPUを利用した高速化 
KEY

PDF

PPT

PDF
localstackによるAWS Lambdaの開発環境を、miniconda上でつくったら簡単便利だった話 
PDF
Ceph Loves OpenStack: Why and How 
PPTX

PDF

PDF
Prometheus at Preferred Networks 
PDF
Vyatta and Virtualization 仮想環境でのVyatta Similar to Fluentdでログを集めてGlusterFSに保存してMapReduceで集計

PDF

PDF

PDF

PDF

PPT
Hadoop ~Yahoo! JAPANの活用について~ 
PDF
OSSで支えられるライブドアの巨大ログ集計 #nhntech 
PDF

PDF
Muninではじめる実践★リソース監視 -俺のサーバがこんなに重いはずがない、を乗り切るために- 
PPT
遊休リソースを用いた�相同性検索処理の並列化とその評価 
PDF
how to defend DNS authoritative server against DNS WaterTorture 
PDF

PDF

PDF
Guide to Cassandra for Production Deployments 
PDF
夏サミ2013 Hadoopを使わない独自の分散処理環境の構築とその運用 
PDF
Twitter クライアント “Termtter” の紹介と収集したソーシャルデータを Fluentd + Hadoop で分析する話 
PDF
第12回CloudStackユーザ会_ApacheCloudStack最新情報 
PDF
Fabric + Amazon EC2で快適サポート生活 #PyFes 
PDF
Jenkinsとhadoopを利用した継続的データ解析環境の構築 
PDF
Hadoop - OSC2010 Tokyo/Spring 
PPTX
Jenkinsとhadoopを利用した継続的データ解析環境の構築 Fluentdでログを集めてGlusterFSに保存してMapReduceで集計
- 1.
- 2.
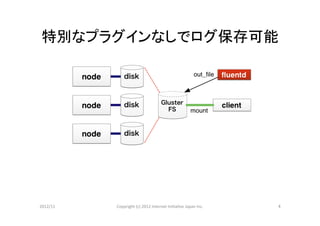
キーワード
Fluentd
GlusterFS
MapReduce
2012/11
Copyright
(c)
2012
Internet
IniCaCve
Japan
Inc.
2
- 3.
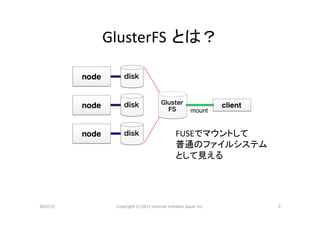
GlusterFS とは?
FUSEでマウントして
普通のファイルシステム
として見える
2012/11
Copyright
(c)
2012
Internet
IniCaCve
Japan
Inc.
3
- 4.
- 5.
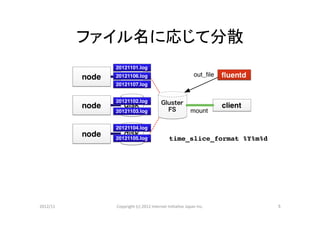
ファイル名に応じて分散
time_slice_format %Y%m%d
2012/11
Copyright
(c)
2012
Internet
IniCaCve
Japan
Inc.
5
- 6.
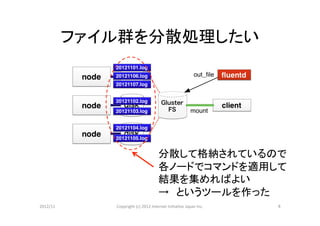
ファイル群を分散処理したい
分散して格納されているので
各ノードでコマンドを適用して
結果を集めればよい
→ というツールを作った
2012/11
Copyright
(c)
2012
Internet
IniCaCve
Japan
Inc.
6
- 7.
pmux
• pipeline
mulCplexer
に由来
• 標準入出力を介してMapReduce
するためのコ
マンドラインツール
$ pmux --mapper="grep PATTERN" /glusterfs/*.log!
• ファイルベース(chunkに分割しない)
– GlusterFSのdistributed,
