More Related Content

PDF

PPTX
Curriculum Learning (関東CV勉強会) 
PDF
自己教師学習(Self-Supervised Learning) 
PPTX
SSII2020SS: 微分可能レンダリングの最新動向 〜「見比べる」ことによる3次元理解 〜 
PDF
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder 
PDF
【メタサーベイ】Vision and Language のトップ研究室/研究者 ![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Deep Learning 第15章 表現学習 What's hot

PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演) 
PDF

PDF

PPTX
NIPS2015読み会: Ladder Networks 
PDF

PDF
感覚運動随伴性、予測符号化、そして自由エネルギー原理 (Sensory-Motor Contingency, Predictive Coding and ... ![[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...](https://cdn.slidesharecdn.com/ss_thumbnails/20180803dlakuzawa-180803003349-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se... 
PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会) 
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話) 
PDF

PPTX

PDF
cvpaper.challenge 研究効率化 Tips 
PDF

PPTX

PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情 
PDF
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent ![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法 
PDF
Viewers also liked

PDF
3次元のデータをグラフにする(Tokyo.R#17) 
PDF

PDF
非線形データの次元圧縮 150905 WACODE 2nd 
PDF

PPTX
Dimension Reduction And Visualization Of Large High Dimensional Data Via Inte... 
PDF
Methods of Manifold Learning for Dimension Reduction of Large Data Sets 
PDF
Manifold learning with application to object recognition 
PDF
WSDM2016読み会 Collaborative Denoising Auto-Encoders for Top-N Recommender Systems ![[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...](https://cdn.slidesharecdn.com/ss_thumbnails/dp-mrmkimicml2012-120727233419-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri... 
PDF
Visualizing Data Using t-SNE 
PDF
関東CV勉強会 Kernel PCA (2011.2.19) 
PPT

PDF
The Gaussian Process Latent Variable Model (GPLVM) 
PPTX

PDF
東京R非公式おじさんが教える本当に気持ちいいパッケージ作成法 
PDF

PDF
More from Hirotaka Matsumoto

PPTX

PDF

PDF

PDF

PDF

PDF

PDF
MixSIH: a mixture model for single individual haplotyping 次元圧縮周りでの気付き&1細胞発現データにおける次元圧縮の利用例@第3回wacode
- 1.
- 2.
自己紹介
• 松本 拡高
•東大 メディカル情報生命専攻 D3
• バイオインフォにおける確率モデル
と機械学習
• 連絡先
– @gggtta
– matsumoto@cb.k.u-tokyo.ac.jp
- 3.
- 4.
- 5.
- 6.
- 7.
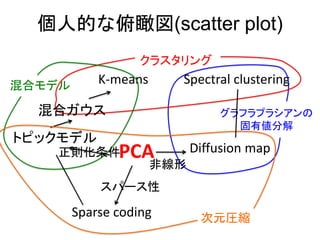
Sparse coding
• 目的関数は
•Wの直交性の条件はない
• Ziにスパース性を含めただけ
• PCAとほとんど同じではないか。。。
• 確率論的には
– PCA : ziの事前分布がガウス分布
– SC : ziの事前分布がラプラス分布
- 8.
- 9.
- 10.
- 11.
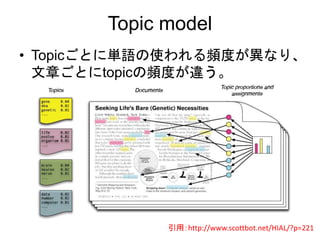
topic model ->mixture model -> k-means
• トピックモデル
– 出現確率がデータごとに異なる。
• 混合モデル
– 出現確率はデータで共通
• K-means
– 混合ガウスのある極限
- 12.
- 13.
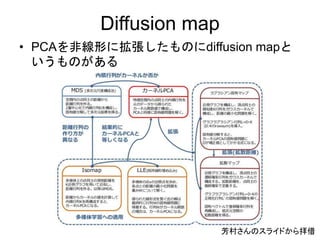
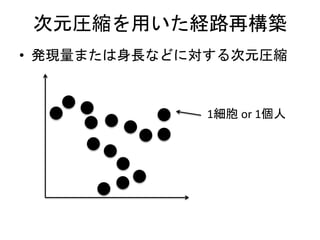
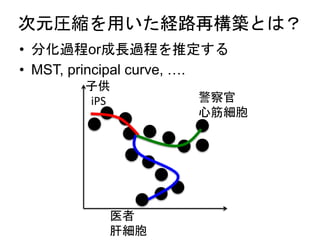
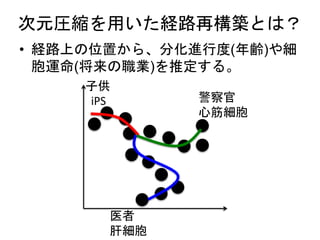
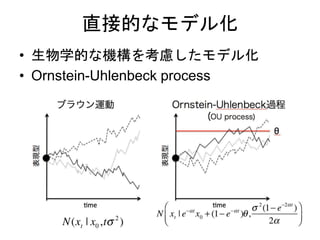
Diffusion map
• 手順
•高次元空間上でのデータ間の遷移確率行
列をガウスカーネルから作る(ある種のグ
ラフラプラシアン)
• 遷移確率行列を固有値分解してえられる
固有ベクトルがZiに相当
- 14.
- 15.
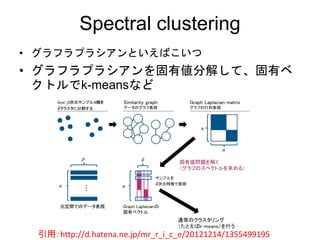
Diffusion map vsspectral clustering
• グラフラプラシアンを固有値分解して固
有ベクトルを見るところまで同じ
– ※正確には許容できるグラフラプラシアンが違うはず
• 固有ベクトルを、連続量として扱うか、
離散的なクラスタに分類するかの違いで
しかない。
- 16.
- 17.
- 18.
- 19.
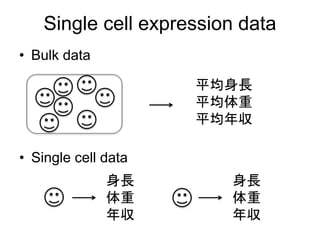
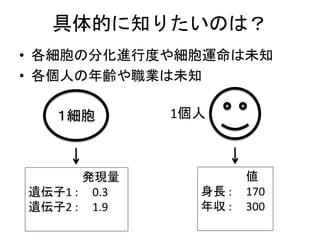
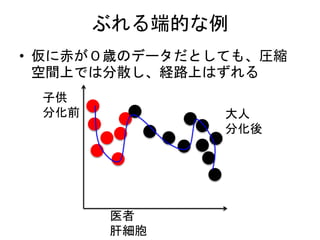
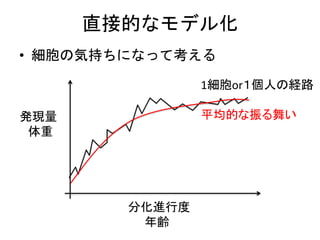
Single cell expressiondata
• Bulk data
– ある程度細胞数が含まれたサンプルをまとめ
て計測する
– 異なる分化進行度、細胞運命の細胞が混ざっ
ており、データは平均像でしかない
• Single cell data
– 各細胞のデータを取得できるようになった
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.