




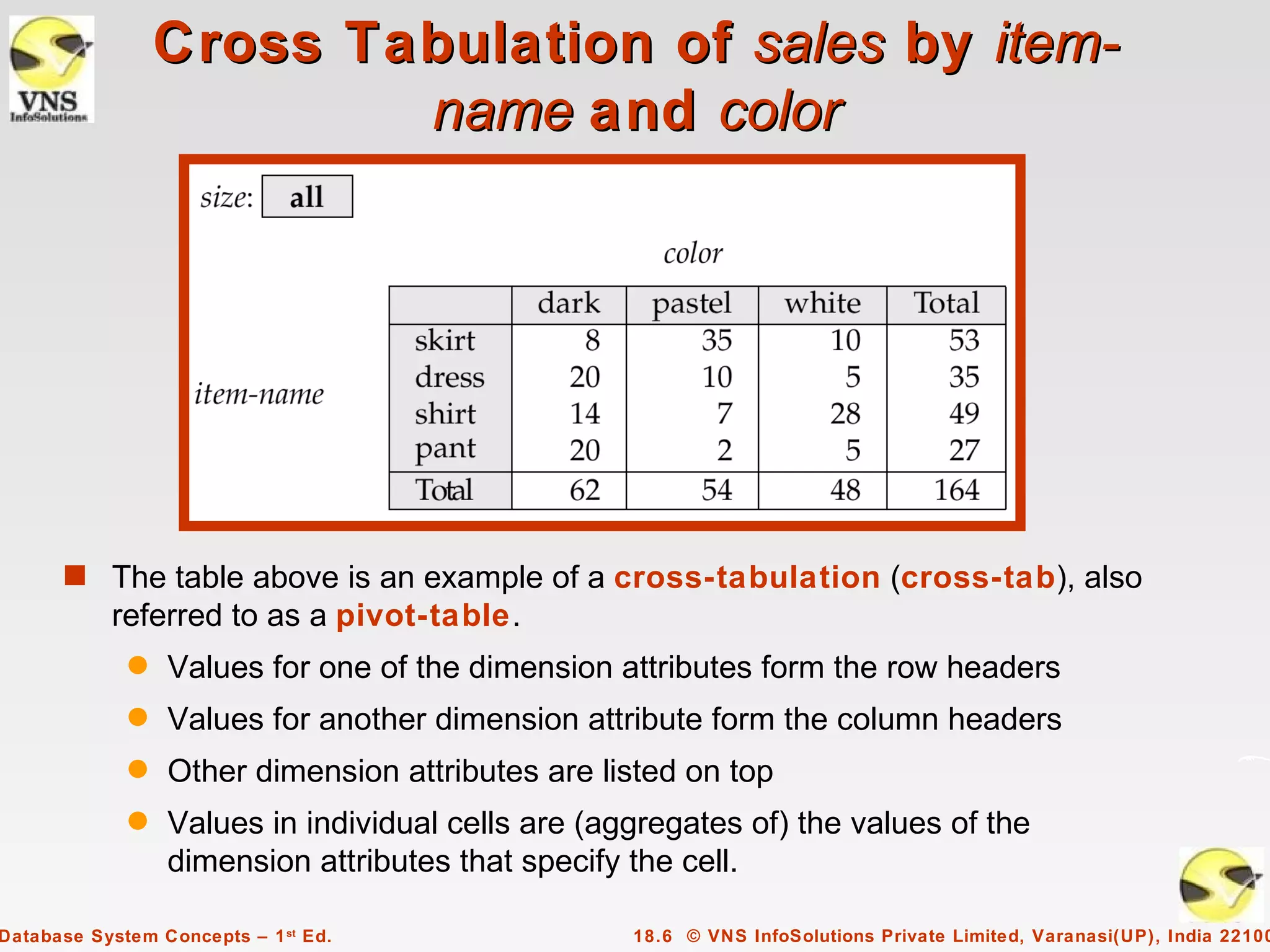
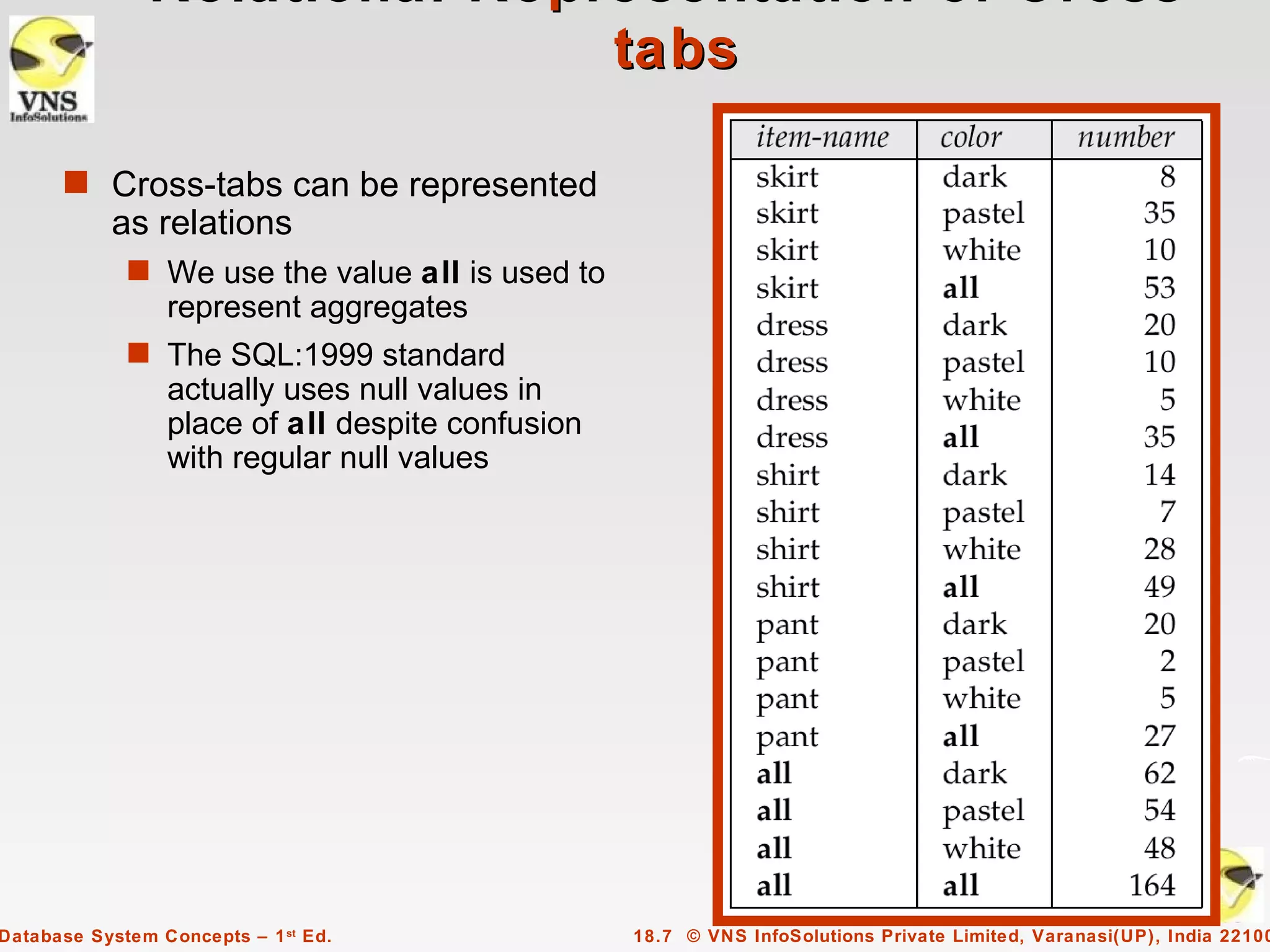
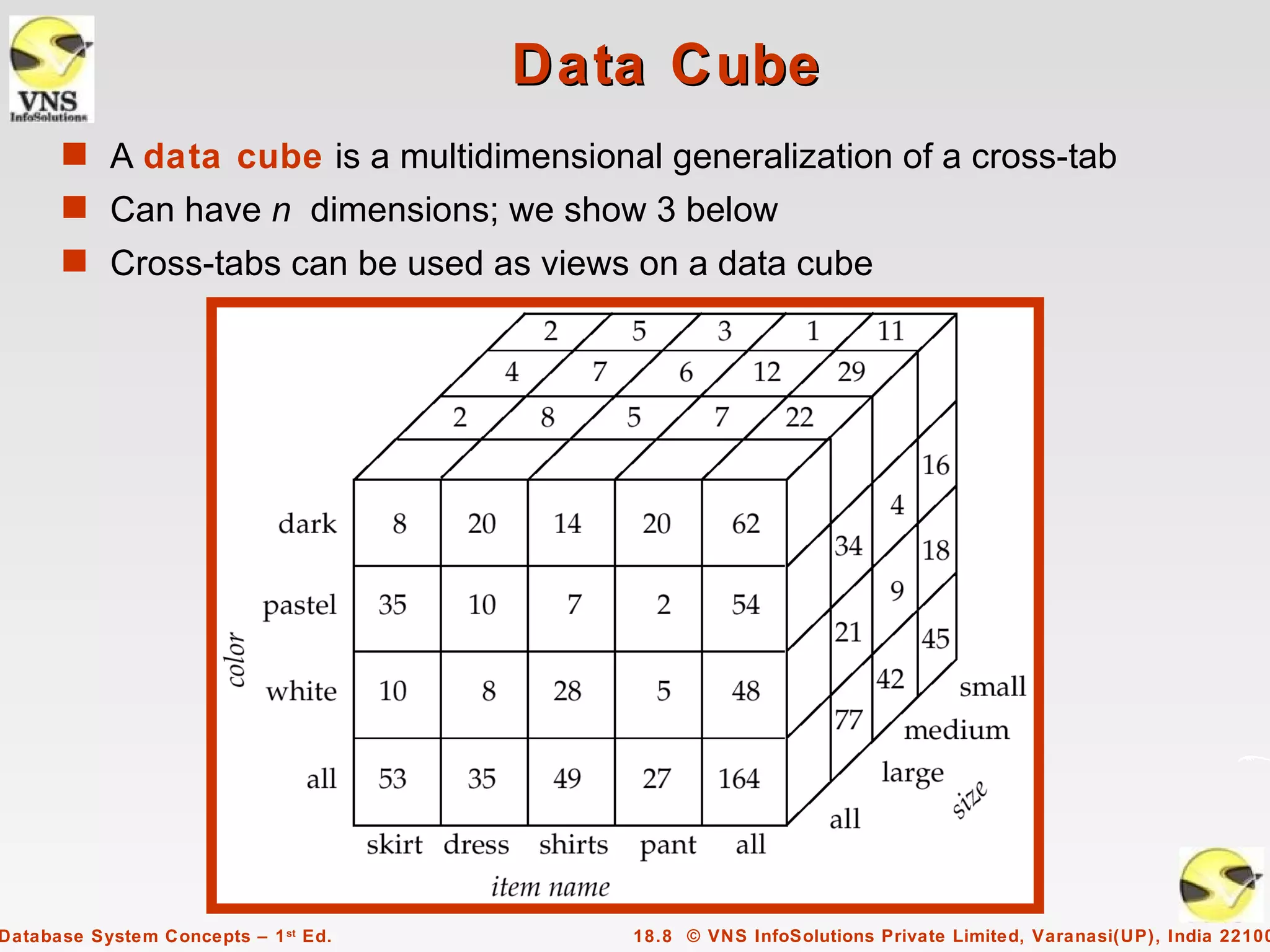