replicated
volumeに対応
• hKps://github.com/iij/pmux
2012/11
Copyright
(c)
2012
Internet
IniCaCve
Japan
Inc.
7
- 8.
似ているもの
• Hadoop
Streaming
• GNU
Parallel
• GXP
2012/11
Copyright
(c)
2012
Internet
IniCaCve
Japan
Inc.
8
- 9.
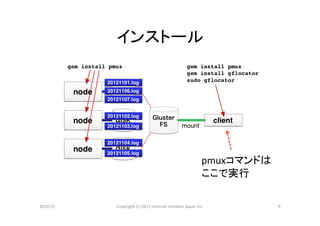
インストール
pmuxコマンドは
ここで実行
2012/11
Copyright
(c)
2012
Internet
IniCaCve
Japan
Inc.
9
- 10.
- 11.
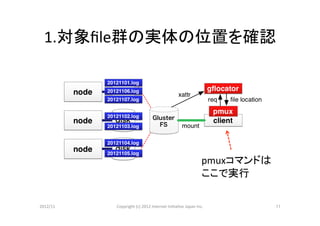
1.対象file群の実体の位置を確認
pmuxコマンドは
ここで実行
2012/11
Copyright
(c)
2012
Internet
IniCaCve
Japan
Inc.
11
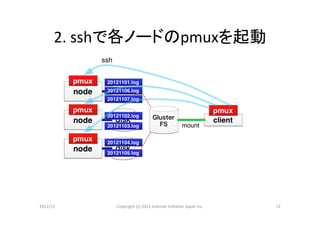
- 12.
- 13.
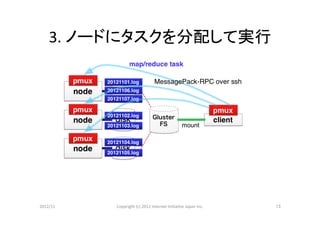
- 14.
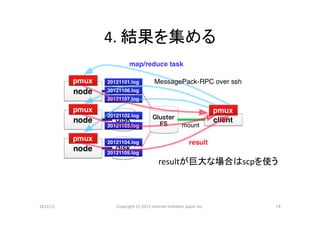
4.
結果を集める
resultが巨大な場合はscpを使う
2012/11
Copyright
(c)
2012
Internet
IniCaCve
Japan
Inc.
14
- 15.
ベンチマークテスト
こんなかんじのログの
2012-‐11-‐01T23:50:22+09:00
apache.access
{"host":
"192.168.16.153","user":"-‐","method":"GET","path":"/0123456789
10000","code":"200","size":"1513395608","referer":"-‐","agent":"-‐",
"inbyte":"162","outbyte":"233396987"}
size,
inbyte,
outbyteを集計する
665ファイル、1億6300万行
2012/11
Copyright
(c)
2012
Internet
IniCaCve
Japan
Inc.
15
- 16.
• pmux
使わない場合
$ ./sum.rb /glusterfs/*.log.gz!
• pmux
使う場合
$ pmux --file=sum.rb --mapper=sum.rb !
/glusterfs/*.log.gz | ./sum.rb!
2012/11
Copyright
(c)
2012
Internet
IniCaCve
Japan
Inc.
16
- 17.
• pmux
使わない場合
94分55秒
$ ./sum.rb /glusterfs/*.log.gz!
• pmux
使う場合
$ pmux --file=sum.rb --mapper=sum.rb !
/glusterfs/*.log.gz | ./sum.rb!
2012/11
Copyright
(c)
2012
Internet
IniCaCve
Japan
Inc.
17
- 18.
• pmux
使わない場合
94分55秒
$ ./sum.rb /glusterfs/*.log.gz!
• pmux
使う場合 ノード40台で
35秒
$ pmux --file=sum.rb --mapper=sum.rb !
/glusterfs/*.log.gz | ./sum.rb!
162倍
2012/11
Copyright
(c)
2012
Internet
IniCaCve
Japan
Inc.
18
- 19.
- 20.