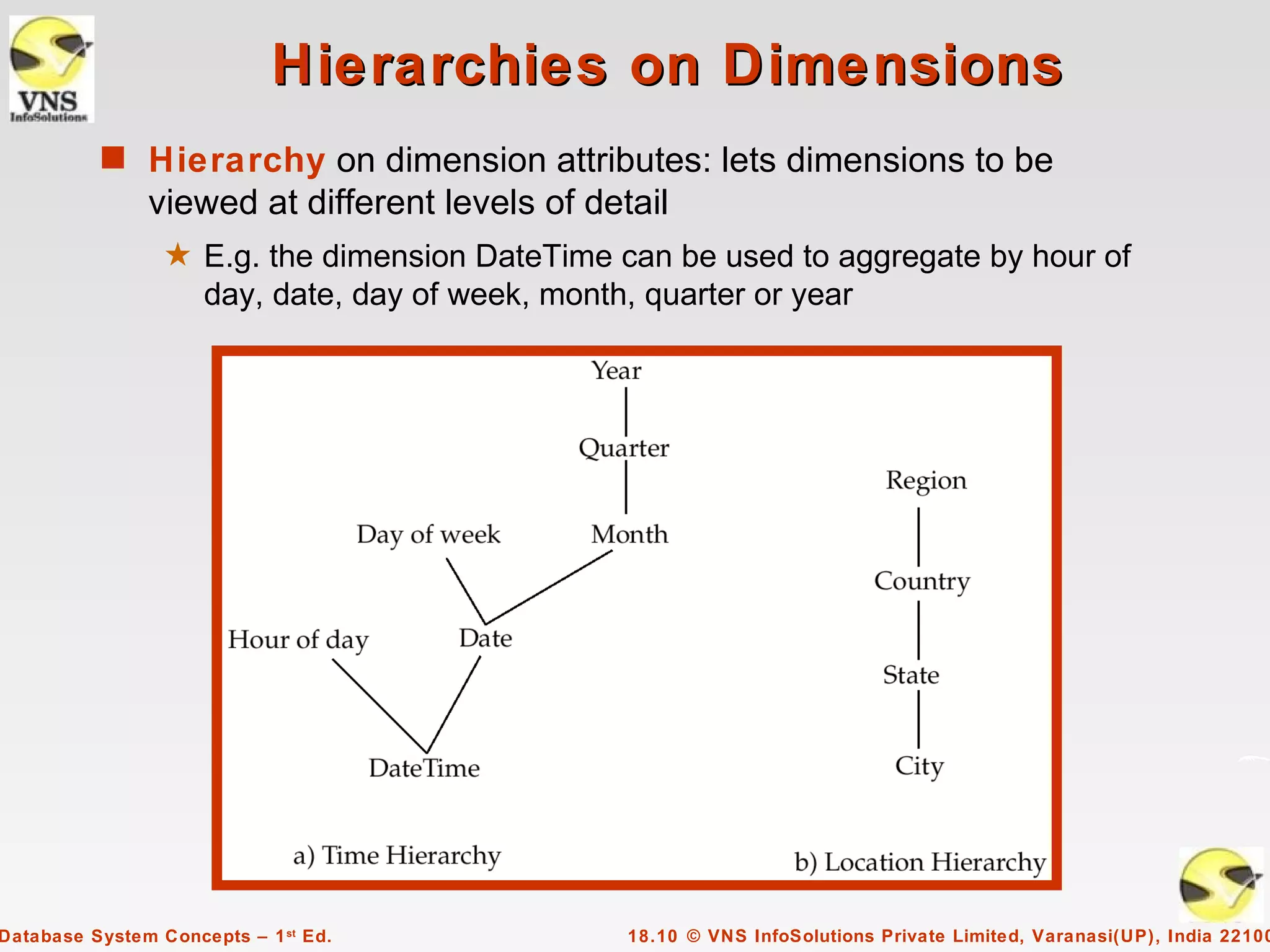
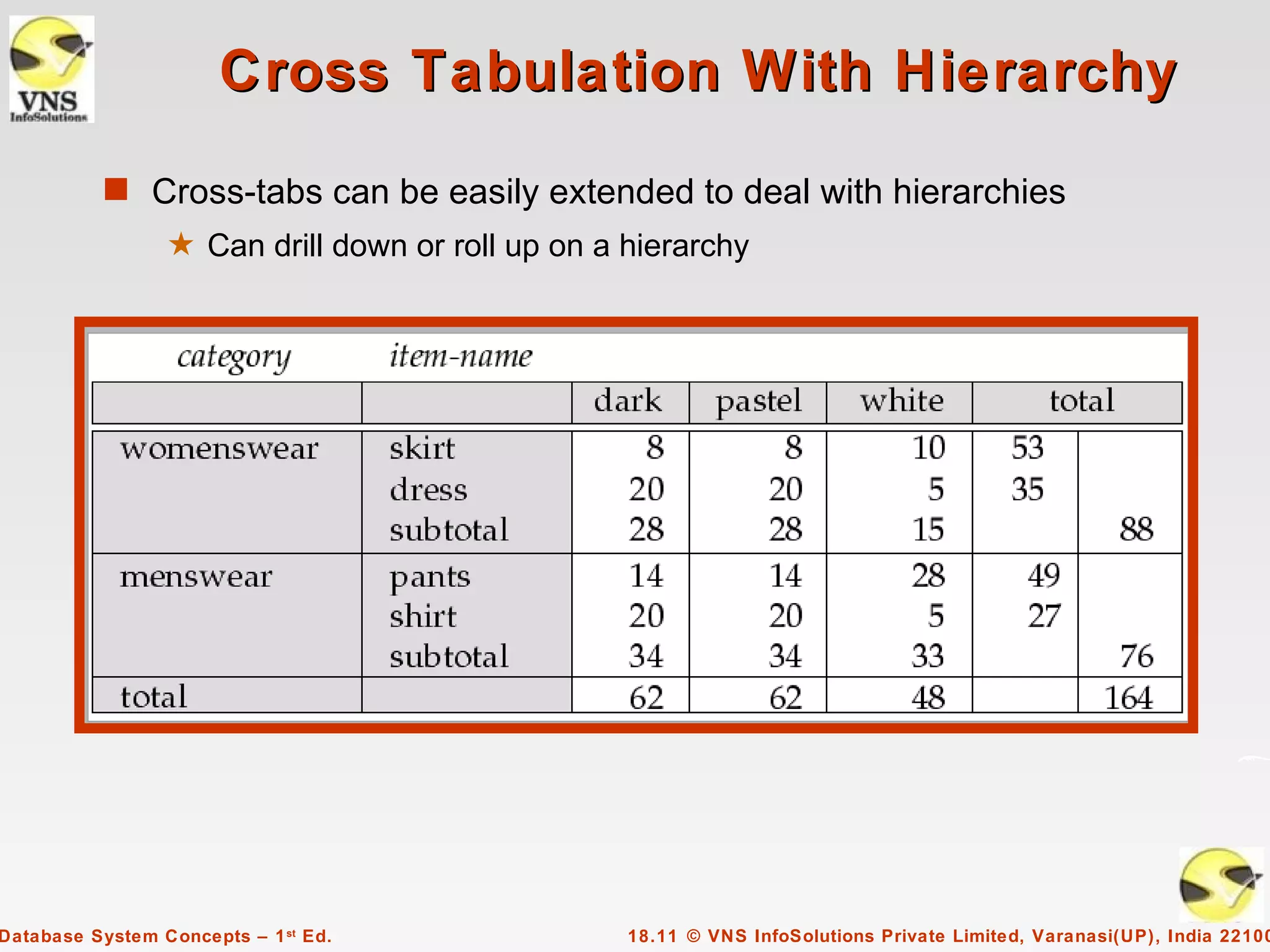













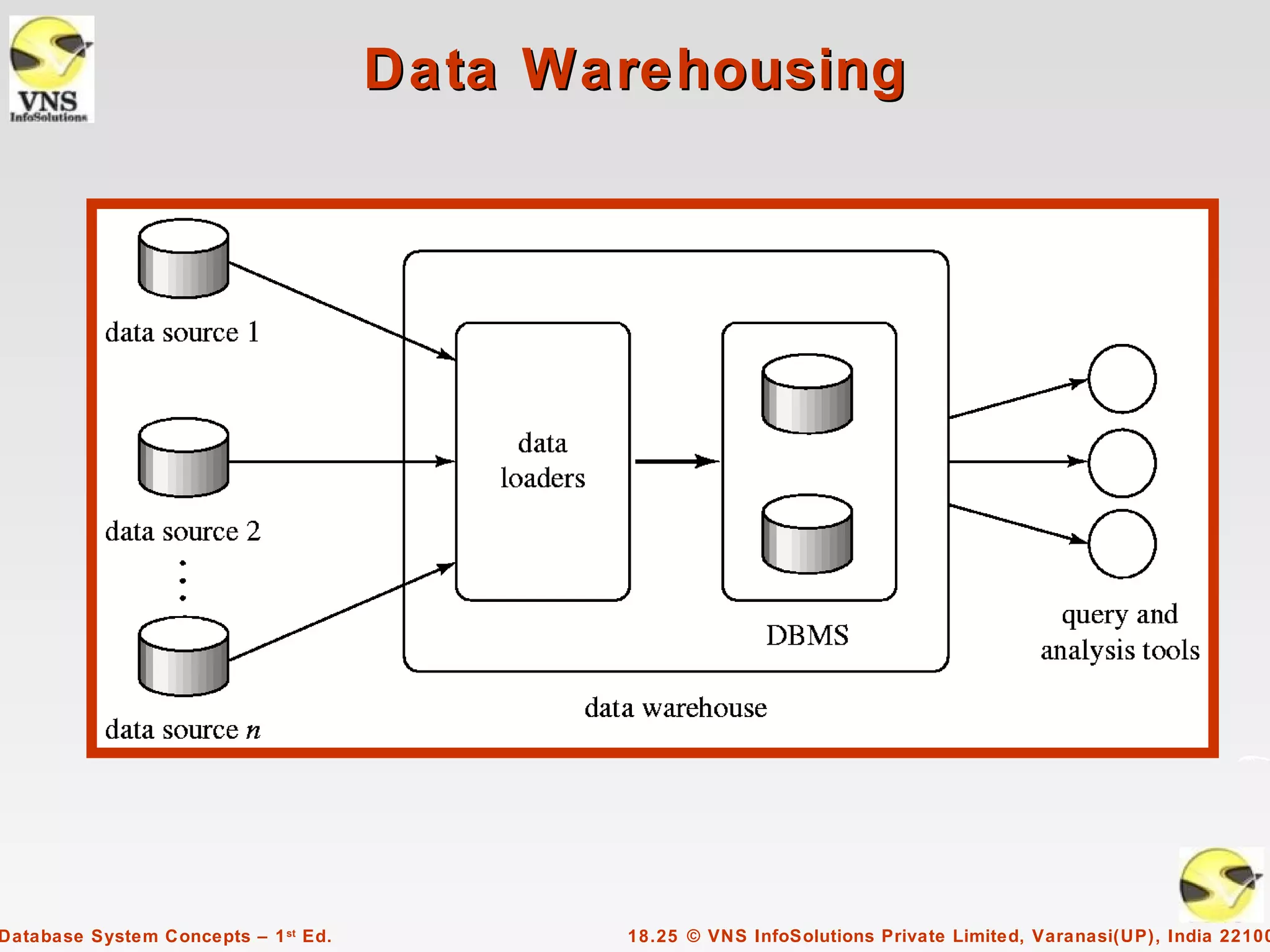



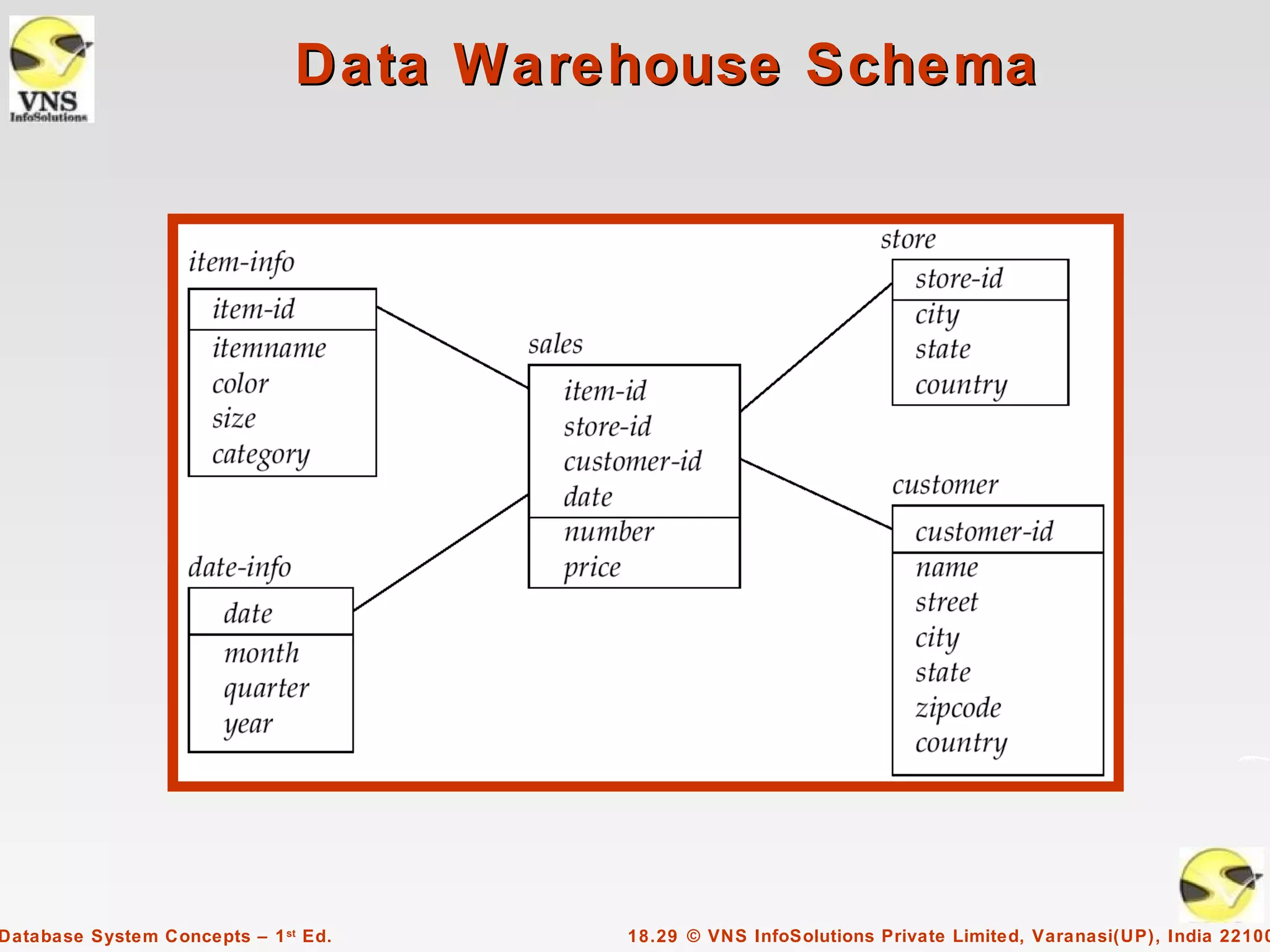



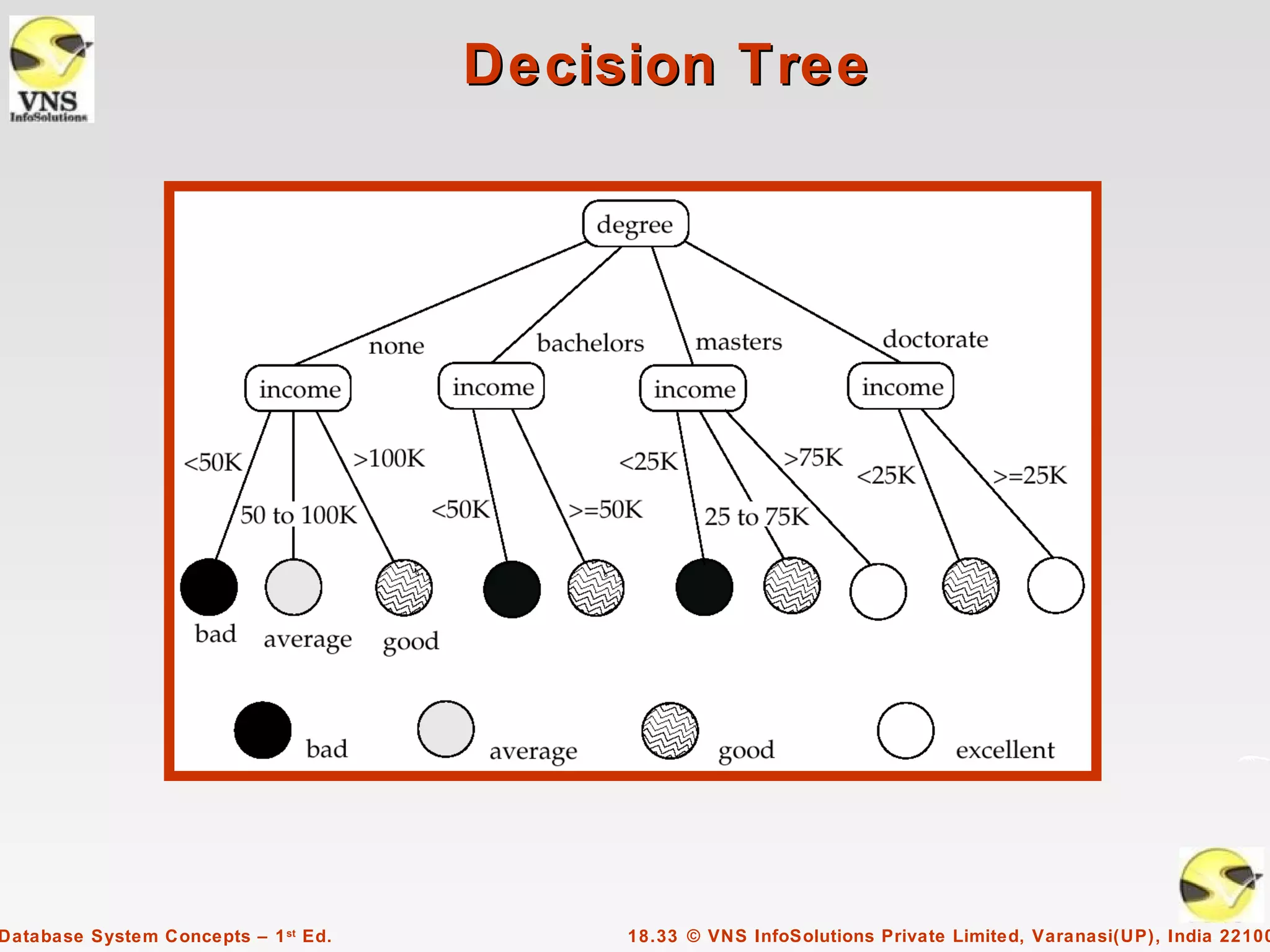



















The document discusses data analysis and mining within database systems, highlighting decision support systems that use data from online transaction-processing systems for business decisions. It covers various data analysis tools such as OLAP, data warehousing, and the importance of data mining for discovering patterns and knowledge in large databases. Key concepts include data cubes, aggregation methods, and the design and implementation of data warehouses for streamlined querying and historical data analysis.



































































